Using Simulated Annealing to Find Increased Sound-Shape Systematicity in Parametric Fonts
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-
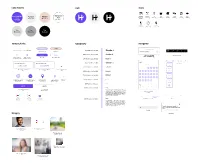
Color Palette Typography Header 1 Navigation Imagery Logo
Color Palette Logo Icons Background Brand/Highlight Highlight Highlight Dates Page/ Restaurant Bar Coffee Movies The Arts Music Sports /Text Date on date (location tag) (location tag) (location tag) (location tag) (location tag) (location tag) (location tag) /Text #EDEDED #F1D7CA plan page #6A42ED #FFFFFF Outdoors Time Location (location tag) (Date plan page) (Date plan page) Text Text Text #DDDDDD #AAAAAA #000000 Buttons/Links Typography Navigation Button Button Ready to go on a date? Open drop down menu Close drop down menu Source Serif Pro, s: 36, Bold Header 1 4 1 Inactive primary CTA Secondary CTA Enable “Set Up a Date” Feature Private until you both have enabled Button Button IBM Plex Sans, s: 30, Semi-Bold Header 2 Popup with the Enable a date Bottom navigation menu feature on the match chat page Inactive toggle state Active toggle state Primary CTA Tertiary CTA and Filters (enable setup feature) (enable setup feature) IBM Plex Sans, s: 21, Semi-Bold Header 3 Activity Price Rating April Source Serif Pro, s: 24, Bold Subheader 1 Who do you want to date? Who do you want to date? Recommended Filters (expanded) S M T W T F S Select a Match Erin Matthews New Spots IBM Plex Sans, s: 18, Semi-Bold Subheader 2 1 2 3 4 Upcoming Events Setup a Date Buttons (nothing Setup a Date Buttons (selection Close button (used for popout selected made) screens) Get a Drink IBM Plex Sans, s: 15, Semi-Bold Subheader 3 5 6 7 8 9 10 11 Get some Food 12 13 14 15 16 17 18 IBM Plex Sans, s: 24, Semi-Bold Button 1 See a Movie Add Add 19 20 21 22 23 24 25 Get Outside Add button for set up a date Add button for set up a date Location selector on Location selector on IBM Plex Sans, s: 13, Semi-Bold Button 2 Back button 26 27 28 29 30 Sports options (inactive) options (active) map view (current) map view (not-current) Listen to Music IBM Plex Sans, s: 9, Medium Button 3 May Add 6:00 PM 6:00 PM S M T W T F S IBM Plex Sans, s: 14, Medium Body 1 Setup a date button (selected Setup a date button This is an example of a body text paragraph. -
Variable First
Variable first Baptiste Guesnon Designer & Design Technologist at Söderhavet A small text Text with hyphen- ation Gulliver, Gerard Unger, 1993 Screens are variable first Static units Relative units Pica, type points, %, viewport width, pixels, cm… viewport height Why should type be static… …while writing is organic? Century Expanded plomb from 72 pt to 4 pt and putted at a same scale Image by Nick Sherman Through our experience with traditional typesetting methods, we have come to expect that the individual letterforms of a particular typeface should always look the same. This notion is the result of a technical process, not the other way round. However, there is no technical reason for making a digital letter the same every time it is printed. Is Best Really Better, Erik van Blokland & Just van Rossum First published in Emigre magazine issue 18, 1990 Lettering ? Typography Potential of variations in shape a same letter [————— 500 years of type technology evolution —————] Metal / Ink / Paper / Punch & Counterpunch / Pantograph / Linotype & Monotype / etc. Opentype Gutenberg Postscript Photocompo. Variable Fonts Change is the rule in the computer, stability the exception. Jay David Bolter, Writing Space, 1991 Fedra outlines, Typotheque Metafont Postscript Truetype GX Opentype 1.8 (Variable Fonts) Multiple Master Ikarus Fonts HZ Program Webfont Opentype (.woff) Now 1970 1975 1980 1985 1990 1995 2000 2005 2010 Punk/Metafont Beowolf Digital Lettering Donald Knuth Letteror Letteror 1988 1995 2015 HZ-program Indesign glyph scaling glyph scaling Skia, Matthew Carter for Mac OS, 1993 How to make it work? The Stroke, Gerrit Noordzij, 1985 Metafont book, Donald Knuth Kalliculator, 2007, Frederik Berlaen Beowolf, Letteror, 1995 Parametric fonts ≠ Variable fonts Designing instances vs. -
Fira Code: Monospaced Font with Programming Ligatures
Personal Open source Business Explore Pricing Blog Support This repository Sign in Sign up tonsky / FiraCode Watch 282 Star 9,014 Fork 255 Code Issues 74 Pull requests 1 Projects 0 Wiki Pulse Graphs Monospaced font with programming ligatures 145 commits 1 branch 15 releases 32 contributors OFL-1.1 master New pull request Find file Clone or download lf- committed with tonsky Add mintty to the ligatures-unsupported list (#284) Latest commit d7dbc2d 16 days ago distr Version 1.203 (added `__`, closes #120) a month ago showcases Version 1.203 (added `__`, closes #120) a month ago .gitignore - Removed `!!!` `???` `;;;` `&&&` `|||` `=~` (closes #167) `~~~` `%%%` 3 months ago FiraCode.glyphs Version 1.203 (added `__`, closes #120) a month ago LICENSE version 0.6 a year ago README.md Add mintty to the ligatures-unsupported list (#284) 16 days ago gen_calt.clj Removed `/**` `**/` and disabled ligatures for `/*/` `*/*` sequences … 2 months ago release.sh removed Retina weight from webfonts 3 months ago README.md Fira Code: monospaced font with programming ligatures Problem Programmers use a lot of symbols, often encoded with several characters. For the human brain, sequences like -> , <= or := are single logical tokens, even if they take two or three characters on the screen. Your eye spends a non-zero amount of energy to scan, parse and join multiple characters into a single logical one. Ideally, all programming languages should be designed with full-fledged Unicode symbols for operators, but that’s not the case yet. Solution Download v1.203 · How to install · News & updates Fira Code is an extension of the Fira Mono font containing a set of ligatures for common programming multi-character combinations. -

FONT GUIDE Workbook to Help You Find the Right One for Your Brand
FONT GUIDE Workbook to help you find the right one for your brand. www.ottocreative.com.au Choosing the right font for your brand YOUR BRAND VALUES: How different font styles can be used to make up your brand: Logo Typeface: Is usually a bit more special and packed with your brands personality. This font should be used sparingly and kept for special occasions. Headings font: Logo Font This font will reflect the same brand values as your logo font - eg in this example both fonts are feminine and elegant. Headings Unlike your logo typeface, this font should be easier to read and look good a number of different sizes and thicknesses. Body copy Body font: The main rule here is that this font MUST be easy to read, both digitally and for print. If there is already alot going on in your logo and heading font, keep this style simple. Typefaces, common associations & popular font styles San Serif: Clean, Modern, Neutral Try these: Roboto, Open Sans, Lato, Montserrat, Raleway Serif: Classic, Traditional, reliable Try these: Playfair Display, Lora, Source Serif Pro, Prata, Gentium Basic Slab Serif: Youthful, modern, approachable Try these: Roboto Slab, Merriweather, Slabo 27px, Bitter, Arvo Script: Feminine, Romantic, Elegant Try these: Dancing Script, Pacifico, Satisfy, Courgette, Great Vibes Monotype:Simple, Technical, Futuristic Try these: Source Code Pro, Nanum Gothic Coding, Fira Mono, Cutive Mono Handwritten: Authentic, casual, creative Try these: Indie Flower, Shadows into light, Amatic SC, Caveat, Kalam Display: Playful, fun, personality galore Try these: Lobster, Abril Fatface, Luckiest Guy, Bangers, Monoton NOTE: Be careful when using handwritten and display fonts, as they can be hard to read. -

Differences of Fira Sans & Firago
January 2018 FiraGO and Fira Sans – A guide Fira Sans Copyright by bBox Type GmbH 2018 January 2018 FiraGO and Fira Sans – A guide Project History: Fira Sans In 2012, Fira was designed as a typeface for the Mozilla OS in cooperation with Erik Spiekermann and – of course – Mozilla. Over the next years, Fira covered more and more languages and provided further weights and styles. In 2016 (with version 4.2), Mozilla decided not to put effort into the project anymore and in fact quit. Please also note that their Git is not up to date anymore. Since 2016, we encourage the project on our own and therefor introduced a new Git: https://github.com/carrois/Fira Also, recent font files can always be downloaded at: http://bboxtype.com/typefaces/FiraSans Fira Sans 4.3 will be the last version of Fira Sans (except from bug fixing). We decided to go on with a new branch: FiraGO. Copyright by bBox Type GmbH 2018 January 2018 FiraGO and Fira Sans – A guide Status Quo: Fira Sans 4.3 Family structure: Fira Sans Two to Ultra 16 weights Fira Sans TwoItalic to UltraItalic 16 weights Fira Sans Condensed Two to Heavy 15 weights Fira Sans Condensed TwoItalic to HeavyItalic 15 weights Fira Sans Compressed Two to Heavy 15 weights Fira Sans Compressed TwoItalic to HeavyItalic 15 weights Fira Mono Regular Medium Bold 3 weights Script Support: Latin Extended/IPA, Cyrillic Extended, Polytonic Greek ~ 2600 glyphs per font Copyright by bBox Type GmbH 2018 January 2018 FiraGO and Fira Sans – A guide FiraGO Copyright by bBox Type GmbH 2018 January 2018 FiraGO and Fira Sans – A guide Project History: FiraGO In 2016, the geo data provider Here chose Fira Sans as their corporate typeface. -

264 Tugboat, Volume 37 (2016), No. 3 Typographers' Inn Peter Flynn
264 TUGboat, Volume 37 (2016), No. 3 A Typographers’ Inn X LE TEX Peter Flynn Back at the ranch, we have been experimenting with X LE ATEX in our workflow, spurred on by two recent Dashing it off requests to use a specific set of OpenType fonts for A I recently put up a new version of Formatting Infor- some GNU/Linux documentation. X LE TEX offers A mation (http://latex.silmaril.ie), and in the two major improvements on pdfLTEX: the use of section on punctuation I described the difference be- OpenType and TrueType fonts, and the handling of tween hyphens, en rules, em rules, and minus signs. UTF-8 multibyte characters. In particular I explained how to type a spaced Font packages. You can’t easily use the font pack- dash — like that, using ‘dash~---Ђlike’ to put a A ages you use with pdfLTEX because the default font tie before the dash and a normal space afterwards, encoding is EU1 in the fontspec package which is key so that if the dash occurred near a line-break, it to using OTF/TTF fonts, rather than the T1 or OT1 would never end up at the start of a line, only at A conventionally used in pdfLTEX. But late last year the end. I somehow managed to imply that a spaced Herbert Voß kindly posted a list of the OTF/TTF dash was preferable to an unspaced one (probably fonts distributed with TEX Live which have packages because it’s my personal preference, but certainly A of their own for use with X LE TEX [6]. -

Noto Sans Tagalog V3 Documentation
Noto Sans Tagalog v3.0 Documentation & Information FREDRICK R. BRENNAN 2 August 2020 Differences between Noto Sans Tagalog Noto Sans Tagalog v3.0 improves upon v2.0 in the following ways: ● It is a one-axis (weight) variable font with an avar table ● It includes glyph for “ra”, a missing letter, at U+170D ○ Also archaic “ra” at U+171F ● It includes a pamudpod ● It includes alternate hollow kudlit enabled in various ways (salt; cv02; VS1) Overview Tagalog? Noto Sans Tagalog is a font for a script known to The Unicode Standard as “Tagalog”. However, this name is not what the script is known by to Filipinos; Filipinos know it as baybayin or alibata. Baybayin is the name preferred by Philippine scholars, deriving from the Tagalog verb root baybay, meaning “to spell”. The name “Tagalog” was kept as Noto Sans Tagalog is part of the much larger Noto family, and as all the others are named after their respective Unicode blocks, so too should Noto Sans Tagalog. However, the alternate name of “Noto Sans Baybayin” should be understood just as well by your OS to refer to the font, as it’s in the name table. Creation notes Process in a nutshell This was primarily an engineering project and learning experience for me, Fred Brennan, the author of this font. This was my first Google Web Font. It is a requirement of Google that all Google Fonts be built from UFO with fontmake. This is unfortunate as it leads many to use Glyphs to make Google Fonts, which is not what Google wants to promote (I’d hope). -

Typographers'
TUGboat, Volume 39 (2018), No. 1 17 Typographers’ Inn Peter Flynn Fonts and faces and families I suppose we’ve all but given up the unequal strug- gle to distinguish between a family, a face, and a font. I still use the terms separately, out of force of habit, but some work we were doing recently (see ‘X LE ATEX’ below) allowed me to identify many good examples. One family I installed recently (following its announcement on comp.text.tex) was IBM Plex, which is composed of these faces: 1. Plex Serif 12. Plex Sans SemiBold Figure 1: IBM Plex in action 2. Plex Serif ExtraLight 13. Plex Sans Text 3. Plex Serif Light 14. Plex Sans Thin 4. Plex Serif Medium 15. Plex Mono 5. Plex Serif SemiBold 16. Plex Mono ExtraLight 6. Plex Serif Text 17. Plex Mono Light ports. maybe four if we include theses) it’s usually 7. Plex Serif Thin 18. Plex Mono Medium much more important that the choice of typeface 8. Plex Sans 19. Plex Mono SemiBold remains unnoticed. It’s not that the choice is unim- 9. Plex Sans ExtraLight 20. Plex Mono Text portant, but that it’s more subtle than just choosing 10. Plex Sans Light 21. Plex Mono Thin a ‘font’ that you like the look of, although that is 11. Plex Sans Medium obviously part of the decision. In the days of metal type, even the largest print- I numbered them on a slide for a training course ers would have had only a tiny fraction of the type- so that the students could see the seven serif, seven faces available to the average computer user today: sans, and seven monospace components — and with a designer specifying a face not on hand would have luck, understand the distinction — before explaining had to cost-justify the rental of the matrices needed that each one came in the four standard font variants: to cast it, or (in smaller houses) buying sorts in regular, bold, italic, and bold-italic; making 84 in all. -
Part 1: from Truetype GX to Variable Fonts | Monotype
Monotype › Blog › Articles Contact Search Menu Part 1: from TrueType GX to Variable Fonts Tom Rickner, veteran type designer, Category: Articles shares his personal role in the Author: Tom Rickner 29. 11. 2016 beginnings of type’s most exciting development in decades. Share this In August of 2016, four unlikely collaborators in the world of type, fonts and font technology stood on a stage at the ATypI conference in Warsaw, Poland. The collaborators were Apple, Microsoft, Adobe and Google. Together they announced the publishing of OpenType 1.8, an update to the now ubiquitous font standard which was originally an amalgam of Apple & Microsoft’s TrueType, and Adobe’s PostScript font formats. The OpenType 1.8 announcement, ATypI, Warsaw, Poland, September 14, 2016 OpenType 1.8 unveils tremendous new powers of control for type designers, typographers and application developers alike, and it will do so on each of the major operating systems. For those of you who remember Adobe’s Multiple Master format, that technology represented a sliver of the capabilities that will be at your disposal within the new OpenType standard. There were numerous reasons that this announcement was unique, and many have written about this news in these past few months. But for me, the announcement was not only the culmination of months of meetings, private discussions and collaboration with industry colleagues, but it was in fact the rebirth of one of my first collaborations in the font software business, some 25 years earlier. During the late 1980’s and early 1990’s I was a member of the TrueType team at Apple, working within the “Blue” system software group that released the revolutionary System 7 for the Macintosh. -

Variable Fonts in Chrome Webengines Hackfest, Igalia, a Coruña
Variable Fonts in Chrome Webengines Hackfest, Igalia, A Coruña Behdad Esfahbod [email protected] Dominik Röttsches [email protected] Demos ● Responsive Web Typography ● Font Playground ● Underware’s HOI Variable Fonts in CSS Level 4 Fonts font-weight, font-stretch, font-style before font-weight, font-stretch, font-style variable Ranges in @font-face @font-face { font-family: Roboto; font-weight: 700; /* or: 400, 600, 900,... */ font-style: normal; /* or: italic, oblique */ font-stretch: condensed; /* or: expanded, ultra-expanded */ } Ranges in @font-face @font-face { font-family: Roboto; font-weight: 400 700; font-style: 10deg 20deg; font-stretch: 50% 200%; } New Font Style Matching Algorithm ● https://drafts.csswg.org/css-fonts-4/#font-style-matching ● Previously, for a font request: ○ Match font-stretch, font-style, font-weight by traversing keyword values, find closest keyword ● New definition: Search for numerically nearest value ○ As defined by @font-face and ○ Within the range that the variable font allows font-optical-sizing font-variation-settings ● Similar to font-feature-settings ● Sequence of 4 character axis name plus font-variation-settings: ‘wght’ 700, ‘UPWD’ 200; Variable Fonts in Blink New CSS Font Matching Algorithm ● Implements font-stretch, font-style, font-weight matching based on numbers, not based on keywords ● FontTraits replaced with FontSelectionRequest ○ Now storing three FontSelectionValues (numerical values for stretch, style weight) ● FontSelectionCapabilities are storing what the @font-face definition provides -

Brand Identity Guidelines Version 1 June 2019 What We Are About
BRAND IDENTITY GUIDELINES VERSION 1 JUNE 2019 WHAT WE ARE ABOUT THE ALASKA COUNTS The Alaska Counts campaign is CAMPAIGN IS GUIDED BY A MISSION AND VALUES THAT TRUSTWORTHY honest, straightforward INFORM EVERYTHING WE DO AND SAY. INCLUSIVE non-partisan, nondiscriminatory, equitable RESOURCEFUL collaborative, complementary OUR BRAND FUNCTIONS ACCESSIBLE TO SHARE OUR IDENTITY open, approachable, welcoming WITH THE WORLD; WE COMMUNICATE POWERFULLY AND CONSISTENTLY. The Alaska Counts campaign’s goal is TO ENSURE A COMPLETE AND ACCURATE COUNT OF ALL ALASKANS ALASKA COUNTS INTRODUCTION 2 LOGO A BRAND IS MUCH MORE THAN A LOGO. IT IS A COLLECTION OF RELATIONSHIPS. IT EXPLAINS WHAT DRIVES US, WHAT WE BELIEVE IN, WHY WE EXIST. THESE THINGS ARE NOT FROZEN IN TIME. 3 LOGO THE ALASKA COUNTS LOGOMARK IS SIMPLE, MAIN TYPE GRAPHICAL SPEAK ELEMENT CLEAR. IT INCORPORATES A SECONDARY TYPE GRAPHICAL SPEAK ELEMENT. STATE OF ALASKA TO ENGAGE, ENCOURAGE, AND ENSURE SELF-RESPONSE AND PARTICIPATION. LOCAL BACKGROUND COLOR - WHITE VOICES OF LEADERSHIP ARE CRITICAL TO ACHIEVING AN ACCURATE COUNT IN 2020. BACKGROUND COLOR - LIGHT COLOR BACKGROUND COLOR - DARK COLOR ALASKA COUNTS LOGO 4 LOGO CLEARSPACE & SIZE TO MAXIMIZE THE BRAND’S THE DISTANCE MARKED X REPRESENTS THE HEIGHT X PRESENCE AND VISUAL OF THE ‘A’ IN THE TYPE ALASKA. THE FORMULA STANDOUT, THERE IS SHOWN OPPOSITE APPLIES A DEFINED MINIMUM TO ALL SIZES OF BRANDMARK REPRODUCTION. CLEAR SPACE AREA. THIS X CLEAR ZONE AROUND THE X X BRANDMARK DEFINES THE AREA INTO WHICH NO OTHER GRAPHIC ELEMENTS, SUCH AS TEXT, IMAGERY OR OTHER BRANDMARKS CAN INTRUDE. FOR EASE OF RECOGNITION, A MINIMUM SIZE HAS BEEN SET FOR THE DIFFERENT VERSIONS OF THE BRANDMARK, IN ORDER TO ASSURE SUCCESSFUL REPRODUCTION. -
Microsoft Core Fonts Package Post-Installation to Obtain a Proper Type Library
AP�������F��� ��� O���S�����T������� �� �� �������� ���� �� �� ��� ������ ��� ���������� �� ���� �� the development of libre ecosystems. Typography has always been a stubborn holdout in this regard, and to this day there remain few free high-quality comprehensive text typefaces. Free type is mainly concentrated in a handful of flagship “superfonts” that contain a staggering catalog of glyphs, but lack greatly in the quality of design and typographic styles and features seen in professional type. To my knowledge, there are currently just two great open source text families—Gentium, which is still incomplete, and Linux Libertine, in addition to a few corporate gifts such as Adobe Source Serif and Bitstream Charter. To help fill the gap, I present my own original type design and ask for the Wikimedia projects’ help in finishing and releasing my font to provide a quality free font choice. What is this font? ��� ���� � �� ��������� (��� ���� ��� ��� ��������� ������� 0 1 2 3 4 5 6 7 8 9 this paragraph in) is meant to be an original serif typeface that an editor might want to set a textbook in. It does not yet have an official name. Many existing open source typefaces are clones of 0 1 2 3 4 5 6 7 8 9 popular old public domain typefaces (like Asana, S���, EB Garamond, or Free Serif, which are clones of Palatino, Times, Garamond, and Times again, respectively). Others like Liberation Serif, Déjà Vu, and Droid Serif have a distinctive “computer type” style that makes them convenient for pixel display and easy to HQWinâaba construct and adapt but poor in most other regards. I tried to create something different.