Unsupervised Multilingual Learning Benjamin Snyder
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Copyright © 2014 Richard Charles Mcdonald All Rights Reserved. The
Copyright © 2014 Richard Charles McDonald All rights reserved. The Southern Baptist Theological Seminary has permission to reproduce and disseminate this document in any form by any means for purposes chosen by the Seminary, including, without, limitation, preservation or instruction. GRAMMATICAL ANALYSIS OF VARIOUS BIBLICAL HEBREW TEXTS ACCORDING TO A TRADITIONAL SEMITIC GRAMMAR __________________ A Dissertation Presented to the Faculty of The Southern Baptist Theological Seminary __________________ In Partial Fulfillment of the Requirements for the Degree Doctor of Philosophy __________________ by Richard Charles McDonald December 2014 APPROVAL SHEET GRAMMATICAL ANALYSIS OF VARIOUS BIBLICAL HEBREW TEXTS ACCORDING TO A TRADITIONAL SEMITIC GRAMMAR Richard Charles McDonald Read and Approved by: __________________________________________ Russell T. Fuller (Chair) __________________________________________ Terry J. Betts __________________________________________ John B. Polhill Date______________________________ I dedicate this dissertation to my wife, Nancy. Without her support, encouragement, and love I could not have completed this arduous task. I also dedicate this dissertation to my parents, Charles and Shelly McDonald, who instilled in me the love of the Lord and the love of His Word. TABLE OF CONTENTS Page LIST OF ABBREVIATIONS.............................................................................................vi LIST OF TABLES.............................................................................................................vii -

Fine Arts BA (Fine Arts)
THE UNIVERSITY OF THE FREE STATE RULE BOOK 2013 FACULTY OF THE HUMANITIES ARTS AND SOCIAL SCIENCES UNDERGRADUATE PROGRAMMES Dean: Prof. L.J.S. Botes 106 Flippie Groenewoud Building Telephone: 051 4012240 Fax: 051 4445803 OFFICIAL ADDRESS FOR ENQUIRIES: Correspondence with regard to academic matters should be addressed to: The Faculty Manager University of the Free State Faculty of the Humanities P.O. Box 339 BLOEMFONTEIN 9300 Telephone: 051 4012369 Fax: 051 4445803 E-mail: [email protected] hhhhhhhh hhhhhhhh hhhhhhhh 1 Faculty of the Humanities Undergraduate Rule book - 2013 RULE BOOK FACULTIES Humanities Law Agriculture and Natural Sciences Economic and Management Sciences Education Health Sciences Theology N.B.: Copies of the individual sections of the Rule book (as above), including the General Calendar, are available on request from the Registrar: Academic Student Services. 2 Faculty of the Humanities Undergraduate Rule book - 2013 CONTENTS Academic Staff ..................................................................................................... 5 Contact Details .................................................................................................... 8 General Information ............................................................................................. 9 General University Regulations ........................................................................... 9 Faculty Regulations ............................................................................................. 9 General requirements -

(Cf. 1.Common Semitic) a Bibliography of Ugaritic
6A. STANDARD HEBREW 6A.1. BIBLIOGRAPHY (cf. 1. Common Semitic ) A Bibliography of Ugaritic Grammar and Biblical Hebrew in the Twentieth Century , by M. Smith [http://oi.uchicago.edu/OI/DEPT/RA/bibs/BH-Ugaritic.html: pdf, doc, rtf]. “A classified discourse analysis bibliography”, by K.E. Lowery, in DABL , pp. 213-253. An Index of English Periodical Literature on the Old Testament and Ancient Near Eastern Studies , 2 vols. (American Theological Library Association. Bibliography Series 21), by W.G. Hupper, Philadelphia 1987-1999. ´ “Bibliografia historii i kultury Zydów w Polsce za rok 1994”, by St. G ąsiorowski, Studia Judaica Crocoviensia: Series Bibliographica 2 (10), Krakow 2002 [Bibliography on the history and culture od the Jews in Poland for the year 1994]. “Bibliographie, Altes Testament/Qumran”, AfO 14, 1941-1944 // 29-30, 1983-1984 (Palestina und Syrien ; Altes Testament un nachbiblische Schriftum ; Die handschriftenfunde am Toten Meer/Qumran). Bibliographie biblique/Biblical Bibliography/Biblische Bibliographie/Bibliografla biblica/Bibliografía bíblica. III : 1930-1983 , by P.-E. Langevin, Québec 1985 [‘Philologie’, 335-464]. “Bibliographische Dokurnentation: lexikalisches und grammatisches Material”, bearb. von T. Ijoherty et al. , ZAH l, 1988, 122-137, 210-234. “Bibliographische Dokumentation: lexikalisches und grammatisches Material”, bearb. von W. Breder et al. , ZAH 2, 1989, 93-119; 2, 1989, 213-243, 3, 1990, 98-125; 3, 1990, 221-231. “Bibliographische Dokumentation: lexikalisches und grammatisches Material”, bearb. von B. Brauer et al. ., ZAH 4, 1991, 95-114,194-209; 5, 1992, 91-112, 226-236; 6, 1993, 128-148; 6, 1993, 243-256 ; 6, 1993, 128-148; 6, 1993, 243-256 ; 7, 1994, 88-100; 7, 1994, 245-257; “Bibliographische Dokumientation: lexikalisches und grammatisches Material”, in Verbindung mit B. -

Arts Undergraduate
Arts – Undergraduate University College Dublin National University of Ireland, Dublin Arts, Philosophy, Celtic Studies (Undergraduate Day Courses) Session 2002/2003 1 University College Dublin Information For Exchange Students Re. Units And Credits Throughout this booklet, undergraduate Arts courses, except in first year, are given or deemed to have a unit value. A one-unit course consists of one lecture/tutorial per week for a twelve-week period or represents an equivalent proportion of the year’s work. Courses of two or three units are pro rata. Normally a student would take courses to the value of twenty-four units in a full year. In addition, University College Dublin has adopted a system of credits, awarded for work successfully completed. In line with the European Course Credit Transfer System (ECTS), a full year’s work successfully completed will be allotted 60 credits. Exchange students and others involved in ECTS transfer of courses should note that to determine the number of credits which will be allotted to a successfully completed day Arts course, the Arts Faculty unit value should be multiplied by 2.5. Thus: A one-unit course, successfully completed, will be awarded 2.5 credits; a two-unit course, successfully completed, will be awarded 5 credits; a three-unit course, successfully completed, will be awarded 7.5 credits; and twenty-four units, successfully completed, will be awarded 60 credits. N.B. Enquiries on the award of credits should be addressed to the Registrar, University College Dublin, Belfield, Dublin 4. 2 Arts – Undergraduate Contents Information For Exchange Students Re. Units And Credits............................. -

2018-2019 | Academic Catalog
2018-2019 | Academic Catalog We Train Men Because Lives Depend On It Dear Minister of the Gospel, You will certainly agree with me that there is nothing more thrilling and, at the same time, humbling than to be called by the God of the universe to be one of His special representatives to His church and to a needy and lost generation. If our wonderful Lord has laid His hand upon you for such an exciting ministry, it is critical that you receive the very best training that is available. In fact, choosing a seminary is one of the most crucial ministry decisions you will ever make. This is true because your life, and later the lives of those to whom you minister, will reflect the character and quality of your study and experience in seminary. At The Master’s Seminary we offer theological education that is centered in the inerrant Word of God, sustained by scholarly study and research, nurtured in discipling relationships and ministry experiences, characterized by personal growth, and directed toward effectiveness in evangelism and edification. Here you will find seminary training that majors on personal holiness, exegetical study, and biblical theology and does so right in the context of a vital local church. If God is calling you to a special ministry, if you aspire to effectiveness in a ministry of the Word, if you are willing to submit yourself to the discipline of diligent study and to discipleship by godly men. then we invite you to prayerfully consider the exciting potential for study with us at The Master’s Seminary. -

Forming Servants in Who Teach the Faithful, Reach the Lost, and Care for All
CONCORDIA THEOLOGICAL SEMINARY 2014-2015Fort Academic Wayne, CatalogIndiana Forming servants in Jesus Christ who teach the faithful, reach the lost, and care for all. Notes for Christ in the Classroom and Community: The citation for the quote on pages 13-14 is from Robert D. Preus, The Theology of Post-Reformation Lutheranism, vol. 1 (St. Louis: Concordia, 1970), 217. Excerpts from Arthur A. Just Jr., “The Incarnational Life,” and Pam Knepper, “Kramer Chapel: The Jewel of the Seminary,” (For the Life of the World, June 1998) were used in this piece. Concordia Theological Seminary, Fort Wayne Academic Catalog 2014-2015 CONTENTS Christ in the Classroom and Community...................5 From the President ..................................15 Academic Calendar .................................16 History ..........................................19 Mission Statement/Introduction ........................ 20 Buildings and Facilities .............................. 24 Faculty/Boards.....................................26 Academic Programs .................................37 Academic Policies and Information .....................90 Seminary Community Life ........................... 104 Financial Information............................... 109 Course Descriptions ................................ 118 Campus Map ..................................... 184 Index ........................................... 186 This catalog is a statement of the policies, personnel and financial arrangements of Concordia Theological Seminary as projected by the responsible -
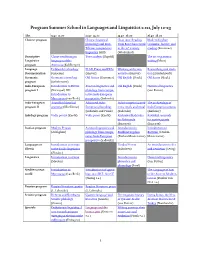
Program Summer School in Languages and Linguistics 2021, July 12-23
Program Summer School in Languages and Linguistics 2021, July 12-23 Slot 9.30–11.00 11.30–13.00 14.30–16.00 16.30–18.00 Chinese program Chinese historical Chao now: Reading Modern Uyghur: phonology and Sino- Yuen Ren Chao's work Grammar, history, and Tibetan comparative in the 21st century reading (Kontovas) linguistics (Hill) (Wiedenhof) Descriptive Clause combining in Tone analysis (Rapold) The art of grammar Linguistics languages of the writing (Mous) program Americas (Kohlberger) Language Fieldwork technology ELAN, Praat, and FLEx Working with com- Researching oral tradi- Documentation (Griscom) (Harvey) munities (Harvey) tion (Zuyderhoudt) Germanic Germanic etymology Old Frisian (Bremmer) Old English (Porck) Old Saxon (Quak) program (Schuhmann) Indo-European Introduction to Hittite Avestan linguistics and Old English (Porck) Historical linguistics program I (Vertegaal) OR: philology from compa- (van Putten) Introduction to rative Indo-European Mycenaean (van Beek) perspective (Sadovski) Indo-European Anatolian historical Advanced Indo- Indo-European sacred The archaeology of program II grammar (Kloekhorst) European phonology texts, myth, and ritual Indo-European origins (Lubotsky and Pronk) (Sadovski) (Anthony) Indology program Vedic poetry (Knobl) Vedic prose (Knobl) Kādambarīkathāsāra Kaviśikṣā, manuals by Abhinanda for aspiring poets (Isaacson) (Isaacson) Iranian program Modern Persian Avestan linguistics and Introduction to Introduction to (Zolfaghari) philology from compa- Buddhist Sogdian Bactrian (Durkin- rative Indo-European -

<Product> <Article-Title>Handbook of Ugaritic Studies</Article-Title
THE JEWISHQUARTERLY REVIEW, XCI, Nos. 1-2 (July-October, 2000) 191-196 Review Essay WILFREDG. E. WATSONAND NICOLASWYATT, eds. Handbook of Ugaritic Studies. Handbuchder Orientalistik,Abteilung 1, Band 39. Leiden: Brill, 1999. Pp. xiii + 892. The size of this volume attests to the fact that Ugaritic studies is a thriv- ing field unto itself. For much of the 20th century, Ugaritic studies served largely as the handmaidto biblical studies-and indeed it still has much to offer in that regard-but in recent decades, the study of Ras Shamra (the modern name of ancient Ugarit) and its treasures has developed into an independent field, worthy of the volume under review. The editors inform us in the Preface that Johannes de Moor conceived the project and served as its original editor, though later he ceded the work to W. G. E. Watson and N. Wyatt. We are grateful to all three scholars for the production of this excellent and most useful work, presenting in very convenient fashion a complete survey of Ugaritic studies. Watson deserves additional credit for having translated a number of the contributions from German, Italian, and Spanish. Readers of reviews do not always enjoy a listing of the chapters in a reference work, but a list will give an idea of the scope and breadth of the volume. The essays are as follows: Watson and Wyatt, "General Introduc- tion"; A. Curtis, "Ras Shamra, Minet el-Beida and Ras Ibn Hani: The Ma- terial Sources"; W. van Soldt, "The Syllabic Akkadian Texts"; W. Pitard, "The Alphabetic Ugaritic Tablets";M. -

Report of the Oxford Centre for Hebrew and Jewish Studies 2018
Report of the Oxford Centre for Hebrew and Jewish Studies 2018–2019 Report of the Oxford Centre for Hebrew and Jewish Studies Report of the Oxford Centre for Hebrew and Jewish Studies 2018–2019 oxford centre for hebrew and jewish studies Contents oxford centre for hebrew and jewish studies The Clarendon Institute Walton Street President’s Message 8 Oxford Highlights of the 2018–2019 Academic Year 10 ox1 2hg Tel: 01865 610422 People Email: [email protected] Academic Staff 22 Website: www.ochjs.ac.uk Board of Governors 25 The Oxford Centre for Hebrew and Jewish Studies is a company, limited by Academic Activities of the Centre for Hebrew and Jewish Studies guarantee, incorporated in England, Registered No. 1109384 (Registered Charity No. 309720). The Oxford Centre for Hebrew and Jewish Studies is a tax-deductible Oxford Seminar in Advanced Jewish Studies: The Mishnah organization within the United States under Section 501(c)(3) of the Internal Revenue between Christians and Jews in Early Modern Europe Code (Employer Identification number 13–2943469). The Mishnah between Christians and Jews in Early Modern Europe Dr Piet van Boxel and Professor Joanna Weinberg 28 William Wootton’s Version of Mishnah Shabbat and Eruvin (1718) and the Mishneh Torah in England between the Late-seventeenth and the Early-eighteenth Centuries Marcello Cattaneo 29 Imagining the Mishnah Visually: From Wagenseil to Wotton Professor Richard Cohen 30 Rabbi Jacob Abendana, the Author of a Lost Spanish Translation of the Mishnah Professor Yosef Kaplan 32 Guilielmus -

Philip Y. Yoo Curriculum Vitae, January 2020
Philip Y. Yoo curriculum vitae, January 2020 Lecturer Thomas Jefferson Center for the Study of Core Texts and Ideas College of Liberal Arts The University of Texas at Austin Mailing Address: Office: 158 W 21st ST STOP A1800 Waggener Hall 401D Austin, TX 78712-1719 (512) 471-6649 email: [email protected] utexas.academia.edu/PhilipYoo Citizenship: Canadian Permanent Residency: USA (renewable 01/2028) EDUCATION University of Oxford, Oxford, UK D.Phil., 2014, Theology and Religion Dissertation: “Ezra and the Second Wilderness: The Literary Development of Ezra 7–10 and Nehemiah 8–10.” Supervised by Hugh Williamson. Examined by John Barton (internal) and Joachim Schaper (external). Pass, no corrections. Yale University, New Haven, Conn. S.T.M., 2009, Divinity School University of Toronto, Toronto, Ontario, Canada M.Div., 2007, Knox College University of Toronto, Toronto, Ontario, Canada B.Comm., 2001, University College APPOINTMENTS The University of Texas at Austin, Thomas Jefferson Center for the Study of Core Texts and Ideas Lecturer, September 2019–present Postdoctoral Fellow in Religious Thought, September 2016–August 2019 Yoo C.V. i.2020 page 1 of 7 University of Toronto, Department of Near and Middle Eastern Civilizations and Department of Historical Studies Sessional Lecturer, September 2015–May 2016 PUBLICATIONS Monograph 1. Ezra and the Second Wilderness. Oxford Theology and Religion Monographs. Oxford: Oxford University Press, 2017. Reviews: Roy E. Garton, Review of Biblical Literature, 06/2018; Lena-Sofia Tiemeyer, Journal for the Study of the Old Testament 42,5 (2018): 168–169; Juha Pakkala, Journal of Hebrew Scriptures, 12/2018; Katherine Southwood, Journal of Theological Studies 70,1 (2019): 348–350. -

Academic Catalog Concordia Theological Seminary Exists to Form Servants in Jesus Christ Who Teach the Faithful, Reach the Lost and Care for All
ctsfw.edu 2017–2018 Academic Catalog Concordia Theological Seminary exists to form servants in Jesus Christ who teach the faithful, reach the lost and care for all. Notes for Christ in the Classroom and Community: e citation for the quote on pages 13-14 is from Robert D. Preus,e eology of Post-Reformation Lutheranism, vol. 1(St. Louis: Concordia, 1970), 217. Excerpts from Arthur A. Just Jr., “e Incarnational Life,” and Pam Knepper, “Kramer Chapel: e Jewel of the Seminary,”(For the Life of the World, June 1998) were used in this piece. contents Communicating with the Seminary . 3 Christ in the Classroom and Community. 5 From the President . 10 History. 13 Mission Statement. 14 Faculty/Boards/Staff . 16 Academic Calendar. 28 Academic Programs. 30 Academic Policies and Information . 85 Seminary Community Life . 97 Financial Information . 101 Course Descriptions. 111 Buildings and Facilities . 176 Campus Map . 178 Index. 180 is catalog is a statement of the policies, personnel and financial arrangements of Concordia eological Seminary (CTSFW) , Fort Wayne, Indiana, as projected by the responsible authorities of the Seminary. e Seminary reserves the right to make alterations without prior notice, in accordance with the school’s institutional needs and academic purposes. Academic catalog 2017–2018 n 3 coMMUnIcAtInG WItH tHe seMInARY Concordia eological Seminary 6600 North Clinton Street Fort Wayne, Indiana 46825-4996 www.ctsfw.edu telephone numbers: Switchboard. 260.452.2100 Fax . 260.452.2121 Admission . 800.481.2155 email: Admission. [email protected] M.Div., Alternate Route Deaconess Certification, M.A. in Deaconess Studies Advancement . [email protected] Alumni Affairs Annuities, Gis, Trusts Business Office . -

Josef Tropper. Ugaritische Grammatik. 1056 Pp. Münster, Ugarit-Verlag, 2000
Josef Tropper. Ugaritische Grammatik. 1056 pp. Münster, Ugarit-Verlag, 2000. (Alter Orient und Altes Testament 273). The disadvantage of a dead language attested by a small corpus of texts is that it leaves many lacunae in our knowledge of text-dependent aspects of the culture that are revealed by that language; the advantage for the grammarian is that it permits an exhaustive inclusion of the data in a grammatical description. This T. has done in the volume under review, which explains why one of the more poorly attested of the ancient Near-Eastern languages now boasts one of the thickest grammars. The disadvantageous side for the grammarian wishing to exploit these data exhaustively is that, for many grammatical categories, they are very few, all too often a single datum or none at all. The danger is always lurking, therefore, that any given datum is for one reason or another atypical or misunderstood and that a rule be proposed that in fact has no basis. In a relatively brief time, the author has established himself as one of the principal authorities on the ancient Semitic languages, with forty-nine titles cited under his name in the bibliography, dated from 1989 to 2000, including three important monographs. Though he is familiar with the major Semitic languages, indeed has published on several of them, he has concentrated on the Northwest-Semitic languages and particularly on Ugaritic. His grammatical work has always been of the highest order and all who will in the future have reason to investigate any aspect of Ugaritic grammar will do well to start here.