Analysis of Gene Expression Data for Gene Ontology
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Dominantly Acting Variants in ARF3 Have Disruptive Consequences on Golgi Integrity and Cause Microcephaly Recapitulated in Zebra�Sh
Dominantly acting variants in ARF3 have disruptive consequences on Golgi integrity and cause microcephaly recapitulated in zebrash Giulia Fasano Ospedale Pediatrico Bambino Gesù Valentina Muto Ospedale Pediatrico Bambino Gesù Francesca Clementina Radio Genetic and Rare Disease Research Division, Bambino Gesù Children's Hospital IRCCS, Rome, Italy https://orcid.org/0000-0003-1993-8018 Martina Venditti Ospedale Pediatrico Bambino Gesù Alban Ziegler Département de Génétique, CHU d’Angers Giovanni Chillemi Tuscia University https://orcid.org/0000-0003-3901-6926 Annalisa Vetro Pediatric Neurology, Neurogenetics and Neurobiology Unit and Laboratories, Meyer Children’s Hospital, University of Florence Francesca Pantaleoni https://orcid.org/0000-0003-0765-9281 Simone Pizzi Bambino Gesù Children's Hospital Libenzio Conti Ospedale Pediatrico Bambino Gesù, IRCCS, 00146 Rome https://orcid.org/0000-0001-9466-5473 Stefania Petrini Bambino Gesù Children's Hospital Simona Coppola Istituto Superiore di Sanità Alessandro Bruselles Istituto Superiore di Sanità https://orcid.org/0000-0002-1556-4998 Ingrid Guarnetti Prandi University of Pisa, 56124 Pisa, Italy Balasubramanian Chandramouli Super Computing Applications and Innovation, CINECA Magalie Barth Céline Bris Département de Génétique, CHU d’Angers Donatella Milani Fondazione IRCCS Ca' Granda Ospedale Maggiore Policlinico Angelo Selicorni ASST Lariana Marina Macchiaiolo Ospedale Pediatrico Bambino Gesù, IRCCS Michaela Gonantini Ospedale Pediatrico Bambino Gesù, IRCCS Andrea Bartuli Bambino Gesù Children's -

A New Genetic Method for Isolating Functionally Interacting Genes
Copyright 2000 by the Genetics Society of America A New Genetic Method for Isolating Functionally Interacting Genes: High plo1؉-Dependent Mutants and Their Suppressors De®ne Genes in Mitotic and Septation Pathways in Fission Yeast C. Fiona Cullen,*,² Karen M. May,* Iain M. Hagan,³ David M. Glover²,§ and Hiroyuki Ohkura*,² *Institute of Cell and Molecular Biology, The University of Edinburgh, Edinburgh EH9 3JR, United Kingdom, ²Department of Anatomy and Physiology, Medical Sciences Institute, The University of Dundee, Dundee DD1 4HN, United Kingdom, ³School of Biological Sciences, The University of Manchester, Manchester M13 9PT, United Kingdom and §Department of Genetics, University of Cambridge, Cambridge CB2 3EH, United Kingdom Manuscript received February 2, 2000 Accepted for publication April 10, 2000 ABSTRACT We describe a general genetic method to identify genes encoding proteins that functionally interact with and/or are good candidates for downstream targets of a particular gene product. The screen identi®es mutants whose growth depends on high levels of expression of that gene. We apply this to the plo1ϩ gene that encodes a ®ssion yeast homologue of the polo-like kinases. plo1ϩ regulates both spindle formation and septation. We have isolated 17 high plo1ϩ-dependent (pld) mutants that show defects in mitosis or septation. Three mutants show a mitotic arrest phenotype. Among the 14 pld mutants with septation defects, 12 mapped to known loci: cdc7, cdc15, cdc11 spg1, and sid2. One of the pld mutants, cdc7-PD1, was selected for suppressor analysis. As multicopy suppressors, we isolated four known genes involved in septation in ®ssion yeast: spg1ϩ, sce3ϩ, cdc8ϩ, and rho1ϩ, and two previously uncharacterized genes, mpd1ϩ and mpd2ϩ. -

Annexina7 and CAP1 Are Associated with Regulating Tumor Cell Adhesion Molecule Expression and Biological Behavior
AnnexinA7 and CAP1 are associated with regulating tumor cell adhesion molecule expression and biological behavior Type Research paper Keywords hepatocellular carcinoma, adhesion molecule, AnnexinA7, CAP1, Biological behaviors Abstract Introduction To find out the correlations between the effects of down-regulating AnnexinA7 and CAP1 gene on cell adhesion factors and the biological behavior of Hca-p cells cells, and finally infer the relationship between the two genes. Material and methods Western blot ,qRT-PCR,immunocytochemistry, CCK8 cell proliferation, flow cytometry, lymph node adhesion and transwell chamber assay testing . Results AnnexinA7 and CAP1 were consistent with the regulation of the expression of the adhesion molecules such as FAK, Src, Paxillin and E-cadherin. At the mRNA and protein levels, the expression of FAK, Src and Paxillin were increased with down-regulated AnnexinA7 and CAP1 genes, while E-cadherin was down-regulated in the change of these two genes. And the low expression of AnnexinA7 could affect the expression of CAP1 in mRNA and protein levels. otherwise, the localization of AnnexinA7 and CAP1 in hepatocellular carcinoma cells was also the same. After down-regulating the expression of CAP1, the functions of proliferation, lymph node adhesion and invasion were increased and earlyPreprint apoptotic ability was decreased in Hca-P cells. Conclusions AnnexinA7 and CAP1 could control the expression of these adhesion molecules in the same trend. We speculated they may be co-localization. And AnnexinA7 gene may be related to the molecular mechanism of CAP1 gene, which is likely to have a consistent effect on cell adhesion molecules and be closely related to the biological behaviors of Hca-P cells.AnnexinA7 and CAP1 may play an inhibitory role in lymph node metastasis to provide a reliable basis for the early identification of lymphatic metastasis in hepatocellular carcinoma. -

Molecular and Physiological Basis for Hair Loss in Near Naked Hairless and Oak Ridge Rhino-Like Mouse Models: Tracking the Role of the Hairless Gene
University of Tennessee, Knoxville TRACE: Tennessee Research and Creative Exchange Doctoral Dissertations Graduate School 5-2006 Molecular and Physiological Basis for Hair Loss in Near Naked Hairless and Oak Ridge Rhino-like Mouse Models: Tracking the Role of the Hairless Gene Yutao Liu University of Tennessee - Knoxville Follow this and additional works at: https://trace.tennessee.edu/utk_graddiss Part of the Life Sciences Commons Recommended Citation Liu, Yutao, "Molecular and Physiological Basis for Hair Loss in Near Naked Hairless and Oak Ridge Rhino- like Mouse Models: Tracking the Role of the Hairless Gene. " PhD diss., University of Tennessee, 2006. https://trace.tennessee.edu/utk_graddiss/1824 This Dissertation is brought to you for free and open access by the Graduate School at TRACE: Tennessee Research and Creative Exchange. It has been accepted for inclusion in Doctoral Dissertations by an authorized administrator of TRACE: Tennessee Research and Creative Exchange. For more information, please contact [email protected]. To the Graduate Council: I am submitting herewith a dissertation written by Yutao Liu entitled "Molecular and Physiological Basis for Hair Loss in Near Naked Hairless and Oak Ridge Rhino-like Mouse Models: Tracking the Role of the Hairless Gene." I have examined the final electronic copy of this dissertation for form and content and recommend that it be accepted in partial fulfillment of the requirements for the degree of Doctor of Philosophy, with a major in Life Sciences. Brynn H. Voy, Major Professor We have read this dissertation and recommend its acceptance: Naima Moustaid-Moussa, Yisong Wang, Rogert Hettich Accepted for the Council: Carolyn R. -

CCT2 Antibody A
Revision 5 C 0 2 - t CCT2 Antibody a e r o t S Orders: 877-616-CELL (2355) [email protected] Support: 877-678-TECH (8324) 1 6 Web: [email protected] 5 www.cellsignal.com 3 # 3 Trask Lane Danvers Massachusetts 01923 USA For Research Use Only. Not For Use In Diagnostic Procedures. Applications: Reactivity: Sensitivity: MW (kDa): Source: UniProt ID: Entrez-Gene Id: WB, IP H M R Mk Endogenous 54 Rabbit P78371 10576 Product Usage Information 6. McCormack, E.A. et al. (2001) J Struct Biol 135, 198-204. Application Dilution Western Blotting 1:1000 Immunoprecipitation 1:100 Storage Supplied in 10 mM sodium HEPES (pH 7.5), 150 mM NaCl, 100 µg/ml BSA and 50% glycerol. Store at –20°C. Do not aliquot the antibody. Specificity / Sensitivity CCT2 Antibody detects endogenous levels of total CCT2 protein. Species Reactivity: Human, Mouse, Rat, Monkey Source / Purification Polyclonal antibodies are produced by immunizing animals with a synthetic peptide corresponding to human CCT2. Antibodies are purified by protein A and peptide affinity chromatography. Background CCT2 is one of eight largely unrelated subunit proteins found in a protein chaperone complex known as the chaperonin-containing TCP-1 (CCT) or TRiC complex. The CCT complex is an abundanct cytoslic component that is credited with helping newly synthesized polypeptides adopt the correct conformation (1). Proteins that fold and assemble with the help of CCT include the cytoskeletal proteins actin and tubulin as well as up to 15% of newly synthesized eukaryotic proteins (2). CCT2 is the β-subunit of the chaperone complex and is one of several CCT proteins that exhibit increased expression in response to stress. -

Transcriptional Regulation of RKIP in Prostate Cancer Progression
Health Science Campus FINAL APPROVAL OF DISSERTATION Doctor of Philosophy in Biomedical Sciences Transcriptional Regulation of RKIP in Prostate Cancer Progression Submitted by: Sandra Marie Beach In partial fulfillment of the requirements for the degree of Doctor of Philosophy in Biomedical Sciences Examination Committee Major Advisor: Kam Yeung, Ph.D. Academic William Maltese, Ph.D. Advisory Committee: Sonia Najjar, Ph.D. Han-Fei Ding, M.D., Ph.D. Manohar Ratnam, Ph.D. Senior Associate Dean College of Graduate Studies Michael S. Bisesi, Ph.D. Date of Defense: May 16, 2007 Transcriptional Regulation of RKIP in Prostate Cancer Progression Sandra Beach University of Toledo ACKNOWLDEGMENTS I thank my major advisor, Dr. Kam Yeung, for the opportunity to pursue my degree in his laboratory. I am also indebted to my advisory committee members past and present, Drs. Sonia Najjar, Han-Fei Ding, Manohar Ratnam, James Trempe, and Douglas Pittman for generously and judiciously guiding my studies and sharing reagents and equipment. I owe extended thanks to Dr. William Maltese as a committee member and chairman of my department for supporting my degree progress. The entire Department of Biochemistry and Cancer Biology has been most kind and helpful to me. Drs. Roy Collaco and Hong-Juan Cui have shared their excellent technical and practical advice with me throughout my studies. I thank members of the Yeung laboratory, Dr. Sungdae Park, Hui Hui Tang, Miranda Yeung for their support and collegiality. The data mining studies herein would not have been possible without the helpful advice of Dr. Robert Trumbly. I am also grateful for the exceptional assistance and shared microarray data of Dr. -

New Approaches to Functional Process Discovery in HPV 16-Associated Cervical Cancer Cells by Gene Ontology
Cancer Research and Treatment 2003;35(4):304-313 New Approaches to Functional Process Discovery in HPV 16-Associated Cervical Cancer Cells by Gene Ontology Yong-Wan Kim, Ph.D.1, Min-Je Suh, M.S.1, Jin-Sik Bae, M.S.1, Su Mi Bae, M.S.1, Joo Hee Yoon, M.D.2, Soo Young Hur, M.D.2, Jae Hoon Kim, M.D.2, Duck Young Ro, M.D.2, Joon Mo Lee, M.D.2, Sung Eun Namkoong, M.D.2, Chong Kook Kim, Ph.D.3 and Woong Shick Ahn, M.D.2 1Catholic Research Institutes of Medical Science, 2Department of Obstetrics and Gynecology, College of Medicine, The Catholic University of Korea, Seoul; 3College of Pharmacy, Seoul National University, Seoul, Korea Purpose: This study utilized both mRNA differential significant genes of unknown function affected by the display and the Gene Ontology (GO) analysis to char- HPV-16-derived pathway. The GO analysis suggested that acterize the multiple interactions of a number of genes the cervical cancer cells underwent repression of the with gene expression profiles involved in the HPV-16- cancer-specific cell adhesive properties. Also, genes induced cervical carcinogenesis. belonging to DNA metabolism, such as DNA repair and Materials and Methods: mRNA differential displays, replication, were strongly down-regulated, whereas sig- with HPV-16 positive cervical cancer cell line (SiHa), and nificant increases were shown in the protein degradation normal human keratinocyte cell line (HaCaT) as a con- and synthesis. trol, were used. Each human gene has several biological Conclusion: The GO analysis can overcome the com- functions in the Gene Ontology; therefore, several func- plexity of the gene expression profile of the HPV-16- tions of each gene were chosen to establish a powerful associated pathway, identify several cancer-specific cel- cervical carcinogenesis pathway. -

A Computational Approach for Defining a Signature of Β-Cell Golgi Stress in Diabetes Mellitus
Page 1 of 781 Diabetes A Computational Approach for Defining a Signature of β-Cell Golgi Stress in Diabetes Mellitus Robert N. Bone1,6,7, Olufunmilola Oyebamiji2, Sayali Talware2, Sharmila Selvaraj2, Preethi Krishnan3,6, Farooq Syed1,6,7, Huanmei Wu2, Carmella Evans-Molina 1,3,4,5,6,7,8* Departments of 1Pediatrics, 3Medicine, 4Anatomy, Cell Biology & Physiology, 5Biochemistry & Molecular Biology, the 6Center for Diabetes & Metabolic Diseases, and the 7Herman B. Wells Center for Pediatric Research, Indiana University School of Medicine, Indianapolis, IN 46202; 2Department of BioHealth Informatics, Indiana University-Purdue University Indianapolis, Indianapolis, IN, 46202; 8Roudebush VA Medical Center, Indianapolis, IN 46202. *Corresponding Author(s): Carmella Evans-Molina, MD, PhD ([email protected]) Indiana University School of Medicine, 635 Barnhill Drive, MS 2031A, Indianapolis, IN 46202, Telephone: (317) 274-4145, Fax (317) 274-4107 Running Title: Golgi Stress Response in Diabetes Word Count: 4358 Number of Figures: 6 Keywords: Golgi apparatus stress, Islets, β cell, Type 1 diabetes, Type 2 diabetes 1 Diabetes Publish Ahead of Print, published online August 20, 2020 Diabetes Page 2 of 781 ABSTRACT The Golgi apparatus (GA) is an important site of insulin processing and granule maturation, but whether GA organelle dysfunction and GA stress are present in the diabetic β-cell has not been tested. We utilized an informatics-based approach to develop a transcriptional signature of β-cell GA stress using existing RNA sequencing and microarray datasets generated using human islets from donors with diabetes and islets where type 1(T1D) and type 2 diabetes (T2D) had been modeled ex vivo. To narrow our results to GA-specific genes, we applied a filter set of 1,030 genes accepted as GA associated. -

Integrating Single-Step GWAS and Bipartite Networks Reconstruction Provides Novel Insights Into Yearling Weight and Carcass Traits in Hanwoo Beef Cattle
animals Article Integrating Single-Step GWAS and Bipartite Networks Reconstruction Provides Novel Insights into Yearling Weight and Carcass Traits in Hanwoo Beef Cattle Masoumeh Naserkheil 1 , Abolfazl Bahrami 1 , Deukhwan Lee 2,* and Hossein Mehrban 3 1 Department of Animal Science, University College of Agriculture and Natural Resources, University of Tehran, Karaj 77871-31587, Iran; [email protected] (M.N.); [email protected] (A.B.) 2 Department of Animal Life and Environment Sciences, Hankyong National University, Jungang-ro 327, Anseong-si, Gyeonggi-do 17579, Korea 3 Department of Animal Science, Shahrekord University, Shahrekord 88186-34141, Iran; [email protected] * Correspondence: [email protected]; Tel.: +82-31-670-5091 Received: 25 August 2020; Accepted: 6 October 2020; Published: 9 October 2020 Simple Summary: Hanwoo is an indigenous cattle breed in Korea and popular for meat production owing to its rapid growth and high-quality meat. Its yearling weight and carcass traits (backfat thickness, carcass weight, eye muscle area, and marbling score) are economically important for the selection of young and proven bulls. In recent decades, the advent of high throughput genotyping technologies has made it possible to perform genome-wide association studies (GWAS) for the detection of genomic regions associated with traits of economic interest in different species. In this study, we conducted a weighted single-step genome-wide association study which combines all genotypes, phenotypes and pedigree data in one step (ssGBLUP). It allows for the use of all SNPs simultaneously along with all phenotypes from genotyped and ungenotyped animals. Our results revealed 33 relevant genomic regions related to the traits of interest. -
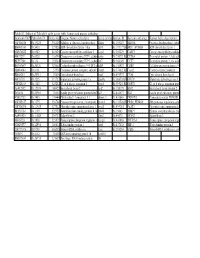
Table S3: Subset of Zebrafish Early Genes with Human And
Table S3: Subset of Zebrafish early genes with human and mouse orthologs Genbank ID(ZFZebrafish ID Entrez GenUnigene Name (zebrafish) Gene symbo Human ID Humann ortholog Human Gene description AW116838 Dr.19225 336425 Aldolase a, fructose-bisphosphate aldoa Hs.155247 ALDOA Fructose-bisphosphate aldola BM005100 Dr.5438 327026 ADP-ribosylation factor 1 like arf1l Hs.119177||HsARF1_HUMAN ADP-ribosylation factor 1 AW076882 Dr.6582 403025 Cancer susceptibility candidate 3 casc3 Hs.350229 CASC3 Cancer susceptibility candidat AI437239 Dr.6928 116994 Chaperonin containing TCP1, subun cct6a Hs.73072||Hs.CCT6A T-complex protein 1, zeta sub BE557308 Dr.134 192324 Chaperonin containing TCP1, subun cct7 Hs.368149 CCT7 T-complex protein 1, eta subu BG303647 Dr.26326 321602 Cyclin-dependent kinase 9 (CDC2-recdk9 Hs.150423 CDK9 Cell division protein kinase 9 AB040044 Dr.8161 57970 Coatomer protein complex, subunit zcopz1 Hs.37482||Hs.Copz2 Coatomer zeta-2 subunit BI888253 Dr.20911 30436 Eyes absent homolog 1 eya1 Hs.491997 EYA4 Eyes absent homolog 4 AI878758 Dr.3225 317737 Glutamate dehydrogenase 1a glud1a Hs.368538||HsGLUD1 Glutamate dehydrogenase 1, AW128619 Dr.1388 325284 G1 to S phase transition 1 gspt1 Hs.59523||Hs.GSPT1 G1 to S phase transition prote AF412832 Dr.12595 140427 Heat shock factor 2 hsf2 Hs.158195 HSF2 Heat shock factor protein 2 D38454 Dr.20916 30151 Insulin gene enhancer protein Islet3 isl3 Hs.444677 ISL2 Insulin gene enhancer protein AY052752 Dr.7485 170444 Pbx/knotted 1 homeobox 1.1 pknox1.1 Hs.431043 PKNOX1 Homeobox protein PKNOX1 -

1 Supporting Information for a Microrna Network Regulates
Supporting Information for A microRNA Network Regulates Expression and Biosynthesis of CFTR and CFTR-ΔF508 Shyam Ramachandrana,b, Philip H. Karpc, Peng Jiangc, Lynda S. Ostedgaardc, Amy E. Walza, John T. Fishere, Shaf Keshavjeeh, Kim A. Lennoxi, Ashley M. Jacobii, Scott D. Rosei, Mark A. Behlkei, Michael J. Welshb,c,d,g, Yi Xingb,c,f, Paul B. McCray Jr.a,b,c Author Affiliations: Department of Pediatricsa, Interdisciplinary Program in Geneticsb, Departments of Internal Medicinec, Molecular Physiology and Biophysicsd, Anatomy and Cell Biologye, Biomedical Engineeringf, Howard Hughes Medical Instituteg, Carver College of Medicine, University of Iowa, Iowa City, IA-52242 Division of Thoracic Surgeryh, Toronto General Hospital, University Health Network, University of Toronto, Toronto, Canada-M5G 2C4 Integrated DNA Technologiesi, Coralville, IA-52241 To whom correspondence should be addressed: Email: [email protected] (M.J.W.); yi- [email protected] (Y.X.); Email: [email protected] (P.B.M.) This PDF file includes: Materials and Methods References Fig. S1. miR-138 regulates SIN3A in a dose-dependent and site-specific manner. Fig. S2. miR-138 regulates endogenous SIN3A protein expression. Fig. S3. miR-138 regulates endogenous CFTR protein expression in Calu-3 cells. Fig. S4. miR-138 regulates endogenous CFTR protein expression in primary human airway epithelia. Fig. S5. miR-138 regulates CFTR expression in HeLa cells. Fig. S6. miR-138 regulates CFTR expression in HEK293T cells. Fig. S7. HeLa cells exhibit CFTR channel activity. Fig. S8. miR-138 improves CFTR processing. Fig. S9. miR-138 improves CFTR-ΔF508 processing. Fig. S10. SIN3A inhibition yields partial rescue of Cl- transport in CF epithelia. -

Variation in Protein Coding Genes Identifies Information
bioRxiv preprint doi: https://doi.org/10.1101/679456; this version posted June 21, 2019. The copyright holder for this preprint (which was not certified by peer review) is the author/funder, who has granted bioRxiv a license to display the preprint in perpetuity. It is made available under aCC-BY-NC-ND 4.0 International license. Animal complexity and information flow 1 1 2 3 4 5 Variation in protein coding genes identifies information flow as a contributor to 6 animal complexity 7 8 Jack Dean, Daniela Lopes Cardoso and Colin Sharpe* 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 Institute of Biological and Biomedical Sciences 25 School of Biological Science 26 University of Portsmouth, 27 Portsmouth, UK 28 PO16 7YH 29 30 * Author for correspondence 31 [email protected] 32 33 Orcid numbers: 34 DLC: 0000-0003-2683-1745 35 CS: 0000-0002-5022-0840 36 37 38 39 40 41 42 43 44 45 46 47 48 49 Abstract bioRxiv preprint doi: https://doi.org/10.1101/679456; this version posted June 21, 2019. The copyright holder for this preprint (which was not certified by peer review) is the author/funder, who has granted bioRxiv a license to display the preprint in perpetuity. It is made available under aCC-BY-NC-ND 4.0 International license. Animal complexity and information flow 2 1 Across the metazoans there is a trend towards greater organismal complexity. How 2 complexity is generated, however, is uncertain. Since C.elegans and humans have 3 approximately the same number of genes, the explanation will depend on how genes are 4 used, rather than their absolute number.