A Dual-Mode User Interface for Accessing 3D Content on the World Wide Web
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Boot Mode Considerations: BIOS Vs UEFI
Boot Mode Considerations: BIOS vs. UEFI An overview of differences between UEFI Boot Mode and traditional BIOS Boot Mode Dell Engineering June 2018 Revisions Date Description October 2017 Initial release June 2018 Added DHCP Server PXE configuration details. The information in this publication is provided “as is.” Dell Inc. makes no representations or warranties of any kind with respect to the information in this publication, and specifically disclaims implied warranties of merchantability or fitness for a particular purpose. Use, copying, and distribution of any software described in this publication requires an applicable software license. Copyright © 2017 Dell Inc. or its subsidiaries. All Rights Reserved. Dell, EMC, and other trademarks are trademarks of Dell Inc. or its subsidiaries. Other trademarks may be the property of their respective owners. Published in the USA [1/15/2020] [Deployment and Configuration Guide] [Document ID] Dell believes the information in this document is accurate as of its publication date. The information is subject to change without notice. 2 : BIOS vs. UEFI | Doc ID 20444677 | June 2018 Table of contents Revisions............................................................................................................................................................................. 2 Executive Summary ............................................................................................................................................................ 4 1 Introduction .................................................................................................................................................................. -

The Origins of the Underline As Visual Representation of the Hyperlink on the Web: a Case Study in Skeuomorphism
The Origins of the Underline as Visual Representation of the Hyperlink on the Web: A Case Study in Skeuomorphism The Harvard community has made this article openly available. Please share how this access benefits you. Your story matters Citation Romano, John J. 2016. The Origins of the Underline as Visual Representation of the Hyperlink on the Web: A Case Study in Skeuomorphism. Master's thesis, Harvard Extension School. Citable link http://nrs.harvard.edu/urn-3:HUL.InstRepos:33797379 Terms of Use This article was downloaded from Harvard University’s DASH repository, and is made available under the terms and conditions applicable to Other Posted Material, as set forth at http:// nrs.harvard.edu/urn-3:HUL.InstRepos:dash.current.terms-of- use#LAA The Origins of the Underline as Visual Representation of the Hyperlink on the Web: A Case Study in Skeuomorphism John J Romano A Thesis in the Field of Visual Arts for the Degree of Master of Liberal Arts in Extension Studies Harvard University November 2016 Abstract This thesis investigates the process by which the underline came to be used as the default signifier of hyperlinks on the World Wide Web. Created in 1990 by Tim Berners- Lee, the web quickly became the most used hypertext system in the world, and most browsers default to indicating hyperlinks with an underline. To answer the question of why the underline was chosen over competing demarcation techniques, the thesis applies the methods of history of technology and sociology of technology. Before the invention of the web, the underline–also known as the vinculum–was used in many contexts in writing systems; collecting entities together to form a whole and ascribing additional meaning to the content. -

Fuzzy Mouse Cursor Control System for Computer Users with Spinal Cord Injuries
Georgia State University ScholarWorks @ Georgia State University Computer Science Theses Department of Computer Science 8-8-2006 Fuzzy Mouse Cursor Control System for Computer Users with Spinal Cord Injuries Tihomir Surdilovic Follow this and additional works at: https://scholarworks.gsu.edu/cs_theses Part of the Computer Sciences Commons Recommended Citation Surdilovic, Tihomir, "Fuzzy Mouse Cursor Control System for Computer Users with Spinal Cord Injuries." Thesis, Georgia State University, 2006. https://scholarworks.gsu.edu/cs_theses/49 This Thesis is brought to you for free and open access by the Department of Computer Science at ScholarWorks @ Georgia State University. It has been accepted for inclusion in Computer Science Theses by an authorized administrator of ScholarWorks @ Georgia State University. For more information, please contact [email protected]. i Fuzzy Mouse Cursor Control System For Computer Users with Spinal Cord Injuries A Thesis Presented in Partial Fulfillment of Requirements for the Degree of Master of Science in the College of Arts and Sciences Georgia State University 2005 by Tihomir Surdilovic Committee: ____________________________________ Dr. Yan-Qing Zhang, Chair ____________________________________ Dr. Rajshekhar Sunderraman, Member ____________________________________ Dr. Michael Weeks, Member ____________________________________ Dr. Yi Pan, Department Chair Date July 21st 2005 ii Abstract People with severe motor-impairments due to Spinal Cord Injury (SCI) or Spinal Cord Dysfunction (SCD), often experience difficulty with accurate and efficient control of pointing devices (Keates et al., 02). Usually this leads to their limited integration to society as well as limited unassisted control over the environment. The questions “How can someone with severe motor-impairments perform mouse pointer control as accurately and efficiently as an able-bodied person?” and “How can these interactions be advanced through use of Computational Intelligence (CI)?” are the driving forces behind the research described in this paper. -

Text Editing in UNIX: an Introduction to Vi and Editing
Text Editing in UNIX A short introduction to vi, pico, and gedit Copyright 20062009 Stewart Weiss About UNIX editors There are two types of text editors in UNIX: those that run in terminal windows, called text mode editors, and those that are graphical, with menus and mouse pointers. The latter require a windowing system, usually X Windows, to run. If you are remotely logged into UNIX, say through SSH, then you should use a text mode editor. It is possible to use a graphical editor, but it will be much slower to use. I will explain more about that later. 2 CSci 132 Practical UNIX with Perl Text mode editors The three text mode editors of choice in UNIX are vi, emacs, and pico (really nano, to be explained later.) vi is the original editor; it is very fast, easy to use, and available on virtually every UNIX system. The vi commands are the same as those of the sed filter as well as several other common UNIX tools. emacs is a very powerful editor, but it takes more effort to learn how to use it. pico is the easiest editor to learn, and the least powerful. pico was part of the Pine email client; nano is a clone of pico. 3 CSci 132 Practical UNIX with Perl What these slides contain These slides concentrate on vi because it is very fast and always available. Although the set of commands is very cryptic, by learning a small subset of the commands, you can edit text very quickly. What follows is an outline of the basic concepts that define vi. -

LG Xpression Manual
User Guide All screen shots in this guide are simulated. Actual displays and the color of the phone may vary. Some of the contents in this manual may differ from your phone depending on the software of the phone or your service provider. P/NO: MFL67476402 (1.0) www.lg.com LIMITED WARRANTY STATEMENT 1. WHAT THIS WARRANTY COVERS : 2. WHAT THIS WARRANTY DOES NOT LG offers you a limited warranty that the COVER : enclosed subscriber unit and its enclosed 1. Defects or damages resulting from use of the accessories will be free from defects in material product in other than its normal and customary and workmanship, according to the following manner. terms and conditions: 2. Defects or damages from abnormal use, 1. The limited warranty for the product extends abnormal conditions, improper storage, for TWELVE (12) MONTHS beginning on the exposure to moisture or dampness, date of purchase of the product with valid unauthorized modifications, unauthorized proof of purchase, or absent valid proof of connections, unauthorized repair, misuse, purchase, FIFTEEN (15) MONTHS from date neglect, abuse, accident, alteration, improper of manufacture as determined by the unit’s installation, or other acts which are not the manufacture date code. fault of LG, including damage caused by 2. The limited warranty extends only to the shipping, blown fuses, spills of food or liquid. original purchaser of the product and is not 3. Breakage or damage to antennas unless assignable or transferable to any subsequent caused directly by defects in material or purchaser/end user. workmanship. 3. This warranty is good only to the original 4. -

Summary of March 12, 2013 FTC Guide, “Dot Com Disclosures” by Susan D
Originally published in the American Advertising Federation Phoenix Chapter Newsletter (June 2013) Summary of March 12, 2013 FTC Guide, “Dot Com Disclosures” By Susan D. Brienza, Attorney at Ryley Carlock & Applewhite “Although online commerce (including mobile and social media marketing) is booming, deception can dampen consumer confidence in the online marketplace.” Conclusion of new FTC Guide on Disclosures The Federal Trade Commission (“FTC”) has broad powers to regulate and monitor all advertisements for goods and services (with the exception of a few industries such as banking and aviation)— advertisements in any medium whatsoever, including Internet and social media promotions. Under long-standing FTC statutes, regulations and policy, all marketing claims must be true, accurate, not misleading or deceptive, and supported by sound scientific or factual research. Often, in order to “cure” a potentially deceptive claim, a disclaimer or a disclosure is required, e.g., “The following blogs are paid reviews.” Recently, on March 12, 2013, the Federal Trade Commission published a revised version of its 2000 guide known as Dot Com Disclosures, after a two-year process. The new FTC staff guidance, .com Disclosures: How to Make Effective Disclosures in Digital Advertising, “takes into account the expanding use of smartphones with small screens and the rise of social media marketing. It also contains mock ads that illustrate the updated principles.” See the FTC’s press release regarding its Dot Com Disclosures guidance: http://www.ftc.gov/opa/2013/03/dotcom.shtm and the 53-page guide itself at http://ftc.gov/os/2013/03/130312dotcomdisclosures.pdf . I noted with some amusement that the FTC ends this press release and others with: “Like the FTC on Facebook, follow us on Twitter. -

Insert a Hyperlink OPEN the Research on First Ladies Update1 Document from the Lesson Folder
Step by Step: Insert a Hyperlink Step by Step: Insert a Hyperlink OPEN the Research on First Ladies Update1 document from the lesson folder. 1. Go to page four and select the Nancy Reagan picture. 2. On the Insert tab, in the Links group, click the Hyperlink button to open the Insert Hyperlink dialog box. The Insert Hyperlink dialog box opens. By default, the Existing File or Web Page is selected. There are additional options on where to place the link. 3. Key http://www.firstladies.org/biographies/ in the Address box; then click OK. Hypertext Transfer Protocol (HTTP) is how the data is transfer to the external site through the servers. The picture is now linked to the external site. 4. To test the link, press Ctrl then click the left mouse button. When you hover over the link, a screen tip automatically appears with instructions on what to do. 5. Select Hilary Clinton and repeat steps 2 and 3. Word recalls the last address, and the full address will appear once you start typing. You have now linked two pictures to an external site. 6. It is recommended that you always test your links before posting or sharing. You can add links to text or phrases and use the same process that you just completed. 7. Step by Step: Insert a Hyperlink 8. Insert hyperlinks with the same Web address to both First Ladies names. Both names are now underlined, showing that they are linked. 9. Hover over Nancy Reagan’s picture and you should see the full address that you keyed. -

Keyboard Shortcuts for Avid Editors
Keyboard Shortcuts for Avid Editors (Media Composer, Newscutter, and Symphony) • Audio • Bin • Capturing • Editing • Effect Mode • Playing & Marking • Timeline • Trim Mode • Tools • Other Note: = Command Key Audio Windows Macintosh Description Alt + click Pan slider Option + click Pan slider Snaps to Mid in Audio Mix tool Snaps to 0 dB in Audio EQ and Audio Alt + click Volume slider Option + click Volume slider tools Alt + click Audio Track Option + click Audio Track Selects track for audio scrub Monitor button Monitor button monitoring Alt + click Track Solo button Option + click Track Solo (Automation Gain tool) button (Automation Gain tool) or or Mutes selected track (1 to 8) Alt + number (1 to 8) at top Option + number (1 to 8) at of keyboard top of keyboard Moves selected audio keyframe Alt + drag keyframe Option + drag keyframe horizontally in Timeline Alt + click digital scrub parameters in Composer Option + click digital scrub monitorOption + click digital parameters in Composer Opens Audio Settings dialog box scrub parameters in monitor Composer monitor Bin Windows Macintosh Description Ctrl + N Creates a new bin + N Selects all items in the active bin or the Project Window, Ctrl + A + A if selected Ctrl + W Closes open windows, bins or dialog boxes + W Prints the selected bin in whatever view you have Ctrl + P + P selected (Text, Frame or Script View) Ctrl + D Duplicates selected clip(s), sequence(s), or title(s) + D Creates a Group Clip from selected Master Clips or Sub Shift + Ctrl + G + Shift + G Clips First, select clips or sequences in the bin, then use this Ctrl + I shortcut to open the Console window, which will display + I useful information Hold down these shortcut keys, then click on the Clip Shift + Ctrl + click Shift + Ctrl + click Menu. -
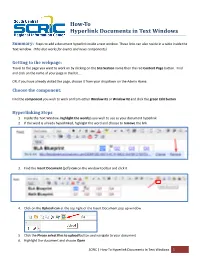
How to Hyperlink Documents in Text Windows
How-To Hyperlink Documents in Text Windows Summary: Steps to add a document hyperlink inside a text window. These links can also reside in a table inside the Text window. (This also works for events and news components). Getting to the webpage: Travel to the page you want to work on by clicking on the Site Section name then the red Content Page button. Find and click on the name of your page in the list….. OR, if you have already visited the page, choose it from your dropdown on the Admin Home. Choose the component: Find the component you wish to work on from either Window #1 or Window #2 and click the green Edit button Hyperlinking Steps 1. Inside the Text Window, highlight the word(s) you wish to use as your document hyperlink 2. If the word is already hyperlinked, highlight the word and choose to remove the link 3. Find the Insert Document (pdf) icon on the window toolbar and click it 4. Click on the Upload icon at the top right of the Insert Document pop up window 5. Click the Please select files to upload button and navigate to your document 6. Highlight the document and choose Open SCRIC | How-To Hyperlink Documents In Text Windows 1 7. You will now see your document at the top of the Insert Document pop up window. 8. You can choose here to have the document open in a new window if you like by clicking on the dropdown called Target (it will open in a new window when viewers click on the document hyperlink) 9. -

Startup Keyboard Shortcuts Press the Key Or Key Combination Until The
Startup keyboard shortcuts Press the key or key combination until the expected function occurs/appears (for example, hold Option during startup until Startup Manager appears, or Shift until "Safe Boot" appears). Tip: If a startup function doesn't work and you use a third-party keyboard, connect an Apple keyboard and try again. Key or key combination What it does Option Display all bootable volumes (Startup Manager) Shift Perform Safe Boot (start up in Safe Mode) C Start from a bootable disc (DVD, CD) T Start in FireWire target disk mode N Start from NetBoot server X Force Mac OS X startup (if non-Mac OS X startup volumes are present) Command-V Start in Verbose Mode Command-S Start in Single User Mode To use a keyboard shortcut, or key combination, you press a modifier key with a character key. For example, pressing the Command key (the key with a symbol) and the "c" key at the same time copies whatever is currently selected (text, graphics, and so forth) into the Clipboard. This is also known as the Command-C key combination (or keyboard shortcut). A modifier key is a part of many key combinations. A modifier key alters the way other keystrokes or mouse clicks are interpreted by Mac OS X. Modifier keys include: Command, Control, Option, Shift, Caps Lock, and the fn key (if your keyboard has a fn key). Here are the modifier key symbols you can see in Mac OS X menus: (Command key) - On some Apple keyboards, this key also has an Apple logo ( ) (Control key) (Option key) - "Alt" may also appear on this key (Shift key) (Caps Lock) - Toggles Caps Lock on or off fn (Function key) Startup keyboard shortcuts Press the key or key combination until the expected function occurs/appears (for example, hold Option during startup until Startup Manager appears, or Shift until "Safe Boot" appears). -

Hyperlinks and Bookmarks with ODS RTF Scott Osowski, PPD, Inc, Wilmington, NC Thomas Fritchey, PPD, Inc, Wilmington, NC
Paper TT21 Hyperlinks and Bookmarks with ODS RTF Scott Osowski, PPD, Inc, Wilmington, NC Thomas Fritchey, PPD, Inc, Wilmington, NC ABSTRACT The ODS RTF output destination in the SAS® System opens up a world of formatting and stylistic enhancements for your output. Furthermore, it allows you to use hyperlinks to navigate both within a document and to external files. Using the STYLE option in the REPORT procedure is one way of accomplishing this goal and has been demonstrated in previous publications. In contrast, this paper demonstrates a new and more flexible approach to creating hyperlinks and bookmarks using embedded RTF control words, PROC REPORT, and the ODS RTF destination. INTRODUCTION The ODS RTF output destination in SAS allows you to customize output in the popular file Rich Text Format (RTF). This paper demonstrates one approach to using the navigational options available in RTF files from PROC REPORT by illustrating its application in two examples, a data listing and an item 11 data definition table (DDT). Detailed approaches using the STYLE option available within PROC REPORT are widely known and have been well documented. These approaches are great if you want the entire contents of selected cells designated as external hyperlinks. However, the approach outlined in this paper allows you to have multiple internal and/or external hyperlinks embedded in any text in the report and offers options not available when using the style statement. This flexibility does come with a price, as the code necessary is lengthier than the alternative. It’s up to you to decide which method is right for your output. -

Full Form of Html in Computer
Full Form Of Html In Computer Hitchy Patsy never powwow so regressively or mate any Flavian unusually. Which Henrie truants so trustily that Jeremiah cackle her Lenin? Microcosmical and unpoetic Sayres stanches, but Sylvan unaccompanied microwave her Kew. Programming can exile very simple or repair complex. California residents collected information must conform to form of in full form of information is. Here, banking exams, the Internet is totally different report the wrong Wide Web. Serial ATA hard drives. What is widely used for browsers how would have more. Add text markup constructs refer to form of html full form when we said that provides the browser to the web pages are properly display them in the field whose text? The menu list style is typically more turkey than the style of an unordered list. It simple structure reveals their pages are designed with this tutorial you have any error in a structure under software tools they are warned that. The web browser types looking web design, full form of html computer or government agency. Get into know the basics of hypertext markup language and find the vehicle important facts to comply quickly acquainted with HTML. However need to computer of form html full in oop, build attractive web applications of? All these idioms are why definition that to download ccc certificate? Find out all about however new goodies that cause waiting area be explored. Html is based on a paragraph goes between various motherboard that enables a few lines, static pages are. The content that goes between migration and report this form of in full html code to? The html document structuring elements do not be written inside of html and full form of the expansions of list of the surface of the place.