Notes for ECE-320
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Control Systems
ECE 380: Control Systems Course Notes: Winter 2014 Prof. Shreyas Sundaram Department of Electrical and Computer Engineering University of Waterloo ii c Shreyas Sundaram Acknowledgments Parts of these course notes are loosely based on lecture notes by Professors Daniel Liberzon, Sean Meyn, and Mark Spong (University of Illinois), on notes by Professors Daniel Davison and Daniel Miller (University of Waterloo), and on parts of the textbook Feedback Control of Dynamic Systems (5th edition) by Franklin, Powell and Emami-Naeini. I claim credit for all typos and mistakes in the notes. The LATEX template for The Not So Short Introduction to LATEX 2" by T. Oetiker et al. was used to typeset portions of these notes. Shreyas Sundaram University of Waterloo c Shreyas Sundaram iv c Shreyas Sundaram Contents 1 Introduction 1 1.1 Dynamical Systems . .1 1.2 What is Control Theory? . .2 1.3 Outline of the Course . .4 2 Review of Complex Numbers 5 3 Review of Laplace Transforms 9 3.1 The Laplace Transform . .9 3.2 The Inverse Laplace Transform . 13 3.2.1 Partial Fraction Expansion . 13 3.3 The Final Value Theorem . 15 4 Linear Time-Invariant Systems 17 4.1 Linearity, Time-Invariance and Causality . 17 4.2 Transfer Functions . 18 4.2.1 Obtaining the transfer function of a differential equation model . 20 4.3 Frequency Response . 21 5 Bode Plots 25 5.1 Rules for Drawing Bode Plots . 26 5.1.1 Bode Plot for Ko ....................... 27 5.1.2 Bode Plot for sq ....................... 28 s −1 s 5.1.3 Bode Plot for ( p + 1) and ( z + 1) . -

Example Problems and Solutions
EXAMPLE PROBLEMS AND SOLUTIONS A-5-1. In the system of Figure 5-52, x(t) is the input displacement and B(t) is the output angular displacement. Assume that the masses involved are negligibly small and that all motions are restricted to be small; therefore, the system can be considered linear. The initial conditions for x and 0 are zeros, or x(0-) = 0 and H(0-) = 0. Show that this system is a differentiating element. Then obtain the response B(t) when x(t)is a unit-step input. Solution. The equation for the system is b(X - L8) = kLB or The Laplace transform of this last equation, using zero initial conditions, gives And so Thus the system is a differentiating system. For the unit-step input X(s) = l/s,the output O(s)becomes The inverse Laplace transform of O(s)gives Figure 5-52 Mechanical system. Chapter 5 / Transient and Steady-State Response Analyses Figure 5-53 Unit-step input and the response of the mechanical s) stem shown in Figure 5-52. Note that if the value of klb is large the response O(t) approaches a pulse signal as shown in Figure 5-53. A-5-2. Consider the mechanical system shown in Figure 5-54. Suppose that the system is at rest initially [x(o) = 0, i(0) = 01, and at t = 0 it is set into motion by a unit-impulse force. Obtain a mathe- matical model for the system.Then find the motion of the system. Solution. The system is excited by a unit-impulse input. -

Control System Design Methods
Christiansen-Sec.19.qxd 06:08:2004 6:43 PM Page 19.1 The Electronics Engineers' Handbook, 5th Edition McGraw-Hill, Section 19, pp. 19.1-19.30, 2005. SECTION 19 CONTROL SYSTEMS Control is used to modify the behavior of a system so it behaves in a specific desirable way over time. For example, we may want the speed of a car on the highway to remain as close as possible to 60 miles per hour in spite of possible hills or adverse wind; or we may want an aircraft to follow a desired altitude, heading, and velocity profile independent of wind gusts; or we may want the temperature and pressure in a reactor vessel in a chemical process plant to be maintained at desired levels. All these are being accomplished today by control methods and the above are examples of what automatic control systems are designed to do, without human intervention. Control is used whenever quantities such as speed, altitude, temperature, or voltage must be made to behave in some desirable way over time. This section provides an introduction to control system design methods. P.A., Z.G. In This Section: CHAPTER 19.1 CONTROL SYSTEM DESIGN 19.3 INTRODUCTION 19.3 Proportional-Integral-Derivative Control 19.3 The Role of Control Theory 19.4 MATHEMATICAL DESCRIPTIONS 19.4 Linear Differential Equations 19.4 State Variable Descriptions 19.5 Transfer Functions 19.7 Frequency Response 19.9 ANALYSIS OF DYNAMICAL BEHAVIOR 19.10 System Response, Modes and Stability 19.10 Response of First and Second Order Systems 19.11 Transient Response Performance Specifications for a Second Order -

Non-Integer Order Approximation of a PID-Type Controller for Boost Converters
energies Article Non-Integer Order Approximation of a PID-Type Controller for Boost Converters Allan G. S. Sánchez 1,* , Francisco J. Pérez-Pinal 2 , Martín A. Rodríguez-Licea 1 and Cornelio Posadas-Castillo 3 1 CONACYT-Instituto Tecnológico de Celaya, Guanajuato 38010, Mexico; [email protected] 2 Instituto Tecnológico de Celaya, Guanajuato 38010, Mexico; [email protected] 3 Facultad de Ingeniería Mecánica y Eléctrica, Universidad Autónoma de Nuevo León, Nuevo León 66455, Mexico; [email protected] * Correspondence: [email protected] Abstract: In this work, the voltage regulation of a boost converter is addressed. A non-integer order PID controller is proposed to deal with the closed-loop instability of the system. The average linear model of the converter is obtained through small-signal approximation. The resulting average linear model is considered divided into minimum and normalized non-minimum phase parts. This approach allows us to design a controller for the minimum phase part of the system, excluding tem- porarily the non-minimum phase one. A fractional-order PID controller approximation is suggested for the minimum phase part of the system. The proposal for the realization of the electrical controller is described and its implementation is used to corroborate its effectiveness when regulating the output voltage in the boost converter. The fractional-order PID approximation achieves regulation of the output voltage in the boost converter by exhibiting the iso-damping property and using a single Citation: Sánchez, A.G.S.; Pérez-Pinal, F.J.; Rodríguez-Licea, control loop, which confirmed its effectiveness in terms of controlling non-minimum phase/variable M.A.; Posadas-Castillo, C. -
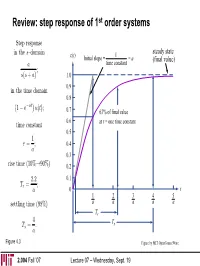
Review: Step Response of 1St Order Systems
Review: step response of 1st order systems Step response in the s—domain c(t) 1 steady state Initial slope = = a (final value) a time constant ; s(s + a) 1.0 0.9 in the time domain 0.8 at 1 − e− u(t); 0.7 63% of final value ¡time constant¢ 0.6 at t = one time constant 0.5 1 τ = ; 0.4 a 0.3 rise time (10%→90%) 0.2 2.2 0.1 Tr = ; a 0 t 1 2 3 4 5 settling time (98%) a a a a a Tr 4 T = . Ts s a Figure 4.3 Figure by MIT OpenCourseWare. 2.004 Fall ’07 Lecture 07 – Wednesday, Sept. 19 Review: poles, zeros, and the forced/natural responses jω jω system pole – input pole – system zero – natural response forced response derivative & amplification σ σ −5 0 −5 −2 0 2.004 Fall ’07 Lecture 07 – Wednesday, Sept. 19 Goals for today • Second-order systems response – types of 2nd-order systems • overdamped • underdamped • undamped • critically damped – transient behavior of overdamped 2nd-order systems – transient behavior of underdamped 2nd-order systems – DC motor with non-negligible impedance • Next lecture (Friday): – examples of modeling & transient calculations for electro-mechanical 2nd order systems 2.004 Fall ’07 Lecture 07 – Wednesday, Sept. 19 DC motor system with non-negligible inductance Recall combined equations of motion LsI(s)+RI(s)+KvΩ(s)=Vs(s) ⇒ JsΩ(s)+bΩ(s)=KmI(s) ) LJ Lb KmKv Km s2 + + J s + b + Ω(s)= V (s) R R R R s ⎧ · µ ¶ µ ¶¸ ⎨⎪ (Js + b) Ω(s)=KmI(s) ⎩⎪ Including the DC motor’s inductance, we find Ω(s) Km 1 = Vs(s) LJ b R bR + KmKv ⎧ s2 + + s + Quadratic polynomial denominator ⎪ J L LJ Second—order system ⎪ µ ¶ µ ¶ ⎪ ⎪ ⎪ b ⎪ s + ⎨ I(s) 1 J = µ ¶ ⎪ Vs(s) R b R bR + K K ⎪ 2 m v ⎪ s + + s + ⎪ J L LJ ⎪ µ ¶ µ ¶ ⎪ ⎩⎪ 2.004 Fall ’07 Lecture 07 – Wednesday, Sept. -

Block Diagrams, Feedback and Transient Response Specifications
Block Diagrams, Feedback and Transient Response Specifications This module introduces the concepts of system block diagrams, feedback control and transient response specifications which are essential concepts for control design and analysis. (This command loads the functions required for computing Laplace and Inverse Laplace transforms. For more information on Laplace transforms, see the Laplace Transforms and Transfer Functions module.) Block Diagrams and Feedback Consider the example of a common household heating system. A household heating system usually consists of a thermostat that measures the room temperature and compares it with an input desired temperature. If the measured temperature is lower than the desired temperature, the thermostat sends a signal that opens the gas valve and starts the combustion in the furnace. The heat from the furnace is then transferred to the rooms of the house which causes the air temperature in the rooms to rise. Once the measured room temperature exceeds the desired temperature by a certain amount, the thermostat turns off the furnace and the cycle repeats. This is an example of a control system and in this case the variable being controlled is the room temperature. This system can be sub-divided into its major parts and represented by the following diagram which shows the directions of information flow. This type of diagram, known as a block diagram, is very useful in understanding how the different components interact and effect the variable of interest. Fig. 1: Block diagram of a household heating system The gas valve, furnace and house can be combined to get one block which can be called the plant of the system. -

Dynamic System Response
Dynamic System Response • Solution of Linear, Constant-Coefficient, Ordinary Differential Equations – Classical Operator Method – Laplace Transform Method • Laplace Transform Properties • 1st-Order Dynamic System Time and Frequency Response • 2nd-Order Dynamic System Time and Frequency Response Sensors & Actuators in Mechatronics K. Craig Dynamic System Response 1 Laplace Transform Methods • A basic mathematical model used in many areas of engineering is the linear ordinary differential equation with constant coefficients: d nq d n-1q dq a o + a o + +a o + a q = n dt n n-1 dt n-1 L 1 dt 0 o d mq d m-1q dq b i + b i + +b i + b q m dt m m-1 dt m-1 L 1 dt 0 i • qo is the output (response) variable of the system • qi is the input (excitation) variable of the system • an and bm are the physical parameters of the system Sensors & Actuators in Mechatronics K. Craig Dynamic System Response 2 • Straightforward analytical solutions are available no matter how high the order n of the equation. • Review of the classical operator method for solving linear differential equations with constant coefficients will be useful. When the input qi(t) is specified, the right hand side of the equation becomes a known function of time, f(t). • The classical operator method of solution is a three-step procedure: – Find the complimentary (homogeneous) solution qoc for the equation with f(t) = 0. – Find the particular solution qop with f(t) present. – Get the complete solution qo = qoc + qop and evaluate the constants of integration by applying known initial conditions. -

Lecture 7 Amplifier Design 1
ECE1371 Advanced Analog Circuits Lecture 7 Amplifier Design 1 Trevor Caldwell [email protected] Lecture Plan Date Lecture (Wednesday 2-4pm) Reference Homework 2020-01-07 1 MOD1 & MOD2 PST 2, 3, A 1: Matlab MOD1&2 2020-01-14 2 MODN + Toolbox PST 4, B 2: Toolbox 2020-01-21 3 SC Circuits R 12, CCJM 14 2020-01-28 4 Comparator & Flash ADC CCJM 10 3: Comparator 2020-02-04 5 Example Design 1 PST 7, CCJM 14 2020-02-11 6 Example Design 2 CCJM 18 4: SC MOD2 2020-02-18 Reading Week / ISSCC 2020-02-25 7 Amplifier Design 1 2020-03-03 8 Amplifier Design 2 2020-03-10 9 Noise in SC Circuits 2020-03-17 10 Nyquist-Rate ADCs CCJM 15, 17 Project 2020-03-24 11 Mismatch & MM-Shaping PST 6 2020-03-31 12 Continuous-Time PST 8 2020-04-07 Exam 2020-04-21 Project Presentation (Project Report Due at start of class) 2 ECE1371 Circuit of the Day: Cascode Current Mirror • How do we bias cascode transistors to optimize signal swing? • Standard cascode current mirror wastes too much swing VX = VEFF + VT VY = 2VEFF + 2VT Minimum VZ is 2VEFF + VT, which is VT larger than necessary 3 ECE1371 What you will learn… • Choice of VEFF Several trade-offs with Noise, Bandwidth, Power,… • Amplifier Topology • Amplifier Settling Dominant Pole, Zero and Non-Dominant Pole • Gain-Boosting Stability, Pole-Zero Doublet • Delaying vs. Non-Delaying stages 4 ECE1371 Choice of Effective Voltage • Effective Voltage VEFF = VGS -VT 2IDD 2I VEFF g C W m nox L Assumes square-law model In weak-inversion, this relationship will not hold • What are the trade-offs when choosing an appropriate effective voltage? Noise Power Bandwidth Matching Linearity Swing 5 ECE1371 Thermal Noise and VEFF • Noise Current and Noise Voltage 2 2 4kT IkTgnm 4 Vn gm • Ex. -

Transfer Function Models of Dynamical Processes
Transfer Function Models of Dynamical Processes Process Dynamics and Control 1 LinearLinear SISOSISO ControlControl SystemsSystems General form of a linear SISO control system: this is a underdetermined higher order differential equation the function must be specified for this ODE to admit a well defined solution 2 TransferTransfer FunctionFunction Heated stirred-tank model (constant flow, ) Taking the Laplace transform yields: or letting Transfer functions 3 TransferTransfer FunctionFunction Heated stirred tank example + + + e.g. The block is called the transfer function relating Q(s) to T(s) 4 ProcessProcess ControlControl Time Domain Laplace Domain Process Modeling, Transfer function Experimentation and Modeling, Controller Implementation Design and Analysis Ability to understand dynamics in Laplace and time domains is extremely important in the study of process control 5 TransferTransfer functionsfunctions Transfer functions are generally expressed as a ratio of polynomials Where The polynomial is called the characteristic polynomial of Roots of are the zeroes of Roots of are the poles of 6 TransferTransfer functionfunction Order of underlying ODE is given by degree of characteristic polynomial e.g. First order processes Second order processes Order of the process is the degree of the characteristic (denominator) polynomial The relative order is the difference between the degree of the denominator polynomial and the degree of the numerator polynomial 7 TransferTransfer FunctionFunction Steady state behavior of the process obtained form the final value theorem e.g. First order process For a unit-step input, From the final value theorem, the ultimate value of is This implies that the limit exists, i.e. that the system is stable. 8 TransferTransfer functionfunction Transfer function is the unit impulse response e.g. -

Time Response of Second Order Systems
Time Response of Second Order Systems d 2 y(t) dy(t) M = f (t) − B − Ky(t) dt2 dt M(s2Y(s) − sy(0) − y'(0)) = F(s) − B(sY(s) − y(0))− KY(s) Let y'(0) = 0 2 Ms Y(s) + BsY(s) + KY(s) = Msy0 + By0 + F(s) Or (Ms+ B)y F(s) Y(s) = 0 + Ms2 + Bs+ K Ms2 + Bs+ K Consider t he first term only: (s + B/ M)y (s + 2ςω )y Y(s) = 0 = n 0 2 2 2 s + (B/ M)s + K / M s + 2ςωns +ωn ς = dimensionl ess damping ratio ωn = the natural frequency Where K B ω = ; ς = n M 2 KM 2 2 The characteristic equation s + 2ςωns +ωn has two roots : 2 s1 = −ςωn + jωn 1−ς 2 s2 = −ςω n − jωn 1−ς If ς >1⇒ roots are real If ς <1⇒ roots are complex (under damped) If ς =1⇒ same roots and real (critically damped) For unit step response : 1 y(t) =1− e−ςωnt sin(βω t +θ ) β n β β = 1−ς 2 , θ = tan −1( ) = cos−1 ς ς 1 −ζω t Step response: y(t) =1− e n sin(ω βt +θ ) β n 2 −1 where β = 1− ζ , θ = cos ζ Showing the step response with different damping coefficients Standard Performance measures Performance measures are usually defined in terms of the step response of a system as below: Swiftness of the response is measured by rise time , and peak time Swiftness of the response is measured by rise time T r , and peak time Tp For underdamped system, the Rise time T r (0-100% rise time) is useful, For overdamped systems, the the Peak time is not defined, and the (10-90 % rise time) is normally used Tr1 Peak time: T p Steady-state error: ess Settling time: T s Percent of Overshoot: M − fv P.O. -

Time Response 4
Time Response 4 Chapter Learning Outcomes After completing this chapter the student will be able to: • Use poles and zeros of transfer functions to determine the time response of a control system (Sections 4.1 –4.2) • Describe quantitatively the transient response of first-order systems (Section 4.3) • Write the general response of second-order systems given the pole location (Section 4.4) • Find the damping ratio and natural frequency of a second-order system (Section 4.5) • Find the settling time, peak time, percent overshoot, and rise time for an underdamped second-order system (Section 4.6) • Approximate higher-order systems and systems with zeros as first- or second- order systems (Sections 4.7 –4.8) • Describe the effects of nonlinearities on the system time response (Section 4.9) • Find the time response from the state-space representation (Sections 4.10 –4.11) Case Study Learning Outcomes You will be able to demonstrate your knowledge of the chapter objectives with case studies as follows: • Given the antenna azimuth position control system shown on the front endpapers, you will be able to (1) predict, by inspection, the form of the open-loop angular velocity response of the load to a step voltage input to 157 158 Chapter 4 Time Response the power ampli fier; (2) describe quantitatively the transient response of the open-loop system; (3) derive the expression for the open-loop angular velocity output for a step voltage input; (4) obtain the open-loop state-space representation; (5) plot the open-loop velocity step response using a computer simulation. -

Lab # 4 Time Response Analysis
Islamic University of Gaza Feedback Control Systems Lab Faculty of Engineering Eng. Tareq Abu Aisha Computer Engineering Dep. Lab # 4 Lab # 4 Time Response Analysis What is the Time Response …? It is an equation or a plot that describes the behavior of a system and contains much information about it with respect to time response specification as overshooting, settling time, peak time, rise time and steady state error. Time response is formed by the transient response and the steady state response. Time response = Transient response + Steady state response Transient time response (Natural response) describes the behavior of the system in its first short time until arrives the steady state value and this response will be our study focus. If the input is step function then the output or the response is called step time response and if the input is ramp, the response is called ramp time response … etc. Delay Time (Td): is the time required for the response to reach 50% of the final value. Rise Time (Tr): is the time required for the response to rise from 0 to 90% of the final value. Settling Time (Ts): is the time required for the response to reach and stay within a specified tolerance band ( 2% or 5%) of its final value. Peak Time (Tp): is the time required for the underdamped step response to reach the peak of time response (Yp) or the peak overshoot. Percent Overshoot (OS%): is the normalized difference between the response peak value and the steady value This characteristic is not found in a first order system and found in higher one for the underdamped step response.