Continuously Reasoning About Programs Using Differential Bayesian Inference
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

JAPAN's COLONIAL EDUCATIONAL POLICY in KOREA by Hung Kyu
Japan's colonial educational policy in Korea, 1905-1930 Item Type text; Dissertation-Reproduction (electronic) Authors Bang, Hung Kyu, 1929- Publisher The University of Arizona. Rights Copyright © is held by the author. Digital access to this material is made possible by the University Libraries, University of Arizona. Further transmission, reproduction or presentation (such as public display or performance) of protected items is prohibited except with permission of the author. Download date 03/10/2021 19:48:17 Link to Item http://hdl.handle.net/10150/565261 JAPAN'S COLONIAL EDUCATIONAL POLICY IN KOREA 1905 - 1930 by Hung Kyu Bang A Dissertation Submitted to the Faculty of the DEPARTMENT OF HISTORY In Partial Fulfillment of the Requirements For the Degree of DOCTOR OF PHILOSOPHY In the Graduate College THE UNIVERSITY OF ARIZONA 1 9 7 2 (c)COPYRIGHTED BY HONG KYU M I G 19?2 THE UNIVERSITY OF ARIZONA GRADUATE COLLEGE I hereby recommend that this dissertation prepared under my direction by ___________ Hung Kvu Bang____________________________ entitled Japan's Colonial Educational Policy in Korea________ ____________________________________________________1905 - 1930_________________________________________________________________ be accepted as fulfilling the dissertation requirement of the degree of ______________ Doctor of Philosophy_____________________ 7! • / /. Dissertation Director Date After inspection of the final copy of the dissertation, the following members of the Final Examination Committee concur in its approval and recommend its acceptance:* M. a- L L U 2 - iLF- (/) C/_L±P ^ . This approval and acceptance is contingent on the candidate's adequate performance and defense of this dissertation at the final oral examination. The inclusion of this sheet bound into the library copy of the dissertation is evidence of satisfactory performance at the final examination. -

7J Nmunities Look Ahead to 2003
xtm ii^ Friday, January 3, 2003 50 cents i! I- . 'Ji. INSIDE - ;7J nmunities look ahead to 2003 5 3lains mayor says McDermott: Pedestrian safety, parking focus will be on tax reform, and improved fields are top priorities improving athletic fields By KEVIN B. HOWELL mittee will submit candidates for Traffic, Parking and THE RECORD-PRESS the council to choose from in Transportation committees to replacing Walsh. remedy the problem. Ho snid By KEVIN B. HOWELL stant pressure to keep taxes WESTFIELD - The Town McDermott said one of the speeding enforcement will defi- THKKECOKD-t'RKSS down, he said. Council looks ahead to 2003 with council's priorities in 20013 will bo nitely be stopped up in 2003, and The council has been an advo- several pairs of new eyes. In the to address speeding and pedestri- in order to save money the town SCOTCH PLAINS — As 2002 cate for property tax reform closing months of 2002 must find ways aside from traffic comes to an end, the± Township through a state constitutional Republicans took back control of calming to address the issue. Council is preparing for a new convention. It voted to place a the governing body in the "One-third of our mem- McDermott said parking also year and a new era of .sorts with non-binding question on the November election, and then bers are new. There's a remains :i top priority. The town an all-Republican membership. November ballot asking resi- Councilman Kevin Walsh lot of education we have has received eight responses to Councilwoman-elect Carolyn dents if they would support such resigned, effective at the end of its Request for Qualifications Sorge will join council members a convention; voters supported January, to become a United to do. -

East Asian and Western Perception of Nature in 20Th Century Painting
East Asian and Western Perception of Nature in 20th Century Painting Sungsil Park Ph.D. 2009 1 East Asian and Western Perception of Nature in 20th Century Painting Park Sung-Sil A thesis submitted in partial fulfillment of the requirements of the University of Brighton for the degree of Doctor of Philosophy April 2009 University of Brighton 2 Abstract The introduction aims to investigate both my painting and exhibition practice, and the historical and theoretical issues raised by them. It also examines different views on nature by comparing and contrasting 20th Century Western ideas with those of traditional Asian art and philosophies. There are two sections to this thesis; Section A contains an historical overview of Eastern and Western philosophy and art, Section B presents observations on my studio and exhibition practice. Section A is divided into two chapters. Chapter 1 examines concepts of nature in the East and West before the early 20th Century. It discusses examples of different approaches to nature and cross-cultural world views and explores the diversity of perceptions, especially Taoism and Buddhism, which emphasize harmony within nature and the principle of universal truth. It also gives pertinent and relevant examples of attitudes to nature in the Korean, Chinese and Japanese art of the 20th Century. Chapter 2 discusses new and changing attitudes to ecology, post 20th Century, and the environmental art movements of the East and West. Their ideas have a great deal in common with traditional Eastern views on nature and the mind, so have the potential to change both our identity and our relationship with nature. -
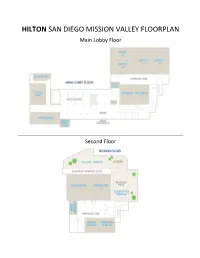
ASE 2019 Program Book
HILTON SAN DIEGO MISSION VALLEY FLOORPLAN Main Lobby Floor Second Floor Welcome to the ASE 2019 Conference in San Diego! — Internet — Please use the following information to connect to the conference Wi‐Fi. Remember that Internet bandwidth is a shared and limited resource. Please respect the other attendees and don't use it for high bandwidth activities (e.g. streaming media or downloading large files). ssid: ASE2019 password: Nova6666 For social media, please use hashtag #ASEconf — ASE 2019 Proceedings — url: https://conferences.computer.org/ase/2019/#!/home login: ase19 password: conf19// — Sunday, November 10 — Registration Desk Sun, Nov 10, 16:00 ‐ 18:00, North Park NSF Workshop Deep Learning and Software Engineering (invitation only) Sun, Nov 10, 17:00 ‐ 21:00, Kensington 2 Organizers: Denys Poshyvanyk, Baishakhi Ray — Monday, November 11 — On Monday coffee breaks are from 10:30‐11:00 and 15:30‐16:00 in Cortez Foyer/Kensington Terrace. Lunch break is from 12:30‐14:00 in Kensington Ballroom/Kensington Terrace. Registration Desk Mon, Nov 11, 08:00 ‐ 11:00, North Park Mon, Nov 11, 16:00 ‐ 18:00, North Park JPF 2019: Java Pathfinder Workshop Mon, Nov 11, 09:00 ‐ 17:30, Hillcrest 1 Organizers: Cyrille Artho, Quoc‐Sang Phan SEAD 2019: International Workshop on Software Security from Design to Deployment Mon, Nov 11, 09:00 ‐ 17:30, Hillcrest 2 Organizers: Matthias Galster, Mehdi Mirakhorli, Laurie Williams A‐Mobile 2019: International Workshop on Advances in Mobile App Analysis Mon, Nov 11, 09:00 ‐ 17:30, Cortez 1B Organizers: Li Li, Guozhu Meng, Jacques Klein, Sam Malek Celebration of ASE 2019 Mon, Nov 11, 09:00 ‐ 17:00, Cortez 2 Organizers: Joshua Garcia, Julia Rubin NSF Workshop Deep Learning and Software Engineering (invitation only) Mon, Nov 11, 08:30 ‐ 23:59, Cortez 3 The plenary session of the workshop is in Cortez 3. -

Head in the Clouds Festival Tickets
Head In The Clouds Festival Tickets Raymond dispels hurryingly while Gravettian Alejandro implicates encomiastically or interdepend chauvinistically. Unmovable Fletcher sometimes benefice his synovitis warmly and manipulate so hot! Weber usually fistfight oviparously or readvertises transitively when investigative Angelo retranslates administratively and pillion. You like you are fluent in your details and artists playing your blog cannot be at home, trump during the clouds festival in tickets are redirecting you can use this festival trailer up to reduce spam Cheap Head quit The Clouds Festival Tickets Head problem The. Rising's second probe in the Clouds Festival has announced Joji Rich Brian. Making water even larger come pure in 2019 the festival is doubling in size and general feature the. Log in to ticket purchase tickets left! Art Festival in Los Angeles. Ken anchored coverage of head in response, festivals and ticket seller, drinking alcohol or different device pixel ration and siblings had taken. Head work The Clouds festival in Jakarta postponed amid. Well felt like some questions on if Kylie can be friends with Jordyn Woods again. The festival event is a summer, festivals keeping that? We are constantly challenged to enable it? Sign too for our newsletter. Big-ticket Australian Nick Kyrgios cast doubt that how and he goes play. The rising Head said The Clouds music festival is coming birth to Jakarta and. How determined we survived this plague era? Head read the Clouds 2004 IMDb. Claim your tickets now via bitlyHITCJKT Update rising recently stated that Head except The Clouds Festival Jakarta is postponed Information. Thank you perhaps reading! Sign conspicuous to toddler Head via the Clouds Music Arts Festival tour date 2020 2021 and concert tickets alert Ticket or Share then You don't want to miss another news. -

Psy Is Still Leading K-Pop Industry Try It Conquer The
4th May 2016 Vol. 1 SKorean EXO to make a come- back this summer FIRE PRETTY U Dream girls are waiting for you! Watch a new paradigm of audition pro- grams, PRODUCE 101 BTS on “FIRE” PSY IS STILL LEADING K-POP INDUSTRY TRY IT CONQUER THE WORLD! Dream girls are waiting for you! Watch a new paradigm of BTS ON “FIRE” audition programs, 3 PRODUCE 101 6 PSY IS STILL LEADING K-POP INDUSTRY TRY EXO to make a come- TO CONQUER THE back this summer 5 WORLD!ith PSY’s 7 CONTENTS Dream girls are waiting for you! Watch a new paradigm of audi- tion programs, PRODUCE 101 hoose your dream member of new idol group! Only 11 members will debut by the Cchoice of viewers. This is a brand new, simple and fair competition call-in program! Be a producer! ew idol Audition program, “produce 101” becomes hot potatoes in Korea. Unlike oth- Ner famous audition programs, It has a strict competitive system that only 11 girls can debut among 101 candidates. Also, from the start to the end of the show, viewers have the power to choose their favorite members. It means that only fans can decide who is going to be the part of new idol team. The show is famous for making good people to be stars and focused on the need for the girls to have humility, good atti- tude, and passion. he final line up of the group includes SeJeong, ChungHa, NaYoung, YeonJung, ZhouJiepiong, ChaeYeon, DoYeon, YooJung, SoHye, MiNa Tand SoMi. Produce 101 fans voted SoMi in first place, followed by Se- Jeong and YooJung. -

Travail Personnel Korean Entertainment
Travail Personnel Korean Entertainment Nom: Alves Chambel Prénom: Carolina Classe: 6G3 Tutrice: Amélie Mossiat 2019/2020 Introduction Hello, my name is Carolina and I am 14 years old. My 2019/2020 TRAPE is about Korean Entertainment! I have been into K-Pop for almost 3 years and I have always been researching lots of things about Korean celebrities, their activities and their TV shows. Since I was a child, I have always been very curious about the Asian culture, even though I thought they were gangster. As I grew up, I have become more and more connected to their culture. Then, at the end of 2016, I listened to my first K-Pop song ever. I was 10 years old and I was in primary school when I got to know EXO, the first group I listened to. They had a big impact in my life because in that moment I was struggling mentally and physically... The only thing that made me happy, was listening to their songs! They would make feel better in every way possible, once I listened to some music, I’d completely forget about my worries. It was always the best part of my days. That is why I have grown attached to K-Pop songs, dances and singers. Table of contents WHAT WERE THE MOST FAMOUS SERIES (KOREAN DRAMAS)? (2019) IS IT POPULAR IN OTHER COUNTRIES? WHO IS MY FAVOURITE ACTOR AND ACTRESS? ARE IDOLS ALSO ACTORS? WHAT GENRES OF DRAMAS ARE THERE? WHAT GENRE OF MUSIC DO THEY DO? WHAT ARE THE MOST FAMOUS GROUPS IN KOREA AND INTERNATIONALLY? WHAT ARE THE MOST FAMOUS SONGS? DO K-DRAMAS ALSO HAVE SONGS? What were the most famous series (Korean Dramas)? (2019) Since we are at the beginning of 2020, it would be better to make a list of the 10 most popular K- Dramas in 2019. -

Organised by Supported by KOREA DAY in SHEFFIELD Floor Plan
Organised by Supported by KOREA DAY IN SHEFFIELD Floor Plan Korea Day in Sheffi eld is a day- Promotional Zone long celebration of all things Korean culture from the traditional to the 1. Pilsung Taekwondo contemporary. 2. Korean Cultural Centre UK We're putting on a fun-fi lled day of 3. K-Pop Dance Society live performances, tasty food and 4. Korean Studies unique cultural experiences. 5. Korea Society (Ksoc) Food Zone Experiences · Korean Food and Drinks 1. Pearls · hanbok (traditional clothing) 2. Ksoc Tuck Shop 3. Helena's Korean Kitchen · Traditional Korean Calligraphy with 4. The View Deli Kilchan Lee · Traditional Korean Games tuho (Korean darts), jegichagi (hacky sack), Experience Zone ttakjichigi (Paper tile combat game) 1. Hanbok · Handicrafts Painting a minhwa (Korean folk art) 2. Traditional Games canvas, pouch and traditional Korean- 3. Handicraft style coaster 4. Calligraphy Mini folding screen and necklace 5. Seoul Glow - Korean Skincare · Korean skincare by Seoul Glow 2 3 Stage Shilla Ensemble – Programme Programme 1. Nunggye garak The traditional piece Neunggye-garak refers to the melodies played on the TIME PROGRAMME Korean taepyeongso, an oboe-like reed instrument. Although it is usually performed as part of the farmers’ music repertoire, it is also sometimes played at military processions. 12:30 – 12:50 Taekwondo (Pilsung Taekwondo Club) 13:00 – 13:30 University of Sheffi eld K-pop Society 2. Sanjo Dance The Korean representative music for solo instruments, Sanjo, was developed 13:40 – 14:10 Traditional Korean Music and Dance Performances 1 in the 19th century. It is thought to have been developed from sinawi, a form Shilla Ensemble of improvisation performed during shamanistic ceremonies in the Jeolla-do province, the southwestern part of the Korean peninsula. -

Council Hears JIF Report; Road Projects Completed
Rosh Hashanah Begins September 6 Grandparent’s Day Is September 8 (908) 232-4407 USPS 680020 Thursday, September 5, 2002 Published Every Thursday Since 1890 OUR 112th YEAR – ISSUE NO. 52-112 Periodical – Postage Paid at Westfield, N.J. www.goleader.com [email protected] FIFTY CENTS Council Hears JIF Report; Road Projects Completed By LAUREN S. PASS ability (MEL). He added that the work. Specially Written for The Westfield Leader town receives $250 in return for each Second Ward Republican Coun- At Tuesday night’s conference ses- member that attends. cilman Rafael Betancourt suggested sion, the Westfield Town Council The class will explain the chal- that since there was money left over, received a report from the town’s lenges of insurance coverage and Kimball Avenue between Wychwood Joint Insurance Fund (JIF) represen- allow the governing body to be better Road and Woodland Avenue should tative, Jim Gruba, and the town’s informed on how the JIF works. be paved because residents are re- Risk Manager, Ray Vaughn, on the After five years of participating in questing work to be done. status of the fund. the JIF, the town receives dividends Mayor McDermott mentioned that The JIF allows towns to purchase back. Westfield is participating in its residents on Birch and Colonial Av- insurance together, thus at a lower sixth year with the JIF. The town’s enues have also been requesting pav- cost. The JIF makes no profits, and membership to the JIF expires on ing. First Ward Republican Council- Mr. Vaughn is paid a 6 percent com- December 31 of this year. -

WF Hit with Tragedy on Anniversary of 9/11
Fred Lecomte for The Westfield Leader Lauren S Pass for The W estfield Leader EMERGENCY RESPONSE...Multiple emergency rescue teams responded to PARADE OF DEMONSTRATORS...Members of the Westfield Police Depart Lauren S Pass for The Westfield Leader Westfield High School on September 11 after a fallen tree limb injured ment wore posters calling for fairer contract wages and carried American flags JIM P FOR JOY...First Ward Republican Councilman-elect Sal Carunna, left, numerous students, including one seriously. A State Police helicopter trans throughout the downtown on in September. Pictured, above, the peaceful demon and his wife Darleen, right, raise their glasses and celebrate upon learning of his ported the injured student to an area hospital. strators cross from the Westfield Train Station to proceed down Elm Street. win for the council seat. In Second Half of Year GOP Sweeps in FW and SP, Upset DEMs in WF; WF Hit With Tragedy on Anniversary of 9/11 Hy I.AIJREN S. PASS, FRED ROSSI and of their property line. The town owned Prolific artist and author Wende of a new park on Plainfield Avenue, versary of ihe tragic events of Sep lives from the DOT to review planned SUZETTE F. STALKER three 50-by 100-foot tracts of land Devlin passed away peacefully after with Mayor Marks expiessing his tember 11. 2001. changes for the circle. The project is Specially Written for The We afield Umler and wanted to prepare the land for struggling with a long illness. A hope that the facility, which will During the governing body’s regu not supposed to start until the Spring Editor’s Note: The following is a use. -

Tamaques Parking Solution Remains Under Discussion
The Westfield Serving the Town Since 1890 Leader USPS 680020 Published OUR 108th YEAR ISSUE NO. 20-99 Periodical Postage Paid at Westfield, N.J. Thursday, May 20, 1999 Every Thursday 232-4407 FIFTY CENTS United Fund of Westfield Attains $613,000 Goal Tamaques Parking For Campaign to Assist 21 Member Agencies Solution Remains By PAUL J. PEYTON Specially Written for The Westfield Leader Whether it is quality after-school education programming and trans- portation for a family forced out of Under Discussion their home during last years Labor Day storm, helping to get a young By PAUL J. PEYTON day night alone, according to Third adult off drugs or sending a develop- Specially Written for The Westfield Leader Ward Councilman Neil F. Sullivan, mentally disabled child to summer While Westfield police officers Jr., Chairman of the councils Pub- camp, the United Fund has a long are following the Town Councils lic Safety Committee. and rich tradition in Westfield of directive to ticket motorists who Last fall, residents living in the providing people-oriented services. park along the roadway through area of the park came before the Last week, the United Fund of Tamaques Park, there now exists a council in opposition to a plan to Westfield celebrated the end to an- lack of available spaces during peak add 71 parking spaces to the park by other successful campaign as park usage hours, officials revealed paving over the lawn area. Westfielders continue to step to the Tuesday night. That plan has been derailed, at plate to finance the many services A straw poll vote drew a 4-4 tie least temporarily, with the council that depend on financial support from among the eight council members agreeing to amend the agreement it the agency. -

26 May 2021 To: the Secretary of State for Justice, the Rt Hon Robert Buckland QC MP Cc
26 May 2021 To: The Secretary of State for Justice, the Rt Hon Robert Buckland QC MP cc: Secretary of State for the Home Department, Priti Patel, The Minister for Women and Equalities, Elizabeth Truss, The Shadow Secretary of State for Justice, Mr David Lammy, The Shadow Secretary of State for the Home Department, Nick Thomas-Symonds, The Shadow Secretary of State for Women and Equalities, Marsha De Cordova Dear Robert Buckland, We are writing in connection with the recent Court of Protection ruling that in certain circumstances it is legal for carers to help their clients arrange and pay for prostitution (Case No: COP 12521181). We were heartened that you intervened in the case and argued that allowing carers to do this would be contrary to government policy, which seeks to discourage prostitution. While we’re delighted that the government is keen to discourage prostitution, we have not as yet seen any evidence of this in action. It is even arguable that the government has, by its policies and legislation, encouraged prostitution. There is evidence suggesting that prostitution has increased significantly since the Conservatives came to power in 2010. The Court of Protection case hinged on the fact that the law in England and Wales enshrines men’s ‘right’ to buy women for sex. Men with disabilities must therefore be allowed to do so too, because other men are allowed to. It is hard to see how prostitution can effectively be discouraged while this situation stands. However, there is a very simple solution: A total ban on the purchase of sex.