STATISTICAL GRAPHICS and EXPERIMENTAL DATA E. Nikolić
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-
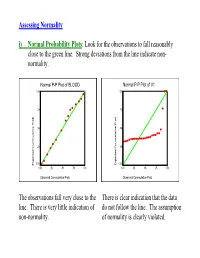
Assessing Normality I) Normal Probability Plots : Look for The
Assessing Normality i) Normal Probability Plots: Look for the observations to fall reasonably close to the green line. Strong deviations from the line indicate non- normality. Normal P-P Plot of BLOOD Normal P-P Plot of V1 1.00 1.00 .75 .75 .50 .50 .25 .25 0.00 0.00 Expected Cummulative Prob Expected Cummulative Expected Cummulative Prob Expected Cummulative 0.00 .25 .50 .75 1.00 0.00 .25 .50 .75 1.00 Observed Cummulative Prob Observed Cummulative Prob The observations fall very close to the There is clear indication that the data line. There is very little indication of do not follow the line. The assumption non-normality. of normality is clearly violated. ii) Histogram: Look for a “bell-shape”. Severe skewness and/or outliers are indications of non-normality. 5 16 14 4 12 10 3 8 2 6 4 1 Std. Dev = 60.29 Std. Dev = 992.11 2 Mean = 274.3 Mean = 573.1 0 N = 20.00 0 N = 25.00 150.0 200.0 250.0 300.0 350.0 0.0 1000.0 2000.0 3000.0 4000.0 175.0 225.0 275.0 325.0 375.0 500.0 1500.0 2500.0 3500.0 4500.0 BLOOD V1 Although the histogram is not perfectly There is a clear indication that the data symmetric and bell-shaped, there is no are right-skewed with some strong clear violation of normality. outliers. The assumption of normality is clearly violated. Caution: Histograms are not useful for small sample sizes as it is difficult to get a clear picture of the distribution. -

Fundamental Statistical Concepts in Presenting Data Principles For
Fundamental Statistical Concepts in Presenting Data Principles for Constructing Better Graphics Rafe M. J. Donahue, Ph.D. Director of Statistics Biomimetic Therapeutics, Inc. Franklin, TN Adjunct Associate Professor Vanderbilt University Medical Center Department of Biostatistics Nashville, TN Version 2.11 July 2011 2 FUNDAMENTAL STATI S TIC S CONCEPT S IN PRE S ENTING DATA This text was developed as the course notes for the course Fundamental Statistical Concepts in Presenting Data; Principles for Constructing Better Graphics, as presented by Rafe Donahue at the Joint Statistical Meetings (JSM) in Denver, Colorado in August 2008 and for a follow-up course as part of the American Statistical Association’s LearnStat program in April 2009. It was also used as the course notes for the same course at the JSM in Vancouver, British Columbia in August 2010 and will be used for the JSM course in Miami in July 2011. This document was prepared in color in Portable Document Format (pdf) with page sizes of 8.5in by 11in, in a deliberate spread format. As such, there are “left” pages and “right” pages. Odd pages are on the right; even pages are on the left. Some elements of certain figures span opposing pages of a spread. Therefore, when printing, as printers have difficulty printing to the physical edge of the page, care must be taken to ensure that all the content makes it onto the printed page. The easiest way to do this, outside of taking this to a printing house and having them print on larger sheets and trim down to 8.5-by-11, is to print using the “Fit to Printable Area” option under Page Scaling, when printing from Adobe Acrobat. -

Interactive Statistical Graphics/ When Charts Come to Life
Titel Event, Date Author Affiliation Interactive Statistical Graphics When Charts come to Life [email protected] www.theusRus.de Telefónica Germany Interactive Statistical Graphics – When Charts come to Life PSI Graphics One Day Meeting Martin Theus 2 www.theusRus.de What I do not talk about … Interactive Statistical Graphics – When Charts come to Life PSI Graphics One Day Meeting Martin Theus 3 www.theusRus.de … still not what I mean. Interactive Statistical Graphics – When Charts come to Life PSI Graphics One Day Meeting Martin Theus 4 www.theusRus.de Interactive Graphics ≠ Dynamic Graphics • Interactive Graphics … uses various interactions with the plots to change selections and parameters quickly. Interactive Statistical Graphics – When Charts come to Life PSI Graphics One Day Meeting Martin Theus 4 www.theusRus.de Interactive Graphics ≠ Dynamic Graphics • Interactive Graphics … uses various interactions with the plots to change selections and parameters quickly. • Dynamic Graphics … uses animated / rotating plots to visualize high dimensional (continuous) data. Interactive Statistical Graphics – When Charts come to Life PSI Graphics One Day Meeting Martin Theus 4 www.theusRus.de Interactive Graphics ≠ Dynamic Graphics • Interactive Graphics … uses various interactions with the plots to change selections and parameters quickly. • Dynamic Graphics … uses animated / rotating plots to visualize high dimensional (continuous) data. 1973 PRIM-9 Tukey et al. Interactive Statistical Graphics – When Charts come to Life PSI Graphics One Day Meeting Martin Theus 4 www.theusRus.de Interactive Graphics ≠ Dynamic Graphics • Interactive Graphics … uses various interactions with the plots to change selections and parameters quickly. • Dynamic Graphics … uses animated / rotating plots to visualize high dimensional (continuous) data. -

Infovis and Statistical Graphics: Different Goals, Different Looks1
Infovis and Statistical Graphics: Different Goals, Different Looks1 Andrew Gelman2 and Antony Unwin3 20 Jan 2012 Abstract. The importance of graphical displays in statistical practice has been recognized sporadically in the statistical literature over the past century, with wider awareness following Tukey’s Exploratory Data Analysis (1977) and Tufte’s books in the succeeding decades. But statistical graphics still occupies an awkward in-between position: Within statistics, exploratory and graphical methods represent a minor subfield and are not well- integrated with larger themes of modeling and inference. Outside of statistics, infographics (also called information visualization or Infovis) is huge, but their purveyors and enthusiasts appear largely to be uninterested in statistical principles. We present here a set of goals for graphical displays discussed primarily from the statistical point of view and discuss some inherent contradictions in these goals that may be impeding communication between the fields of statistics and Infovis. One of our constructive suggestions, to Infovis practitioners and statisticians alike, is to try not to cram into a single graph what can be better displayed in two or more. We recognize that we offer only one perspective and intend this article to be a starting point for a wide-ranging discussion among graphics designers, statisticians, and users of statistical methods. The purpose of this article is not to criticize but to explore the different goals that lead researchers in different fields to value different aspects of data visualization. Recent decades have seen huge progress in statistical modeling and computing, with statisticians in friendly competition with researchers in applied fields such as psychometrics, econometrics, and more recently machine learning and “data science.” But the field of statistical graphics has suffered relative neglect. -

Principles of Graph Construction
PRINCIPLES OF GRAPH CONSTRUCTION Frank E Harrell Jr Department of Biostatistics Vanderbilt University School of Medicine [email protected] biostat.mc.vanderbilt.edu at Jump: StatGraphCourse Office of Biostatistics, FDA CDER [email protected] Blog: fharrell.com Twitter: @f2harrell DIA/FDA STATISTICS FORUM NORTH BETHESDA MD 2017-04-24 Copyright 2000-2017 FE Harrell All Rights Reserved Chapter 1 Principles of Graph Construction The ability to construct clear and informative graphs is related to the ability to understand the data. There are many excellent texts on statistical graphics (many of which are listed at the end of this chapter). Some of the best are Cleveland’s 1994 book The Elements of Graphing Data and the books by Tufte. The sugges- tions for making good statistical graphics outlined here are heavily influenced by Cleveland’s 1994 book. See also the excellent special issue of Journal of Computa- tional and Graphical Statistics vol. 22, March 2013. 2 CHAPTER 1. PRINCIPLES OF GRAPH CONSTRUCTION 3 1.1 Graphical Perception • Goals in communicating information: reader percep- tion of data values and of data patterns. Both accu- racy and speed are important. • Pattern perception is done by detection : recognition of geometry encoding physi- cal values assembly : grouping of detected symbol elements; discerning overall patterns in data estimation : assessment of relative magnitudes of two physical values • For estimation, many graphics involve discrimination, ranking, and estimation of ratios • Humans are not good at estimating differences with- out directly seeing differences (especially for steep curves) • Humans do not naturally order color hues • Only a limited number of hues can be discriminated in one graphic • Weber’s law: The probability of a human detecting a difference in two lines is related to the ratio of the two line lengths CHAPTER 1. -

Boxplots for Grouped and Clustered Data in Toxicology
Penultimate version. If citing, please refer instead to the published version in Archives of Toxicology, DOI: 10.1007/s00204-015-1608-4. Boxplots for grouped and clustered data in toxicology Philip Pallmann1, Ludwig A. Hothorn2 1 Department of Mathematics and Statistics, Lancaster University, Lancaster LA1 4YF, UK, Tel.: +44 (0)1524 592318, [email protected] 2 Institute of Biostatistics, Leibniz University Hannover, 30419 Hannover, Germany Abstract The vast majority of toxicological papers summarize experimental data as bar charts of means with error bars. While these graphics are easy to generate, they often obscure essen- tial features of the data, such as outliers or subgroups of individuals reacting differently to a treatment. Especially raw values are of prime importance in toxicology, therefore we argue they should not be hidden in messy supplementary tables but rather unveiled in neat graphics in the results section. We propose jittered boxplots as a very compact yet comprehensive and intuitively accessible way of visualizing grouped and clustered data from toxicological studies together with individual raw values and indications of statistical significance. A web application to create these plots is available online. Graphics, statistics, R software, body weight, micronucleus assay 1 Introduction Preparing a graphical summary is usually the first if not the most important step in a data analysis procedure, and it can be challenging especially with many-faceted datasets as they occur frequently in toxicological studies. However, even in simple experimental setups many researchers have a hard time presenting their results in a suitable manner. Browsing recent volumes of this journal, we have realized that the least favorable ways of displaying toxicological data appear to be the most popular ones (according to the number of publications that use them). -

Statistical Concepts in Metrology — with a Postscript on Statistical Graphics
NBS Special Publication 747 Statistical Concepts in Metrology — With a Postscript on Statistical Graphics Harry H, Ku NBS NBS NBS NBS NBS NBS NBS NBS NBS NBS iS NBS NBS NBS NBS NBS NBS NBS NBS NBS Nl NBS NBS NBS NBS NBS NBS NBS NBS NBS NBS tS NBS NBS NBS NBS NBS NBS NBS NBS NBS Nl NBS NBS NBS NBS NBS NBS NBS NBS NBS NBS iS NBS NBS NBS NBS NBS NBS NBS NBS NBS NlJ. NBS NBS NBS NBS NBS NBS NBS NBS NBS NBS iS NBS NBS NBS NBS NBS NBS NBS NBS NBS NlJ. NBS NBS NBS NBS NBS NBS NBS NBS NBS NBS tS NBS NBS NBS NBS NBS NBS NBS NBS NBS Nl NBS NBS NBS National Bureau ofStandards NBS NBS tS NBS NBS NBS NBS NBS NBS NBS NBS NBS Nl NBS NBS NBS NBS NBS NBS NBS NBS NBS NBS ^^mS NBS NBS NBS NBS NBS NBS NBS NBS Nl ^^NBS NBS NBS NBS NBS NBS NBS NBS NBS l^mS NBS NBS NBS NBS NBS NBS NBS NBS Nl m he National Bureau of Standards' was established by an act of Congress on March 3, 1901. The m Bureau's overall goal is to strengthen and advance the Nation's science and technology and facilitate their effective application for public benefit. To this end, the Bureau conducts research to assure international competi- tiveness and leadership of U.S. industry, science and technology. NBS work involves development and transfer of measurements, standards and related science and technology, in support of continually improving U.S. -

Length of Stay Outlier Detection Through Cluster Analysis: a Case Study in Pediatrics Daniel Gartnera, Rema Padmanb
Length of Stay Outlier Detection through Cluster Analysis: A Case Study in Pediatrics Daniel Gartnera, Rema Padmanb aSchool of Mathematics, Cardiff University, United Kingdom bThe H. John Heinz III College, Carnegie Mellon University, Pittsburgh, USA Abstract The increasing availability of detailed inpatient data is enabling the develop- ment of data-driven approaches to provide novel insights for the management of Length of Stay (LOS), an important quality metric in hospitals. This study examines clustering of inpatients using clinical and demographic attributes to identify LOS outliers and investigates the opportunity to reduce their LOS by comparing their order sequences with similar non-outliers in the same cluster. Learning from retrospective data on 353 pediatric inpatients admit- ted for appendectomy, we develop a two-stage procedure that first identifies a typical cluster with LOS outliers. Our second stage analysis compares orders pairwise to determine candidates for switching to make LOS outliers simi- lar to non-outliers. Results indicate that switching orders in homogeneous inpatient sub-populations within the limits of clinical guidelines may be a promising decision support strategy for LOS management. Keywords: Machine Learning; Clustering; Health Care; Length of Stay Email addresses: [email protected] (Daniel Gartner), [email protected] (Rema Padman) 1. Introduction Length of Stay (LOS) is an important quality metric in hospitals that has been studied for decades Kim and Soeken (2005); Tu et al. (1995). However, the increasing digitization of healthcare with Electronic Health Records and other clinical information systems is enabling the collection and analysis of vast amounts of data using advanced data-driven methods that may be par- ticularly valuable for LOS management Gartner (2015); Saria et al. -

Graph Pie — Pie Charts
Title stata.com graph pie — Pie charts Description Quick start Menu Syntax Options Remarks and examples References Also see Description graph pie draws pie charts. graph pie has three modes of operation. The first corresponds to the specification of two or more variables: . graph pie div1_revenue div2_revenue div3_revenue Three pie slices are drawn, the first corresponding to the sum of variable div1 revenue, the second to the sum of div2 revenue, and the third to the sum of div3 revenue. The second mode of operation corresponds to the specification of one variable and the over() option: . graph pie revenue, over(division) Pie slices are drawn for each value of variable division; the first slice corresponds to the sum of revenue for the first division, the second to the sum of revenue for the second division, and so on. The third mode of operation corresponds to the specification of over() with no variables: . graph pie, over(popgroup) Pie slices are drawn for each value of variable popgroup; the slices correspond to the number of observations in each group. Quick start Pie chart with slices that reflect the proportion of observations for each level of catvar1 graph pie, over(catvar1) As above, but slices reflect the total of v1 for each level of catvar1 graph pie v1, over(catvar1) As above, but with one pie chart for each level of catvar2 graph pie v1, over(catvar1) by(catvar2) Size of slices reflects the share of each variable in the total of v1, v2, v3, v4, and v5 graph pie v1 v2 v3 v4 v5 As above, and label the first slice with its percentage -

Statistical Graphics Using ODS This Document Is an Individual Chapter from SAS/STAT® 13.2 User’S Guide
SAS/STAT® 13.2 User’s Guide Statistical Graphics Using ODS This document is an individual chapter from SAS/STAT® 13.2 User’s Guide. The correct bibliographic citation for the complete manual is as follows: SAS Institute Inc. 2014. SAS/STAT® 13.2 User’s Guide. Cary, NC: SAS Institute Inc. Copyright © 2014, SAS Institute Inc., Cary, NC, USA All rights reserved. Produced in the United States of America. For a hard-copy book: No part of this publication may be reproduced, stored in a retrieval system, or transmitted, in any form or by any means, electronic, mechanical, photocopying, or otherwise, without the prior written permission of the publisher, SAS Institute Inc. For a Web download or e-book: Your use of this publication shall be governed by the terms established by the vendor at the time you acquire this publication. The scanning, uploading, and distribution of this book via the Internet or any other means without the permission of the publisher is illegal and punishable by law. Please purchase only authorized electronic editions and do not participate in or encourage electronic piracy of copyrighted materials. Your support of others’ rights is appreciated. U.S. Government License Rights; Restricted Rights: The Software and its documentation is commercial computer software developed at private expense and is provided with RESTRICTED RIGHTS to the United States Government. Use, duplication or disclosure of the Software by the United States Government is subject to the license terms of this Agreement pursuant to, as applicable, FAR 12.212, DFAR 227.7202-1(a), DFAR 227.7202-3(a) and DFAR 227.7202-4 and, to the extent required under U.S. -

Graphical Perception: Theory, Experimentation, and Application to the Development of Graphical Methods Author(S): William S
Graphical Perception: Theory, Experimentation, and Application to the Development of Graphical Methods Author(s): William S. Cleveland and Robert McGill Source: Journal of the American Statistical Association, Vol. 79, No. 387 (Sep., 1984), pp. 531-554 Published by: Taylor & Francis, Ltd. on behalf of the American Statistical Association Stable URL: http://www.jstor.org/stable/2288400 Accessed: 01-03-2016 14:55 UTC Your use of the JSTOR archive indicates your acceptance of the Terms & Conditions of Use, available at http://www.jstor.org/page/ info/about/policies/terms.jsp JSTOR is a not-for-profit service that helps scholars, researchers, and students discover, use, and build upon a wide range of content in a trusted digital archive. We use information technology and tools to increase productivity and facilitate new forms of scholarship. For more information about JSTOR, please contact [email protected]. Taylor & Francis, Ltd. and American Statistical Association are collaborating with JSTOR to digitize, preserve and extend access to Journal of the American Statistical Association. http://www.jstor.org This content downloaded from 162.105.192.28 on Tue, 01 Mar 2016 14:55:50 UTC All use subject to JSTOR Terms and Conditions Graphical Perception: Theory, Experimentation, and Application to the Development of Graphical Methods WILLIAM S. CLEVELAND and ROBERT McGILL* The subject of graphical methods for data analysis and largely unscientific. This is why Cox (1978) argued, for data presentation needs a scientific foundation. In this "There is a major need for a theory of graphical methods" article we take a few steps in the direction of establishing (p. -

Non-Parametric Vs. Parametric Tests in SAS® Venita Depuy and Paul A
NESUG 17 Analysis Perusing, Choosing, and Not Mis-using: ® Non-parametric vs. Parametric Tests in SAS Venita DePuy and Paul A. Pappas, Duke Clinical Research Institute, Durham, NC ABSTRACT spread is less easy to quantify but is often represented by Most commonly used statistical procedures, such as the t- the interquartile range, which is simply the difference test, are based on the assumption of normality. The field between the first and third quartiles. of non-parametric statistics provides equivalent procedures that do not require normality, but often require DETERMINING NORMALITY assumptions such as equal variances. Parametric tests (OR LACK THEREOF) (which assume normality) are often used on non-normal One of the first steps in test selection should be data; even non-parametric tests are used when their investigating the distribution of the data. PROC assumptions are violated. This paper will provide an UNIVARIATE can be implemented to help determine overview of parametric tests and their non-parametric whether or not your data are normal. This procedure equivalents; what assumptions are required for each test; ® generates a variety of summary statistics, such as the how to perform the tests in SAS ; and guidelines for when mean and median, as well as numerical representations of both sets of assumptions are violated. properties such as skewness and kurtosis. Procedures covered will include PROCs ANOVA, CORR, If the population from which the data are obtained is NPAR1WAY, TTEST and UNIVARIATE. Discussion will normal, the mean and median should be equal or close to include assumptions and assumption violations, equal. The skewness coefficient, which is a measure of robustness, and exact versus approximate tests.