Normality Tests
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-
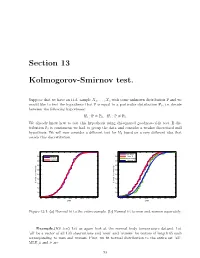
Section 13 Kolmogorov-Smirnov Test
Section 13 Kolmogorov-Smirnov test. Suppose that we have an i.i.d. sample X1; : : : ; Xn with some unknown distribution P and we would like to test the hypothesis that P is equal to a particular distribution P0; i.e. decide between the following hypotheses: H : P = P ; H : P = P : 0 0 1 6 0 We already know how to test this hypothesis using chi-squared goodness-of-fit test. If dis tribution P0 is continuous we had to group the data and consider a weaker discretized null hypothesis. We will now consider a different test for H0 based on a very different idea that avoids this discretization. 1 1 men data 0.9 0.9 'men' fit all data women data 0.8 normal fit 0.8 'women' fit 0.7 0.7 0.6 0.6 0.5 0.5 0.4 0.4 Cumulative probability 0.3 Cumulative probability 0.3 0.2 0.2 0.1 0.1 0 0 96 96.5 97 97.5 98 98.5 99 99.5 100 100.5 96.5 97 97.5 98 98.5 99 99.5 100 100.5 Data Data Figure 13.1: (a) Normal fit to the entire sample. (b) Normal fit to men and women separately. Example.(KS test) Let us again look at the normal body temperature dataset. Let ’all’ be a vector of all 130 observations and ’men’ and ’women’ be vectors of length 65 each corresponding to men and women. First, we fit normal distribution to the entire set ’all’. -

On the Meaning and Use of Kurtosis
Psychological Methods Copyright 1997 by the American Psychological Association, Inc. 1997, Vol. 2, No. 3,292-307 1082-989X/97/$3.00 On the Meaning and Use of Kurtosis Lawrence T. DeCarlo Fordham University For symmetric unimodal distributions, positive kurtosis indicates heavy tails and peakedness relative to the normal distribution, whereas negative kurtosis indicates light tails and flatness. Many textbooks, however, describe or illustrate kurtosis incompletely or incorrectly. In this article, kurtosis is illustrated with well-known distributions, and aspects of its interpretation and misinterpretation are discussed. The role of kurtosis in testing univariate and multivariate normality; as a measure of departures from normality; in issues of robustness, outliers, and bimodality; in generalized tests and estimators, as well as limitations of and alternatives to the kurtosis measure [32, are discussed. It is typically noted in introductory statistics standard deviation. The normal distribution has a kur- courses that distributions can be characterized in tosis of 3, and 132 - 3 is often used so that the refer- terms of central tendency, variability, and shape. With ence normal distribution has a kurtosis of zero (132 - respect to shape, virtually every textbook defines and 3 is sometimes denoted as Y2)- A sample counterpart illustrates skewness. On the other hand, another as- to 132 can be obtained by replacing the population pect of shape, which is kurtosis, is either not discussed moments with the sample moments, which gives or, worse yet, is often described or illustrated incor- rectly. Kurtosis is also frequently not reported in re- ~(X i -- S)4/n search articles, in spite of the fact that virtually every b2 (•(X i - ~')2/n)2' statistical package provides a measure of kurtosis. -

The Probability Lifesaver: Order Statistics and the Median Theorem
The Probability Lifesaver: Order Statistics and the Median Theorem Steven J. Miller December 30, 2015 Contents 1 Order Statistics and the Median Theorem 3 1.1 Definition of the Median 5 1.2 Order Statistics 10 1.3 Examples of Order Statistics 15 1.4 TheSampleDistributionoftheMedian 17 1.5 TechnicalboundsforproofofMedianTheorem 20 1.6 TheMedianofNormalRandomVariables 22 2 • Greetings again! In this supplemental chapter we develop the theory of order statistics in order to prove The Median Theorem. This is a beautiful result in its own, but also extremely important as a substitute for the Central Limit Theorem, and allows us to say non- trivial things when the CLT is unavailable. Chapter 1 Order Statistics and the Median Theorem The Central Limit Theorem is one of the gems of probability. It’s easy to use and its hypotheses are satisfied in a wealth of problems. Many courses build towards a proof of this beautiful and powerful result, as it truly is ‘central’ to the entire subject. Not to detract from the majesty of this wonderful result, however, what happens in those instances where it’s unavailable? For example, one of the key assumptions that must be met is that our random variables need to have finite higher moments, or at the very least a finite variance. What if we were to consider sums of Cauchy random variables? Is there anything we can say? This is not just a question of theoretical interest, of mathematicians generalizing for the sake of generalization. The following example from economics highlights why this chapter is more than just of theoretical interest. -

Theoretical Statistics. Lecture 5. Peter Bartlett
Theoretical Statistics. Lecture 5. Peter Bartlett 1. U-statistics. 1 Outline of today’s lecture We’ll look at U-statistics, a family of estimators that includes many interesting examples. We’ll study their properties: unbiased, lower variance, concentration (via an application of the bounded differences inequality), asymptotic variance, asymptotic distribution. (See Chapter 12 of van der Vaart.) First, we’ll consider the standard unbiased estimate of variance—a special case of a U-statistic. 2 Variance estimates n 1 s2 = (X − X¯ )2 n n − 1 i n Xi=1 n n 1 = (X − X¯ )2 +(X − X¯ )2 2n(n − 1) i n j n Xi=1 Xj=1 n n 1 2 = (X − X¯ ) − (X − X¯ ) 2n(n − 1) i n j n Xi=1 Xj=1 n n 1 1 = (X − X )2 n(n − 1) 2 i j Xi=1 Xj=1 1 1 = (X − X )2 . n 2 i j 2 Xi<j 3 Variance estimates This is unbiased for i.i.d. data: 1 Es2 = E (X − X )2 n 2 1 2 1 = E ((X − EX ) − (X − EX ))2 2 1 1 2 2 1 2 2 = E (X1 − EX1) +(X2 − EX2) 2 2 = E (X1 − EX1) . 4 U-statistics Definition: A U-statistic of order r with kernel h is 1 U = n h(Xi1 ,...,Xir ), r iX⊆[n] where h is symmetric in its arguments. [If h is not symmetric in its arguments, we can also average over permutations.] “U” for “unbiased.” Introduced by Wassily Hoeffding in the 1940s. 5 U-statistics Theorem: [Halmos] θ (parameter, i.e., function defined on a family of distributions) admits an unbiased estimator (ie: for all sufficiently large n, some function of the i.i.d. -

Lecture 14 Testing for Kurtosis
9/8/2016 CHE384, From Data to Decisions: Measurement, Kurtosis Uncertainty, Analysis, and Modeling • For any distribution, the kurtosis (sometimes Lecture 14 called the excess kurtosis) is defined as Testing for Kurtosis 3 (old notation = ) • For a unimodal, symmetric distribution, Chris A. Mack – a positive kurtosis means “heavy tails” and a more Adjunct Associate Professor peaked center compared to a normal distribution – a negative kurtosis means “light tails” and a more spread center compared to a normal distribution http://www.lithoguru.com/scientist/statistics/ © Chris Mack, 2016Data to Decisions 1 © Chris Mack, 2016Data to Decisions 2 Kurtosis Examples One Impact of Excess Kurtosis • For the Student’s t • For a normal distribution, the sample distribution, the variance will have an expected value of s2, excess kurtosis is and a variance of 6 2 4 1 for DF > 4 ( for DF ≤ 4 the kurtosis is infinite) • For a distribution with excess kurtosis • For a uniform 2 1 1 distribution, 1 2 © Chris Mack, 2016Data to Decisions 3 © Chris Mack, 2016Data to Decisions 4 Sample Kurtosis Sample Kurtosis • For a sample of size n, the sample kurtosis is • An unbiased estimator of the sample excess 1 kurtosis is ∑ ̅ 1 3 3 1 6 1 2 3 ∑ ̅ Standard Error: • For large n, the sampling distribution of 1 24 2 1 approaches Normal with mean 0 and variance 2 1 of 24/n 3 5 • For small samples, this estimator is biased D. N. Joanes and C. A. Gill, “Comparing Measures of Sample Skewness and Kurtosis”, The Statistician, 47(1),183–189 (1998). -

Covariances of Two Sample Rank Sum Statistics
JOURNAL OF RESEARCH of the National Bureou of Standards - B. Mathematical Sciences Volume 76B, Nos. 1 and 2, January-June 1972 Covariances of Two Sample Rank Sum Statistics Peter V. Tryon Institute for Basic Standards, National Bureau of Standards, Boulder, Colorado 80302 (November 26, 1971) This note presents an elementary derivation of the covariances of the e(e - 1)/2 two-sample rank sum statistics computed among aU pairs of samples from e populations. Key words: e Sample proble m; covariances, Mann-Whitney-Wilcoxon statistics; rank sum statistics; statistics. Mann-Whitney or Wilcoxon rank sum statistics, computed for some or all of the c(c - 1)/2 pairs of samples from c populations, have been used in testing the null hypothesis of homogeneity of dis tribution against a variety of alternatives [1, 3,4,5).1 This note presents an elementary derivation of the covariances of such statistics under the null hypothesis_ The usual approach to such an analysis is the rank sum viewpoint of the Wilcoxon form of the statistic. Using this approach, Steel [3] presents a lengthy derivation of the covariances. In this note it is shown that thinking in terms of the Mann-Whitney form of the statistic leads to an elementary derivation. For comparison and completeness the rank sum derivation of Kruskal and Wallis [2] is repeated in obtaining the means and variances. Let x{, r= 1,2, ... , ni, i= 1,2, ... , c, be the rth item in the sample of size ni from the ith of c populations. Let Mij be the Mann-Whitney statistic between the ith andjth samples defined by n· n· Mij= ~ t z[J (1) s=1 1' = 1 where l,xJ~>xr Zr~= { I) O,xj";;;x[ } Thus Mij is the number of times items in the jth sample exceed items in the ith sample. -

Analysis of Covariance (ANCOVA) with Two Groups
NCSS Statistical Software NCSS.com Chapter 226 Analysis of Covariance (ANCOVA) with Two Groups Introduction This procedure performs analysis of covariance (ANCOVA) for a grouping variable with 2 groups and one covariate variable. This procedure uses multiple regression techniques to estimate model parameters and compute least squares means. This procedure also provides standard error estimates for least squares means and their differences, and computes the T-test for the difference between group means adjusted for the covariate. The procedure also provides response vs covariate by group scatter plots and residuals for checking model assumptions. This procedure will output results for a simple two-sample equal-variance T-test if no covariate is entered and simple linear regression if no group variable is entered. This allows you to complete the ANCOVA analysis if either the group variable or covariate is determined to be non-significant. For additional options related to the T- test and simple linear regression analyses, we suggest you use the corresponding procedures in NCSS. The group variable in this procedure is restricted to two groups. If you want to perform ANCOVA with a group variable that has three or more groups, use the One-Way Analysis of Covariance (ANCOVA) procedure. This procedure cannot be used to analyze models that include more than one covariate variable or more than one group variable. If the model you want to analyze includes more than one covariate variable and/or more than one group variable, use the General Linear Models (GLM) for Fixed Factors procedure instead. Kinds of Research Questions A large amount of research consists of studying the influence of a set of independent variables on a response (dependent) variable. -

What Is Statistic?
What is Statistic? OPRE 6301 In today’s world. ...we are constantly being bombarded with statistics and statistical information. For example: Customer Surveys Medical News Demographics Political Polls Economic Predictions Marketing Information Sales Forecasts Stock Market Projections Consumer Price Index Sports Statistics How can we make sense out of all this data? How do we differentiate valid from flawed claims? 1 What is Statistics?! “Statistics is a way to get information from data.” Statistics Data Information Data: Facts, especially Information: Knowledge numerical facts, collected communicated concerning together for reference or some particular fact. information. Statistics is a tool for creating an understanding from a set of numbers. Humorous Definitions: The Science of drawing a precise line between an unwar- ranted assumption and a forgone conclusion. The Science of stating precisely what you don’t know. 2 An Example: Stats Anxiety. A business school student is anxious about their statistics course, since they’ve heard the course is difficult. The professor provides last term’s final exam marks to the student. What can be discerned from this list of numbers? Statistics Data Information List of last term’s marks. New information about the statistics class. 95 89 70 E.g. Class average, 65 Proportion of class receiving A’s 78 Most frequent mark, 57 Marks distribution, etc. : 3 Key Statistical Concepts. Population — a population is the group of all items of interest to a statistics practitioner. — frequently very large; sometimes infinite. E.g. All 5 million Florida voters (per Example 12.5). Sample — A sample is a set of data drawn from the population. -

Downloaded 09/24/21 09:09 AM UTC
MARCH 2007 NOTES AND CORRESPONDENCE 1151 NOTES AND CORRESPONDENCE A Cautionary Note on the Use of the Kolmogorov–Smirnov Test for Normality DAG J. STEINSKOG Nansen Environmental and Remote Sensing Center, and Bjerknes Centre for Climate Research, and Geophysical Institute, University of Bergen, Bergen, Norway DAG B. TJØSTHEIM Department of Mathematics, University of Bergen, Bergen, Norway NILS G. KVAMSTØ Geophysical Institute, University of Bergen, and Bjerknes Centre for Climate Research, Bergen, Norway (Manuscript received and in final form 28 April 2006) ABSTRACT The Kolmogorov–Smirnov goodness-of-fit test is used in many applications for testing normality in climate research. This note shows that the test usually leads to systematic and drastic errors. When the mean and the standard deviation are estimated, it is much too conservative in the sense that its p values are strongly biased upward. One may think that this is a small sample problem, but it is not. There is a correction of the Kolmogorov–Smirnov test by Lilliefors, which is in fact sometimes confused with the original Kolmogorov–Smirnov test. Both the Jarque–Bera and the Shapiro–Wilk tests for normality are good alternatives to the Kolmogorov–Smirnov test. A power comparison of eight different tests has been undertaken, favoring the Jarque–Bera and the Shapiro–Wilk tests. The Jarque–Bera and the Kolmogorov– Smirnov tests are also applied to a monthly mean dataset of geopotential height at 500 hPa. The two tests give very different results and illustrate the danger of using the Kolmogorov–Smirnov test. 1. Introduction estimates of skewness and kurtosis. Such moments can be used to diagnose nonlinear processes and to provide The Kolmogorov–Smirnov test (hereafter the KS powerful tools for validating models (see also Ger- test) is a much used goodness-of-fit test. -

Exponentiality Test Using a Modified Lilliefors Test Achut Prasad Adhikari
University of Northern Colorado Scholarship & Creative Works @ Digital UNC Dissertations Student Research 5-1-2014 Exponentiality Test Using a Modified Lilliefors Test Achut Prasad Adhikari Follow this and additional works at: http://digscholarship.unco.edu/dissertations Recommended Citation Adhikari, Achut Prasad, "Exponentiality Test Using a Modified Lilliefors Test" (2014). Dissertations. Paper 63. This Text is brought to you for free and open access by the Student Research at Scholarship & Creative Works @ Digital UNC. It has been accepted for inclusion in Dissertations by an authorized administrator of Scholarship & Creative Works @ Digital UNC. For more information, please contact [email protected]. UNIVERSITY OF NORTHERN COLORADO Greeley, Colorado The Graduate School AN EXPONENTIALITY TEST USING A MODIFIED LILLIEFORS TEST A Dissertation Submitted in Partial Fulfillment Of the Requirements for the Degree of Doctor of Philosophy Achut Prasad Adhikari College of Education and Behavioral Sciences Department of Applied Statistics and Research Methods May 2014 ABSTRACT Adhikari, Achut Prasad An Exponentiality Test Using a Modified Lilliefors Test. Published Doctor of Philosophy dissertation, University of Northern Colorado, 2014. A new exponentiality test was developed by modifying the Lilliefors test of exponentiality for the purpose of improving the power of the test it directly modified. Lilliefors has considered the maximum absolute differences between the sample empirical distribution function (EDF) and the exponential cumulative distribution function (CDF). The proposed test considered the sum of all the absolute differences between the CDF and EDF. By considering the sum of all the absolute differences rather than only a point difference of each observation, the proposed test would expect to be less affected by individual extreme (too low or too high) observations and capable of detecting smaller, but consistent, differences between the distributions. -

Power Comparisons of Shapiro-Wilk, Kolmogorov-Smirnov, Lilliefors and Anderson-Darling Tests
Journal ofStatistical Modeling and Analytics Vol.2 No.I, 21-33, 2011 Power comparisons of Shapiro-Wilk, Kolmogorov-Smirnov, Lilliefors and Anderson-Darling tests Nornadiah Mohd Razali1 Yap Bee Wah 1 1Faculty ofComputer and Mathematica/ Sciences, Universiti Teknologi MARA, 40450 Shah Alam, Selangor, Malaysia E-mail: nornadiah@tmsk. uitm. edu.my, yapbeewah@salam. uitm. edu.my ABSTRACT The importance of normal distribution is undeniable since it is an underlying assumption of many statistical procedures such as I-tests, linear regression analysis, discriminant analysis and Analysis of Variance (ANOVA). When the normality assumption is violated, interpretation and inferences may not be reliable or valid. The three common procedures in assessing whether a random sample of independent observations of size n come from a population with a normal distribution are: graphical methods (histograms, boxplots, Q-Q-plots), numerical methods (skewness and kurtosis indices) and formal normality tests. This paper* compares the power offour formal tests of normality: Shapiro-Wilk (SW) test, Kolmogorov-Smirnov (KS) test, Lillie/ors (LF) test and Anderson-Darling (AD) test. Power comparisons of these four tests were obtained via Monte Carlo simulation of sample data generated from alternative distributions that follow symmetric and asymmetric distributions. Ten thousand samples ofvarious sample size were generated from each of the given alternative symmetric and asymmetric distributions. The power of each test was then obtained by comparing the test of normality statistics with the respective critical values. Results show that Shapiro-Wilk test is the most powerful normality test, followed by Anderson-Darling test, Lillie/ors test and Kolmogorov-Smirnov test. However, the power ofall four tests is still low for small sample size. -

Lecture 8 — October 15 8.1 Bayes Estimators and Average Risk
STATS 300A: Theory of Statistics Fall 2015 Lecture 8 | October 15 Lecturer: Lester Mackey Scribe: Hongseok Namkoong, Phan Minh Nguyen Warning: These notes may contain factual and/or typographic errors. 8.1 Bayes Estimators and Average Risk Optimality 8.1.1 Setting We discuss the average risk optimality of estimators within the framework of Bayesian de- cision problems. As with the general decision problem setting the Bayesian setup considers a model P = fPθ : θ 2 Ωg, for our data X, a loss function L(θ; d), and risk R(θ; δ). In the frequentist approach, the parameter θ was considered to be an unknown deterministic quan- tity. In the Bayesian paradigm, we consider a measure Λ over the parameter space which we call a prior. Assuming this measure defines a probability distribution, we interpret the parameter θ as an outcome of the random variable Θ ∼ Λ. So, in this setup both X and θ are random. Conditioning on Θ = θ, we assume the data is generated by the distribution Pθ. Now, the optimality goal for our decision problem of estimating g(θ) is the minimization of the average risk r(Λ; δ) = E[L(Θ; δ(X))] = E[E[L(Θ; δ(X)) j X]]: An estimator δ which minimizes this average risk is a Bayes estimator and is sometimes referred to as being Bayes. Note that the average risk is an expectation over both the random variables Θ and X. Then by using the tower property, we showed last time that it suffices to find an estimator δ which minimizes the posterior risk E[L(Θ; δ(X))jX = x] for almost every x.