One-Way Analysis of Variance
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Internal Validity Is About Causal Interpretability
Internal Validity is about Causal Interpretability Before we can discuss Internal Validity, we have to discuss different types of Internal Validity variables and review causal RH:s and the evidence needed to support them… Every behavior/measure used in a research study is either a ... Constant -- all the participants in the study have the same value on that behavior/measure or a ... • Measured & Manipulated Variables & Constants Variable -- when at least some of the participants in the study • Causes, Effects, Controls & Confounds have different values on that behavior/measure • Components of Internal Validity • “Creating” initial equivalence and every behavior/measure is either … • “Maintaining” ongoing equivalence Measured -- the value of that behavior/measure is obtained by • Interrelationships between Internal Validity & External Validity observation or self-report of the participant (often called “subject constant/variable”) or it is … Manipulated -- the value of that behavior/measure is controlled, delivered, determined, etc., by the researcher (often called “procedural constant/variable”) So, every behavior/measure in any study is one of four types…. constant variable measured measured (subject) measured (subject) constant variable manipulated manipulated manipulated (procedural) constant (procedural) variable Identify each of the following (as one of the four above, duh!)… • Participants reported practicing between 3 and 10 times • All participants were given the same set of words to memorize • Each participant reported they were a Psyc major • Each participant was given either the “homicide” or the “self- defense” vignette to read From before... Circle the manipulated/causal & underline measured/effect variable in each • Causal RH: -- differences in the amount or kind of one behavior cause/produce/create/change/etc. -

Validity and Reliability of the Questionnaire for Compliance with Standard Precaution for Nurses
View metadata, citation and similar papers at core.ac.uk brought to you by CORE provided by Cadernos Espinosanos (E-Journal) Rev Saúde Pública 2015;49:87 Original Articles DOI:10.1590/S0034-8910.2015049005975 Marília Duarte ValimI Validity and reliability of the Maria Helena Palucci MarzialeII Miyeko HayashidaII Questionnaire for Compliance Fernanda Ludmilla Rossi RochaIII with Standard Precaution Jair Lício Ferreira SantosIV ABSTRACT OBJECTIVE: To evaluate the validity and reliability of the Questionnaire for Compliance with Standard Precaution for nurses. METHODS: This methodological study was conducted with 121 nurses from health care facilities in Sao Paulo’s countryside, who were represented by two high-complexity and by three average-complexity health care facilities. Internal consistency was calculated using Cronbach’s alpha and stability was calculated by the intraclass correlation coefficient, through test-retest. Convergent, discriminant, and known-groups construct validity techniques were conducted. RESULTS: The questionnaire was found to be reliable (Cronbach’s alpha: 0.80; intraclass correlation coefficient: (0.97) In regards to the convergent and discriminant construct validity, strong correlation was found between compliance to standard precautions, the perception of a safe environment, and the smaller perception of obstacles to follow such precautions (r = 0.614 and r = 0.537, respectively). The nurses who were trained on the standard precautions and worked on the health care facilities of higher complexity were shown to comply more (p = 0.028 and p = 0.006, respectively). CONCLUSIONS: The Brazilian version of the Questionnaire for I Departamento de Enfermagem. Centro Compliance with Standard Precaution was shown to be valid and reliable. -
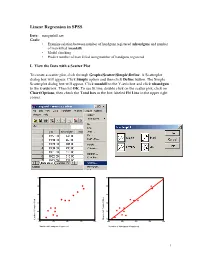
Linear Regression in SPSS
Linear Regression in SPSS Data: mangunkill.sav Goals: • Examine relation between number of handguns registered (nhandgun) and number of man killed (mankill) • Model checking • Predict number of man killed using number of handguns registered I. View the Data with a Scatter Plot To create a scatter plot, click through Graphs\Scatter\Simple\Define. A Scatterplot dialog box will appear. Click Simple option and then click Define button. The Simple Scatterplot dialog box will appear. Click mankill to the Y-axis box and click nhandgun to the x-axis box. Then hit OK. To see fit line, double click on the scatter plot, click on Chart\Options, then check the Total box in the box labeled Fit Line in the upper right corner. 60 60 50 50 40 40 30 30 20 20 10 10 Killed of People Number Number of People Killed 400 500 600 700 800 400 500 600 700 800 Number of Handguns Registered Number of Handguns Registered 1 Click the target button on the left end of the tool bar, the mouse pointer will change shape. Move the target pointer to the data point and click the left mouse button, the case number of the data point will appear on the chart. This will help you to identify the data point in your data sheet. II. Regression Analysis To perform the regression, click on Analyze\Regression\Linear. Place nhandgun in the Dependent box and place mankill in the Independent box. To obtain the 95% confidence interval for the slope, click on the Statistics button at the bottom and then put a check in the box for Confidence Intervals. -

Discussion Notes for Aristotle's Politics
Sean Hannan Classics of Social & Political Thought I Autumn 2014 Discussion Notes for Aristotle’s Politics BOOK I 1. Introducing Aristotle a. Aristotle was born around 384 BCE (in Stagira, far north of Athens but still a ‘Greek’ city) and died around 322 BCE, so he lived into his early sixties. b. That means he was born about fifteen years after the trial and execution of Socrates. He would have been approximately 45 years younger than Plato, under whom he was eventually sent to study at the Academy in Athens. c. Aristotle stayed at the Academy for twenty years, eventually becoming a teacher there himself. When Plato died in 347 BCE, though, the leadership of the school passed on not to Aristotle, but to Plato’s nephew Speusippus. (As in the Republic, the stubborn reality of Plato’s family connections loomed large.) d. After living in Asia Minor from 347-343 BCE, Aristotle was invited by King Philip of Macedon to serve as the tutor for Philip’s son Alexander (yes, the Great). Aristotle taught Alexander for eight years, then returned to Athens in 335 BCE. There he founded his own school, the Lyceum. i. Aside: We should remember that these schools had substantial afterlives, not simply as ideas in texts, but as living sites of intellectual energy and exchange. The Academy lasted from 387 BCE until 83 BCE, then was re-founded as a ‘Neo-Platonic’ school in 410 CE. It was finally closed by Justinian in 529 CE. (Platonic philosophy was still being taught at Athens from 83 BCE through 410 CE, though it was not disseminated through a formalized Academy.) The Lyceum lasted from 334 BCE until 86 BCE, when it was abandoned as the Romans sacked Athens. -

Statistical Analysis 8: Two-Way Analysis of Variance (ANOVA)
Statistical Analysis 8: Two-way analysis of variance (ANOVA) Research question type: Explaining a continuous variable with 2 categorical variables What kind of variables? Continuous (scale/interval/ratio) and 2 independent categorical variables (factors) Common Applications: Comparing means of a single variable at different levels of two conditions (factors) in scientific experiments. Example: The effective life (in hours) of batteries is compared by material type (1, 2 or 3) and operating temperature: Low (-10˚C), Medium (20˚C) or High (45˚C). Twelve batteries are randomly selected from each material type and are then randomly allocated to each temperature level. The resulting life of all 36 batteries is shown below: Table 1: Life (in hours) of batteries by material type and temperature Temperature (˚C) Low (-10˚C) Medium (20˚C) High (45˚C) 1 130, 155, 74, 180 34, 40, 80, 75 20, 70, 82, 58 2 150, 188, 159, 126 136, 122, 106, 115 25, 70, 58, 45 type Material 3 138, 110, 168, 160 174, 120, 150, 139 96, 104, 82, 60 Source: Montgomery (2001) Research question: Is there difference in mean life of the batteries for differing material type and operating temperature levels? In analysis of variance we compare the variability between the groups (how far apart are the means?) to the variability within the groups (how much natural variation is there in our measurements?). This is why it is called analysis of variance, abbreviated to ANOVA. This example has two factors (material type and temperature), each with 3 levels. Hypotheses: The 'null hypothesis' might be: H0: There is no difference in mean battery life for different combinations of material type and temperature level And an 'alternative hypothesis' might be: H1: There is a difference in mean battery life for different combinations of material type and temperature level If the alternative hypothesis is accepted, further analysis is performed to explore where the individual differences are. -

A Pragmatic Stylistic Framework for Text Analysis
International Journal of Education ISSN 1948-5476 2015, Vol. 7, No. 1 A Pragmatic Stylistic Framework for Text Analysis Ibrahim Abushihab1,* 1English Department, Alzaytoonah University of Jordan, Jordan *Correspondence: English Department, Alzaytoonah University of Jordan, Jordan. E-mail: [email protected] Received: September 16, 2014 Accepted: January 16, 2015 Published: January 27, 2015 doi:10.5296/ije.v7i1.7015 URL: http://dx.doi.org/10.5296/ije.v7i1.7015 Abstract The paper focuses on the identification and analysis of a short story according to the principles of pragmatic stylistics and discourse analysis. The focus on text analysis and pragmatic stylistics is essential to text studies, comprehension of the message of a text and conveying the intention of the producer of the text. The paper also presents a set of standards of textuality and criteria from pragmatic stylistics to text analysis. Analyzing a text according to principles of pragmatic stylistics means approaching the text’s meaning and the intention of the producer. Keywords: Discourse analysis, Pragmatic stylistics Textuality, Fictional story and Stylistics 110 www.macrothink.org/ije International Journal of Education ISSN 1948-5476 2015, Vol. 7, No. 1 1. Introduction Discourse Analysis is concerned with the study of the relation between language and its use in context. Harris (1952) was interested in studying the text and its social situation. His paper “Discourse Analysis” was a far cry from the discourse analysis we are studying nowadays. The need for analyzing a text with more comprehensive understanding has given the focus on the emergence of pragmatics. Pragmatics focuses on the communicative use of language conceived as intentional human action. -

Mathematics: Analysis and Approaches First Assessments for SL and HL—2021
International Baccalaureate Diploma Programme Subject Brief Mathematics: analysis and approaches First assessments for SL and HL—2021 The Diploma Programme (DP) is a rigorous pre-university course of study designed for students in the 16 to 19 age range. It is a broad-based two-year course that aims to encourage students to be knowledgeable and inquiring, but also caring and compassionate. There is a strong emphasis on encouraging students to develop intercultural understanding, open-mindedness, and the attitudes necessary for them LOMA PROGRA IP MM to respect and evaluate a range of points of view. B D E I DIES IN LANGUA STU GE ND LITERATURE The course is presented as six academic areas enclosing a central core. Students study A A IN E E N D N DG two modern languages (or a modern language and a classical language), a humanities G E D IV A O L E I W X S ID U IT O T O G E U or social science subject, an experimental science, mathematics and one of the creative IS N N C N K ES TO T I A U CH E D E A A A L F C T L Q O H E S O R I I C P N D arts. Instead of an arts subject, students can choose two subjects from another area. P G E A Y S A E R S It is this comprehensive range of subjects that makes the Diploma Programme a O S E A Y H T demanding course of study designed to prepare students effectively for university entrance. -

Auditor: an R Package for Model-Agnostic Visual Validation and Diagnostics
auditor: an R Package for Model-Agnostic Visual Validation and Diagnostics APREPRINT Alicja Gosiewska Przemysław Biecek Faculty of Mathematics and Information Science Faculty of Mathematics and Information Science Warsaw University of Technology Warsaw University of Technology Poland Faculty of Mathematics, Informatics and Mechanics [email protected] University of Warsaw Poland [email protected] May 27, 2020 ABSTRACT Machine learning models have spread to almost every area of life. They are successfully applied in biology, medicine, finance, physics, and other fields. With modern software it is easy to train even a complex model that fits the training data and results in high accuracy on test set. The problem arises when models fail confronted with the real-world data. This paper describes methodology and tools for model-agnostic audit. Introduced tech- niques facilitate assessing and comparing the goodness of fit and performance of models. In addition, they may be used for analysis of the similarity of residuals and for identification of outliers and influential observations. The examination is carried out by diagnostic scores and visual verification. Presented methods were implemented in the auditor package for R. Due to flexible and con- sistent grammar, it is simple to validate models of any classes. K eywords machine learning, R, diagnostics, visualization, modeling 1 Introduction Predictive modeling is a process that uses mathematical and computational methods to forecast outcomes. arXiv:1809.07763v4 [stat.CO] 26 May 2020 Lots of algorithms in this area have been developed and are still being develop. Therefore, there are countless possible models to choose from and a lot of ways to train a new new complex model. -

5. Dummy-Variable Regression and Analysis of Variance
Sociology 740 John Fox Lecture Notes 5. Dummy-Variable Regression and Analysis of Variance Copyright © 2014 by John Fox Dummy-Variable Regression and Analysis of Variance 1 1. Introduction I One of the limitations of multiple-regression analysis is that it accommo- dates only quantitative explanatory variables. I Dummy-variable regressors can be used to incorporate qualitative explanatory variables into a linear model, substantially expanding the range of application of regression analysis. c 2014 by John Fox Sociology 740 ° Dummy-Variable Regression and Analysis of Variance 2 2. Goals: I To show how dummy regessors can be used to represent the categories of a qualitative explanatory variable in a regression model. I To introduce the concept of interaction between explanatory variables, and to show how interactions can be incorporated into a regression model by forming interaction regressors. I To introduce the principle of marginality, which serves as a guide to constructing and testing terms in complex linear models. I To show how incremental I -testsareemployedtotesttermsindummy regression models. I To show how analysis-of-variance models can be handled using dummy variables. c 2014 by John Fox Sociology 740 ° Dummy-Variable Regression and Analysis of Variance 3 3. A Dichotomous Explanatory Variable I The simplest case: one dichotomous and one quantitative explanatory variable. I Assumptions: Relationships are additive — the partial effect of each explanatory • variable is the same regardless of the specific value at which the other explanatory variable is held constant. The other assumptions of the regression model hold. • I The motivation for including a qualitative explanatory variable is the same as for including an additional quantitative explanatory variable: to account more fully for the response variable, by making the errors • smaller; and to avoid a biased assessment of the impact of an explanatory variable, • as a consequence of omitting another explanatory variables that is relatedtoit. -

Analysis of Variance and Analysis of Variance and Design of Experiments of Experiments-I
Analysis of Variance and Design of Experimentseriments--II MODULE ––IVIV LECTURE - 19 EXPERIMENTAL DESIGNS AND THEIR ANALYSIS Dr. Shalabh Department of Mathematics and Statistics Indian Institute of Technology Kanpur 2 Design of experiment means how to design an experiment in the sense that how the observations or measurements should be obtained to answer a qqyuery inavalid, efficient and economical way. The desigggning of experiment and the analysis of obtained data are inseparable. If the experiment is designed properly keeping in mind the question, then the data generated is valid and proper analysis of data provides the valid statistical inferences. If the experiment is not well designed, the validity of the statistical inferences is questionable and may be invalid. It is important to understand first the basic terminologies used in the experimental design. Experimental unit For conducting an experiment, the experimental material is divided into smaller parts and each part is referred to as experimental unit. The experimental unit is randomly assigned to a treatment. The phrase “randomly assigned” is very important in this definition. Experiment A way of getting an answer to a question which the experimenter wants to know. Treatment Different objects or procedures which are to be compared in an experiment are called treatments. Sampling unit The object that is measured in an experiment is called the sampling unit. This may be different from the experimental unit. 3 Factor A factor is a variable defining a categorization. A factor can be fixed or random in nature. • A factor is termed as fixed factor if all the levels of interest are included in the experiment. -

Statistical Analysis in JASP
Copyright © 2018 by Mark A Goss-Sampson. All rights reserved. This book or any portion thereof may not be reproduced or used in any manner whatsoever without the express written permission of the author except for the purposes of research, education or private study. CONTENTS PREFACE .................................................................................................................................................. 1 USING THE JASP INTERFACE .................................................................................................................... 2 DESCRIPTIVE STATISTICS ......................................................................................................................... 8 EXPLORING DATA INTEGRITY ................................................................................................................ 15 ONE SAMPLE T-TEST ............................................................................................................................. 22 BINOMIAL TEST ..................................................................................................................................... 25 MULTINOMIAL TEST .............................................................................................................................. 28 CHI-SQUARE ‘GOODNESS-OF-FIT’ TEST............................................................................................. 30 MULTINOMIAL AND Χ2 ‘GOODNESS-OF-FIT’ TEST. .......................................................................... -

A Robust Rescaled Moment Test for Normality in Regression
Journal of Mathematics and Statistics 5 (1): 54-62, 2009 ISSN 1549-3644 © 2009 Science Publications A Robust Rescaled Moment Test for Normality in Regression 1Md.Sohel Rana, 1Habshah Midi and 2A.H.M. Rahmatullah Imon 1Laboratory of Applied and Computational Statistics, Institute for Mathematical Research, University Putra Malaysia, 43400 Serdang, Selangor, Malaysia 2Department of Mathematical Sciences, Ball State University, Muncie, IN 47306, USA Abstract: Problem statement: Most of the statistical procedures heavily depend on normality assumption of observations. In regression, we assumed that the random disturbances were normally distributed. Since the disturbances were unobserved, normality tests were done on regression residuals. But it is now evident that normality tests on residuals suffer from superimposed normality and often possess very poor power. Approach: This study showed that normality tests suffer huge set back in the presence of outliers. We proposed a new robust omnibus test based on rescaled moments and coefficients of skewness and kurtosis of residuals that we call robust rescaled moment test. Results: Numerical examples and Monte Carlo simulations showed that this proposed test performs better than the existing tests for normality in the presence of outliers. Conclusion/Recommendation: We recommend using our proposed omnibus test instead of the existing tests for checking the normality of the regression residuals. Key words: Regression residuals, outlier, rescaled moments, skewness, kurtosis, jarque-bera test, robust rescaled moment test INTRODUCTION out that the powers of t and F tests are extremely sensitive to the hypothesized error distribution and may In regression analysis, it is a common practice over deteriorate very rapidly as the error distribution the years to use the Ordinary Least Squares (OLS) becomes long-tailed.