Modal Matching: a Method for Describing, Comparing, and Manipulating Digital Signals by Stanley Edward Sclaroff
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Initial Configuration: • Bar on a Horizontal Plane • Equal Sized Bands • Straightened out • Just About to Be Stretched Couples in 2-D
Couples in 2-D Approximately 45° Initial configuration: • bar on a horizontal plane • equal sized bands • straightened out • just about to be stretched Couples in 2-D 45° Unloaded Configuration: Pivot the bar about its center stretching bands of equal length are unstretched the bands equal amounts as shown Gr in the middle not possible to pivot with Where would you apply a single force to Pi pivot the bar to this position? single force Bl at the end Ye at the peg Couples in 2-D F F Bar is to be pivoted about center (bands stretch equal amounts) It is not possible to balance the pair of equal and opposite forces F (exerted by the bands) with a single force ! Pi Couples in 2-D Unloaded Configuration: Pivot the bar about its center stretching bands of equal length are unstretched the bands equal amounts as shown 1 Gr What is the smallest number of 2 Pi forces which can be used to maintain this pivoted position? 3 Bl Can you produce this motion with more than one combination of Yes Gr forces? No Pi Couples in 2-D Unloaded Configuration: Pivot the bar about its center bands of equal length stretching the bands equal are nnstretched amounts as shown Must the forces be acting Yes Gr parallel to the rubber bands? No Pi Couples in 2-D Unloaded Configuration: Pivot the bar about its center stretching bands of equal length are unstretched the bands equal amounts as shown What can you do to decrease the magnitude of a pair of forces needed to produce this motion? Couples in 2-D Given the band forces F, what else must be applied to the bar to maintain it in this position? d F F ΣFy = F - F = 0: no net force is needed ΣM|c = F(d/2) +F(d/2) = Fd ≠ 0: must apply a moment (-Fd) Couples in 2-D d d F F F F d d F F F F All pairs of forces exerted by fingers produce statically equivalent effect Couples in 2-D Unloaded Configuration: Pivot the bar about its center bands of equal length stretching the bands equal are unstretched amounts as shown Load the body so it pivots using only the nutdriver. -
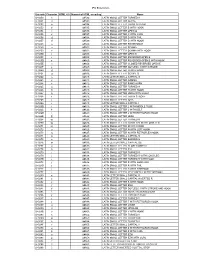
IPA Extensions
IPA Extensions Unicode Character HTML 4.0 Numerical HTML encoding Name U+0250 ɐ ɐ LATIN SMALL LETTER TURNED A U+0251 ɑ ɑ LATIN SMALL LETTER ALPHA U+0252 ɒ ɒ LATIN SMALL LETTER TURNED ALPHA U+0253 ɓ ɓ LATIN SMALL LETTER B WITH HOOK U+0254 ɔ ɔ LATIN SMALL LETTER OPEN O U+0255 ɕ ɕ LATIN SMALL LETTER C WITH CURL U+0256 ɖ ɖ LATIN SMALL LETTER D WITH TAIL U+0257 ɗ ɗ LATIN SMALL LETTER D WITH HOOK U+0258 ɘ ɘ LATIN SMALL LETTER REVERSED E U+0259 ə ə LATIN SMALL LETTER SCHWA U+025A ɚ ɚ LATIN SMALL LETTER SCHWA WITH HOOK U+025B ɛ ɛ LATIN SMALL LETTER OPEN E U+025C ɜ ɜ LATIN SMALL LETTER REVERSED OPEN E U+025D ɝ ɝ LATIN SMALL LETTER REVERSED OPEN E WITH HOOK U+025E ɞ ɞ LATIN SMALL LETTER CLOSED REVERSED OPEN E U+025F ɟ ɟ LATIN SMALL LETTER DOTLESS J WITH STROKE U+0260 ɠ ɠ LATIN SMALL LETTER G WITH HOOK U+0261 ɡ ɡ LATIN SMALL LETTER SCRIPT G U+0262 ɢ ɢ LATIN LETTER SMALL CAPITAL G U+0263 ɣ ɣ LATIN SMALL LETTER GAMMA U+0264 ɤ ɤ LATIN SMALL LETTER RAMS HORN U+0265 ɥ ɥ LATIN SMALL LETTER TURNED H U+0266 ɦ ɦ LATIN SMALL LETTER H WITH HOOK U+0267 ɧ ɧ LATIN SMALL LETTER HENG WITH HOOK U+0268 ɨ ɨ LATIN SMALL LETTER I WITH STROKE U+0269 ɩ ɩ LATIN SMALL LETTER IOTA U+026A ɪ ɪ LATIN LETTER SMALL CAPITAL I U+026B ɫ ɫ LATIN SMALL LETTER L WITH MIDDLE TILDE U+026C ɬ ɬ LATIN SMALL LETTER L WITH BELT U+026D ɭ ɭ LATIN SMALL LETTER L WITH RETROFLEX HOOK U+026E ɮ ɮ LATIN SMALL LETTER LEZH U+026F ɯ ɯ LATIN SMALL -

1 Symbols (2286)
1 Symbols (2286) USV Symbol Macro(s) Description 0009 \textHT <control> 000A \textLF <control> 000D \textCR <control> 0022 ” \textquotedbl QUOTATION MARK 0023 # \texthash NUMBER SIGN \textnumbersign 0024 $ \textdollar DOLLAR SIGN 0025 % \textpercent PERCENT SIGN 0026 & \textampersand AMPERSAND 0027 ’ \textquotesingle APOSTROPHE 0028 ( \textparenleft LEFT PARENTHESIS 0029 ) \textparenright RIGHT PARENTHESIS 002A * \textasteriskcentered ASTERISK 002B + \textMVPlus PLUS SIGN 002C , \textMVComma COMMA 002D - \textMVMinus HYPHEN-MINUS 002E . \textMVPeriod FULL STOP 002F / \textMVDivision SOLIDUS 0030 0 \textMVZero DIGIT ZERO 0031 1 \textMVOne DIGIT ONE 0032 2 \textMVTwo DIGIT TWO 0033 3 \textMVThree DIGIT THREE 0034 4 \textMVFour DIGIT FOUR 0035 5 \textMVFive DIGIT FIVE 0036 6 \textMVSix DIGIT SIX 0037 7 \textMVSeven DIGIT SEVEN 0038 8 \textMVEight DIGIT EIGHT 0039 9 \textMVNine DIGIT NINE 003C < \textless LESS-THAN SIGN 003D = \textequals EQUALS SIGN 003E > \textgreater GREATER-THAN SIGN 0040 @ \textMVAt COMMERCIAL AT 005C \ \textbackslash REVERSE SOLIDUS 005E ^ \textasciicircum CIRCUMFLEX ACCENT 005F _ \textunderscore LOW LINE 0060 ‘ \textasciigrave GRAVE ACCENT 0067 g \textg LATIN SMALL LETTER G 007B { \textbraceleft LEFT CURLY BRACKET 007C | \textbar VERTICAL LINE 007D } \textbraceright RIGHT CURLY BRACKET 007E ~ \textasciitilde TILDE 00A0 \nobreakspace NO-BREAK SPACE 00A1 ¡ \textexclamdown INVERTED EXCLAMATION MARK 00A2 ¢ \textcent CENT SIGN 00A3 £ \textsterling POUND SIGN 00A4 ¤ \textcurrency CURRENCY SIGN 00A5 ¥ \textyen YEN SIGN 00A6 -

The Brill Typeface User Guide & Complete List of Characters
The Brill Typeface User Guide & Complete List of Characters Version 2.06, October 31, 2014 Pim Rietbroek Preamble Few typefaces – if any – allow the user to access every Latin character, every IPA character, every diacritic, and to have these combine in a typographically satisfactory manner, in a range of styles (roman, italic, and more); even fewer add full support for Greek, both modern and ancient, with specialised characters that papyrologists and epigraphers need; not to mention coverage of the Slavic languages in the Cyrillic range. The Brill typeface aims to do just that, and to be a tool for all scholars in the humanities; for Brill’s authors and editors; for Brill’s staff and service providers; and finally, for anyone in need of this tool, as long as it is not used for any commercial gain.* There are several fonts in different styles, each of which has the same set of characters as all the others. The Unicode Standard is rigorously adhered to: there is no dependence on the Private Use Area (PUA), as it happens frequently in other fonts with regard to characters carrying rare diacritics or combinations of diacritics. Instead, all alphabetic characters can carry any diacritic or combination of diacritics, even stacked, with automatic correct positioning. This is made possible by the inclusion of all of Unicode’s combining characters and by the application of extensive OpenType Glyph Positioning programming. Credits The Brill fonts are an original design by John Hudson of Tiro Typeworks. Alice Savoie contributed to Brill bold and bold italic. The black-letter (‘Fraktur’) range of characters was made by Karsten Lücke. -

SUPERCONDUCTIVITY of VARIOUS BORIDES: the ROLE of STRETCHED C- PARAMETER
SUPERCONDUCTIVITY OF VARIOUS BORIDES: THE ROLE OF STRETCHED c- PARAMETER Monika Mudgel, V. P. S. Awana $ and H. Kishan National Physical Laboratory, Dr. K. S. Krishnan Marg, New Delhi-110012, India I. Felner Racah Institute of Physics, Hebrew University of Jerusalem, Jeursalem-91904, Israel Dr. G. A. Alvarez * Institute for Superconducting and Electronic Materials, University of Wollongong, Australia G. L. Bhalla Department of Physics and Astrophysics, University of Delhi, Delhi-110007, India *Presenting Author: Dr. G. A. Alvarez Institute for Superconducting and Electronic Materials University of Wollongong, Australia $Corresponding Author: Dr. V.P.S. Awana Room 109, National Physical Laboratory, Dr. K.S. Krishnan Marg, New Delhi-110012, India Fax No. 0091-11-45609310: Phone no. 0091-11-45609210 [email protected] : www.freewebs.com/vpsawana/ 1 Abstract The superconductivity of MgB 2, AlB 2, NbB 2+x and TaB 2+x is inter-compared. The stretched c-lattice parameter ( c = 3.52 Å) of MgB 2 in comparison to NbB 2.4 ( c = 3.32 Å) and AlB 2 ( c = 3.25 Å) decides empirically the population of their π and σ bands and as a result their transition temperature, Tc values respectively at 39K and 9.5K for the first two and no superconductivity for the later. Besides the electron doping from substitution of Mg +2 by Al +3 , the stretched c-parameter also affects the Boron plane constructed hole type σ-band population and the contribution from Mg or Al plane electron type π band. This turns the electron type (mainly π-band conduction) non-superconducting AlB 2 to hole type (mainly σ-band conduction) MgB 2 superconductor (39 K) as indicated by the thermoelectric power study. -

1. Analysis Procedure
Appendix A 1. Analysis Procedure A flexible electronic design platform is used to analyze the delay associated with stretchable interconnects. The delay analysis procedure flow of stretchable interconnects is shown in Fig.1. Advanced Design System Time domain Q3D simulation ANSYS Extract RLC Mechanical anslysis and parameter and Verification extract deformation model Q3D Model Time Delay Model Estimation Fig.1 The Analysis Procedure Flow of The Stretchable Interconnects Delay 1.1 Stretchable Interconnects Structure The electrical properties of stretchable interconnects would be changed with different type and degree of deformation. The initial structure of the stretchable interconnects as shown in Fig.2 were firstly defined in ANSYS software. In this paper, the stretchable interconnects consist of a copper (Cu) metal layer sandwiched between two polyimide (PI) layers. The sizes of the stretchable interconnects models selected for analysis are listed in Table.1. D d W l l e wire Fig.2 The Structure of The Stretchable Interconnects Table 1 Initial Sizes of Stretchable Interconnects (unit: μm) Interconnects Thickness Effective Length le Outer Radius D Inner Radius d Number Cu Pi 1 400 50 30 5 2 2 450 50 40 5 2 3 475 50 45 5 2 4 360 50 40 3 1 The stretching structure shown in Fig.3 (a) is formed by stretching the ends of the stretchable interconnects. The bending structure shown in Fig.3 (b) is formed by applying force perpendicular to the plane shown in Fig.2 on the ends of the stretchable interconnects, while the stretchable interconnects midpoint position and the structure width W are fixed. -

MSR-4: Annotated Repertoire Tables, Non-CJK
Maximal Starting Repertoire - MSR-4 Annotated Repertoire Tables, Non-CJK Integration Panel Date: 2019-01-25 How to read this file: This file shows all non-CJK characters that are included in the MSR-4 with a yellow background. The set of these code points matches the repertoire specified in the XML format of the MSR. Where present, annotations on individual code points indicate some or all of the languages a code point is used for. This file lists only those Unicode blocks containing non-CJK code points included in the MSR. Code points listed in this document, which are PVALID in IDNA2008 but excluded from the MSR for various reasons are shown with pinkish annotations indicating the primary rationale for excluding the code points, together with other information about usage background, where present. Code points shown with a white background are not PVALID in IDNA2008. Repertoire corresponding to the CJK Unified Ideographs: Main (4E00-9FFF), Extension-A (3400-4DBF), Extension B (20000- 2A6DF), and Hangul Syllables (AC00-D7A3) are included in separate files. For links to these files see "Maximal Starting Repertoire - MSR-4: Overview and Rationale". How the repertoire was chosen: This file only provides a brief categorization of code points that are PVALID in IDNA2008 but excluded from the MSR. For a complete discussion of the principles and guidelines followed by the Integration Panel in creating the MSR, as well as links to the other files, please see “Maximal Starting Repertoire - MSR-4: Overview and Rationale”. Brief description of exclusion -

Latin Extended-B Range: 0180–024F
Latin Extended-B Range: 0180–024F This file contains an excerpt from the character code tables and list of character names for The Unicode Standard, Version 14.0 This file may be changed at any time without notice to reflect errata or other updates to the Unicode Standard. See https://www.unicode.org/errata/ for an up-to-date list of errata. See https://www.unicode.org/charts/ for access to a complete list of the latest character code charts. See https://www.unicode.org/charts/PDF/Unicode-14.0/ for charts showing only the characters added in Unicode 14.0. See https://www.unicode.org/Public/14.0.0/charts/ for a complete archived file of character code charts for Unicode 14.0. Disclaimer These charts are provided as the online reference to the character contents of the Unicode Standard, Version 14.0 but do not provide all the information needed to fully support individual scripts using the Unicode Standard. For a complete understanding of the use of the characters contained in this file, please consult the appropriate sections of The Unicode Standard, Version 14.0, online at https://www.unicode.org/versions/Unicode14.0.0/, as well as Unicode Standard Annexes #9, #11, #14, #15, #24, #29, #31, #34, #38, #41, #42, #44, #45, and #50, the other Unicode Technical Reports and Standards, and the Unicode Character Database, which are available online. See https://www.unicode.org/ucd/ and https://www.unicode.org/reports/ A thorough understanding of the information contained in these additional sources is required for a successful implementation. -

Iso/Iec Jtc1/Sc2/Wg2 N5148r L2/20-266R
ISO/IEC JTC1/SC2/WG2 N5148R L2/20-266R 2020-11-09 Universal Multiple-Octet Coded Character Set International Organization for Standardization Organisation Internationale de Normalisation Международная организация по стандартизации Doc Type: Working Group Document Title: Consolidated code chart of proposed phonetic characters Source: Michael Everson and Kirk Miller Status: Individual Contribution Action: For consideration by JTC1/SC2/WG2 and UTC Date: 2020-11-09 The charts attached present the recommended code positions for a number of documents related to the addition of IPA and other phonetic characters to the repertoire. 1 10780 Latin Extended-F 107BF 1078 1079 107A 107B 0 10780 10790 107A0 107B0 1 10781 10791 107A1 2 10782 10792 107A2 107B2 3 10783 10793 107A3 107B3 4 10784 10794 107A4 107B4 5 10785 10795 107A5 107B5 6 10796 107A6 107B6 7 10787 10797 107A7 107B7 8 10788 10798 107A8 107B8 9 10789 10799 107A9 107B9 A 1078A 1079A 107AA B 1078B 1079B 107AB C 1078C 1079C 107AC D 1078D 1079D 107AD E 1078E 1079E 107AE F 1078F 1079F 107AF Printed using UniBook™ Printed: 09-Nov-2020 2 (http://www.unicode.org/unibook/) 10780 Latin Extended-F 107B6 1079C MODIFIER LETTER SMALL CAPITAL L WITH Voice Quality Symbol (VoQS) BELT 10780 MODIFIER LETTER SMALL CAPITAL AA ≈ <super> 1DF04 → A732 Ꜳ latin capital letter aa 1079D MODIFIER LETTER SMALL L WITH RETROFLEX HOOK AND BELT Modifier letters for the IPA ≈ <super> A78E ꞎ 10781 MODIFIER LETTER SUPERSCRIPT TRIANGULAR MODIFIER LETTER SMALL LEZH -

Superconductivity of Nb1−Xmgxb2: Impact of Stretched C-Parameter
CORE Metadata, citation and similar papers at core.ac.uk Provided by IR@NPL J Supercond Nov Magn (2008) 21: 457–460 DOI 10.1007/s10948-008-0384-2 ORIGINAL PAPER Superconductivity of Nb1−xMgxB2: Impact of Stretched c-Parameter Monika Mudgel · V.P.S. Awana · G.L. Bhalla · H. Kishan Received: 30 May 2008 / Accepted: 22 October 2008 / Published online: 6 November 2008 © Springer Science+Business Media, LLC 2008 Abstract We have performed a systematic study on the oc- PACS 61.10.Nz · 74.62.-c · 74.62.Bf currence of superconductivity in Nb1−xMgxB2 (0.0 ≤ x ≤ 0.40). X-ray diffraction and magnetization measurements are carried out to determine the changes in lattice parame- 1 Introduction ters, superconducting transition temperature (Tc) and crit- ical field (Hc1). The substitution of Mg at Nb site results The discovery of superconductivity in MgB2 [1] has put an in considerable stretching of c-parameter with only a slight impetus in search for analogous behavior in similar systems. change in a parameter. Rietveld analysis on X-ray diffrac- Although the most similar candidates for such investigations tion patterns gives a = 3.11 Å and c = 3.26 Å for pure seem to be the AlB2 type alkali, alkaline or group III el- = NbB2 while a = 3.10 Å and c = 3.32 Å for Nb0.60Mg0.40B2. ement diborides, i.e., AB2 (A Li, Na, Be, Al), none of This increased c-parameter introduces superconductivity them is reported to have superconductivity [2–4]. The group in niobium diboride. Magnetization measurements though IVa, Va & VIIa elements (Nb, Ta, Mo, Zr and Hf) also form indicate the absence of superconductivity in NbB2,the diborides isostructural to MgB2. -

Unicode Request for Additional Phonetic Click Letters Characters Suggested Annotations
Unicode request for additional phonetic click letters Kirk Miller, [email protected] Bonny Sands, [email protected] 2020 July 10 This request is for phonetic symbols used for click consonants, primarily for Khoisan and Bantu languages. For the two symbols ⟨⟩ and ⟨ ⟩, which fit the pre- and post-Kiel IPA and see relatively frequent use, code points in the Basic Plane are requested. Per the recommendation of the Script Ad Hoc Committee, two other symbols, ⟨‼⟩ and ⟨⦀⟩, may be best handled by adding annotations to existing punctuation and mathematical characters. The remainder of the symbols being proposed are less common and may be best placed in the supplemental plane. Three precomposed characters, old IPA ʇ ʖ ʗ with a swash (⟨⟩, ⟨⟩, ⟨⟩), are covered in a separate proposal. Characters U+A7F0 LATIN SMALL LETTER ESH WITH DOUBLE BAR. Figures 1–9. U+A7F1 LATIN LETTER RETROFLEX CLICK WITH RETROFLEX HOOK. Figures 16–19. U+10780 LATIN SMALL LETTER TURNED T WITH CURL. Figures 8–13. U+10781 LATIN LETTER INVERTED GLOTTAL STOP WITH CURL. Figures 8, 9, 11, 12, 15. U+10782 LATIN SMALL LETTER ESH WITH DOUBLE BAR AND CURL. Figures 8-10. U+10783 LATIN LETTER STRETCHED C WITH CURL. Figures 8, 9, 12, 14. U+10784 LATIN LETTER SMALL CAPITAL TURNED K. Figure 20. Suggested annotations U+A7F0 LATIN SMALL LETTER ESH WITH DOUBLE BAR ⟨⟩ resembles U+2A0E INTEGRAL WITH DOUBLE STROKE ⟨⨎⟩, though the glyph design is different. (The Script Ad Hoc Committee recommends not unifying them.) U+203C DOUBLE EXCLAMATION MARK ⟨‼⟩ may be used as a phonetic symbol, equivalent to a doubled U+1C3 LATIN LETTER RETROFLEX CLICK ⟨ǃ⟩. -

Unicode Request for Additional Phonetic Click Letters Characters
Unicode request for additional phonetic click letters Kirk Miller, [email protected] Bonny Sands, [email protected] 2020 April 14 This request is for phonetic symbols used for click consonants, primarily for Khoisan and Bantu languages. For the two symbols ⟨⟩ and ⟨ ⟩, which fit the pre- and post-Kiel IPA and see relatively frequent use, code points in the Basic Plane are requested. Per the recommendation of the Script Ad Hoc Committee, two other symbols, ⟨‼⟩ and ⟨⦀⟩, may be best handled by adding annotations to existing punctuation and mathematical characters. The remainder of the symbols being proposed are best placed in a supplemental plane. Three precomposed characters, old IPA ʇ ʖ ʗ with a swash ( ), are covered in a separate proposal. Characters U+A7F0 LATIN SMALL LETTER ESH WITH DOUBLE BAR. Figures 1–9. U+10780 LATIN SMALL LETTER ESH WITH DOUBLE BAR AND CURL. Figures 8-10. U+10781 LATIN SMALL LETTER TURNED T WITH CURL. Figures 8–13. U+10782 LATIN LETTER STRETCHED C WITH CURL. Figures 8, 9, 12, 14. U+10783 LATIN LETTER INVERTED GLOTTAL STOP WITH CURL. Figures 8, 9, 11, 12, 15. U+A7F1 LATIN LETTER RETROFLEX CLICK WITH RETROFLEX HOOK. Figures 16–19. U+ sup plane so U can join it. LATIN LETTER SMALL CAPITAL TURNED K. Figure 20. Suggested annotations U+A7F0 LATIN SMALL LETTER ESH WITH DOUBLE BAR ⟨⟩ resembles U+2A0E INTEGRAL WITH DOUBLE STROKE ⟨⨎⟩, though the glyph design is different. (The Ad Hoc Committee recommended not unifying them.) U+203C DOUBLE EXCLAMATION MARK ⟨‼⟩ may be used as a phonetic symbol, equivalent to a doubled U+1C3 LATIN LETTER RETROFLEX CLICK ⟨ǃ⟩.