Library of Congress Rule Interpretations, 2008 Update
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Children's Understanding of Compositionality of Complex Numerals
University of Massachusetts Amherst ScholarWorks@UMass Amherst Masters Theses Dissertations and Theses April 2021 Children's Understanding of Compositionality of Complex Numerals Jihyun Hwang University of Massachusetts Amherst Follow this and additional works at: https://scholarworks.umass.edu/masters_theses_2 Part of the Developmental Psychology Commons Recommended Citation Hwang, Jihyun, "Children's Understanding of Compositionality of Complex Numerals" (2021). Masters Theses. 1015. https://doi.org/10.7275/20255220 https://scholarworks.umass.edu/masters_theses_2/1015 This Open Access Thesis is brought to you for free and open access by the Dissertations and Theses at ScholarWorks@UMass Amherst. It has been accepted for inclusion in Masters Theses by an authorized administrator of ScholarWorks@UMass Amherst. For more information, please contact [email protected]. CHILDREN’S UNDERSTANDING OF THE COMPOSITIONALITY OF COMPLEX NUMERALS A Thesis Presented by JIHYUN HWANG Submitted to the Graduate School of the University of Massachusetts Amherst in partial fulfillment of the requirements for the degree of MASTER OF SCIENCE February 2021 Psychology DocuSign Envelope ID: 473F956E-041E-403E-902D-16A2DE83D651 CHILDREN’S UNDERSTANDING OF THE COMPOSITIONALITY OF COMPLEX NUMERALS A Thesis Presented by JIHYUN HWANG Approved as to style and content by: _________________________________________________________________ Joonkoo Park, Chair _________________________________________________________________ Kirby Deater-Deckard, Member _________________________________________________________________ -

A Mathematical Problem How Do We Teach
A MATHEMATICAL PROBLEM: HOW DO WE TEACH MATHEMATICS TO LEP 6/4/09 3:32 PM The Journal of Educational Issues of Language Minority Students, v13 p. 1-12, Spring 1994. A MATHEMATICAL PROBLEM: HOW DO WE TEACH MATHEMATICS TO LEP ELEMENTARY STUDENTS? Jeanne Ramirez Corpus Mather; John J. Chiodo Note: This information was originally published and provided by The Bilingual Education Teacher Preparation Program at Boise State University. Every attempt has been made to maintain the integrity of the printed text. In some cases, figures and tables have been reconstructed within the constraints of the electronic environment. Elementary school teachers are facing a new mathematical problem that is causing great concern: how to teach basic mathematical concepts to the increasing numbers of limited English proficient (LEP) students. With the growing number of LEP students nationally, it is important to evaluate the methods teachers are using to teach these students in general, as well as the particular methods used in the process of teaching mathematics. In attempting to ascertain what particular methods would be effective in mathematics to teach LEP students, the first issue to resolve is, "Does the ability to speak English affect the acquisition of mathematics skills?" Many hold a common belief that the inability to speak English is not so much a barrier as an inconvenience in regard to the learning of mathematics (Kimball, 1990; Kessler, Quinn, & Hayes, 1985). Is this belief substantiated? It seems to depend on the answers to the following two questions: 1. Is rote computation the primary and sufficient element of mathematical literacy? 2. -

Altaic Numerals
102 ALTAIC NUMERALS For Karl H. Menges to his 90th birthday (April 22,1998) The Altaic hypothesis supposes a genetic relationship of Turkic, Mongo lian, Tungus, Korean and Japanese. One of the most frequent arguments of its opponents (Clauson, Scerbak) is based on an imaginary absence of common numerals. The presence of common (= inherited) numerals represents certainly an important argument for a genetic relationship. But its absence has no de claring value — there are more safely related languages without any related numerals. The recent progress in a comparative historical phonology of Altaic languages allows to identify more inherited numerals and to differentiate them from the numerals of substratal or adstratal origin. The most promising set of regular correspondences among Altaic branches and the reconstruction of the Proto-Altaic consonantism was made by Sta- rostin (1986: 104 and 1991: 21) and Vovin (1994: 100): Rule Proto- Proto-Tuikic Common Proto- Middle Proto-Japanese - Altaic Mongolian Tungus Korean 1. V *0-,*-p- V > h-, -b- *P p-.p(h) *P 2. *p *b h-, -r-/-w- *p-. *-b- p-, -w- */>-, -m- 3. *b *b b-,-y- *b-, *-w- P *p/*b(-m-/-r-) 4. *-w- *-b-/*-0- -b-l-y- *-w/*-y-•0- / *-0- 5. *m *b-, *m m *m m *m/*-0 6. +t *t t. m *t. V;'- t-. t(h) *t 7. *t *d-, *-t- d.Sd) *d; *Sl-.- t-, -r- *t/*d t- 8. *d *d- d,S(0 *d. *Si- t-, -r- *t/*d, -y-l-0 9. *n *-n- n *n n *n/*-0 10. *-rr *-r- -r- *-r- -r- *-t-/*-r-/*-0 11. -

Korean Classifier-Less Number Constructions1
Korean classifier-less number constructions1 Dorothy AHN — Harvard University Abstract. Korean is a generalized classifier language where classifiers are required for numer- als to combine with nominals. This paper presents a number construction where the classifier is absent and the numeral appears prenominally. This construction, which I call the classifier-less number construction (Cl-less NC), results in a definite or a partitive reading where the refer- ent must be familiar: ‘the two women’ or ‘two of the women’. In order to account for this, I argue that Korean postnominal number constructions are ambiguous between a plain number construction and a partitive construction. After motivating and proposing an analysis for the partitive structure, I argue that Cl-less NC is derived from the partitive construction, explaining its distributional restriction and the interpretation. Keywords: number construction, classifiers, partitives, Korean. 1. Introduction Korean is a generalized classifier language where classifiers are required for numerals to com- bine with nominals. However, the language allows a construction where the classifier is absent and the numeral appears prenominally in some contexts, as shown in (1). Unlike the regu- lar number construction shown in (2), (1) results in a definite or a partitive reading where the referent of women is familiar. I call the classifier-less number construction (Cl-less NC). The existence of such construction has been noted before in the literature, but it was assumed to be a special case of direct combination of a small class of human or body-part denoting nouns with numerals (cf. Choi, 2005; Shin, 2017). That this construction results in a different meaning from the regular number construction is a new observation that, as far as the author knows, has not been discussed in the literature. -

An Analysis of Linguistic Features of the Multiplication Tables and the Language of Multiplication
EURASIA Journal of Mathematics, Science and Technology Education, 2018, 14(7), 2839-2856 ISSN:1305-8223 (online) 1305-8215 (print) OPEN ACCESS Research Paper https://doi.org/10.29333/ejmste/90760 An Analysis of Linguistic Features of the Multiplication Tables and the Language of Multiplication Emily Sum 1*, Oh Nam Kwon 1 1 Seoul National University, Seoul, SOUTH KOREA Received 8 January 2018 ▪ Revised 26 March 2018 ▪ Accepted 18 April 2018 ABSTRACT This study analyses the linguistic features of Korean language in learning multiplication. Ancient Korean multiplication tables, Gugudan, as well as mathematics textbooks and teacher’s guides from South Korea were examined for the instruction of multiplication in second grade. Our findings highlight the uniqueness of the grammatical features of numbers, the syntax of multiplication tables, the simplicity of language of multiplication in Korean language, and also the complexities and ambiguities in English language. We believe that, by examining the specific language of a topic, we will help to identify how language and culture tools shape the understanding of students’ mathematical development. Although this study is based on Korean context, the method and findings will shed light on other East Asian languages, and will add value to the research on international comparative studies. Keywords: cultural artefacts, Korean language, linguistic features, multiplication tables INTRODUCTION Hong Kong, Japan, South Korea and Singapore have maintained their lead in international league tables of mathematics achievement such as TIMSS and PISA. Numerous comparative studies have been undertaken in search of the best East Asian practices and factors that have contributed to high student achievement; researchers have argued that one of the major factors behind the superior performance in cross-national studies is based on the underlying culture (e.g. -

Development of Number System
Prof. Musheer Ahmad Department of Applied Sciences & Humanities Faculty of Engineering & Technology Jamia Millia Islamia, New Delhi DIFFERENT TYPES OF NUMERALS Name: Sample: Approx. first appearance: Babylonian numerals 3100 BC Chinese numerals, Japanese Unknown numerals, Korean numerals Hindu-Arabic Numerals 1st century Roman numerals 1000 BC Greek numerals After 100 BC Chinese rod numerals 1st century NUMBER SYSTEM A number system is a writing system for expressing numbers, that is, a mathematical notation for representing numbers of a given set, using digits or other symbols in a consistent manner. The number system we have today, commonly called Hindu-Arabic Numerals. It came about because human beings wanted to solve problems and mainly, wanted to know the quantity of a particular thing. So they started creating numbers to solve these problems. In olden days, The counting numbers satisfied people for a long time. For example: Counting through fingers NATURAL NUMBER The natural numbers are the ordinary numbers, 1, 2, 3,. with which humans count. Sometimes they are called the counting numbers. Natural numbers have been called natural because much of human experience from infancy deals with discrete objects such as fingers, balls, peanuts, etc. People quickly, if not naturally, learn to count them. The natural numbers are presumed to have started before recorded history when humans began to count things. The Babylonians developed a place-value system based on the numerals for 1 (one) and 10 (ten). The ancient Egyptians added to this system to include all the powers of 10 up to one million. Natural numbers were first studied seriously by such Greek philosophers and mathematicians as Pythagoras (582–500 BC) and Archimedes (287–212 BC). -

An Analysis on Numeral Words in Mongolian and Korean Languages
Social Sciences 2018; 7(6): 274-278 http://www.sciencepublishinggroup.com/j/ss doi: 10.11648/j.ss.20180706.15 ISSN: 2326-9863 (Print); ISSN: 2326-988X (Online) An Analysis on Numeral Words in Mongolian and Korean Languages Dao Runa School of Mongolian Studies, Inner Mongolia University, Hohhot, China Email address: To cite this article: Dao Runa. An Analysis on Numeral Words in Mongolian and Korean Languages. Social Sciences . Vol. 7, No. 6, 2018, pp. 274-278. doi: 10.11648/j.ss.20180706.15 Received : October 15, 2018; Accepted : November 7, 2018; Published : December 5, 2018 Abstract: This article mainly conducts a comparative study of numeral forms in Mongolian and Korean through the observation of the numeral forms in mediaeval Mongolian literature, such as The Secret History of the Mongols and mediaeval Korean literature. The aim is to explore the homology between Mongolian and Korean numerals. Altaic numerals do not have an obvious phonetic correspondence as indo-European numerals do. Due to the nature of the numeral itself, a comparative study of numerals is not like a comparative study of grammatical elements. Strictly speaking, the comparative study of numerals belongs to the lexical category. In the whole numeral system, it is equally important to analyze the nature of a single numeral and observe other numerals in two languages. The character of a single numeral refers to the combination of root and affix, while the relation between numeral and numeral refers to the relation between one digits numeral word and the corresponding ten digits numeral word. Based on this point of view, the paper mainly analyzes the properties of the numeral itself and attempts to construct the root form of the numerals by combining the observation of the same root words. -

A Brief History of Western Knowledge About the Korean Language and Script— from the Beginnings to Pallas (1786/87–89)
A Brief History of Western Knowledge about the Korean Language and Script— from the Beginnings to Pallas (1786/87–89) Sven Osterkamp The aim of the present article is to outline Western knowledge and studies pertaining to the Korean language and script from its vague beginnings in the late 16th century to the monumental linguistic works of the 1780s. The latter date will appear somewhat arbitrary, and it certainly is to some extent. It can, if at all, only be justified by the circumstances out of which this study developed. Originally intended to be little more than a prolegomenon to the investigation of Philipp Franz von Siebold’s (1796–1866) contribution to the study of Korean in the West,1 with the modest aim of situating his work in an appropriate manner, it soon became apparent that the subject matter at hand presented a field of study in its own right—and one undoubtedly still in need of plowing. As work on the topic progressed, the list of sources to be covered and problems to be solved grew ever longer, resulting in a split of the period into the one treated herein, and another one from the last decade of the 18th century to the 1830s. The latter period will be treated separately on another occasion and is therefore merely outlined in rough strokes towards the end of this contribution. Among the prior studies in this field, the pioneering efforts by Ogura Shinpei 小倉 進平 (1882–1944) in the 1920s are the first that have to be mentioned.2 Despite the 1 For some preliminary results see the present author’s »Selected Materials on Korean from the Siebold Archive in Bochum—Preceded by Some General Remarks Regarding Siebold’s Study of Korean«, Bochumer Jahrbuch zur Ostasienforschung 33 (2009), 187–216. -
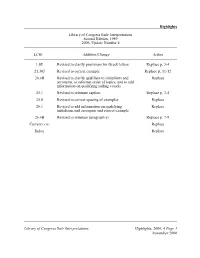
Library of Congress Rule Interpretations, 2006 Update 4
Highlights Library of Congress Rule Interpretations Second Edition, 1989 2006, Update Number 4 LCRI Addition/Change Action 1.0E Revised to clarify provisions for Greek letters Replace p. 3-4 21.30J Revised to correct example Replace p. 11-12 24.4B Revised to clarify qualifiers to initialisms and Replace acronyms, to reformat order of topics, and to add information on qualifying sailing vessels 25.1 Revised to reinstate caption Replace p. 3-4 25.8 Revised to correct spacing of examples Replace 26.1 Revised to add information on qualifying Replace initialisms and acronyms and correct example 26.4B Revised to reinstate paragraph e) Replace p. 7-8 Current LCRI Replace Index Replace Library of Congress Rule Interpretations Highlights, 2006, 4 Page 1 November 2006 Highlights LCRI Addition/Change Action THIS PAGE INTENTIONALLY LEFT BLANK Page 2 Highlights, 2006, 4 Library of Congress Rule Interpretations November 2006 1.0E chief source: Separation of 59FeIII and 59FeII in neutron ... transcription: 245 10 $a Separation of 59FeIII and 59FeII in neutron ... suggested note: 500 ## $a On t.p. "III" and "II" are superscript chief source: Estimating Lx(1) transcription: 245 10 $a Estimating Lx(1) suggested note: 500 ## $a On t.p. "x" is subscript chief source: ENDOR hyperfine constants of Vk-type centers transcription: 245 10 $a ENDOR hyperfine constants of Vk- type centers suggested note: 500 ## $a On t.p. "k" is subscript chief source: The structure of 1f 7/2 nuclei transcription: 245 14 $a The structure of 1f 7/2 nuclei suggested note: 500 ## $a On t.p. -

Constructing Calendar and Time Expression Local Grammar Graph
DESCRIPTIVE STUDY OF INDONESIAN AND KOREAN TIME EXPRESSION WITH LGGs Prihantoro*, Sébastien Paumier ** *DICORA, Hankuk University of Foreign Studies, Korea/ ** IGM, University of Paris-Est, France [email protected], [email protected] Abstract This paper aims at considering some problems encountered when we translate time expressions between Korean and Indonesian. We consider in this paper the time expressions corresponding to the questions of type what time or when, rather than those related to the questions of type how long or how often. Especially the time expressions referring to calendar, day and clock time in Indonesian and Korean are considered in this study. Our discussion underlines four different aspects in translating the time expressions between these two languages: word order, numeral system, abbreviation, and time segmentation. The LGG(Local Grammar Graph) model will be used in the description of these aspects. The result of our study can be used as a linguistic resource not only for the learning system of Indonesian and Korean, but also for the machine translation system between these two languages. 1. Introduction Indonesian is the official language of Indonesia and was politically created in October 28th 1928, as an effort of unifying Indonesian people, who was colonialized by Netherlands. At that time, Indonesian communicated mostly in their first language only. Indonesian is the development of Malay used in Riau (Sneddon, 2004:14), in order to fulfill the plural characteristic of around 250 million Indonesian people. In other hand, Korean is the official language of Korea, both South and North. There are about 78 million Korean speakers. -

Ki-Moon Lee, S. Robert Ramsey, a History of the Korean Language
This page intentionally left blank A History of the Korean Language A History of the Korean Language is the first book on the subject ever published in English. It traces the origin, formation, and various historical stages through which the language has passed, from Old Korean through to the present day. Each chapter begins with an account of the historical and cultural background. A comprehensive list of the literature of each period is then provided and the textual record described, along with the script or scripts used to write it. Finally, each stage of the language is analyzed, offering new details supplementing what is known about its phonology, morphology, syntax, and lexicon. The extraordinary alphabetic materials of the fifteenth and sixteenth centuries are given special attention, and are used to shed light on earlier, pre-alphabetic periods. ki-moon lee is Professor Emeritus at Seoul National University. s. robert ramsey is Professor and Chair in the Department of East Asian Languages and Cultures at the University of Maryland, College Park. Frontispiece: Korea’s seminal alphabetic work, the Hunmin cho˘ngu˘m “The Correct Sounds for the Instruction of the People” of 1446 A History of the Korean Language Ki-Moon Lee S. Robert Ramsey CAMBRIDGE UNIVERSITY PRESS Cambridge, New York, Melbourne, Madrid, Cape Town, Singapore, Sa˜o Paulo, Delhi, Dubai, Tokyo, Mexico City Cambridge University Press The Edinburgh Building, Cambridge CB2 8RU, UK Published in the United States of America by Cambridge University Press, New York www.cambridge.org Information on this title: www.cambridge.org/9780521661898 # Cambridge University Press 2011 This publication is in copyright. -

Eastern Arabic Numerals - Wikipedia
Eastern Arabic numerals - Wikipedia https://en.wikipedia.org/wiki/Eastern_Arabic_numerals Eastern Arabic numerals e Eastern Arabic numerals (also called Arabic–Hindu numerals , Arabic Eastern numerals and Indo-Persian numerals ) are the symbols used to represent the Hindu–Arabic numeral system, in conjunction with the Arabic alphabet in the countries of the Mashriq (the east of the Arab world), the Arabian Peninsula, and its ariant in other countries that use the Perso-Arabic script in the Iranian plateau and Asia. Eastern Arabic numerals on a clock Contents in the Cairo Metro. Origin Other names Numerals Usage Contemporary use Notes References Origin e numeral system originates from an ancient Indian numeral system, which was re-introduced in the book On the Calculation with Hindu Numerals wri&en by Clocks in the Ottoman Empire tended to use Eastern Arabic the medie al-era Iranian mathematician and engineer Khwara(mi,[1] whose name numerals. was Latini(ed as Algoritmi .[note 1] Other names Indian numbers") in Arabic. ey are sometimes also called "Indic numerals" in") ﺃﺭﻗﺎﻡ ﻫﻨﺪﻳﺔ ese numbers are known as English. [2] Howe er, that is sometimes discouraged as it can lead to confusion with Indian numerals, used in ,rahmic scripts of India.[3] Numerals Each numeral in the Persian ariant has a di-erent .nicode point e en if it looks identical to the Eastern Arabic numeral counterpart. Howe er the ariants used with .rdu, Sindhi, and other South Asian languages are not encoded separately from the Persian ariants. See .01221 through .01223 and .01241 through .01243. 1 of 3 6/13/2018, 9:46 PM Eastern Arabic numerals - Wikipedia https://en.wikipedia.org/wiki/Eastern_Arabic_numerals Hindu-Arabic numerals 0 1 2 3 4 5 6 7 8 9 ٩ ٨ ٧ ٦ ٥ ٤ ٣ ٢ ١ ٠ Eastern Arabic Perso-Arabic variant ۰ ۱ ۲ ۳ ۴ ۵ ۶ ۷ ۸ ۹ Urdu variant Usage 5ri&en numerals are arranged with their lowest- alue digit to the right, with higher alue positions added to the le6.