Mosaic Origin of the Eukaryotic Kinetochore SEE COMMENTARY Eelco C
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Gene Knockdown of CENPA Reduces Sphere Forming Ability and Stemness of Glioblastoma Initiating Cells
Neuroepigenetics 7 (2016) 6–18 Contents lists available at ScienceDirect Neuroepigenetics journal homepage: www.elsevier.com/locate/nepig Gene knockdown of CENPA reduces sphere forming ability and stemness of glioblastoma initiating cells Jinan Behnan a,1, Zanina Grieg b,c,1, Mrinal Joel b,c, Ingunn Ramsness c, Biljana Stangeland a,b,⁎ a Department of Molecular Medicine, Institute of Basic Medical Sciences, The Medical Faculty, University of Oslo, Oslo, Norway b Norwegian Center for Stem Cell Research, Department of Immunology and Transfusion Medicine, Oslo University Hospital, Oslo, Norway c Vilhelm Magnus Laboratory for Neurosurgical Research, Institute for Surgical Research and Department of Neurosurgery, Oslo University Hospital, Oslo, Norway article info abstract Article history: CENPA is a centromere-associated variant of histone H3 implicated in numerous malignancies. However, the Received 20 May 2016 role of this protein in glioblastoma (GBM) has not been demonstrated. GBM is one of the most aggressive Received in revised form 23 July 2016 human cancers. GBM initiating cells (GICs), contained within these tumors are deemed to convey Accepted 2 August 2016 characteristics such as invasiveness and resistance to therapy. Therefore, there is a strong rationale for targeting these cells. We investigated the expression of CENPA and other centromeric proteins (CENPs) in Keywords: fi CENPA GICs, GBM and variety of other cell types and tissues. Bioinformatics analysis identi ed the gene signature: fi Centromeric proteins high_CENP(AEFNM)/low_CENP(BCTQ) whose expression correlated with signi cantly worse GBM patient Glioblastoma survival. GBM Knockdown of CENPA reduced sphere forming ability, proliferation and cell viability of GICs. We also Brain tumor detected significant reduction in the expression of stemness marker SOX2 and the proliferation marker Glioblastoma initiating cells and therapeutic Ki67. -

PDF Output of CLIC (Clustering by Inferred Co-Expression)
PDF Output of CLIC (clustering by inferred co-expression) Dataset: Num of genes in input gene set: 13 Total number of genes: 16493 CLIC PDF output has three sections: 1) Overview of Co-Expression Modules (CEMs) Heatmap shows pairwise correlations between all genes in the input query gene set. Red lines shows the partition of input genes into CEMs, ordered by CEM strength. Each row shows one gene, and the brightness of squares indicates its correlations with other genes. Gene symbols are shown at left side and on the top of the heatmap. 2) Details of each CEM and its expansion CEM+ Top panel shows the posterior selection probability (dataset weights) for top GEO series datasets. Bottom panel shows the CEM genes (blue rows) as well as expanded CEM+ genes (green rows). Each column is one GEO series dataset, sorted by their posterior probability of being selected. The brightness of squares indicates the gene's correlations with CEM genes in the corresponding dataset. CEM+ includes genes that co-express with CEM genes in high-weight datasets, measured by LLR score. 3) Details of each GEO series dataset and its expression profile: Top panel shows the detailed information (e.g. title, summary) for the GEO series dataset. Bottom panel shows the background distribution and the expression profile for CEM genes in this dataset. Overview of Co-Expression Modules (CEMs) with Dataset Weighting Scale of average Pearson correlations Num of Genes in Query Geneset: 13. Num of CEMs: 1. 0.0 0.2 0.4 0.6 0.8 1.0 Cenpk Cenph Cenpp Cenpu Cenpn Cenpq Cenpl Apitd1 -
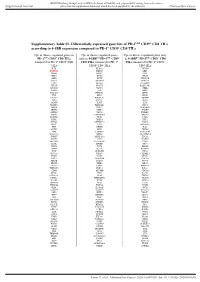
Supplementary Table S5. Differentially Expressed Gene Lists of PD-1High CD39+ CD8 Tils According to 4-1BB Expression Compared to PD-1+ CD39- CD8 Tils
BMJ Publishing Group Limited (BMJ) disclaims all liability and responsibility arising from any reliance Supplemental material placed on this supplemental material which has been supplied by the author(s) J Immunother Cancer Supplementary Table S5. Differentially expressed gene lists of PD-1high CD39+ CD8 TILs according to 4-1BB expression compared to PD-1+ CD39- CD8 TILs Up- or down- regulated genes in Up- or down- regulated genes Up- or down- regulated genes only PD-1high CD39+ CD8 TILs only in 4-1BBneg PD-1high CD39+ in 4-1BBpos PD-1high CD39+ CD8 compared to PD-1+ CD39- CD8 CD8 TILs compared to PD-1+ TILs compared to PD-1+ CD39- TILs CD39- CD8 TILs CD8 TILs IL7R KLRG1 TNFSF4 ENTPD1 DHRS3 LEF1 ITGA5 MKI67 PZP KLF3 RYR2 SIK1B ANK3 LYST PPP1R3B ETV1 ADAM28 H2AC13 CCR7 GFOD1 RASGRP2 ITGAX MAST4 RAD51AP1 MYO1E CLCF1 NEBL S1PR5 VCL MPP7 MS4A6A PHLDB1 GFPT2 TNF RPL3 SPRY4 VCAM1 B4GALT5 TIPARP TNS3 PDCD1 POLQ AKAP5 IL6ST LY9 PLXND1 PLEKHA1 NEU1 DGKH SPRY2 PLEKHG3 IKZF4 MTX3 PARK7 ATP8B4 SYT11 PTGER4 SORL1 RAB11FIP5 BRCA1 MAP4K3 NCR1 CCR4 S1PR1 PDE8A IFIT2 EPHA4 ARHGEF12 PAICS PELI2 LAT2 GPRASP1 TTN RPLP0 IL4I1 AUTS2 RPS3 CDCA3 NHS LONRF2 CDC42EP3 SLCO3A1 RRM2 ADAMTSL4 INPP5F ARHGAP31 ESCO2 ADRB2 CSF1 WDHD1 GOLIM4 CDK5RAP1 CD69 GLUL HJURP SHC4 GNLY TTC9 HELLS DPP4 IL23A PITPNC1 TOX ARHGEF9 EXO1 SLC4A4 CKAP4 CARMIL3 NHSL2 DZIP3 GINS1 FUT8 UBASH3B CDCA5 PDE7B SOGA1 CDC45 NR3C2 TRIB1 KIF14 TRAF5 LIMS1 PPP1R2C TNFRSF9 KLRC2 POLA1 CD80 ATP10D CDCA8 SETD7 IER2 PATL2 CCDC141 CD84 HSPA6 CYB561 MPHOSPH9 CLSPN KLRC1 PTMS SCML4 ZBTB10 CCL3 CA5B PIP5K1B WNT9A CCNH GEM IL18RAP GGH SARDH B3GNT7 C13orf46 SBF2 IKZF3 ZMAT1 TCF7 NECTIN1 H3C7 FOS PAG1 HECA SLC4A10 SLC35G2 PER1 P2RY1 NFKBIA WDR76 PLAUR KDM1A H1-5 TSHZ2 FAM102B HMMR GPR132 CCRL2 PARP8 A2M ST8SIA1 NUF2 IL5RA RBPMS UBE2T USP53 EEF1A1 PLAC8 LGR6 TMEM123 NEK2 SNAP47 PTGIS SH2B3 P2RY8 S100PBP PLEKHA7 CLNK CRIM1 MGAT5 YBX3 TP53INP1 DTL CFH FEZ1 MYB FRMD4B TSPAN5 STIL ITGA2 GOLGA6L10 MYBL2 AHI1 CAND2 GZMB RBPJ PELI1 HSPA1B KCNK5 GOLGA6L9 TICRR TPRG1 UBE2C AURKA Leem G, et al. -

1 AGING Supplementary Table 2
SUPPLEMENTARY TABLES Supplementary Table 1. Details of the eight domain chains of KIAA0101. Serial IDENTITY MAX IN COMP- INTERFACE ID POSITION RESOLUTION EXPERIMENT TYPE number START STOP SCORE IDENTITY LEX WITH CAVITY A 4D2G_D 52 - 69 52 69 100 100 2.65 Å PCNA X-RAY DIFFRACTION √ B 4D2G_E 52 - 69 52 69 100 100 2.65 Å PCNA X-RAY DIFFRACTION √ C 6EHT_D 52 - 71 52 71 100 100 3.2Å PCNA X-RAY DIFFRACTION √ D 6EHT_E 52 - 71 52 71 100 100 3.2Å PCNA X-RAY DIFFRACTION √ E 6GWS_D 41-72 41 72 100 100 3.2Å PCNA X-RAY DIFFRACTION √ F 6GWS_E 41-72 41 72 100 100 2.9Å PCNA X-RAY DIFFRACTION √ G 6GWS_F 41-72 41 72 100 100 2.9Å PCNA X-RAY DIFFRACTION √ H 6IIW_B 2-11 2 11 100 100 1.699Å UHRF1 X-RAY DIFFRACTION √ www.aging-us.com 1 AGING Supplementary Table 2. Significantly enriched gene ontology (GO) annotations (cellular components) of KIAA0101 in lung adenocarcinoma (LinkedOmics). Leading Description FDR Leading Edge Gene EdgeNum RAD51, SPC25, CCNB1, BIRC5, NCAPG, ZWINT, MAD2L1, SKA3, NUF2, BUB1B, CENPA, SKA1, AURKB, NEK2, CENPW, HJURP, NDC80, CDCA5, NCAPH, BUB1, ZWILCH, CENPK, KIF2C, AURKA, CENPN, TOP2A, CENPM, PLK1, ERCC6L, CDT1, CHEK1, SPAG5, CENPH, condensed 66 0 SPC24, NUP37, BLM, CENPE, BUB3, CDK2, FANCD2, CENPO, CENPF, BRCA1, DSN1, chromosome MKI67, NCAPG2, H2AFX, HMGB2, SUV39H1, CBX3, TUBG1, KNTC1, PPP1CC, SMC2, BANF1, NCAPD2, SKA2, NUP107, BRCA2, NUP85, ITGB3BP, SYCE2, TOPBP1, DMC1, SMC4, INCENP. RAD51, OIP5, CDK1, SPC25, CCNB1, BIRC5, NCAPG, ZWINT, MAD2L1, SKA3, NUF2, BUB1B, CENPA, SKA1, AURKB, NEK2, ESCO2, CENPW, HJURP, TTK, NDC80, CDCA5, BUB1, ZWILCH, CENPK, KIF2C, AURKA, DSCC1, CENPN, CDCA8, CENPM, PLK1, MCM6, ERCC6L, CDT1, HELLS, CHEK1, SPAG5, CENPH, PCNA, SPC24, CENPI, NUP37, FEN1, chromosomal 94 0 CENPL, BLM, KIF18A, CENPE, MCM4, BUB3, SUV39H2, MCM2, CDK2, PIF1, DNA2, region CENPO, CENPF, CHEK2, DSN1, H2AFX, MCM7, SUV39H1, MTBP, CBX3, RECQL4, KNTC1, PPP1CC, CENPP, CENPQ, PTGES3, NCAPD2, DYNLL1, SKA2, HAT1, NUP107, MCM5, MCM3, MSH2, BRCA2, NUP85, SSB, ITGB3BP, DMC1, INCENP, THOC3, XPO1, APEX1, XRCC5, KIF22, DCLRE1A, SEH1L, XRCC3, NSMCE2, RAD21. -

Supplementary Table S1. Correlation Between the Mutant P53-Interacting Partners and PTTG3P, PTTG1 and PTTG2, Based on Data from Starbase V3.0 Database
Supplementary Table S1. Correlation between the mutant p53-interacting partners and PTTG3P, PTTG1 and PTTG2, based on data from StarBase v3.0 database. PTTG3P PTTG1 PTTG2 Gene ID Coefficient-R p-value Coefficient-R p-value Coefficient-R p-value NF-YA ENSG00000001167 −0.077 8.59e-2 −0.210 2.09e-6 −0.122 6.23e-3 NF-YB ENSG00000120837 0.176 7.12e-5 0.227 2.82e-7 0.094 3.59e-2 NF-YC ENSG00000066136 0.124 5.45e-3 0.124 5.40e-3 0.051 2.51e-1 Sp1 ENSG00000185591 −0.014 7.50e-1 −0.201 5.82e-6 −0.072 1.07e-1 Ets-1 ENSG00000134954 −0.096 3.14e-2 −0.257 4.83e-9 0.034 4.46e-1 VDR ENSG00000111424 −0.091 4.10e-2 −0.216 1.03e-6 0.014 7.48e-1 SREBP-2 ENSG00000198911 −0.064 1.53e-1 −0.147 9.27e-4 −0.073 1.01e-1 TopBP1 ENSG00000163781 0.067 1.36e-1 0.051 2.57e-1 −0.020 6.57e-1 Pin1 ENSG00000127445 0.250 1.40e-8 0.571 9.56e-45 0.187 2.52e-5 MRE11 ENSG00000020922 0.063 1.56e-1 −0.007 8.81e-1 −0.024 5.93e-1 PML ENSG00000140464 0.072 1.05e-1 0.217 9.36e-7 0.166 1.85e-4 p63 ENSG00000073282 −0.120 7.04e-3 −0.283 1.08e-10 −0.198 7.71e-6 p73 ENSG00000078900 0.104 2.03e-2 0.258 4.67e-9 0.097 3.02e-2 Supplementary Table S2. -

(P -Value<0.05, Fold Change≥1.4), 4 Vs. 0 Gy Irradiation
Table S1: Significant differentially expressed genes (P -Value<0.05, Fold Change≥1.4), 4 vs. 0 Gy irradiation Genbank Fold Change P -Value Gene Symbol Description Accession Q9F8M7_CARHY (Q9F8M7) DTDP-glucose 4,6-dehydratase (Fragment), partial (9%) 6.70 0.017399678 THC2699065 [THC2719287] 5.53 0.003379195 BC013657 BC013657 Homo sapiens cDNA clone IMAGE:4152983, partial cds. [BC013657] 5.10 0.024641735 THC2750781 Ciliary dynein heavy chain 5 (Axonemal beta dynein heavy chain 5) (HL1). 4.07 0.04353262 DNAH5 [Source:Uniprot/SWISSPROT;Acc:Q8TE73] [ENST00000382416] 3.81 0.002855909 NM_145263 SPATA18 Homo sapiens spermatogenesis associated 18 homolog (rat) (SPATA18), mRNA [NM_145263] AA418814 zw01a02.s1 Soares_NhHMPu_S1 Homo sapiens cDNA clone IMAGE:767978 3', 3.69 0.03203913 AA418814 AA418814 mRNA sequence [AA418814] AL356953 leucine-rich repeat-containing G protein-coupled receptor 6 {Homo sapiens} (exp=0; 3.63 0.0277936 THC2705989 wgp=1; cg=0), partial (4%) [THC2752981] AA484677 ne64a07.s1 NCI_CGAP_Alv1 Homo sapiens cDNA clone IMAGE:909012, mRNA 3.63 0.027098073 AA484677 AA484677 sequence [AA484677] oe06h09.s1 NCI_CGAP_Ov2 Homo sapiens cDNA clone IMAGE:1385153, mRNA sequence 3.48 0.04468495 AA837799 AA837799 [AA837799] Homo sapiens hypothetical protein LOC340109, mRNA (cDNA clone IMAGE:5578073), partial 3.27 0.031178378 BC039509 LOC643401 cds. [BC039509] Homo sapiens Fas (TNF receptor superfamily, member 6) (FAS), transcript variant 1, mRNA 3.24 0.022156298 NM_000043 FAS [NM_000043] 3.20 0.021043295 A_32_P125056 BF803942 CM2-CI0135-021100-477-g08 CI0135 Homo sapiens cDNA, mRNA sequence 3.04 0.043389246 BF803942 BF803942 [BF803942] 3.03 0.002430239 NM_015920 RPS27L Homo sapiens ribosomal protein S27-like (RPS27L), mRNA [NM_015920] Homo sapiens tumor necrosis factor receptor superfamily, member 10c, decoy without an 2.98 0.021202829 NM_003841 TNFRSF10C intracellular domain (TNFRSF10C), mRNA [NM_003841] 2.97 0.03243901 AB002384 C6orf32 Homo sapiens mRNA for KIAA0386 gene, partial cds. -

WO 2012/174282 A2 20 December 2012 (20.12.2012) P O P C T
(12) INTERNATIONAL APPLICATION PUBLISHED UNDER THE PATENT COOPERATION TREATY (PCT) (19) World Intellectual Property Organization International Bureau (10) International Publication Number (43) International Publication Date WO 2012/174282 A2 20 December 2012 (20.12.2012) P O P C T (51) International Patent Classification: David [US/US]; 13539 N . 95th Way, Scottsdale, AZ C12Q 1/68 (2006.01) 85260 (US). (21) International Application Number: (74) Agent: AKHAVAN, Ramin; Caris Science, Inc., 6655 N . PCT/US20 12/0425 19 Macarthur Blvd., Irving, TX 75039 (US). (22) International Filing Date: (81) Designated States (unless otherwise indicated, for every 14 June 2012 (14.06.2012) kind of national protection available): AE, AG, AL, AM, AO, AT, AU, AZ, BA, BB, BG, BH, BR, BW, BY, BZ, English (25) Filing Language: CA, CH, CL, CN, CO, CR, CU, CZ, DE, DK, DM, DO, Publication Language: English DZ, EC, EE, EG, ES, FI, GB, GD, GE, GH, GM, GT, HN, HR, HU, ID, IL, IN, IS, JP, KE, KG, KM, KN, KP, KR, (30) Priority Data: KZ, LA, LC, LK, LR, LS, LT, LU, LY, MA, MD, ME, 61/497,895 16 June 201 1 (16.06.201 1) US MG, MK, MN, MW, MX, MY, MZ, NA, NG, NI, NO, NZ, 61/499,138 20 June 201 1 (20.06.201 1) US OM, PE, PG, PH, PL, PT, QA, RO, RS, RU, RW, SC, SD, 61/501,680 27 June 201 1 (27.06.201 1) u s SE, SG, SK, SL, SM, ST, SV, SY, TH, TJ, TM, TN, TR, 61/506,019 8 July 201 1(08.07.201 1) u s TT, TZ, UA, UG, US, UZ, VC, VN, ZA, ZM, ZW. -

How Does SUMO Participate in Spindle Organization?
cells Review How Does SUMO Participate in Spindle Organization? Ariane Abrieu * and Dimitris Liakopoulos * CRBM, CNRS UMR5237, Université de Montpellier, 1919 route de Mende, 34090 Montpellier, France * Correspondence: [email protected] (A.A.); [email protected] (D.L.) Received: 5 July 2019; Accepted: 30 July 2019; Published: 31 July 2019 Abstract: The ubiquitin-like protein SUMO is a regulator involved in most cellular mechanisms. Recent studies have discovered new modes of function for this protein. Of particular interest is the ability of SUMO to organize proteins in larger assemblies, as well as the role of SUMO-dependent ubiquitylation in their disassembly. These mechanisms have been largely described in the context of DNA repair, transcriptional regulation, or signaling, while much less is known on how SUMO facilitates organization of microtubule-dependent processes during mitosis. Remarkably however, SUMO has been known for a long time to modify kinetochore proteins, while more recently, extensive proteomic screens have identified a large number of microtubule- and spindle-associated proteins that are SUMOylated. The aim of this review is to focus on the possible role of SUMOylation in organization of the spindle and kinetochore complexes. We summarize mitotic and microtubule/spindle-associated proteins that have been identified as SUMO conjugates and present examples regarding their regulation by SUMO. Moreover, we discuss the possible contribution of SUMOylation in organization of larger protein assemblies on the spindle, as well as the role of SUMO-targeted ubiquitylation in control of kinetochore assembly and function. Finally, we propose future directions regarding the study of SUMOylation in regulation of spindle organization and examine the potential of SUMO and SUMO-mediated degradation as target for antimitotic-based therapies. -

A High-Throughput Approach to Uncover Novel Roles of APOBEC2, a Functional Orphan of the AID/APOBEC Family
Rockefeller University Digital Commons @ RU Student Theses and Dissertations 2018 A High-Throughput Approach to Uncover Novel Roles of APOBEC2, a Functional Orphan of the AID/APOBEC Family Linda Molla Follow this and additional works at: https://digitalcommons.rockefeller.edu/ student_theses_and_dissertations Part of the Life Sciences Commons A HIGH-THROUGHPUT APPROACH TO UNCOVER NOVEL ROLES OF APOBEC2, A FUNCTIONAL ORPHAN OF THE AID/APOBEC FAMILY A Thesis Presented to the Faculty of The Rockefeller University in Partial Fulfillment of the Requirements for the degree of Doctor of Philosophy by Linda Molla June 2018 © Copyright by Linda Molla 2018 A HIGH-THROUGHPUT APPROACH TO UNCOVER NOVEL ROLES OF APOBEC2, A FUNCTIONAL ORPHAN OF THE AID/APOBEC FAMILY Linda Molla, Ph.D. The Rockefeller University 2018 APOBEC2 is a member of the AID/APOBEC cytidine deaminase family of proteins. Unlike most of AID/APOBEC, however, APOBEC2’s function remains elusive. Previous research has implicated APOBEC2 in diverse organisms and cellular processes such as muscle biology (in Mus musculus), regeneration (in Danio rerio), and development (in Xenopus laevis). APOBEC2 has also been implicated in cancer. However the enzymatic activity, substrate or physiological target(s) of APOBEC2 are unknown. For this thesis, I have combined Next Generation Sequencing (NGS) techniques with state-of-the-art molecular biology to determine the physiological targets of APOBEC2. Using a cell culture muscle differentiation system, and RNA sequencing (RNA-Seq) by polyA capture, I demonstrated that unlike the AID/APOBEC family member APOBEC1, APOBEC2 is not an RNA editor. Using the same system combined with enhanced Reduced Representation Bisulfite Sequencing (eRRBS) analyses I showed that, unlike the AID/APOBEC family member AID, APOBEC2 does not act as a 5-methyl-C deaminase. -

A Systems-Genetics Analyses of Complex Phenotypes
A systems-genetics analyses of complex phenotypes A thesis submitted to the University of Manchester for the degree of Doctor of Philosophy in the Faculty of Life Sciences 2015 David Ashbrook Table of contents Table of contents Table of contents ............................................................................................... 1 Tables and figures ........................................................................................... 10 General abstract ............................................................................................... 14 Declaration ....................................................................................................... 15 Copyright statement ........................................................................................ 15 Acknowledgements.......................................................................................... 16 Chapter 1: General introduction ...................................................................... 17 1.1 Overview................................................................................................... 18 1.2 Linkage, association and gene annotations .............................................. 20 1.3 ‘Big data’ and ‘omics’ ................................................................................ 22 1.4 Systems-genetics ..................................................................................... 24 1.5 Recombinant inbred (RI) lines and the BXD .............................................. 25 Figure 1.1: -

Loss of PRDM1/BLIMP-1 Function Contributes to Poor Prognosis for Activated B-Cell–Like Diffuse Large B-Cell Lymphoma
HHS Public Access Author manuscript Author ManuscriptAuthor Manuscript Author Leukemia Manuscript Author . Author manuscript; Manuscript Author available in PMC 2018 March 05. Published in final edited form as: Leukemia. 2017 March ; 31(3): 625–636. doi:10.1038/leu.2016.243. Loss of PRDM1/BLIMP-1 function contributes to poor prognosis for activated B-cell–like diffuse large B-cell lymphoma Yi Xia1,2,*, Zijun Y. Xu-Monette1,*, Alexandar Tzankov3,*, Xin Li1, Ganiraju C. Manyam4, Vundavalli Murty5, Govind Bhagat5, Shanxiang Zhang1, Laura Pasqualucci5, Li Zhang4, Carlo Visco6, Karen Dybkaer7, April Chiu8, Attilio Orazi9, Youli Zu10, Kristy L. Richards11, Eric D. Hsi12, William W.L. Choi13, J. Han van Krieken14, Jooryung Huh15, Maurilio Ponzoni16, Andrés J.M. Ferreri16, Michael B. Møller17, Ben M. Parsons18, Jane N. Winter19, Miguel A. Piris20, Jason Westin21, Nathan Fowler21, Roberto N. Miranda1, Chi Young Ok1, Jianyong Li2,¶, L. Jeffrey Medeiros1, and Ken H. Young1,22,¶ 1Department of Hematopathology, The University of Texas MD Anderson Cancer Center, Houston, TX, USA 2The First Affiliated Hospital of Nanjing Medical University, Jiangsu Province Hospital, Nanjing, China 3University Hospital, Basel, Switzerland 4Department of Bioinformatics and Computational Biology, The University of Texas MD Anderson Cancer Center, Houston, Texas, USA 5Columbia University Medical Center and New York Presbyterian Hospital, New York, NY, USA 6San Bortolo Hospital, Vicenza, Italy 7Aalborg University Hospital, Aalborg, Denmark 8Memorial Sloan-Kettering Cancer Center, New York, NY, USA 9Weill Medical College of Cornell University, New York, NY, USA 10The Methodist Hospital, Houston, TX, USA 11Cornell University, Ithaca, NY, USA 12Cleveland Clinic, Cleveland, OH, USA 13University of Hong Kong Li Ka Shing Faculty of Medicine, Hong Kong, China 14Radboud University Nijmegen Medical Centre, Nijmegen, Netherlands 15Asan Medical Center, Ulsan University College of Medicine, Seoul, Korea 16San Raffaele H. -

Ranking Variable Combinations to Characterize Breast Cancer Subtypes Using the IBIF-RF Metric
EPiC Series in Computing Volume 70, 2020, Pages 11{20 Proceedings of the 12th International Conference on Bioinformatics and Computational Biology Ranking Variable Combinations to Characterize Breast Cancer Subtypes using the IBIF-RF Metric Isis Narvaez-Bandera and Wandaliz Torres-Garc´ıa University of Puerto Rico, Mayag¨uezCampus, PR, 00681 USA [email protected] and [email protected] Abstract Gene interactions play a fundamental role in the proneness to cancer. However, detect- ing and ranking these interactions is a complex problem due to the high dimensionality of genomic data. Hence, we aim to find patterns composed of multiple features to molecu- larly characterize breast cancer subtypes from the integration of different omics datasets using a data mining approach. To retrieve biological understanding from these compu- tational results, we developed IBIF-RF (Importance Between Interactive Features using Random Forest), a new metric capable of assessing and holistically ranking the importance of genomic interactions without any prior knowledge of key feature combinations. A set of 247 top-performing features from transcriptomic, proteomic, methylation, and clinical data were used to investigate interactive patterns to classify breast cancer subtypes us- ing over 1150 samples. IBIF-RF metric allowed the extraction of 154312, 190481, and 463917 combinations of variables for TCGA, GSE20685, and GSE21653 datasets. Single genes, MLPH and FOXA1, were the most frequently identified variables across all datasets followed by some two-gene interactions such as CEP55-FOXA1 and FOXC1-THSD4. More- over, IBIF-RF metric allowed the definition of two sets of genes frequently found together (1: FOXA1, MLPH, and SIDT1, and 2: CEP55, ASPM, CENPL, AURKA, ESPL1, TTK, UBE2T, NCAPG, GMPS, NDC80, MYBL2, KIF18B, and EXO1).