Human MED11 Peptide (DAG-P0814) This Product Is for Research Use Only and Is Not Intended for Diagnostic Use
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Mediator Head Subcomplex Med11/22 Contains a Common Helix Bundle
Published online 15 April 2011 Nucleic Acids Research, 2011, Vol. 39, No. 14 6291–6304 doi:10.1093/nar/gkr229 Mediator head subcomplex Med11/22 contains a common helix bundle building block with a specific function in transcription initiation complex stabilization Martin Seizl, Laurent Larivie` re, Toni Pfaffeneder, Larissa Wenzeck and Patrick Cramer* Gene Center and Department of Biochemistry, Center for Integrated Protein Science Munich (CIPSM), Ludwig-Maximilians-Universita¨ t (LMU) Mu¨ nchen, Feodor-Lynen-Strasse 25, 81377 Munich, Germany Received February 24, 2011; Revised and Accepted March 29, 2011 ABSTRACT Mediator undergoes conformational changes, which trig- Mediator is a multiprotein co-activator of RNA poly- ger its interaction with Pol II and promote pre-initiation merase (Pol) II transcription. Mediator contains a complex (PIC) formation (7). Mediator was purified from yeast (8,9), metazoans conserved core that comprises the ‘head’ and (10,11) and plants (12). Comparative genomics identified ‘middle’ modules. We present here a structure– an ancient 17-subunit Mediator core that is conserved function analysis of the essential Med11/22 hetero- in eukaryotes (13,14). Mediator from the yeast dimer, a part of the head module. Med11/22 forms a Saccharomyces cerevisiae (Sc) is a 1.4 MDa multiprotein conserved four-helix bundle domain with C-terminal complex comprising 25 subunits, of which 11 are essential extensions, which bind the central head subunit and 22 are at least partially conserved. Based on electron Med17. A highly conserved patch on the bundle microscopy and biochemical analysis, mediator subunits surface is required for stable transcription pre- were suggested to reside in four flexibly linked modules, initiation complex formation on a Pol II promoter the head, middle, tail and kinase module (15–17). -

Analysis of Gene Expression Data for Gene Ontology
ANALYSIS OF GENE EXPRESSION DATA FOR GENE ONTOLOGY BASED PROTEIN FUNCTION PREDICTION A Thesis Presented to The Graduate Faculty of The University of Akron In Partial Fulfillment of the Requirements for the Degree Master of Science Robert Daniel Macholan May 2011 ANALYSIS OF GENE EXPRESSION DATA FOR GENE ONTOLOGY BASED PROTEIN FUNCTION PREDICTION Robert Daniel Macholan Thesis Approved: Accepted: _______________________________ _______________________________ Advisor Department Chair Dr. Zhong-Hui Duan Dr. Chien-Chung Chan _______________________________ _______________________________ Committee Member Dean of the College Dr. Chien-Chung Chan Dr. Chand K. Midha _______________________________ _______________________________ Committee Member Dean of the Graduate School Dr. Yingcai Xiao Dr. George R. Newkome _______________________________ Date ii ABSTRACT A tremendous increase in genomic data has encouraged biologists to turn to bioinformatics in order to assist in its interpretation and processing. One of the present challenges that need to be overcome in order to understand this data more completely is the development of a reliable method to accurately predict the function of a protein from its genomic information. This study focuses on developing an effective algorithm for protein function prediction. The algorithm is based on proteins that have similar expression patterns. The similarity of the expression data is determined using a novel measure, the slope matrix. The slope matrix introduces a normalized method for the comparison of expression levels throughout a proteome. The algorithm is tested using real microarray gene expression data. Their functions are characterized using gene ontology annotations. The results of the case study indicate the protein function prediction algorithm developed is comparable to the prediction algorithms that are based on the annotations of homologous proteins. -

Structure and Mechanism of the RNA Polymerase II Transcription Machinery
Downloaded from genesdev.cshlp.org on October 9, 2021 - Published by Cold Spring Harbor Laboratory Press REVIEW Structure and mechanism of the RNA polymerase II transcription machinery Allison C. Schier and Dylan J. Taatjes Department of Biochemistry, University of Colorado, Boulder, Colorado 80303, USA RNA polymerase II (Pol II) transcribes all protein-coding ingly high resolution, which has rapidly advanced under- genes and many noncoding RNAs in eukaryotic genomes. standing of the molecular basis of Pol II transcription. Although Pol II is a complex, 12-subunit enzyme, it lacks Structural biology continues to transform our under- the ability to initiate transcription and cannot consistent- standing of complex biological processes because it allows ly transcribe through long DNA sequences. To execute visualization of proteins and protein complexes at or near these essential functions, an array of proteins and protein atomic-level resolution. Combined with mutagenesis and complexes interact with Pol II to regulate its activity. In functional assays, structural data can at once establish this review, we detail the structure and mechanism of how enzymes function, justify genetic links to human dis- over a dozen factors that govern Pol II initiation (e.g., ease, and drive drug discovery. In the past few decades, TFIID, TFIIH, and Mediator), pausing, and elongation workhorse techniques such as NMR and X-ray crystallog- (e.g., DSIF, NELF, PAF, and P-TEFb). The structural basis raphy have been complemented by cryoEM, cross-linking for Pol II transcription regulation has advanced rapidly mass spectrometry (CXMS), and other methods. Recent in the past decade, largely due to technological innova- improvements in data collection and imaging technolo- tions in cryoelectron microscopy. -

Produktinformation
Produktinformation Diagnostik & molekulare Diagnostik Laborgeräte & Service Zellkultur & Verbrauchsmaterial Forschungsprodukte & Biochemikalien Weitere Information auf den folgenden Seiten! See the following pages for more information! Lieferung & Zahlungsart Lieferung: frei Haus Bestellung auf Rechnung SZABO-SCANDIC Lieferung: € 10,- HandelsgmbH & Co KG Erstbestellung Vorauskassa Quellenstraße 110, A-1100 Wien T. +43(0)1 489 3961-0 Zuschläge F. +43(0)1 489 3961-7 [email protected] • Mindermengenzuschlag www.szabo-scandic.com • Trockeneiszuschlag • Gefahrgutzuschlag linkedin.com/company/szaboscandic • Expressversand facebook.com/szaboscandic SANTA CRUZ BIOTECHNOLOGY, INC. Med11 CRISPR/Cas9 KO Plasmid (m): sc-425866 BACKGROUND APPLICATIONS The Clustered Regularly Interspaced Short Palindromic Repeats (CRISPR) and Med11 CRISPR/Cas9 KO Plasmid (m) is recommended for the disruption of CRISPR-associated protein (Cas9) system is an adaptive immune response gene expression in mouse cells. defense mechanism used by archea and bacteria for the degradation of foreign genetic material (4,6). This mechanism can be repurposed for other 20 nt non-coding RNA sequence: guides Cas9 functions, including genomic engineering for mammalian systems, such as to a specific target location in the genomic DNA gene knockout (KO) (1,2,3,5). CRISPR/Cas9 KO Plasmid products enable the U6 promoter: drives gRNA scaffold: helps Cas9 identification and cleavage of specific genes by utilizing guide RNA (gRNA) expression of gRNA bind to target DNA sequences derived from the Genome-scale CRISPR Knock-Out (GeCKO) v2 library developed in the Zhang Laboratory at the Broad Institute (3,5). Termination signal Green Fluorescent Protein: to visually REFERENCES verify transfection CRISPR/Cas9 Knockout Plasmid CBh (chicken β-Actin 1. Cong, L., et al. -

Universidade De São Paulo Faculdade De Zootecnia E Engenharia De Alimentos
UNIVERSIDADE DE SÃO PAULO FACULDADE DE ZOOTECNIA E ENGENHARIA DE ALIMENTOS LAÍS GRIGOLETTO Genomic studies in Montana Tropical Composite cattle Pirassununga 2020 LAIS GRIGOLETTO Genomic studies in Montana Tropical Composite cattle Versão Corrigida Thesis submitted to the College of Animal Science and Food Engineering, University of São Paulo in partial fulfillment of the requirements for the degree of Doctor in Science from the Animal Biosciences program. Concentration area: Genetics, Molecular and Cellular Biology Supervisor: Prof. Dr. José Bento Sterman Ferraz Co-supervisor: Prof. Dr. Fernando Baldi Pirassununga 2020 Ficha catalográfica elaborada pelo Serviço de Biblioteca e Informação, FZEA/USP, com os dados fornecidos pelo(a) autor(a) Grigoletto, Laís G857g Genomic studies in Montana Tropical Composite cattle / Laís Grigoletto ; orientador José Bento Sterman Ferraz ; coorientador Fernando Baldi. -- Pirassununga, 2020. 183 f. Tese (Doutorado - Programa de Pós-Graduação em Biociência Animal) -- Faculdade de Zootecnia e Engenharia de Alimentos, Universidade de São Paulo. 1. beef cattle. 2. composite. 3. genomics. 4. imputation. 5. genetic progress. I. Ferraz, José Bento Sterman, orient. II. Baldi, Fernando, coorient. III. Título. Permitida a cópia total ou parcial deste documento, desde que citada a fonte - o autor UNIVERSIDADE DE SÃO PAULO Faculdade de Zootecnia e Engenharia de Alimentos Comissão de Ética no Uso de Animais DISPENSA DE ANÁLISE ÉTICA Comunicamos que o projeto de pesquisa abaixo identificado está dispensado da análise ética por utilizar animais oriundos de coleções biológicas formadas anteriormente ao ano de 2008, ano da promulgação da Lei nº 11.794/2008 – lei que estabelece procedimentos para o uso científico de animais. Ressaltamos que atividades realizadas na vigência da referida lei, ou que resulte em incremento do acervo biológico, devem ser submetidas à análise desta CEUA conforme disposto pelo Conselho Nacional de Controle de Experimentação Animal (CONCEA). -

Quantitative Trait Loci Mapping of Macrophage Atherogenic Phenotypes
QUANTITATIVE TRAIT LOCI MAPPING OF MACROPHAGE ATHEROGENIC PHENOTYPES BRIAN RITCHEY Bachelor of Science Biochemistry John Carroll University May 2009 submitted in partial fulfillment of requirements for the degree DOCTOR OF PHILOSOPHY IN CLINICAL AND BIOANALYTICAL CHEMISTRY at the CLEVELAND STATE UNIVERSITY December 2017 We hereby approve this thesis/dissertation for Brian Ritchey Candidate for the Doctor of Philosophy in Clinical-Bioanalytical Chemistry degree for the Department of Chemistry and the CLEVELAND STATE UNIVERSITY College of Graduate Studies by ______________________________ Date: _________ Dissertation Chairperson, Johnathan D. Smith, PhD Department of Cellular and Molecular Medicine, Cleveland Clinic ______________________________ Date: _________ Dissertation Committee member, David J. Anderson, PhD Department of Chemistry, Cleveland State University ______________________________ Date: _________ Dissertation Committee member, Baochuan Guo, PhD Department of Chemistry, Cleveland State University ______________________________ Date: _________ Dissertation Committee member, Stanley L. Hazen, MD PhD Department of Cellular and Molecular Medicine, Cleveland Clinic ______________________________ Date: _________ Dissertation Committee member, Renliang Zhang, MD PhD Department of Cellular and Molecular Medicine, Cleveland Clinic ______________________________ Date: _________ Dissertation Committee member, Aimin Zhou, PhD Department of Chemistry, Cleveland State University Date of Defense: October 23, 2017 DEDICATION I dedicate this work to my entire family. In particular, my brother Greg Ritchey, and most especially my father Dr. Michael Ritchey, without whose support none of this work would be possible. I am forever grateful to you for your devotion to me and our family. You are an eternal inspiration that will fuel me for the remainder of my life. I am extraordinarily lucky to have grown up in the family I did, which I will never forget. -
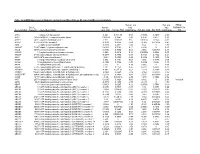
Mrna Expression in Human Leiomyoma and Eker Rats As Measured by Microarray Analysis
Table 3S: mRNA Expression in Human Leiomyoma and Eker Rats as Measured by Microarray Analysis Human_avg Rat_avg_ PENG_ Entrez. Human_ log2_ log2_ RAPAMYCIN Gene.Symbol Gene.ID Gene Description avg_tstat Human_FDR foldChange Rat_avg_tstat Rat_FDR foldChange _DN A1BG 1 alpha-1-B glycoprotein 4.982 9.52E-05 0.68 -0.8346 0.4639 -0.38 A1CF 29974 APOBEC1 complementation factor -0.08024 0.9541 -0.02 0.9141 0.421 0.10 A2BP1 54715 ataxin 2-binding protein 1 2.811 0.01093 0.65 0.07114 0.954 -0.01 A2LD1 87769 AIG2-like domain 1 -0.3033 0.8056 -0.09 -3.365 0.005704 -0.42 A2M 2 alpha-2-macroglobulin -0.8113 0.4691 -0.03 6.02 0 1.75 A4GALT 53947 alpha 1,4-galactosyltransferase 0.4383 0.7128 0.11 6.304 0 2.30 AACS 65985 acetoacetyl-CoA synthetase 0.3595 0.7664 0.03 3.534 0.00388 0.38 AADAC 13 arylacetamide deacetylase (esterase) 0.569 0.6216 0.16 0.005588 0.9968 0.00 AADAT 51166 aminoadipate aminotransferase -0.9577 0.3876 -0.11 0.8123 0.4752 0.24 AAK1 22848 AP2 associated kinase 1 -1.261 0.2505 -0.25 0.8232 0.4689 0.12 AAMP 14 angio-associated, migratory cell protein 0.873 0.4351 0.07 1.656 0.1476 0.06 AANAT 15 arylalkylamine N-acetyltransferase -0.3998 0.7394 -0.08 0.8486 0.456 0.18 AARS 16 alanyl-tRNA synthetase 5.517 0 0.34 8.616 0 0.69 AARS2 57505 alanyl-tRNA synthetase 2, mitochondrial (putative) 1.701 0.1158 0.35 0.5011 0.6622 0.07 AARSD1 80755 alanyl-tRNA synthetase domain containing 1 4.403 9.52E-05 0.52 1.279 0.2609 0.13 AASDH 132949 aminoadipate-semialdehyde dehydrogenase -0.8921 0.4247 -0.12 -2.564 0.02993 -0.32 AASDHPPT 60496 aminoadipate-semialdehyde -

Table S1. 103 Ferroptosis-Related Genes Retrieved from the Genecards
Table S1. 103 ferroptosis-related genes retrieved from the GeneCards. Gene Symbol Description Category GPX4 Glutathione Peroxidase 4 Protein Coding AIFM2 Apoptosis Inducing Factor Mitochondria Associated 2 Protein Coding TP53 Tumor Protein P53 Protein Coding ACSL4 Acyl-CoA Synthetase Long Chain Family Member 4 Protein Coding SLC7A11 Solute Carrier Family 7 Member 11 Protein Coding VDAC2 Voltage Dependent Anion Channel 2 Protein Coding VDAC3 Voltage Dependent Anion Channel 3 Protein Coding ATG5 Autophagy Related 5 Protein Coding ATG7 Autophagy Related 7 Protein Coding NCOA4 Nuclear Receptor Coactivator 4 Protein Coding HMOX1 Heme Oxygenase 1 Protein Coding SLC3A2 Solute Carrier Family 3 Member 2 Protein Coding ALOX15 Arachidonate 15-Lipoxygenase Protein Coding BECN1 Beclin 1 Protein Coding PRKAA1 Protein Kinase AMP-Activated Catalytic Subunit Alpha 1 Protein Coding SAT1 Spermidine/Spermine N1-Acetyltransferase 1 Protein Coding NF2 Neurofibromin 2 Protein Coding YAP1 Yes1 Associated Transcriptional Regulator Protein Coding FTH1 Ferritin Heavy Chain 1 Protein Coding TF Transferrin Protein Coding TFRC Transferrin Receptor Protein Coding FTL Ferritin Light Chain Protein Coding CYBB Cytochrome B-245 Beta Chain Protein Coding GSS Glutathione Synthetase Protein Coding CP Ceruloplasmin Protein Coding PRNP Prion Protein Protein Coding SLC11A2 Solute Carrier Family 11 Member 2 Protein Coding SLC40A1 Solute Carrier Family 40 Member 1 Protein Coding STEAP3 STEAP3 Metalloreductase Protein Coding ACSL1 Acyl-CoA Synthetase Long Chain Family Member 1 Protein -

Rare DNA Copy Number Variants in Cardiovascular Malformations with Extracardiac Abnormalities
European Journal of Human Genetics (2013) 21, 173–181 & 2013 Macmillan Publishers Limited All rights reserved 1018-4813/13 www.nature.com/ejhg ARTICLE Rare DNA copy number variants in cardiovascular malformations with extracardiac abnormalities Seema R Lalani*,1,10,11, Chad Shaw1,11, Xueqing Wang1,10, Ankita Patel1, Lance W Patterson2, Katarzyna Kolodziejska1, Przemyslaw Szafranski1, Zhishuo Ou1,QiTian1, Sung-Hae L Kang1, Amina Jinnah1, Sophia Ali3, Aamir Malik4, Patricia Hixson1, Lorraine Potocki1, James R Lupski1, Pawel Stankiewicz1, Carlos A Bacino1, Brian Dawson1, Arthur L Beaudet1, Fatima M Boricha5, Runako Whittaker6, Chumei Li7, Stephanie M Ware8, Sau Wai Cheung1, Daniel J Penny2, John Lynn Jefferies9 and John W Belmont1,10 Clinically significant cardiovascular malformations (CVMs) occur in 5–8 per 1000 live births. Recurrent copy number variations (CNVs) are among the known causes of syndromic CVMs, accounting for an important fraction of cases. We hypothesized that many additional rare CNVs also cause CVMs and can be detected in patients with CVMs plus extracardiac anomalies (ECAs). Through a genome-wide survey of 203 subjects with CVMs and ECAs, we identified 55 CNVs 450 kb in length that were not present in children without known cardiovascular defects (n ¼ 872). Sixteen unique CNVs overlapping these variants were found in an independent CVM plus ECA cohort (n ¼ 511), which were not observed in 2011 controls. The study identified 12/16 (75%) novel loci including non-recurrent de novo 16q24.3 loss (4/714) and de novo 2q31.3q32.1 loss encompassing PPP1R1C and PDE1A (2/714). The study also narrowed critical intervals in three well-recognized genomic disorders of CVM, such as the cat-eye syndrome region on 22q11.1, 8p23.1 loss encompassing GATA4 and SOX7, and 17p13.3-p13.2 loss. -
Integrated Functional Genomic Analysis Enables Annotation of Kidney Genome-Wide Association Study Loci
BASIC RESEARCH www.jasn.org Integrated Functional Genomic Analysis Enables Annotation of Kidney Genome-Wide Association Study Loci Karsten B. Sieber,1 Anna Batorsky,2 Kyle Siebenthall,2 Kelly L. Hudkins,3 Jeff D. Vierstra,2 Shawn Sullivan,4 Aakash Sur,4,5 Michelle McNulty,6 Richard Sandstrom,2 Alex Reynolds,2 Daniel Bates,2 Morgan Diegel,2 Douglass Dunn,2 Jemma Nelson,2 Michael Buckley,2 Rajinder Kaul,2 Matthew G. Sampson,6 Jonathan Himmelfarb,7,8 Charles E. Alpers,3,8 Dawn Waterworth,1 and Shreeram Akilesh3,8 Due to the number of contributing authors, the affiliations are listed at the end of this article. ABSTRACT Background Linking genetic risk loci identified by genome-wide association studies (GWAS) to their causal genes remains a major challenge. Disease-associated genetic variants are concentrated in regions con- taining regulatory DNA elements, such as promoters and enhancers. Although researchers have previ- ously published DNA maps of these regulatory regions for kidney tubule cells and glomerular endothelial cells, maps for podocytes and mesangial cells have not been available. Methods We generated regulatory DNA maps (DNase-seq) and paired gene expression profiles (RNA-seq) from primary outgrowth cultures of human glomeruli that were composed mainly of podo- cytes and mesangial cells. We generated similar datasets from renal cortex cultures, to compare with those of the glomerular cultures. Because regulatory DNA elements can act on target genes across large genomic distances, we also generated a chromatin conformation map from freshly isolated human glomeruli. Results We identified thousands of unique regulatory DNA elements, many located close to transcription factor genes, which the glomerular and cortex samples expressed at different levels. -

Collaborative Rewiring of the Pluripotency Network by Chromatin and Signalling Modulating Pathways
ARTICLE Received 1 Dec 2014 | Accepted 30 Dec 2014 | Published 4 Feb 2015 DOI: 10.1038/ncomms7188 OPEN Collaborative rewiring of the pluripotency network by chromatin and signalling modulating pathways Khoa A. Tran1,2, Steven A. Jackson1, Zachariah P.G. Olufs1, Nur Zafirah Zaidan1, Ning Leng3, Christina Kendziorski4, Sushmita Roy1,4 & Rupa Sridharan1,5 Reprogramming of somatic cells to induced pluripotent stem cells (iPSCs) represents a profound change in cell fate. Here, we show that combining ascorbic acid (AA) and 2i (MAP kinase and GSK inhibitors) increases the efficiency of reprogramming from fibroblasts and synergistically enhances conversion of partially reprogrammed intermediates to the iPSC state. AA and 2i induce differential transcriptional responses, each leading to the activation of specific pluripotency loci. A unique cohort of pluripotency genes including Esrrb require both stimuli for activation. Temporally, AA-dependent histone demethylase effects are important early, whereas Tet enzyme effects are required throughout the conversion. 2i function could partially be replaced by depletion of components of the epidermal growth factor (EGF) and insulin growth factor pathways, indicating that they act as barriers to reprogramming. Accordingly, reduction in the levels of the EGF receptor gene contributes to the activation of Esrrb. These results provide insight into the rewiring of the pluripotency network at the late stage of reprogramming. 1 Wisconsin Institute for Discovery, University of Wisconsin, Madison, 330 N. Orchard Street, Room 2118, Wisconsin 53715, USA. 2 Molecular and Cellular Pharmacology Program, University of Wisconsin, Madison, 330 N. Orchard Street, Room 2118, Wisconsin 53715, USA. 3 Department of Statistics, University of Wisconsin, Madison, 330 N. -

Rabbit Anti-Cyclin C/FITC Conjugated Antibody-SL0282R-FITC
SunLong Biotech Co.,LTD Tel: 0086-571- 56623320 Fax:0086-571- 56623318 E-mail:[email protected] www.sunlongbiotech.com Rabbit Anti-Cyclin C/FITC Conjugated antibody SL0282R-FITC Product Name: Anti-Cyclin C/FITC Chinese Name: FITC标记的周期素C抗体 CCNC; Cyclin-C; CycC; Cyclin C; hSRB11; SRB11 homolog; Alias: OTTHUMP00000016897; CCNC_HUMAN. Organism Species: Rabbit Clonality: Polyclonal React Species: Human,Mouse,Rat, IF=1:50-200 Applications: not yet tested in other applications. optimal dilutions/concentrations should be determined by the end user. Molecular weight: 33kDa Form: Lyophilized or Liquid Concentration: 1mg/ml immunogen: KLH conjugated synthetic peptide derived from human Cyclin C C-terminus Lsotype: IgG Purification: affinity purified by Protein A Storage Buffer: 0.01M TBS(pH7.4) with 1% BSA, 0.03% Proclin300 and 50% Glycerol. Storewww.sunlongbiotech.com at -20 °C for one year. Avoid repeated freeze/thaw cycles. The lyophilized antibody is stable at room temperature for at least one month and for greater than a year Storage: when kept at -20°C. When reconstituted in sterile pH 7.4 0.01M PBS or diluent of antibody the antibody is stable for at least two weeks at 2-4 °C. background: Cyclin C was originally identified by a genetic screen for human and Drosophila cDNAs that complement a triple knock out of the CLN genes in Saccharomyces cerevisiae. Cyclin C is a nuclear protein present in a multiprotein complex. It interacts Product Detail: both in vitro and in vivo with cdk 8, a novel protein kinase of the cdk family. It is suggested that cyclin C and cdk 8 control RNA polymerase II function.