Null Hypothesis Against an Alternative Hypothesis
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-
Section 13 Kolmogorov-Smirnov Test
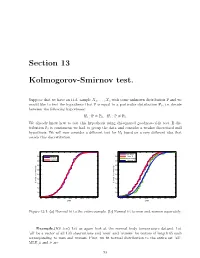
Section 13 Kolmogorov-Smirnov test. Suppose that we have an i.i.d. sample X1; : : : ; Xn with some unknown distribution P and we would like to test the hypothesis that P is equal to a particular distribution P0; i.e. decide between the following hypotheses: H : P = P ; H : P = P : 0 0 1 6 0 We already know how to test this hypothesis using chi-squared goodness-of-fit test. If dis tribution P0 is continuous we had to group the data and consider a weaker discretized null hypothesis. We will now consider a different test for H0 based on a very different idea that avoids this discretization. 1 1 men data 0.9 0.9 'men' fit all data women data 0.8 normal fit 0.8 'women' fit 0.7 0.7 0.6 0.6 0.5 0.5 0.4 0.4 Cumulative probability 0.3 Cumulative probability 0.3 0.2 0.2 0.1 0.1 0 0 96 96.5 97 97.5 98 98.5 99 99.5 100 100.5 96.5 97 97.5 98 98.5 99 99.5 100 100.5 Data Data Figure 13.1: (a) Normal fit to the entire sample. (b) Normal fit to men and women separately. Example.(KS test) Let us again look at the normal body temperature dataset. Let ’all’ be a vector of all 130 observations and ’men’ and ’women’ be vectors of length 65 each corresponding to men and women. First, we fit normal distribution to the entire set ’all’. -

Statistical Analysis in JASP
Copyright © 2018 by Mark A Goss-Sampson. All rights reserved. This book or any portion thereof may not be reproduced or used in any manner whatsoever without the express written permission of the author except for the purposes of research, education or private study. CONTENTS PREFACE .................................................................................................................................................. 1 USING THE JASP INTERFACE .................................................................................................................... 2 DESCRIPTIVE STATISTICS ......................................................................................................................... 8 EXPLORING DATA INTEGRITY ................................................................................................................ 15 ONE SAMPLE T-TEST ............................................................................................................................. 22 BINOMIAL TEST ..................................................................................................................................... 25 MULTINOMIAL TEST .............................................................................................................................. 28 CHI-SQUARE ‘GOODNESS-OF-FIT’ TEST............................................................................................. 30 MULTINOMIAL AND Χ2 ‘GOODNESS-OF-FIT’ TEST. .......................................................................... -

Downloaded 09/24/21 09:09 AM UTC
MARCH 2007 NOTES AND CORRESPONDENCE 1151 NOTES AND CORRESPONDENCE A Cautionary Note on the Use of the Kolmogorov–Smirnov Test for Normality DAG J. STEINSKOG Nansen Environmental and Remote Sensing Center, and Bjerknes Centre for Climate Research, and Geophysical Institute, University of Bergen, Bergen, Norway DAG B. TJØSTHEIM Department of Mathematics, University of Bergen, Bergen, Norway NILS G. KVAMSTØ Geophysical Institute, University of Bergen, and Bjerknes Centre for Climate Research, Bergen, Norway (Manuscript received and in final form 28 April 2006) ABSTRACT The Kolmogorov–Smirnov goodness-of-fit test is used in many applications for testing normality in climate research. This note shows that the test usually leads to systematic and drastic errors. When the mean and the standard deviation are estimated, it is much too conservative in the sense that its p values are strongly biased upward. One may think that this is a small sample problem, but it is not. There is a correction of the Kolmogorov–Smirnov test by Lilliefors, which is in fact sometimes confused with the original Kolmogorov–Smirnov test. Both the Jarque–Bera and the Shapiro–Wilk tests for normality are good alternatives to the Kolmogorov–Smirnov test. A power comparison of eight different tests has been undertaken, favoring the Jarque–Bera and the Shapiro–Wilk tests. The Jarque–Bera and the Kolmogorov– Smirnov tests are also applied to a monthly mean dataset of geopotential height at 500 hPa. The two tests give very different results and illustrate the danger of using the Kolmogorov–Smirnov test. 1. Introduction estimates of skewness and kurtosis. Such moments can be used to diagnose nonlinear processes and to provide The Kolmogorov–Smirnov test (hereafter the KS powerful tools for validating models (see also Ger- test) is a much used goodness-of-fit test. -

Exponentiality Test Using a Modified Lilliefors Test Achut Prasad Adhikari
University of Northern Colorado Scholarship & Creative Works @ Digital UNC Dissertations Student Research 5-1-2014 Exponentiality Test Using a Modified Lilliefors Test Achut Prasad Adhikari Follow this and additional works at: http://digscholarship.unco.edu/dissertations Recommended Citation Adhikari, Achut Prasad, "Exponentiality Test Using a Modified Lilliefors Test" (2014). Dissertations. Paper 63. This Text is brought to you for free and open access by the Student Research at Scholarship & Creative Works @ Digital UNC. It has been accepted for inclusion in Dissertations by an authorized administrator of Scholarship & Creative Works @ Digital UNC. For more information, please contact [email protected]. UNIVERSITY OF NORTHERN COLORADO Greeley, Colorado The Graduate School AN EXPONENTIALITY TEST USING A MODIFIED LILLIEFORS TEST A Dissertation Submitted in Partial Fulfillment Of the Requirements for the Degree of Doctor of Philosophy Achut Prasad Adhikari College of Education and Behavioral Sciences Department of Applied Statistics and Research Methods May 2014 ABSTRACT Adhikari, Achut Prasad An Exponentiality Test Using a Modified Lilliefors Test. Published Doctor of Philosophy dissertation, University of Northern Colorado, 2014. A new exponentiality test was developed by modifying the Lilliefors test of exponentiality for the purpose of improving the power of the test it directly modified. Lilliefors has considered the maximum absolute differences between the sample empirical distribution function (EDF) and the exponential cumulative distribution function (CDF). The proposed test considered the sum of all the absolute differences between the CDF and EDF. By considering the sum of all the absolute differences rather than only a point difference of each observation, the proposed test would expect to be less affected by individual extreme (too low or too high) observations and capable of detecting smaller, but consistent, differences between the distributions. -

Power Comparisons of Shapiro-Wilk, Kolmogorov-Smirnov, Lilliefors and Anderson-Darling Tests
Journal ofStatistical Modeling and Analytics Vol.2 No.I, 21-33, 2011 Power comparisons of Shapiro-Wilk, Kolmogorov-Smirnov, Lilliefors and Anderson-Darling tests Nornadiah Mohd Razali1 Yap Bee Wah 1 1Faculty ofComputer and Mathematica/ Sciences, Universiti Teknologi MARA, 40450 Shah Alam, Selangor, Malaysia E-mail: nornadiah@tmsk. uitm. edu.my, yapbeewah@salam. uitm. edu.my ABSTRACT The importance of normal distribution is undeniable since it is an underlying assumption of many statistical procedures such as I-tests, linear regression analysis, discriminant analysis and Analysis of Variance (ANOVA). When the normality assumption is violated, interpretation and inferences may not be reliable or valid. The three common procedures in assessing whether a random sample of independent observations of size n come from a population with a normal distribution are: graphical methods (histograms, boxplots, Q-Q-plots), numerical methods (skewness and kurtosis indices) and formal normality tests. This paper* compares the power offour formal tests of normality: Shapiro-Wilk (SW) test, Kolmogorov-Smirnov (KS) test, Lillie/ors (LF) test and Anderson-Darling (AD) test. Power comparisons of these four tests were obtained via Monte Carlo simulation of sample data generated from alternative distributions that follow symmetric and asymmetric distributions. Ten thousand samples ofvarious sample size were generated from each of the given alternative symmetric and asymmetric distributions. The power of each test was then obtained by comparing the test of normality statistics with the respective critical values. Results show that Shapiro-Wilk test is the most powerful normality test, followed by Anderson-Darling test, Lillie/ors test and Kolmogorov-Smirnov test. However, the power ofall four tests is still low for small sample size. -

Statistical Analysis in JASP V0.10.0- a Students Guide .Pdf
2nd Edition JASP v0.10.0 June 2019 Copyright © 2019 by Mark A Goss-Sampson. All rights reserved. This book or any portion thereof may not be reproduced or used in any manner whatsoever without the express written permission of the author except for the purposes of research, education or private study. CONTENTS PREFACE .................................................................................................................................................. 1 USING THE JASP ENVIRONMENT ............................................................................................................ 2 DATA HANDLING IN JASP ........................................................................................................................ 7 JASP ANALYSIS MENU ........................................................................................................................... 10 DESCRIPTIVE STATISTICS ....................................................................................................................... 12 EXPLORING DATA INTEGRITY ................................................................................................................ 21 DATA TRANSFORMATION ..................................................................................................................... 29 ONE SAMPLE T-TEST ............................................................................................................................. 33 BINOMIAL TEST .................................................................................................................................... -
Univariate Analysis and Normality Test Using SAS, STATA, and SPSS
© 2002-2006 The Trustees of Indiana University Univariate Analysis and Normality Test: 1 Univariate Analysis and Normality Test Using SAS, STATA, and SPSS Hun Myoung Park This document summarizes graphical and numerical methods for univariate analysis and normality test, and illustrates how to test normality using SAS 9.1, STATA 9.2 SE, and SPSS 14.0. 1. Introduction 2. Graphical Methods 3. Numerical Methods 4. Testing Normality Using SAS 5. Testing Normality Using STATA 6. Testing Normality Using SPSS 7. Conclusion 1. Introduction Descriptive statistics provide important information about variables. Mean, median, and mode measure the central tendency of a variable. Measures of dispersion include variance, standard deviation, range, and interquantile range (IQR). Researchers may draw a histogram, a stem-and-leaf plot, or a box plot to see how a variable is distributed. Statistical methods are based on various underlying assumptions. One common assumption is that a random variable is normally distributed. In many statistical analyses, normality is often conveniently assumed without any empirical evidence or test. But normality is critical in many statistical methods. When this assumption is violated, interpretation and inference may not be reliable or valid. Figure 1. Comparing the Standard Normal and a Bimodal Probability Distributions Standard Normal Distribution Bimodal Distribution .4 .4 .3 .3 .2 .2 .1 .1 0 0 -5 -3 -1 1 3 5 -5 -3 -1 1 3 5 T-test and ANOVA (Analysis of Variance) compare group means, assuming variables follow normal probability distributions. Otherwise, these methods do not make much http://www.indiana.edu/~statmath © 2002-2006 The Trustees of Indiana University Univariate Analysis and Normality Test: 2 sense. -

Hypothesis Testing III
Kolmogorov-Smirnov test Mann-Whitney test Normality test Brief summary Quiz Hypothesis testing III Botond Szabo Leiden University Leiden, 16 April 2018 Kolmogorov-Smirnov test Mann-Whitney test Normality test Brief summary Quiz Outline 1 Kolmogorov-Smirnov test 2 Mann-Whitney test 3 Normality test 4 Brief summary 5 Quiz Kolmogorov-Smirnov test Mann-Whitney test Normality test Brief summary Quiz One-sample Kolmogorov-Smirnov test IID observations X1;:::; Xn∼ F : Want to test H0 : F = F0 versus H1 : F 6=F0; where F0 is some fixed CDF. Test statistic p p Tn = nDn = n sup jF^n(x) − F0(x)j x If X1;:::; Xn ∼ F0 and F0 is continuous, then the asymptotic distribution of Tn is independent of F0 and is given by the Kolmogorov distribution. Reject the null hypothesis if Tn > Kα; where Kα is the 1 − α quantile of the Kolmogorov distribution. Kolmogorov-Smirnov test Mann-Whitney test Normality test Brief summary Quiz Kolmogorov-Smirnov test (estimated parameters) IID data X1;:::; Xn ∼ F : Want to test H0 : F 2 F versus H1 : F 2= F; where F = fFθ : θ 2 Θg: Test statistic p p ^ Tn = nDn = n sup jFn(x) − Fθ^(x)j; x where θ^ is an estimate of θ based on Xi 's. Astronomers often proceed by treating θ^ as a constant and use the critical values from the usual Kolmogorov-Smirnov test. Kolmogorov-Smirnov test Mann-Whitney test Normality test Brief summary Quiz Kolmogorov-Smirnov test (continued) This is a faulty practice: asymptotically Tn will typically not have the Kolmogorov distribution. Extra work required to obtain the correct critical values. -
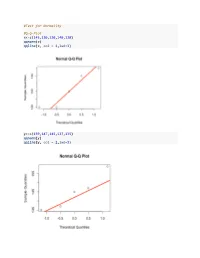
Test for Normality #QQ-Plot X<-C(145130120140120
#Test for Normality #Q-Q-Plot x<-c(145,130,120,140,120) qqnorm(x) qqline(x, col = 2,lwd=3) y<-c(159,147,145,137,135) qqnorm(y) qqline(y, col = 2,lwd=3) #Lilliefors Test #install.packages("nortest") library(nortest) x<-c(145,130,120,140,120) y<-c(159,147,145,137,135) lillie.test(x) ## ## Lilliefors (Kolmogorov-Smirnov) normality test ## ## data: x ## D = 0.23267, p-value = 0.4998 lillie.test(y) ## ## Lilliefors (Kolmogorov-Smirnov) normality test ## ## data: y ## D = 0.20057, p-value = 0.7304 #Mann-Whitney-U Test #MWU Test: unpaired data x<-c(5,5,4,5,3) y<-c(22,14,5,17,30) #exact MWU Test, problem with ties wilcox.test(x,y) ## Warning in wilcox.test.default(x, y): cannot compute exact p-value with ## ties ## ## Wilcoxon rank sum test with continuity correction ## ## data: x and y ## W = 1.5, p-value = 0.02363 ## alternative hypothesis: true location shift is not equal to 0 #asymptotic MWU Test with continuity correction wilcox.test(x,y,exact=FALSE, correct=FALSE) ## ## Wilcoxon rank sum test ## ## data: x and y ## W = 1.5, p-value = 0.01775 ## alternative hypothesis: true location shift is not equal to 0 #asymptotic MWU Test without continuity correction wilcox.test(x,y,exact=FALSE, correct=TRUE) ## ## Wilcoxon rank sum test with continuity correction ## ## data: x and y ## W = 1.5, p-value = 0.02363 ## alternative hypothesis: true location shift is not equal to 0 #Calculating the ranks salve<-c(x,y) group<-c(rep("A",length(x)),rep("B",length(y))) data<-data.frame(salve,group) r1<-sum(rank(data$salve)[data$group=="A"]) r1 ## [1] 16.5 r2<-sum(rank(data$salve)[data$group=="B"]) -

Nonparametric Methods
Chapter 6 Nonparametric Methods CHAPTER VI; SECTION A: INTRODUCTION TO NONPARAMETRIC METHODS Purposes of Nonparametric Methods: Nonparametric methods are uniquely useful for testing nominal (categorical) and ordinal (ordered) scaled data--situations where parametric tests are not generally available. An important second use is when an underlying assumption for a parametric method has been violated. In this case, the interval/ratio scale data can be easily transformed into ordinal scale data and the counterpart nonparametric method can be used. Inferential and Descriptive Statistics: The nonparametric methods described in this chapter are used for both inferential and descriptive statistics. Inferential statistics use data to draw inferences (i.e., derive conclusions) or to make predictions. In this chapter, nonparametric inferential statistical methods are used to draw conclusions about one or more populations from which the data samples have been taken. Descriptive statistics aren’t used to make predictions but to describe the data. This is often best done using graphical methods. Examples: An analyst or engineer might be interested to assess the evidence regarding: 1. The difference between the mean/median accident rates of several marked and unmarked crosswalks (when parametric Student’s t test is invalid because sample distributions are not normal). 2. The differences between the absolute average errors between two types of models for forecasting traffic flow (when analysis of variance is invalid because distribution of errors is not normal). 3. The relationship between the airport site evaluation ordinal rankings of two sets of judges, i.e., citizens and airport professionals. 4. The differences between neighborhood districts in their use of a regional mall for purposes of planning transit routes. -

Power Comparisons of Shapiro-Wilk, Kolmogorov-Smirnov, Lilliefors and Anderson-Darling Tests
Journal of Statistical Modeling and Analytics Vol.2 No.1, 21-33, 2011 Power comparisons of Shapiro-Wilk, Kolmogorov-Smirnov, Lilliefors and Anderson-Darling tests Nornadiah Mohd Razali1 Yap Bee Wah1 1Faculty of Computer and Mathematical Sciences, Universiti Teknologi MARA, 40450 Shah Alam, Selangor, Malaysia E-mail: [email protected], [email protected] ABSTRACT The importance of normal distribution is undeniable since it is an underlying assumption of many statistical procedures such as t-tests, linear regression analysis, discriminant analysis and Analysis of Variance (ANOVA). When the normality assumption is violated, interpretation and inferences may not be reliable or valid. The three common procedures in assessing whether a random sample of independent observations of size n come from a population with a normal distribution are: graphical methods (histograms, boxplots, Q-Q-plots), numerical methods (skewness and kurtosis indices) and formal normality tests. This paper* compares the power of four formal tests of normality: Shapiro-Wilk (SW) test, Kolmogorov-Smirnov (KS) test, Lilliefors (LF) test and Anderson-Darling (AD) test. Power comparisons of these four tests were obtained via Monte Carlo simulation of sample data generated from alternative distributions that follow symmetric and asymmetric distributions. Ten thousand samples of various sample size were generated from each of the given alternative symmetric and asymmetric distributions. The power of each test was then obtained by comparing the test of normality statistics with the respective critical values. Results show that Shapiro-Wilk test is the most powerful normality test, followed by Anderson-Darling test, Lilliefors test and Kolmogorov-Smirnov test. -

One-Way Analysis of Variance
NCSS Statistical Software NCSS.com Chapter 210 One-Way Analysis of Variance Introduction This procedure performs an F-test from a one-way (single-factor) analysis of variance, Welch’s test, the Kruskal- Wallis test, the van der Waerden Normal-Scores test, and the Terry-Hoeffding Normal-Scores test on data contained in either two or more variables or in one variable indexed by a second (grouping) variable. The one- way analysis of variance compares the means of two or more groups to determine if at least one group mean is different from the others. The F-ratio is used to determine statistical significance. The tests are non-directional in that the null hypothesis specifies that all means are equal and the alternative hypothesis simply states that at least one mean is different. This procedure also checks the equal variance (homoscedasticity) assumption using the Levene test, Brown- Forsythe test, Conover test, and Bartlett test. Kinds of Research Questions One of the most common tasks in research is to compare two or more populations (groups). We might want to compare the income level of two regions, the nitrogen content of three lakes, or the effectiveness of four drugs. The first question that arises concerns which aspects (parameters) of the populations we should compare. We might consider comparing the means, medians, standard deviations, distributional shapes (histograms), or maximum values. We base the comparison parameter on our particular problem. One of the simplest comparisons we can make is between the means of two or more populations. If we can show that the mean of one population is different from that of the other populations, we can conclude that the populations are different.