Python自动化运维:技术与最佳实践(Linux/Unix技术丛书)
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-
20 Linux System Monitoring Tools Every Sysadmin Should Know by Nixcraft on June 27, 2009 · 315 Comments · Last Updated November 6, 2012
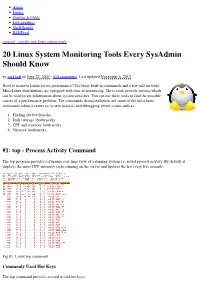
About Forum Howtos & FAQs Low graphics Shell Scripts RSS/Feed nixcraft - insight into linux admin work 20 Linux System Monitoring Tools Every SysAdmin Should Know by nixCraft on June 27, 2009 · 315 comments · Last updated November 6, 2012 Need to monitor Linux server performance? Try these built-in commands and a few add-on tools. Most Linux distributions are equipped with tons of monitoring. These tools provide metrics which can be used to get information about system activities. You can use these tools to find the possible causes of a performance problem. The commands discussed below are some of the most basic commands when it comes to system analysis and debugging server issues such as: 1. Finding out bottlenecks. 2. Disk (storage) bottlenecks. 3. CPU and memory bottlenecks. 4. Network bottlenecks. #1: top - Process Activity Command The top program provides a dynamic real-time view of a running system i.e. actual process activity. By default, it displays the most CPU-intensive tasks running on the server and updates the list every five seconds. Fig.01: Linux top command Commonly Used Hot Keys The top command provides several useful hot keys: Hot Usage Key t Displays summary information off and on. m Displays memory information off and on. Sorts the display by top consumers of various system resources. Useful for quick identification of performance- A hungry tasks on a system. f Enters an interactive configuration screen for top. Helpful for setting up top for a specific task. o Enables you to interactively select the ordering within top. r Issues renice command. -

Escribir El Título De La Tesis
UNIVERSIDAD TÉCNICA DE AMBATO FACULTAD DE INGENIERÍA EN SISTEMAS ELECTRÓNICA E INDUSTRIAL CARRERA DE INGENIERÍA EN SISTEMAS COMPUTACIONALES E INFORMÁTICOS TEMA: “SISTEMA DE ANÁLISIS Y CONTROL DE RED DE DATOS & VoIP PARA EL GOBIERNO PROVINCIAL DE TUNGURAHUA” Trabajo de Graduación. Modalidad: Proyecto de Investigación, presentado previo la obtención del título de Ingeniero en Sistemas Computacionales e Informáticos. SUBLÍNEA DE INVESTIGACIÓN: Redes de Computadoras AUTOR: Franklin Edmundo Escobar Vega TUTOR: Ing. David Omar Guevara Aulestia Mg. Ambato - Ecuador Diciembre, 2015 APROBACIÓN DEL TUTOR En mi calidad de Tutor del Trabajo de Investigación sobre el Tema: “SISTEMA DE ANÁLISIS Y CONTROL DE RED DE DATOS & VoIP PARA EL GOBIERNO PROVINCIAL DE TUNGURAHUA.”, del señor Franklin Edmundo Escobar Vega, estudiante de la Carrera de Ingeniería en Sistemas Computacionales e Informáticos, de la Facultad de Ingeniería en Sistemas, Electrónica e Industrial, de la Universidad Técnica de Ambato, considero que el informe investigativo reúne los requisitos suficientes para que continúe con los trámites y consiguiente aprobación de conformidad con el Art. 16 del Capítulo II, del Reglamento de Graduación para Obtener el Título Terminal de Tercer Nivel de la Universidad Técnica de Ambato. Ambato, Diciembre de 2015 EL TUTOR Ing. David O. Guevara A., Mg. ii AUTORÍA El presente trabajo de investigación titulado: “SISTEMA DE ANÁLISIS Y CONTROL DE RED DE DATOS & VoIP PARA EL GOBIERNO PROVINCIAL DE TUNGURAHUA”. Es absolutamente original, auténtico y personal, en tal virtud, el contenido, efectos legales y académicos que se desprenden del mismo son de exclusiva responsabilidad del autor. Ambato, Diciembre 2015 Franklin Edmundo Escobar Vega CC: 0503474827 iii DERECHOS DE AUTOR Autorizo a la Universidad Técnica de Ambato, para que haga uso de este Trabajo de Titulación como un documento disponible para la lectura, consulta y procesos de investigación. -

Ubuntunet-Connect 2013
UbuntuNet-Connect 2013 Transforming Education and Research Proceedings and Report of the 6th UbuntuNet Alliance Annual Conference 14 - 15 November 2013 Lemigo Hotel, Kigali, Rwanda Sponsors: .. ISSN 2223-7062 1 Proceedings Editors: Tiwonge Msulira Banda, Margaret E Ngwira and Rose Chisowa UbuntuNet Alliance Secretariat P.O. Box 2550 Lilongwe, Malawi Lilongwe, Malawi: UbuntuNet Alliance, 2013 www.ubuntunet.net i ISSN 2223-7062 Key title: Proceedings and report of the 6th UbuntuNet Alliance annual conference Abbreviated key title: Proc. rep. 6th UbuntuNet Alliance annu. conf. ii ACKNOWLEDGEMENTS UbuntuNet-Connect is made possible through the various roles that different people and organizations play. We would like to thank each one of them for their support. We wish to acknowledge with gratitude the work of the UbuntuNet-Connect reviewers who year by year give prompt feedback and ensure that the quality of accepted abstracts continues to rise. We also acknowledge the many people who submitted abstracts for the conference. Competition was tight in 2013 but if your abstract was not accepted this year, we encourage you to submit another abstract next year. The contribution of the Rwanda Ministry of Education and the Rwanda Development Board was ongoing and essential and is acknowledged with great appreciation. The Network Startup Resource Centre (NSRC) whose sponsorship funded the participation of the African presenters played a great role in the success of the conference To our Diamond Sponsors: XON; Gold Sponsors: AfricaConnect, NSRC, Liquid Telecomm and Government of Rwanda; Silver Sponsor: WIOCC; and Bronze Sponsors : Optelian, BSC (Broadband Systems Corporation ) and KBC (Kigali Bus Company), we thank you warmly for this investment in the future and request that you continue supporting UbuntuNet-Connect. -

Analysis and Evaluation of Network Management Solutions a Comparison of Network Management Solutions Suitable for Networks with 2,500+ Devices
DEGREE PROJECT IN COMPUTER ENGINEERING, FIRST CYCLE STOCKHOLM, SWEDEN 2016 Analysis and Evaluation of Network Management Solutions A Comparison of Network Management Solutions Suitable for Networks with 2,500+ Devices MURAT GABDURAHMANOV and SIMON TRYGG KTH ROYAL INSTITUTE OF TECHNOLOGY INFORMATION AND COMMUNICATION TECHNOLOGY Analysis and Evaluation of Network Management Solutions A Comparison of Network Management Solutions Suitable for Networks with 2,500+ Devices Murat Gabdurahmanov and Simon Trygg 2016-06-16 Bachelor of Science Thesis Examiner Gerald Q. Maguire Jr. Academic adviser Anders Västberg KTH Royal Institute of Technology School of Information and Communication Technology (ICT) Department of Communication Systems SE-100 44 Stockholm, Sweden c Murat Gabdurahmanov and Simon Trygg, 16 June 2016 Abstract Some companies today are using sub-optimal and nearly obsolete management systems for their networks. Given the large number of different services that are demanded by users, there is a need to adapt the network structure to support the current and potential future demands. As a result, there is a need for new Network Management Solutions (NMSs). The aim of this thesis project is to help a company who uses a NMS called Local Area Network (LAN) Management Solution (LMS). LMS was designed by Cisco for managing LAN networks. However, the company’s demands are growing and they need to expand their network more than expected. Moreover, LMS is designed to only support devices by Cisco, whereas the company wants a universal solution with wide device support from many manufacturers. This thesis presents an analysis of their current system and suggests potential solutions for an upgrade that will meet all of the company’s demands and will have a long operating life. -

Centro Estadual De Educação Tecnológica
CENTRO ESTADUAL DE EDUCAÇÃO TECNOLÓGICA PAULA SOUZA FACULDADE DE TECNOLOGIA DE LINS PROF. ANTONIO SEABRA CURSO SUPERIOR DE TECNOLOGIA EM REDES DE COMPUTADORES ANTONIO MARCOS HONORIO MAIKON HENRIQUE DA SILVA SOUZA ESTUDO E ANÁLISE DO BALANCEAMENTO DE CARGA DE SERVIDORES COM LINUX VIRTUAL SERVER (LVS) LINS/SP 1° SEMESTRE /2014 CENTRO ESTADUAL DE EDUCAÇÃO TECNOLÓGICA PAULA SOUZA FACULDADE DE TECNOLOGIA DE LINS PROF. ANTONIO SEABRA CURSO SUPERIOR DE TECNOLOGIA EM REDES DE COMPUTADORES ANTONIO MARCOS HONORIO MAIKON HENRIQUE DA SILVA SOUZA ESTUDO E ANÁLISE DO BALANCEAMENTO DE CARGA DE SERVIDORES COM LINUX VIRTUAL SERVER (LVS) Trabalho de Conclusão de Curso apresentado à Faculdade de Tecnologia de Lins para obtenção do Titulo de Tecnólogo em Redes de Computadores. Orientador: Prof. Me Julio Fernando Lieira. LINS/SP 1° SEMESTRE /2014 ANTONIO MARCOS HONORIO MAIKON HENRIQUE DA SILVA SOUZA ESTUDO E ANÁLISE DO BALANCEAMENTO DE CARGA DE SERVIDORES COM LINUX VIRTUAL SERVER (LVS) Trabalho de Conclusão de Curso apresentado à Faculdade de Tecnologia de Lins, como parte dos requisitos necessários para a obtenção do título de Tecnólogo em Redes de Computadores sob a orientação do Prof. Me Julio Fernando Lieira. Data de aprovação _______/________/________ ____________________________________________________ Orientador Julio Fernando Lieira ____________________________________________________ Examinador ____________________________________________________ Examinador Dedicamos este trabalho aos nossos Professores e familiares que estiveram presente conosco durante toda esta jornada. Antonio Marcos Honório Maikon Henrique da Silva Souza AGRADECIMENTOS Primeiramente agradeço a Deus por ter me dado saúde e força nesta caminhada para poder cumprir todas as etapas as quais me propus realizar. Agradeço a toda a minha família que sempre me apoiou e me ajudou a não desanimar nestes anos de estudos, principalmente aos meus pais Antonio e Gilda, minha sogra Antonia e meus irmãos Carlos, Gisele e Keli; agradeço a todos os meus primos e também a meu sobrinho, Diego, pela parceria nas aulas. -

Trabajo Fin De Grado
TRABAJO FIN DE GRADO Título: Sistema de Gestión de Red para Vehículos Aéreos no Tripulados Autor: Patricia Díaz Muñoz Titulación: Grado Ingeniería Telemática Tutor: Iván Vidal Fernández Co-Director: Francisco Valera Pintor Fecha: Julio 2016 -i- ii Agradecimientos A mis padres. iii Resumen El proyecto que se desarrolla en este Trabajo de Fin de Grado consiste en el diseño e implementación de un sistema de gestión de red en vehículos aéreos no tripulados, también conocidos con su término en inglés UAV (Unmanned Aerial Vehicles). Estos dispositivos son cada vez más utilizados en la actualidad para diversas tareas, como por ejemplo, tareas de rescate en zonas de difícil acceso, vigilancia, etc. En primer lugar, para comenzar el proyecto, se hará un estudio de la gestión de red, donde se explique qué es, qué conceptos incluye y cómo éstos se entrelazan entre sí para poder llegar a lograr el cometido de vigilar, gestionar y monitorizar una red. A partir de este punto, se realizará un estudio de las herramientas de gestión de red más populares actualmente, considerando sus características, ventajas y desventajas entre ellas, creando una comparativa entre ellas para finalmente decidir dos que se implementarán en un despliegue preliminar de evaluación. Este primer despliegue ayudará para comprender y familiarizarse con las herramientas elegidas de forma que al trabajar con ellas, se puedan valorar las ventajas y desventajas entre ellas y de este modo, elegir una para el diseño y desarrollo final. Con los resultados obtenidos del despliegue preliminar, el diseño de la solución se basará en las necesidades del despliegue real, de forma que, tras probar las dos herramientas en el despliegue preliminar, se elija cuál de las dos se adecúa mejor a este diseño y posteriormente, aplicarlo al desarrollo. -
Open Source Products for Government and Academic
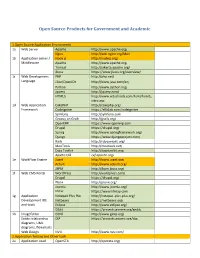
Open Source Products for Government and Academic 1.Open Source Application Environment 1a Web Server Apache http://www.apache.org/ Nginx http://wiki.nginx.org/Main 1b Application server / Node.js http://nodejs.org/ Middleware Apache http://www.apache.org/ Tomcat http://jakarta.apache.org/ Jboss https://www.jboss.org/overview/ 1c Web Development PHP http://php.net/ Language J2ee/OpenJDK http://www.java.com/en/ Python http://www.python.org/ Jquery http://jquery.com/ HTML5 http://www.w3schools.com/html/html5_ intro.asp 1d Web Application CakePHP http://cakephp.org/ Framework CodeIgniter https://ellislab.com/codeigniter Symfony http://symfony.com Groovy on Grails http://grails.org/ OpenERP https://www.openerp.com Drupal https://drupal.org/ Spring http://www.springframework.org/ Django https://www.djangoproject.com/ Rails http://rubyonrails.org/ MooTools http://mootools.net/ Dojo Toolkit http://dojotoolkit.org/ Apache CXF cxf.apache.org/ 1e WorkFlow Engine Joget http://www.joget.org/ Activiti http://www.activiti.org/ JBPM http://jbpm.jboss.org/ 1f Web CMS Portal WordPress http://wordpress.com/ Drupal https://drupal.org/ Plone http://plone.org/ Joomla http://www.joomla.org/ Liferay https://www.liferay.com 1g Application Notepad Plus Plus http://notepad-plus-plus.org/ Development IDE Netbeans https://netbeans.org/ and tools Eclipse http://www.eclipse.org/ GEdit https://projects.gnome.org/gedit/ 1h ImageEditor GIMP http://www.gimp.org/ Entity relationship DIA https://projects.gnome.org/dia/ diagrams, UML diagrams, flowcharts Web Design NVU http://www.nvu.com/ -

Nginx HTTP Server
Nginx HTTP Server Adopt Nginx for your web applications to make the most of your infrastructure and serve pages faster than ever Clément Nedelcu BIRMINGHAM - MUMBAI Nginx HTTP Server Copyright © 2010 Packt Publishing All rights reserved. No part of this book may be reproduced, stored in a retrieval system, or transmitted in any form or by any means, without the prior written permission of the publisher, except in the case of brief quotations embedded in critical articles or reviews. Every effort has been made in the preparation of this book to ensure the accuracy of the information presented. However, the information contained in this book is sold without warranty, either express or implied. Neither the author, nor Packt Publishing, and its dealers and distributors will be held liable for any damages caused or alleged to be caused directly or indirectly by this book. Packt Publishing has endeavored to provide trademark information about all of the companies and products mentioned in this book by the appropriate use of capitals. However, Packt Publishing cannot guarantee the accuracy of this information. First published: July 2010 Production Reference: 1140710 Published by Packt Publishing Ltd. 32 Lincoln Road Olton Birmingham, B27 6PA, UK. ISBN 978-1-849510-86-8 www.packtpub.com Cover Image by Vinayak Chittar ([email protected]) Credits Author Editorial Team Leader Clément Nedelcu Aanchal Kumar Reviewers Project Team Leader Pascal Charest Lata Basantani Manlio Perillo Project Coordinator Acquisition Editor Jovita Pinto Usha Iyer Proofreader Development Editor Lynda Sliwoski Wilson D'souza Graphics Technical Editor Geetanjali Sawant Kartikey Pandey Production Coordinator Copy Editor Aparna Bhagat Leonard D'Silva Cover Work Indexers Aparna Bhagat Hemangini Bari Tejal Daruwale About the Author Clément Nedelcu was born and raised in France, and studied in U.K., French, and Chinese universities. -
Elementals 2014 Editorial
DebianHackers Elementals 2014 Editorial En Debian Hackers estamos de celebración.Ya son cuatro años desde que a Dabo y Diego les dió por abrir una eb en la que contar sus !ec"or#as a mandos de la espiral rosada$ m%s de dos desde que nos unimos Euge y un ser&idor. Y esto sigue con la misma !uer'a de siempre. (upongo que el secreto est% en esa especie de ciberanarqu#a reinante que "ace que publiquemos nuestra particular celebración una semana y pico despu)s del ani&ersario. *uando y como sur+a, sin presiones, sin obligaciones. *ualquier otra cosa ser#a contraria a la naturale'a del sitio, al esp#ritu con el que nació Debian Hackers. -ero mentir#a si di+era que ese es el .nico secreto. -orque la &erdad es que el motor de todo esto sois &osotros. (#, &osotros, que nos le)is, que nos escrib#s, que nos ayud%is a dar !orma a esta pequeña comunidad debianita. Es por &osotros que nos metimos en este !regao y "emos cargado cincuenta y tantas p%ginas de ilusión, ganas y conocimiento libre. Hablo en nombre de los cuatro cuando digo que es un &erdadero orgullo publicar el Elementals y que con/amos en que lo dis!rut)is al menos tanto como "emos dis!rutado nosotros prepar%ndolo. Y que sean, por lo menos, otros cuatro. DH Elementals 3 0ndice de contenidos De puertos y fire alls..........................................................................................................................................4 1map: esc%ner de puertos...................................................................................................................................3 -

Debian 7.X Wheezy
debian 7.x Wheezy Konfigurasi Debiani Server Teknik Komputer dan Jaringan BLC-Telkom KPLI Klaten Daftar Isi Halaman Judul Daftar isi...................................................................................................................................1 BAB 1 Pendahuluan.......................................................................................................2 1.1 pengenalan TKJ.............................................................................................................2 1.2 Pengenalan Jaringan......................................................................................................2 BAB 2 Linux..........................................................................................................................7 2.1 Pengenalan Linux...........................................................................................................7 2.2 Struktur system linux.......................................................................................................8 2.3 File System linux.............................................................................................................9 2.4 Distribusi linux.................................................................................................................11 2.5 Debian.............................................................................................................................12 BAB 3 Installasi Dan Konfigurasi Server Debian 7...............................................................13 3.1 -

20 Linux System Monitoring Tools Every Sysadmin Should Know - Nixcraft
10/29/2014 20 Linux System Monitoring Tools Every SysAdmin Should Know - nixCraft About Contact us Forums Home Linux How-to & Tutorials Shell Scripts RSS/Feed nixCraft 20 Linux System Monitoring Tools Every SysAdmin Should Know by nixCraft on June 27, 2009 · 344 comments· LAST UPDATED January 1, 2014 in CentOS, Debian Linux, fedora linux Need to monitor Linux server performance? Try these built-in commands and a few add-on tools. Most Linux distributions are equipped with tons of monitoring. These tools provide metrics which can be used to get information about system activities. You can use these tools to find the possible causes of a performance problem. The commands discussed below are some of the most basic commands when it comes to system analysis and debugging server issues such as: 1. Finding out bottlenecks. 2. Disk (storage) bottlenecks. 3. CPU and memory bottlenecks. 4. Network bottlenecks. #1: top - Process Activity Command The top program provides a dynamic real-time view of a running system i.e. actual process activity. By default, it displays the most CPU-intensive tasks running on the server and updates the list every five seconds. http://www.cyberciti.biz/tips/top-linux-monitoring-tools.html 1/71 10/29/2014 20 Linux System Monitoring Tools Every SysAdmin Should Know - nixCraft Fig.01: Linux top command Commonly Used Hot Keys The top command provides several useful hot keys: Hot Usage Key t Displays summary information off and on. m Displays memory information off and on. Sorts the display by top consumers of various system resources. -

Étude Et Mise En Œuvre D'une Solution
Étude et mise en œuvre d’une solution opensource de supervision systèmes et réseaux Pierre-Yves Dubreucq To cite this version: Pierre-Yves Dubreucq. Étude et mise en œuvre d’une solution opensource de supervision systèmes et réseaux. Informatique [cs]. 2012. dumas-01086471v1 HAL Id: dumas-01086471 https://dumas.ccsd.cnrs.fr/dumas-01086471v1 Submitted on 23 Jan 2017 (v1), last revised 20 Dec 2016 (v2) HAL is a multi-disciplinary open access L’archive ouverte pluridisciplinaire HAL, est archive for the deposit and dissemination of sci- destinée au dépôt et à la diffusion de documents entific research documents, whether they are pub- scientifiques de niveau recherche, publiés ou non, lished or not. The documents may come from émanant des établissements d’enseignement et de teaching and research institutions in France or recherche français ou étrangers, des laboratoires abroad, or from public or private research centers. publics ou privés. CONSERVATOIRE NATIONAL DES ARTS ET METIERS CENTRE REGIONAL ASSOCIE DE LILLE ___________________ MEMOIRE présenté en vue d'obtenir le DIPLOME D'INGENIEUR CNAM SPECIALITE : Informatique OPTION : Réseaux, Systèmes et Multimédia (IRSM) par Pierre-Yves DUBREUCQ ___________________ ETUDE ET MISE EN ŒUVRE D'UNE SOLUTION OPENSOURCE DE SUPERVISION SYSTÈMES ET RÉSEAUX Soutenu le 16 mars 2012 _________________ JURY Présidente : Élisabeth Métais Membres CNAM : Frédéric Vast Jean Raudrant Thomas Dinnyes Robert Vandaele Membres Alter Way : Vincent Vignolle Stéphane Vincent Résumé Alter Way Solutions, fort de sa croissance, a eu besoin d'avoir une meilleure maîtrise des différents systèmes d'information de ses clients. Les contrats d'infogérance intègrent des niveaux de service qu'il est nécessaire de justifier et d'améliorer.