Financial Market Data for R/Rmetrics
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

COVID-19 Pandemic and Financial Contagion
Journal of Risk and Financial Management Article COVID-19 Pandemic and Financial Contagion Julien Chevallier 1,2 1 Department of Economics & Management, IPAG Business School (IPAG Lab), 184 bd Saint-Germain, 75006 Paris, France; [email protected] 2 Economics Department, Université Paris 8 (LED), 2 rue de la Liberté, CEDEX 93526 Saint-Denis, France Received: 15 October 2020; Accepted: 1 December 2020; Published: 3 December 2020 Abstract: The original contribution of this paper is to empirically document the contagion of the COVID-19 on financial markets. We merge databases from Johns Hopkins Coronavirus Center, Oxford-Man Institute Realized Library, NYU Volatility Lab, an d St-Louis Federal Reserve Board. We deploy three types of models throughout our experiments: (i) the Susceptible-Infective-Removed (SIR) that predicts the infections’ peak on 2020-03-27; (ii) volatility (GARCH), correlation (DCC), and risk-management (Value-at-Risk (VaR)) models that relate how bears painted Wall Street red; and, (iii) data-science trees algorithms with forward prunning, mosaic plots, and Pythagorean forests that crunch the data on confirmed, deaths, and recovered COVID-19 cases and then tie them to high-frequency data for 31 stock markets. Keywords: COVID-19; financial contagion; Johns Hopkins repository; Susceptible-Infective-Removed model; tree algorithm; data science 1. Introduction The COVID-19 pandemic hit the world economy, without anyone knowing, at light-speed, leading to partial unemployment and factories’ shutdown around the globe, leaving doctors, policymakers, businessmen, operational managers, data scientists, and citizens alike in disarray. The origin of the virus itself is not known with certainty, although most theories attach it to zoonotic transfer to the human species (Andersen et al. -
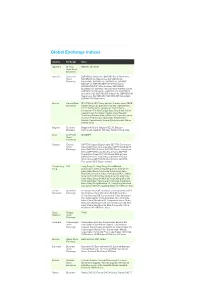
Global Exchange Indices
Global Exchange Indices Country Exchange Index Argentina Buenos MERVAL, BURCAP Aires Stock Exchange Australia Australian S&P/ASX All Ordinaries, S&P/ASX Small Ordinaries, Stock S&P/ASX Small Resources, S&P/ASX Small Exchange Industriials, S&P/ASX 20, S&P/ASX 50, S&P/ASX MIDCAP 50, S&P/ASX MIDCAP 50 Resources, S&P/ASX MIDCAP 50 Industrials, S&P/ASX All Australian 50, S&P/ASX 100, S&P/ASX 100 Resources, S&P/ASX 100 Industrials, S&P/ASX 200, S&P/ASX All Australian 200, S&P/ASX 200 Industrials, S&P/ASX 200 Resources, S&P/ASX 300, S&P/ASX 300 Industrials, S&P/ASX 300 Resources Austria Vienna Stock ATX, ATX Five, ATX Prime, Austrian Traded Index, CECE Exchange Overall Index, CECExt Index, Chinese Traded Index, Czech Traded Index, Hungarian Traded Index, Immobilien ATX, New Europe Blue Chip Index, Polish Traded Index, Romanian Traded Index, Russian Depository Extended Index, Russian Depository Index, Russian Traded Index, SE Europe Traded Index, Serbian Traded Index, Vienna Dynamic Index, Weiner Boerse Index Belgium Euronext Belgium All Share, Belgium BEL20, Belgium Brussels Continuous, Belgium Mid Cap, Belgium Small Cap Brazil Sao Paulo IBOVESPA Stock Exchange Canada Toronto S&P/TSX Capped Equity Index, S&P/TSX Completion Stock Index, S&P/TSX Composite Index, S&P/TSX Equity 60 Exchange Index S&P/TSX 60 Index, S&P/TSX Equity Completion Index, S&P/TSX Equity SmallCap Index, S&P/TSX Global Gold Index, S&P/TSX Global Mining Index, S&P/TSX Income Trust Index, S&P/TSX Preferred Share Index, S&P/TSX SmallCap Index, S&P/TSX Composite GICS Sector Indexes -

Case Study: the Bayer-Monsanto Acquisition Deal
Case Study: The Bayer-Monsanto Acquisition Deal Student: Georgios Ritsos-Kokkinis (SNR:2013707, ANR:927674) Supervisor: Prof. Dr. Christoph Schneider Second reader: Prof. Dr. Olivier de Jonghe Tilburg, August 2020 Acknowledgements I would like to thank my supervisor Dr. Christoph Schneider, Assistant Professor at Tilburg University – Department of Finance, whose expertise and guidance were invaluable in soundly formulating all the relevant methodologies, and concisely structuring the output results. Your feedback pushed me to sharpen my thinking and brought my work to a higher level. I would also like to thank fellow scholar Thanos Vasiliadis, PhD candidate in Mathematics at Université côté d'Azur, Laboratoire Dieudonné, for his support, encouragement and constructive comments, which were instrumental to the completion of this dissertation. ABSTRACT The acquisition of Bayer-Monsanto was one of the largest M&A deals of the past decade. In this study, I document the motives of this transaction and the timeline of events that took place, from the initial rumors until Bayer’s milestone settlement of Monsanto’s “Roundup” litigation in mid-2020. Fundamental valuations of the two individual companies and their officially disclosed synergies reveal that the premium paid over Monsanto’s overvalued share price was not justified, as is commonly observed in the M&A ecosystem. Multiple approaches to the calculation of the discount factor reach the same conclusion. Averaging across multiple costs of capital, shows that the combined intrinsic value with synergy of roughly $177bn was some $2.12bn higher than the sum of parts, suggesting a rather profitable investment opportunity. However, Bayer, did overpay by 18.08% to reap these benefits. -

Tracking Errors of Exchange Traded Funds in Bursa Malaysia
Munich Personal RePEc Archive Tracking Errors of Exchange Traded Funds in Bursa Malaysia Ku, Alfred Ing-Soon and Liew, Venus Khim-Sen and Puah, Chin-Hong RHB Investment Bank Berhad, 102, Pusat Pedada, Jalan Pedada, 96000 Sibu, Sarawak, Malaysia., Faculty of Economics and Business, Universiti Malaysia Sarawak, Jalan Datuk Mohammad Musa, 94300 Kota Samarahan, Sarawak., Faculty of Economics and Business, Universiti Malaysia Sarawak, Jalan Datuk Mohammad Musa, 94300 Kota Samarahan, Sarawak. 2019 Online at https://mpra.ub.uni-muenchen.de/107990/ MPRA Paper No. 107990, posted 27 May 2021 07:20 UTC Tracking Errors of Exchange Traded Funds in Bursa Malaysia Alfred Ing-Soon Ku RHB Investment Bank Berhad, 102, Pusat Pedada, Jalan Pedada, 96000 Sibu, Sarawak, Malaysia. Tel: 6-084-329214 E-mail: [email protected] Venus Khim-Sen Liew Faculty of Economics and Business, Universiti Malaysia Sarawak, Jalan Datuk Mohammad Musa, 94300 Kota Samarahan, Sarawak. Tel: 6-082-584291 (Corresponding Author) E-mail: [email protected] Chin-Hong Puah Faculty of Economics and Business, Universiti Malaysia Sarawak, Jalan Datuk Mohammad Musa, 94300 Kota Samarahan, Sarawak. Tel: 6-082-584294 E-mail: [email protected] Citation: Liew, V.K.-S, Ku, A. I.-S., & Puah, C.-H. 2019. Tracking Errors of Exchange Traded Funds in Bursa Malaysia. Asian Journal of Accounting and Finance, 11(2), 96-109. Abstract This study measures the tracking errors of exchange traded funds (ETFs) listed in Bursa Malaysia. Five measures of tracking errors are estimated in this study for the seven ETFs involved. Overall, the best ETF is METFAPA with the least tracking error. -

2017 Contributing Editors Joshua Ford Bonnie and Kevin P Kennedy
GETTING THROUGH THE DEAL Initial Public Offerings Initial Public Offerings Public Initial Contributing editors Joshua Ford Bonnie and Kevin P Kennedy 2017 Law Business Research 2017 © Law Business Research 2016 Initial Public Offerings 2017 Contributing editors Joshua Ford Bonnie and Kevin P Kennedy Simpson Thacher & Bartlett LLP Publisher Law The information provided in this publication is Gideon Roberton general and may not apply in a specific situation. [email protected] Business Legal advice should always be sought before taking Research any legal action based on the information provided. Subscriptions This information is not intended to create, nor does Sophie Pallier Published by receipt of it constitute, a lawyer–client relationship. [email protected] Law Business Research Ltd The publishers and authors accept no responsibility 87 Lancaster Road for any acts or omissions contained herein. Although Senior business development managers London, W11 1QQ, UK the information provided is accurate as of July 2016, Alan Lee Tel: +44 20 3708 4199 be advised that this is a developing area. [email protected] Fax: +44 20 7229 6910 Adam Sargent © Law Business Research Ltd 2016 Printed and distributed by [email protected] No photocopying without a CLA licence. Encompass Print Solutions First published 2015 Tel: 0844 2480 112 Dan White Second edition [email protected] ISSN 2059-5484 © Law Business Research 2016 CONTENTS Global overview 5 Japan 51 Joshua Ford -

Monthly Economic Update
122 Winnebago Street, Decorah, IA 52101 309 HWY 150 N, West Union, IA 52175 1-877-566-9468 Text: 563-412-4770 [email protected] Visit us at www.knoxfin.com In this month’s recap: stocks stay in rally mode, helped by hints that the U.S. and China may be closing in on a phase-one trade deal; hiring bounces back; key real estate indicators look stronger. Monthly Economic Update Presented by Jason Knox, AIF®, CRC®, December 2019 THE MONTH IN BRIEF The S&P 500 rose 3.4% in November and attained a series of record closes in the process. Earnings results helped stocks, as did intermittent signals that the first stage of a U.S.-China trade agreement might be near at hand. Job creation improved, and consumer spending lived up to market expectations; consumer confidence and business activity, not so much. Housing indicators communicated good news, and the rally in stocks made the commodity sector look less attractive. DOMESTIC ECONOMIC HEALTH Were the U.S. and China close to signing off on the first phase of a new trade deal? According to officials from both countries, the answer was yes. When would this phase- one deal be finalized? No definite answer emerged. On November 8, President Donald Trump said that such an agreement was near, and six days later, White House economic advisor Larry Kudlow said that negotiators were “getting close” to an accord. On November 26, China’s commerce ministry announced that trade representatives had “reached a consensus” on remaining issues, and President Trump said that negotiators were in the “final throes of a very important deal.” Still, November ended without any announcement that a phase-one pact had been reached.2,3 The Department of Labor’s latest employment report found that the economy generated 128,000 net new jobs in October. -

Does the Glass Ceiling Exist? a Longitudinal Study of Women's
The Journal of Applied Business Research – May/June 2014 Volume 30, Number 3 Does The Glass Ceiling Exist? A Longitudinal Study Of Women’s Progress On French Corporate Boards Rey Dang, La Rochelle Business School, France Duc Khuong Nguyen, IPAG Business School, France Linh-Chi Vo, EM Normandie, France ABSTRACT In this article, we conduct a longitudinal study of women’s progress on French corporate boards of directors. We particularly focus on the extent to which women directors have circumvented the glass ceiling. Using a sample of SBF 120 companies over a 10-year period from 2000 to 2009, our results provide evidence of a significant increase in the number of women on French corporate boards. However, the corporate glass ceiling hypothesis is consistently rejected whatever the considered measure of female directors; i.e., the number of board seats held by women, the number of firms with a critical mass of female directors, and the number of directorships held by each women director. Keywords: Boards of Directors; Gender; Diversity; Corporate Governance 1. INTRODUCTION ver the period 2000-2009, the average participation rate of women in the labor market increased from 60 to 64 percent across the European Union’s 27 Members States. More specifically, in France, it went up from 60.3 to 64.9 percent.1 However, despite this notable progress, women remain under-represented Oin senior or executive positions (ILO, 2009).2 This lack of female representation on corporate boards of directors, which is commonly referred to as glass ceiling in practice and past academic studies, seems to be a global phenomenon because women on corporate boards (WOCB) represents less than 15% of board members in the United States, United Kingdom, Canada, Australia, and many European countries (Dang & Vo, 2012).3 Morrison et al. -

Organized Equity Markets in Germany Erik Theissen
No. 2003/17 Organized Equity Markets in Germany Erik Theissen Center for Financial Studies an der Johann Wolfgang Goethe-Universität C Taunusanlage 6 C D-60329 Frankfurt am Main Tel: (+49)069/242941-0 C Fax: (+49)069/242941-77 C E-Mail: [email protected] C Internet: http://www.ifk-cfs.de CFS Working Paper No. 2003/17 Organized Equity Markets in Germany Erik Theissen* March 2003 Abstract: The German financial system is the archetype of a bank-dominated system. This implies that organized equity markets are, in some sense, underdeveloped. The purpose of this paper is, first, to describe the German equity markets and, second, to analyze whether it is underdevel- oped in any meaningful sense. In the descriptive part we provide a detailed account of the microstructure of the German equity markets, putting special emphasis on recent develop- ments. When comparing the German market with its peers, we find that it is indeed underdeveloped with respect to market capitalization. In terms of liquidity, on the other hand, the German equity market is not generally underdeveloped. It does, however, lack a liquid market for block trading. JEL Classification: G 51 Keywords: Market size, liquidity, floor versus screen trading * Prof. Dr. Erik Theissen, Universität Bonn, BWL 1, Adenauerallee 24-42, 53113 Bonn, Germany Email: [email protected]. Forthcoming in: The German Financial System by Jan P. Krahnen and Reinhard H. Schmidt, Oxford University Press, August 2003 Organized Equity Markets Erik Theissen, University of Bonn March 2003 I. Introduction ........................................................................................................................ 2 II. The German Equity Market................................................................................................ 2 III. The (micro)structure of the German equity markets......................................................... -

Are Retail Investors Less Aggressive on Small Price Stocks?
Are retail investors less aggressive on small price stocks? Carole M´etais∗ Tristan Rogery January 13, 2021 Abstract In this paper, we investigate whether number processing impacts the limit orders of retail investors. Building on existing literature in neuropsychology that shows that individuals do not process small numbers and large numbers in the same way, we study the influence of nominal stock price level on order aggressiveness. Using a unique database that allows us to identify order and trade records issued by retail investors on Euronext Paris, we show that retail investors, when posting non-marketable orders, are less aggressive on small price stocks than on large price stocks. This difference in order aggressiveness is not explained by differences in liquidity and other usual drivers of order aggressiveness. We provide additional evidence by showing that no such difference exists for limit orders of high frequency traders (HFTs) over the same period and the same sample of stocks. This finding confirms that our results are driven by a behavioral bias and not by differential market dynamics between small price stocks and large price stocks. ∗LaRGE Research Center, University of Strasbourg { Mailing address: 61 Avenue de la For^etNoire, 67000 Strasbourg FRANCE { Email: [email protected]. I acknowledge support from the French State through the National Agency for Research under the program Investissements d'Avenir ANR-11-EQPX- 006. yDRM Finance, Universit´eParis-Dauphine, PSL Research University { Mailing address: Place du Mar´echal de Lattre de Tassigny, 75775 Paris Cedex 16 FRANCE { Email: [email protected] 1 1 Introduction While conventional finance theory posits that nominal stock prices are irrelevant for firm valuation, a number of papers provide empirical evidence that nominal prices do impact investor behavior. -

789398885.Pdf
A Service of Leibniz-Informationszentrum econstor Wirtschaft Leibniz Information Centre Make Your Publications Visible. zbw for Economics Burhop, Carsten; Lehmann-Hasemeyer, Sibylle H. Working Paper The geography of stock exchanges in Imperial Germany FZID Discussion Paper, No. 89-2014 Provided in Cooperation with: University of Hohenheim, Center for Research on Innovation and Services (FZID) Suggested Citation: Burhop, Carsten; Lehmann-Hasemeyer, Sibylle H. (2014) : The geography of stock exchanges in Imperial Germany, FZID Discussion Paper, No. 89-2014, Universität Hohenheim, Forschungszentrum Innovation und Dienstleistung (FZID), Stuttgart, http://nbn-resolving.de/urn:nbn:de:bsz:100-opus-9834 This Version is available at: http://hdl.handle.net/10419/98252 Standard-Nutzungsbedingungen: Terms of use: Die Dokumente auf EconStor dürfen zu eigenen wissenschaftlichen Documents in EconStor may be saved and copied for your Zwecken und zum Privatgebrauch gespeichert und kopiert werden. personal and scholarly purposes. Sie dürfen die Dokumente nicht für öffentliche oder kommerzielle You are not to copy documents for public or commercial Zwecke vervielfältigen, öffentlich ausstellen, öffentlich zugänglich purposes, to exhibit the documents publicly, to make them machen, vertreiben oder anderweitig nutzen. publicly available on the internet, or to distribute or otherwise use the documents in public. Sofern die Verfasser die Dokumente unter Open-Content-Lizenzen (insbesondere CC-Lizenzen) zur Verfügung gestellt haben sollten, If the documents have been made available under an Open gelten abweichend von diesen Nutzungsbedingungen die in der dort Content Licence (especially Creative Commons Licences), you genannten Lizenz gewährten Nutzungsrechte. may exercise further usage rights as specified in the indicated licence. www.econstor.eu FZID Discussion Papers CC Economics Discussion Paper 89-2014 THE GEOGRAPHY OF STOCK EXCHANGES IN IMPERIAL GERMANY Carsten Burhop Sibylle H. -

Information Product Fee Schedule
INFORMATION PRODUCT FEE SCHEDULE Applicable from: 1 January 2020 (Version 7.0) CONTENTS GENERAL ................................................................................................................................................ 1 DIRECT ACCESS FEES ............................................................................................................................... 2 REDISTRIBUTION LICENCE FEES ............................................................................................................... 3 Real Time Redistribution Licence Fees ............................................................................................................... 3 Delayed Redistribution Licence Fees .................................................................................................................. 4 WHITE LABEL FEES .................................................................................................................................. 6 PUBLIC DISPLAY FEES .............................................................................................................................. 8 DISPLAY USE FEES ................................................................................................................................... 9 NON-PROFESSIONAL FEES1 ................................................................................................................... 11 PAGE VIEW FEES*................................................................................................................................. -

Press Release Paris – June 21St, 2021
Press Release Paris – June 21st, 2021 Europcar Mobility Group rejoins Euronext SBF 120 index Europcar Mobility Group, a major player in mobility markets, is pleased to announce that it has re-entered into the SBF 120 and CAC Mid 60 indices, in accordance with the decision taken by the Euronext Index Steering Committee. This re-entry, which took place after market close on Friday 18 June 2021, is effective from Monday 21 June 2021. The SBF 120 is one of the flagship indices of the Paris Stock Exchange. It includes the first 120 stocks listed on Euronext Paris in terms of liquidity and market capitalization. The CAC Mid 60 index includes 60 companies of national and European importance. It represents the 60 largest French equities beyond the CAC 40 and the CAC Next 20. It includes the 60 most liquid stocks listed in Paris among the 200 first French capitalizations. This total of 120 companies compose the SBF 120. Caroline Parot, CEO of Europcar Mobility Group, said: “Europcar Mobility Group welcomes the re-integration of the SBF 120 and CAC Mid 60. This follows the successful closing of the Group’s financial restructuring during Q1 2021, which allowed the Group to open a new chapter in its history. Europcar Mobility Group re-entry into the SBF 120 and CAC Mid 60 is an important step for our Group and recognizes the fact that we are clearly "back in the game”, in a good position to take full advantage of the progressive recovery of the Travel and Leisure market. In that perspective, our teams are fully mobilized for summer of 2021, in order to meet the demand and expectations of customers who are more than ever eager to travel”.