TESTING STATISTICAL ASSUMPTIONS 2012 Edition
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-
Section 13 Kolmogorov-Smirnov Test
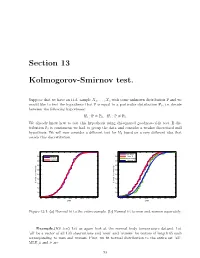
Section 13 Kolmogorov-Smirnov test. Suppose that we have an i.i.d. sample X1; : : : ; Xn with some unknown distribution P and we would like to test the hypothesis that P is equal to a particular distribution P0; i.e. decide between the following hypotheses: H : P = P ; H : P = P : 0 0 1 6 0 We already know how to test this hypothesis using chi-squared goodness-of-fit test. If dis tribution P0 is continuous we had to group the data and consider a weaker discretized null hypothesis. We will now consider a different test for H0 based on a very different idea that avoids this discretization. 1 1 men data 0.9 0.9 'men' fit all data women data 0.8 normal fit 0.8 'women' fit 0.7 0.7 0.6 0.6 0.5 0.5 0.4 0.4 Cumulative probability 0.3 Cumulative probability 0.3 0.2 0.2 0.1 0.1 0 0 96 96.5 97 97.5 98 98.5 99 99.5 100 100.5 96.5 97 97.5 98 98.5 99 99.5 100 100.5 Data Data Figure 13.1: (a) Normal fit to the entire sample. (b) Normal fit to men and women separately. Example.(KS test) Let us again look at the normal body temperature dataset. Let ’all’ be a vector of all 130 observations and ’men’ and ’women’ be vectors of length 65 each corresponding to men and women. First, we fit normal distribution to the entire set ’all’. -

05 36534Nys130620 31
Monte Carlos study on Power Rates of Some Heteroscedasticity detection Methods in Linear Regression Model with multicollinearity problem O.O. Alabi, Kayode Ayinde, O. E. Babalola, and H.A. Bello Department of Statistics, Federal University of Technology, P.M.B. 704, Akure, Ondo State, Nigeria Corresponding Author: O. O. Alabi, [email protected] Abstract: This paper examined the power rate exhibit by some heteroscedasticity detection methods in a linear regression model with multicollinearity problem. Violation of unequal error variance assumption in any linear regression model leads to the problem of heteroscedasticity, while violation of the assumption of non linear dependency between the exogenous variables leads to multicollinearity problem. Whenever these two problems exist one would faced with estimation and hypothesis problem. in order to overcome these hurdles, one needs to determine the best method of heteroscedasticity detection in other to avoid taking a wrong decision under hypothesis testing. This then leads us to the way and manner to determine the best heteroscedasticity detection method in a linear regression model with multicollinearity problem via power rate. In practices, variance of error terms are unequal and unknown in nature, but there is need to determine the presence or absence of this problem that do exist in unknown error term as a preliminary diagnosis on the set of data we are to analyze or perform hypothesis testing on. Although, there are several forms of heteroscedasticity and several detection methods of heteroscedasticity, but for any researcher to arrive at a reasonable and correct decision, best and consistent performed methods of heteroscedasticity detection under any forms or structured of heteroscedasticity must be determined. -

Computer-Assisted Data Treatment in Analytical Chemometrics III. Data Transformation
Computer-Assisted Data Treatment in Analytical Chemometrics III. Data Transformation aM. MELOUN and bJ. MILITKÝ department of Analytical Chemistry, Faculty of Chemical Technology, University Pardubice, CZ-532 10 Pardubice ъDepartment of Textile Materials, Technical University, CZ-461 17 Liberec Received 30 April 1993 In trace analysis an exploratory data analysis (EDA) often finds that the sample distribution is systematically skewed or does not prove a sample homogeneity. Under such circumstances the original data should often be transformed. The power simple transformation and the Box—Cox transformation improves a sample symmetry and also makes stabilization of variance. The Hines— Hines selection graph and the plot of logarithm of the maximum likelihood function enables to find an optimum transformation parameter. Procedure of data transformation in the univariate data analysis is illustrated on quantitative determination of copper traces in kaolin raw. When exploratory data analysis shows that the i) Transformation for variance stabilization implies sample distribution strongly differs from the normal ascertaining the transformation у = g(x) in which the one, we are faced with the problem of how to analyze variance cf(y) is constant. If the variance of the origi the data. Raw data may require re-expression to nal variable x is a function of the type cf(x) = ^(x), produce an informative display, effective summary, the variance cr(y) may be expressed by or a straightforward analysis [1—10]. We may need to change not only the units in which the data are 2 fdg(x)f stated, but also the basic scale of the measurement. <У2(У)= -^ /i(x)=C (1) To change the shape of a data distribution, we must I dx J do more than change the origin and/or unit of mea surement. -

Downloaded 09/24/21 09:09 AM UTC
MARCH 2007 NOTES AND CORRESPONDENCE 1151 NOTES AND CORRESPONDENCE A Cautionary Note on the Use of the Kolmogorov–Smirnov Test for Normality DAG J. STEINSKOG Nansen Environmental and Remote Sensing Center, and Bjerknes Centre for Climate Research, and Geophysical Institute, University of Bergen, Bergen, Norway DAG B. TJØSTHEIM Department of Mathematics, University of Bergen, Bergen, Norway NILS G. KVAMSTØ Geophysical Institute, University of Bergen, and Bjerknes Centre for Climate Research, Bergen, Norway (Manuscript received and in final form 28 April 2006) ABSTRACT The Kolmogorov–Smirnov goodness-of-fit test is used in many applications for testing normality in climate research. This note shows that the test usually leads to systematic and drastic errors. When the mean and the standard deviation are estimated, it is much too conservative in the sense that its p values are strongly biased upward. One may think that this is a small sample problem, but it is not. There is a correction of the Kolmogorov–Smirnov test by Lilliefors, which is in fact sometimes confused with the original Kolmogorov–Smirnov test. Both the Jarque–Bera and the Shapiro–Wilk tests for normality are good alternatives to the Kolmogorov–Smirnov test. A power comparison of eight different tests has been undertaken, favoring the Jarque–Bera and the Shapiro–Wilk tests. The Jarque–Bera and the Kolmogorov– Smirnov tests are also applied to a monthly mean dataset of geopotential height at 500 hPa. The two tests give very different results and illustrate the danger of using the Kolmogorov–Smirnov test. 1. Introduction estimates of skewness and kurtosis. Such moments can be used to diagnose nonlinear processes and to provide The Kolmogorov–Smirnov test (hereafter the KS powerful tools for validating models (see also Ger- test) is a much used goodness-of-fit test. -

Business Economics Paper No. : 8, Fundamentals of Econometrics Module No. : 15, Heteroscedasticity Detection
____________________________________________________________________________________________________ Subject Business Economics Paper 8, Fundamentals of Econometrics Module No and Title 15, Heteroscedasticity- Detection Module Tag BSE_P8_M15 BUSINESS PAPER NO. : 8, FUNDAMENTALS OF ECONOMETRICS ECONOMICS MODULE NO. : 15, HETEROSCEDASTICITY DETECTION ____________________________________________________________________________________________________ TABLE OF CONTENTS 1. Learning Outcomes 2. Introduction 3. Different diagnostic tools to identify the problem of heteroscedasticity 4. Informal methods to identify the problem of heteroscedasticity 4.1 Checking Nature of the problem 4.2 Graphical inspection of residuals 5. Formal methods to identify the problem of heteroscedasticity 5.1 Park Test 5.2 Glejser test 5.3 White's test 5.4 Spearman's rank correlation test 5.5 Goldfeld-Quandt test 5.6 Breusch- Pagan test 6. Summary BUSINESS PAPER NO. : 8, FUNDAMENTALS OF ECONOMETRICS ECONOMICS MODULE NO. : 15, HETEROSCEDASTICITY DETECTION ____________________________________________________________________________________________________ 1.Learning Outcomes After studying this module, you shall be able to understand Different diagnostic tools to detect the problem of heteroscedasticity Informal methods to identify the problem of heteroscedasticity Formal methods to identify the problem of heteroscedasticity 2. Introduction So far in the previous module we have seen that heteroscedasticity is a violation of one of the assumptions of the classical -

Graduate Econometrics Review
Graduate Econometrics Review Paul J. Healy [email protected] April 13, 2005 ii Contents Contents iii Preface ix Introduction xi I Probability 1 1 Probability Theory 3 1.1 Counting ............................... 3 1.1.1 Ordering & Replacement .................. 3 1.2 The Probability Space ........................ 4 1.2.1 Set-Theoretic Tools ..................... 5 1.2.2 Sigma-algebras ........................ 6 1.2.3 Measure Spaces & Probability Spaces ........... 9 1.2.4 The Probability Measure P ................. 10 1.2.5 The Probability Space (; §; P) ............... 11 1.2.6 Random Variables & Induced Probability Measures .... 13 1.3 Conditional Probability & Independence .............. 15 1.3.1 Conditional Probability ................... 15 1.3.2 Warner's Method ....................... 16 1.3.3 Independence ......................... 17 1.3.4 Philosophical Remarks .................... 18 1.4 Important Probability Tools ..................... 19 1.4.1 Probability Distributions .................. 22 1.4.2 The Expectation Operator .................. 23 1.4.3 Variance and Coviariance .................. 25 2 Probability Distributions 27 2.1 Density & Mass Functions ...................... 27 2.1.1 Moments & MGFs ...................... 27 2.1.2 A Side Note on Di®erentiating Under and Integral .... 28 2.2 Commonly Used Distributions .................... 29 iii iv CONTENTS 2.2.1 Discrete Distributions .................... 29 2.2.2 Continuous Distributions .................. 30 2.2.3 Useful Approximations .................... 31 3 Working With Multiple Random Variables 33 3.1 Random Vectors ........................... 33 3.2 Distributions of Multiple Variables ................. 33 3.2.1 Joint and Marginal Distributions .............. 33 3.2.2 Conditional Distributions and Independence ........ 34 3.2.3 The Bivariate Normal Distribution ............. 35 3.2.4 Useful Distribution Identities ................ 38 3.3 Transformations (Functions of Random Variables) ........ 39 3.3.1 Single Variable Transformations ............. -

Exponentiality Test Using a Modified Lilliefors Test Achut Prasad Adhikari
University of Northern Colorado Scholarship & Creative Works @ Digital UNC Dissertations Student Research 5-1-2014 Exponentiality Test Using a Modified Lilliefors Test Achut Prasad Adhikari Follow this and additional works at: http://digscholarship.unco.edu/dissertations Recommended Citation Adhikari, Achut Prasad, "Exponentiality Test Using a Modified Lilliefors Test" (2014). Dissertations. Paper 63. This Text is brought to you for free and open access by the Student Research at Scholarship & Creative Works @ Digital UNC. It has been accepted for inclusion in Dissertations by an authorized administrator of Scholarship & Creative Works @ Digital UNC. For more information, please contact [email protected]. UNIVERSITY OF NORTHERN COLORADO Greeley, Colorado The Graduate School AN EXPONENTIALITY TEST USING A MODIFIED LILLIEFORS TEST A Dissertation Submitted in Partial Fulfillment Of the Requirements for the Degree of Doctor of Philosophy Achut Prasad Adhikari College of Education and Behavioral Sciences Department of Applied Statistics and Research Methods May 2014 ABSTRACT Adhikari, Achut Prasad An Exponentiality Test Using a Modified Lilliefors Test. Published Doctor of Philosophy dissertation, University of Northern Colorado, 2014. A new exponentiality test was developed by modifying the Lilliefors test of exponentiality for the purpose of improving the power of the test it directly modified. Lilliefors has considered the maximum absolute differences between the sample empirical distribution function (EDF) and the exponential cumulative distribution function (CDF). The proposed test considered the sum of all the absolute differences between the CDF and EDF. By considering the sum of all the absolute differences rather than only a point difference of each observation, the proposed test would expect to be less affected by individual extreme (too low or too high) observations and capable of detecting smaller, but consistent, differences between the distributions. -

Power Comparisons of Shapiro-Wilk, Kolmogorov-Smirnov, Lilliefors and Anderson-Darling Tests
Journal ofStatistical Modeling and Analytics Vol.2 No.I, 21-33, 2011 Power comparisons of Shapiro-Wilk, Kolmogorov-Smirnov, Lilliefors and Anderson-Darling tests Nornadiah Mohd Razali1 Yap Bee Wah 1 1Faculty ofComputer and Mathematica/ Sciences, Universiti Teknologi MARA, 40450 Shah Alam, Selangor, Malaysia E-mail: nornadiah@tmsk. uitm. edu.my, yapbeewah@salam. uitm. edu.my ABSTRACT The importance of normal distribution is undeniable since it is an underlying assumption of many statistical procedures such as I-tests, linear regression analysis, discriminant analysis and Analysis of Variance (ANOVA). When the normality assumption is violated, interpretation and inferences may not be reliable or valid. The three common procedures in assessing whether a random sample of independent observations of size n come from a population with a normal distribution are: graphical methods (histograms, boxplots, Q-Q-plots), numerical methods (skewness and kurtosis indices) and formal normality tests. This paper* compares the power offour formal tests of normality: Shapiro-Wilk (SW) test, Kolmogorov-Smirnov (KS) test, Lillie/ors (LF) test and Anderson-Darling (AD) test. Power comparisons of these four tests were obtained via Monte Carlo simulation of sample data generated from alternative distributions that follow symmetric and asymmetric distributions. Ten thousand samples ofvarious sample size were generated from each of the given alternative symmetric and asymmetric distributions. The power of each test was then obtained by comparing the test of normality statistics with the respective critical values. Results show that Shapiro-Wilk test is the most powerful normality test, followed by Anderson-Darling test, Lillie/ors test and Kolmogorov-Smirnov test. However, the power ofall four tests is still low for small sample size. -

Systematic Evaluation and Optimization of Outbreak-Detection Algorithms Based on Labeled Epidemiological Surveillance Data
Universit¨atOsnabr¨uck Fachbereich Humanwissenschaften Institute of Cognitive Science Masterthesis Systematic Evaluation and Optimization of Outbreak-Detection Algorithms Based on Labeled Epidemiological Surveillance Data R¨udigerBusche 968684 Master's Program Cognitive Science November 2018 - April 2019 First supervisor: Dr. St´ephaneGhozzi Robert Koch Institute Berlin Second supervisor: Prof. Dr. Gordon Pipa Institute of Cognitive Science Osnabr¨uck Declaration of Authorship I hereby certify that the work presented here is, to the best of my knowledge and belief, original and the result of my own investigations, except as acknowledged, and has not been submitted, either in part or whole, for a degree at this or any other university. city, date signature Abstract Indicator-based surveillance is a cornerstone of Epidemic Intelligence, which has the objective of detecting disease outbreaks early to prevent the further spread of diseases. As the major institution for public health in Germany, the Robert Koch Institute continuously collects confirmed cases of notifiable diseases from all over the country. Each week the numbers of confirmed cases are evaluated for statistical irregularities. Theses irregularities are referred to as signals. They are reviewed by epidemiologists at the Robert Koch Institute and state level health institutions, and, if found relevant, communicated to local health agencies. While certain algo- rithms have been established for this task, they have usually only been tested on simulated data and are used with a set of default hyperparameters. In this work, we develop a framework to systematically evaluate outbreak detection algorithms on labeled data. These labels are manual annotations of individual cases by ex- perts, such as records of outbreak investigations. -

Regression: an Introduction to Econometrics
Regression: An Introduction to Econometrics Overview The goal in the econometric work is to help us move from the qualitative analysis in the theoretical work favored in the textbooks to the quantitative world in which policy makers operate. The focus in this work is the quantification of relationships. For example, in microeconomics one of the central concepts was demand. It is one half of the supply-demand model that economists use to explain prices, whether it is the price of stock, the exchange rate, wages, or the price of bananas. One of the fundamental rules of economics is the downward sloping demand curve - an increase in price will result in lower demand. Knowing this, would you be in a position to decide on a pricing strategy for your product? For example, armed with the knowledge that demand is negatively related to price, do you have enough information to decide whether a price increase or decrease will raise sales revenue? You may recall from a discussion in an intro econ course that the answer depends upon the elasticity of demand, a measure of how responsive demand is to price changes. But how do we get the elasticity of demand? In your earlier work you were just given the number and asked how this would influence your choices, while here you will be asked to figure out what the elasticity figure is. It is here things become interesting, where we must move from the deterministic world of algebra and calculus to the probabilistic world of statistics. To make this move, a working knowledge of econometrics, a fancy name for applied statistics, is extremely valuable. -
Univariate Analysis and Normality Test Using SAS, STATA, and SPSS
© 2002-2006 The Trustees of Indiana University Univariate Analysis and Normality Test: 1 Univariate Analysis and Normality Test Using SAS, STATA, and SPSS Hun Myoung Park This document summarizes graphical and numerical methods for univariate analysis and normality test, and illustrates how to test normality using SAS 9.1, STATA 9.2 SE, and SPSS 14.0. 1. Introduction 2. Graphical Methods 3. Numerical Methods 4. Testing Normality Using SAS 5. Testing Normality Using STATA 6. Testing Normality Using SPSS 7. Conclusion 1. Introduction Descriptive statistics provide important information about variables. Mean, median, and mode measure the central tendency of a variable. Measures of dispersion include variance, standard deviation, range, and interquantile range (IQR). Researchers may draw a histogram, a stem-and-leaf plot, or a box plot to see how a variable is distributed. Statistical methods are based on various underlying assumptions. One common assumption is that a random variable is normally distributed. In many statistical analyses, normality is often conveniently assumed without any empirical evidence or test. But normality is critical in many statistical methods. When this assumption is violated, interpretation and inference may not be reliable or valid. Figure 1. Comparing the Standard Normal and a Bimodal Probability Distributions Standard Normal Distribution Bimodal Distribution .4 .4 .3 .3 .2 .2 .1 .1 0 0 -5 -3 -1 1 3 5 -5 -3 -1 1 3 5 T-test and ANOVA (Analysis of Variance) compare group means, assuming variables follow normal probability distributions. Otherwise, these methods do not make much http://www.indiana.edu/~statmath © 2002-2006 The Trustees of Indiana University Univariate Analysis and Normality Test: 2 sense. -

Applied Regression Analysis Course Notes for STAT 378/502
Applied Regression Analysis Course notes for STAT 378/502 Adam B Kashlak Mathematical & Statistical Sciences University of Alberta Edmonton, Canada, T6G 2G1 November 19, 2018 cbna This work is licensed under the Creative Commons Attribution- NonCommercial-ShareAlike 4.0 International License. To view a copy of this license, visit http://creativecommons.org/licenses/ by-nc-sa/4.0/. Contents Preface1 1 Ordinary Least Squares2 1.1 Point Estimation.............................5 1.1.1 Derivation of the OLS estimator................5 1.1.2 Maximum likelihood estimate under normality........7 1.1.3 Proof of the Gauss-Markov Theorem..............8 1.2 Hypothesis Testing............................9 1.2.1 Goodness of fit..........................9 1.2.2 Regression coefficients...................... 10 1.2.3 Partial F-test........................... 11 1.3 Confidence Intervals........................... 11 1.4 Prediction Intervals............................ 12 1.4.1 Prediction for an expected observation............. 12 1.4.2 Prediction for a new observation................ 14 1.5 Indicator Variables and ANOVA.................... 14 1.5.1 Indicator variables........................ 14 1.5.2 ANOVA.............................. 16 2 Model Assumptions 18 2.1 Plotting Residuals............................ 18 2.1.1 Plotting Residuals........................ 19 2.2 Transformation.............................. 22 2.2.1 Variance Stabilizing....................... 23 2.2.2 Linearization........................... 24 2.2.3 Box-Cox and the power transform............... 25 2.2.4 Cars Data............................. 26 2.3 Polynomial Regression.......................... 27 2.3.1 Model Problems......................... 28 2.3.2 Piecewise Polynomials...................... 32 2.3.3 Interacting Regressors...................... 36 2.4 Influence and Leverage.......................... 37 2.4.1 The Hat Matrix......................... 37 2.4.2 Cook's D............................. 38 2.4.3 DFBETAS...........................