Notes-Cso-Unit-2
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-
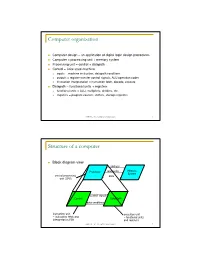
Computer Organization
Computer organization Computer design – an application of digital logic design procedures Computer = processing unit + memory system Processing unit = control + datapath Control = finite state machine inputs = machine instruction, datapath conditions outputs = register transfer control signals, ALU operation codes instruction interpretation = instruction fetch, decode, execute Datapath = functional units + registers functional units = ALU, multipliers, dividers, etc. registers = program counter, shifters, storage registers CSE370 - XI - Computer Organization 1 Structure of a computer Block diagram view address Processor read/write Memory System central processing data unit (CPU) control signals Control Data Path data conditions instruction unit execution unit œ instruction fetch and œ functional units interpretation FSM and registers CSE370 - XI - Computer Organization 2 Registers Selectively loaded – EN or LD input Output enable – OE input Multiple registers – group 4 or 8 in parallel LD OE D7 Q7 OE asserted causes FF state to be D6 Q6 connected to output pins; otherwise they D5 Q5 are left unconnected (high impedance) D4 Q4 D3 Q3 D2 Q2 LD asserted during a lo-to-hi clock D1 Q1 transition loads new data into FFs D0 CLK Q0 CSE370 - XI - Computer Organization 3 Register transfer Point-to-point connection MUX MUX MUX MUX dedicated wires muxes on inputs of each register rs rt rd R4 Common input from multiplexer load enables rs rt rd R4 for each register control signals MUX for multiplexer Common bus with output enables output enables and load rs rt rd R4 enables for each register BUS CSE370 - XI - Computer Organization 4 Register files Collections of registers in one package two-dimensional array of FFs address used as index to a particular word can have separate read and write addresses so can do both at same time 4 by 4 register file 16 D-FFs organized as four words of four bits each write-enable (load) 3E RB read-enable (output enable) RA WE (- WB (. -

Review of Computer Architecture
Basic Computer Architecture CSCE 496/896: Embedded Systems Witawas Srisa-an Review of Computer Architecture Credit: Most of the slides are made by Prof. Wayne Wolf who is the author of the textbook. I made some modifications to the note for clarity. Assume some background information from CSCE 430 or equivalent von Neumann architecture Memory holds data and instructions. Central processing unit (CPU) fetches instructions from memory. Separate CPU and memory distinguishes programmable computer. CPU registers help out: program counter (PC), instruction register (IR), general- purpose registers, etc. von Neumann Architecture Memory Unit Input CPU Output Unit Control + ALU Unit CPU + memory address 200PC memory data CPU 200 ADD r5,r1,r3 ADD IRr5,r1,r3 Recalling Pipelining Recalling Pipelining What is a potential Problem with von Neumann Architecture? Harvard architecture address data memory data PC CPU address program memory data von Neumann vs. Harvard Harvard can’t use self-modifying code. Harvard allows two simultaneous memory fetches. Most DSPs (e.g Blackfin from ADI) use Harvard architecture for streaming data: greater memory bandwidth. different memory bit depths between instruction and data. more predictable bandwidth. Today’s Processors Harvard or von Neumann? RISC vs. CISC Complex instruction set computer (CISC): many addressing modes; many operations. Reduced instruction set computer (RISC): load/store; pipelinable instructions. Instruction set characteristics Fixed vs. variable length. Addressing modes. Number of operands. Types of operands. Tensilica Xtensa RISC based variable length But not CISC Programming model Programming model: registers visible to the programmer. Some registers are not visible (IR). Multiple implementations Successful architectures have several implementations: varying clock speeds; different bus widths; different cache sizes, associativities, configurations; local memory, etc. -

The Von Neumann Computer Model 5/30/17, 10:03 PM
The von Neumann Computer Model 5/30/17, 10:03 PM CIS-77 Home http://www.c-jump.com/CIS77/CIS77syllabus.htm The von Neumann Computer Model 1. The von Neumann Computer Model 2. Components of the Von Neumann Model 3. Communication Between Memory and Processing Unit 4. CPU data-path 5. Memory Operations 6. Understanding the MAR and the MDR 7. Understanding the MAR and the MDR, Cont. 8. ALU, the Processing Unit 9. ALU and the Word Length 10. Control Unit 11. Control Unit, Cont. 12. Input/Output 13. Input/Output Ports 14. Input/Output Address Space 15. Console Input/Output in Protected Memory Mode 16. Instruction Processing 17. Instruction Components 18. Why Learn Intel x86 ISA ? 19. Design of the x86 CPU Instruction Set 20. CPU Instruction Set 21. History of IBM PC 22. Early x86 Processor Family 23. 8086 and 8088 CPU 24. 80186 CPU 25. 80286 CPU 26. 80386 CPU 27. 80386 CPU, Cont. 28. 80486 CPU 29. Pentium (Intel 80586) 30. Pentium Pro 31. Pentium II 32. Itanium processor 1. The von Neumann Computer Model Von Neumann computer systems contain three main building blocks: The following block diagram shows major relationship between CPU components: the central processing unit (CPU), memory, and input/output devices (I/O). These three components are connected together using the system bus. The most prominent items within the CPU are the registers: they can be manipulated directly by a computer program. http://www.c-jump.com/CIS77/CPU/VonNeumann/lecture.html Page 1 of 15 IPR2017-01532 FanDuel, et al. -

V850ES/SA2, V850ES/SA3 32-Bit Single-Chip Microcontrollers
To our customers, Old Company Name in Catalogs and Other Documents On April 1st, 2010, NEC Electronics Corporation merged with Renesas Technology Corporation, and Renesas Electronics Corporation took over all the business of both companies. Therefore, although the old company name remains in this document, it is a valid Renesas Electronics document. We appreciate your understanding. Renesas Electronics website: http://www.renesas.com April 1st, 2010 Renesas Electronics Corporation Issued by: Renesas Electronics Corporation (http://www.renesas.com) Send any inquiries to http://www.renesas.com/inquiry. Notice 1. All information included in this document is current as of the date this document is issued. Such information, however, is subject to change without any prior notice. Before purchasing or using any Renesas Electronics products listed herein, please confirm the latest product information with a Renesas Electronics sales office. Also, please pay regular and careful attention to additional and different information to be disclosed by Renesas Electronics such as that disclosed through our website. 2. Renesas Electronics does not assume any liability for infringement of patents, copyrights, or other intellectual property rights of third parties by or arising from the use of Renesas Electronics products or technical information described in this document. No license, express, implied or otherwise, is granted hereby under any patents, copyrights or other intellectual property rights of Renesas Electronics or others. 3. You should not alter, modify, copy, or otherwise misappropriate any Renesas Electronics product, whether in whole or in part. 4. Descriptions of circuits, software and other related information in this document are provided only to illustrate the operation of semiconductor products and application examples. -

Testing and Validation of a Prototype Gpgpu Design for Fpgas Murtaza Merchant University of Massachusetts Amherst
University of Massachusetts Amherst ScholarWorks@UMass Amherst Masters Theses 1911 - February 2014 2013 Testing and Validation of a Prototype Gpgpu Design for FPGAs Murtaza Merchant University of Massachusetts Amherst Follow this and additional works at: https://scholarworks.umass.edu/theses Part of the VLSI and Circuits, Embedded and Hardware Systems Commons Merchant, Murtaza, "Testing and Validation of a Prototype Gpgpu Design for FPGAs" (2013). Masters Theses 1911 - February 2014. 1012. Retrieved from https://scholarworks.umass.edu/theses/1012 This thesis is brought to you for free and open access by ScholarWorks@UMass Amherst. It has been accepted for inclusion in Masters Theses 1911 - February 2014 by an authorized administrator of ScholarWorks@UMass Amherst. For more information, please contact [email protected]. TESTING AND VALIDATION OF A PROTOTYPE GPGPU DESIGN FOR FPGAs A Thesis Presented by MURTAZA S. MERCHANT Submitted to the Graduate School of the University of Massachusetts Amherst in partial fulfillment of the requirements for the degree of MASTER OF SCIENCE IN ELECTRICAL AND COMPUTER ENGINEERING February 2013 Department of Electrical and Computer Engineering © Copyright by Murtaza S. Merchant 2013 All Rights Reserved TESTING AND VALIDATION OF A PROTOTYPE GPGPU DESIGN FOR FPGAs A Thesis Presented by MURTAZA S. MERCHANT Approved as to style and content by: _________________________________ Russell G. Tessier, Chair _________________________________ Wayne P. Burleson, Member _________________________________ Mario Parente, Member ______________________________ C. V. Hollot, Department Head Electrical and Computer Engineering ACKNOWLEDGEMENTS To begin with, I would like to sincerely thank my advisor, Prof. Russell Tessier for all his support, faith in my abilities and encouragement throughout my tenure as a graduate student. -

The Microarchitecture of the Pentium 4 Processor
The Microarchitecture of the Pentium 4 Processor Glenn Hinton, Desktop Platforms Group, Intel Corp. Dave Sager, Desktop Platforms Group, Intel Corp. Mike Upton, Desktop Platforms Group, Intel Corp. Darrell Boggs, Desktop Platforms Group, Intel Corp. Doug Carmean, Desktop Platforms Group, Intel Corp. Alan Kyker, Desktop Platforms Group, Intel Corp. Patrice Roussel, Desktop Platforms Group, Intel Corp. Index words: Pentium® 4 processor, NetBurst™ microarchitecture, Trace Cache, double-pumped ALU, deep pipelining provides an in-depth examination of the features and ABSTRACT functions of the Intel NetBurst microarchitecture. This paper describes the Intel® NetBurst™ ® The Pentium 4 processor is designed to deliver microarchitecture of Intel’s new flagship Pentium 4 performance across applications where end users can truly processor. This microarchitecture is the basis of a new appreciate and experience its performance. For example, family of processors from Intel starting with the Pentium it allows a much better user experience in areas such as 4 processor. The Pentium 4 processor provides a Internet audio and streaming video, image processing, substantial performance gain for many key application video content creation, speech recognition, 3D areas where the end user can truly appreciate the applications and games, multi-media, and multi-tasking difference. user environments. The Pentium 4 processor enables real- In this paper we describe the main features and functions time MPEG2 video encoding and near real-time MPEG4 of the NetBurst microarchitecture. We present the front- encoding, allowing efficient video editing and video end of the machine, including its new form of instruction conferencing. It delivers world-class performance on 3D cache called the Execution Trace Cache. -

Micro-Circuits for High Energy Physics*
MICRO-CIRCUITS FOR HIGH ENERGY PHYSICS* Paul F. Kunz Stanford Linear Accelerator Center Stanford University, Stanford, California, U.S.A. ABSTRACT Microprogramming is an inherently elegant method for implementing many digital systems. It is a mixture of hardware and software techniques with the logic subsystems controlled by "instructions" stored Figure 1: Basic TTL Gate in a memory. In the past, designing microprogrammed systems was difficult, tedious, and expensive because the available components were capable of only limited number of functions. Today, however, large blocks of microprogrammed systems have been incorporated into a A input B input C output single I.e., thus microprogramming has become a simple, practical method. false false true false true true true false true true true false 1. INTRODUCTION 1.1 BRIEF HISTORY OF MICROCIRCUITS Figure 2: Truth Table for NAND Gate. The first question which arises when one talks about microcircuits is: What is a microcircuit? The answer is simple: a complete circuit within a single integrated-circuit (I.e.) package or chip. The next question one might ask is: What circuits are available? The answer to this question is also simple: it depends. It depends on the economics of the circuit for the semiconductor manufacturer, which depends on the technology he uses, which in turn changes as a function of time. Thus to understand Figure 3: Logical NOT Circuit. what microcircuits are available today and what makes them different from those of yesterday it is interesting to look into the economics of producing microcircuits. The basic element in a logic circuit is a gate, which is a circuit with a number of inputs and one output and it performs a basic logical function such as AND, OR, or NOT. -

Arithmetic and Logical Unit Design for Area Optimization for Microcontroller Amrut Anilrao Purohit 1,2 , Mohammed Riyaz Ahmed 2 and R
et International Journal on Emerging Technologies 11 (2): 668-673(2020) ISSN No. (Print): 0975-8364 ISSN No. (Online): 2249-3255 Arithmetic and Logical Unit Design for Area Optimization for Microcontroller Amrut Anilrao Purohit 1,2 , Mohammed Riyaz Ahmed 2 and R. Venkata Siva Reddy 2 1Research Scholar, VTU Belagavi (Karnataka), India. 2School of Electronics and Communication Engineering, REVA University Bengaluru, (Karnataka), India. (Corresponding author: Amrut Anilrao Purohit) (Received 04 January 2020, Revised 02 March 2020, Accepted 03 March 2020) (Published by Research Trend, Website: www.researchtrend.net) ABSTRACT: Arithmetic and Logic Unit (ALU) can be understood with basic knowledge of digital electronics and any engineer will go through the details only once. The advantage of knowing ALU in detail is two- folded: firstly, programming of the processing device can be efficient and secondly, can design a new ALU architecture as per the various constraints of the use cases. The miniaturization of digital circuits can be achieved by either reducing the size of transistor (Moore’s law) or by optimizing the gate count of the circuit. The first has been explored extensively while the latter has been ignored which deals with the application of Boolean rules and requires sound knowledge of logic design. The ultimate outcome is to have an area optimized architecture/approach that optimizes the circuit at gate level. The design of ALU is for various processing devices varies with the device/system requirements. The area optimization places a significant role in the chip design. Here in this work, we have attempted to design an ALU which is area efficient while being loaded with additional functionality necessary for microcontrollers. -

Unit 8 : Microprocessor Architecture
Unit 8 : Microprocessor Architecture Lesson 1 : Microcomputer Structure 1.1. Learning Objectives On completion of this lesson you will be able to : ♦ draw the block diagram of a simple computer ♦ understand the function of different units of a microcomputer ♦ learn the basic operation of microcomputer bus system. 1.2. Digital Computer A digital computer is a multipurpose, programmable machine that reads A digital computer is a binary instructions from its memory, accepts binary data as input and multipurpose, programmable processes data according to those instructions, and provides results as machine. output. 1.3. Basic Computer System Organization Every computer contains five essential parts or units. They are Basic computer system organization. i. the arithmetic logic unit (ALU) ii. the control unit iii. the memory unit iv. the input unit v. the output unit. 1.3.1. The Arithmetic and Logic Unit (ALU) The arithmetic and logic unit (ALU) is that part of the computer that The arithmetic and logic actually performs arithmetic and logical operations on data. All other unit (ALU) is that part of elements of the computer system - control unit, register, memory, I/O - the computer that actually are there mainly to bring data into the ALU to process and then to take performs arithmetic and the results back out. logical operations on data. An arithmetic and logic unit and, indeed, all electronic components in the computer are based on the use of simple digital logic devices that can store binary digits and perform simple Boolean logic operations. Data are presented to the ALU in registers. These registers are temporary storage locations within the CPU that are connected by signal paths of the ALU. -

Computer Architecture Out-Of-Order Execution
Computer Architecture Out-of-order Execution By Yoav Etsion With acknowledgement to Dan Tsafrir, Avi Mendelson, Lihu Rappoport, and Adi Yoaz 1 Computer Architecture 2013– Out-of-Order Execution The need for speed: Superscalar • Remember our goal: minimize CPU Time CPU Time = duration of clock cycle × CPI × IC • So far we have learned that in order to Minimize clock cycle ⇒ add more pipe stages Minimize CPI ⇒ utilize pipeline Minimize IC ⇒ change/improve the architecture • Why not make the pipeline deeper and deeper? Beyond some point, adding more pipe stages doesn’t help, because Control/data hazards increase, and become costlier • (Recall that in a pipelined CPU, CPI=1 only w/o hazards) • So what can we do next? Reduce the CPI by utilizing ILP (instruction level parallelism) We will need to duplicate HW for this purpose… 2 Computer Architecture 2013– Out-of-Order Execution A simple superscalar CPU • Duplicates the pipeline to accommodate ILP (IPC > 1) ILP=instruction-level parallelism • Note that duplicating HW in just one pipe stage doesn’t help e.g., when having 2 ALUs, the bottleneck moves to other stages IF ID EXE MEM WB • Conclusion: Getting IPC > 1 requires to fetch/decode/exe/retire >1 instruction per clock: IF ID EXE MEM WB 3 Computer Architecture 2013– Out-of-Order Execution Example: Pentium Processor • Pentium fetches & decodes 2 instructions per cycle • Before register file read, decide on pairing Can the two instructions be executed in parallel? (yes/no) u-pipe IF ID v-pipe • Pairing decision is based… On data -

Parallel Computing
Lecture 1: Computer Organization 1 Outline • Overview of parallel computing • Overview of computer organization – Intel 8086 architecture • Implicit parallelism • von Neumann bottleneck • Cache memory – Writing cache-friendly code 2 Why parallel computing • Solving an × linear system Ax=b by using Gaussian elimination takes ≈ flops. 1 • On Core i7 975 @ 4.0 GHz,3 which is capable of about 3 60-70 Gigaflops flops time 1000 3.3×108 0.006 seconds 1000000 3.3×1017 57.9 days 3 What is parallel computing? • Serial computing • Parallel computing https://computing.llnl.gov/tutorials/parallel_comp 4 Milestones in Computer Architecture • Analytic engine (mechanical device), 1833 – Forerunner of modern digital computer, Charles Babbage (1792-1871) at University of Cambridge • Electronic Numerical Integrator and Computer (ENIAC), 1946 – Presper Eckert and John Mauchly at the University of Pennsylvania – The first, completely electronic, operational, general-purpose analytical calculator. 30 tons, 72 square meters, 200KW. – Read in 120 cards per minute, Addition took 200µs, Division took 6 ms. • IAS machine, 1952 – John von Neumann at Princeton’s Institute of Advanced Studies (IAS) – Program could be represented in digit form in the computer memory, along with data. Arithmetic could be implemented using binary numbers – Most current machines use this design • Transistors was invented at Bell Labs in 1948 by J. Bardeen, W. Brattain and W. Shockley. • PDP-1, 1960, DEC – First minicomputer (transistorized computer) • PDP-8, 1965, DEC – A single bus -

Demystifying Internet of Things Security Successful Iot Device/Edge and Platform Security Deployment — Sunil Cheruvu Anil Kumar Ned Smith David M
Demystifying Internet of Things Security Successful IoT Device/Edge and Platform Security Deployment — Sunil Cheruvu Anil Kumar Ned Smith David M. Wheeler Demystifying Internet of Things Security Successful IoT Device/Edge and Platform Security Deployment Sunil Cheruvu Anil Kumar Ned Smith David M. Wheeler Demystifying Internet of Things Security: Successful IoT Device/Edge and Platform Security Deployment Sunil Cheruvu Anil Kumar Chandler, AZ, USA Chandler, AZ, USA Ned Smith David M. Wheeler Beaverton, OR, USA Gilbert, AZ, USA ISBN-13 (pbk): 978-1-4842-2895-1 ISBN-13 (electronic): 978-1-4842-2896-8 https://doi.org/10.1007/978-1-4842-2896-8 Copyright © 2020 by The Editor(s) (if applicable) and The Author(s) This work is subject to copyright. All rights are reserved by the Publisher, whether the whole or part of the material is concerned, specifically the rights of translation, reprinting, reuse of illustrations, recitation, broadcasting, reproduction on microfilms or in any other physical way, and transmission or information storage and retrieval, electronic adaptation, computer software, or by similar or dissimilar methodology now known or hereafter developed. Open Access This book is licensed under the terms of the Creative Commons Attribution 4.0 International License (http://creativecommons.org/licenses/by/4.0/), which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons license and indicate if changes were made. The images or other third party material in this book are included in the book’s Creative Commons license, unless indicated otherwise in a credit line to the material.