Notes Unit 8: Interquartile Range, Box Plots, and Outliers I
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-
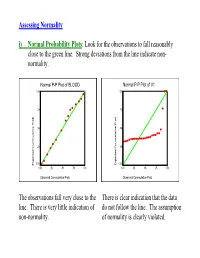
Assessing Normality I) Normal Probability Plots : Look for The
Assessing Normality i) Normal Probability Plots: Look for the observations to fall reasonably close to the green line. Strong deviations from the line indicate non- normality. Normal P-P Plot of BLOOD Normal P-P Plot of V1 1.00 1.00 .75 .75 .50 .50 .25 .25 0.00 0.00 Expected Cummulative Prob Expected Cummulative Expected Cummulative Prob Expected Cummulative 0.00 .25 .50 .75 1.00 0.00 .25 .50 .75 1.00 Observed Cummulative Prob Observed Cummulative Prob The observations fall very close to the There is clear indication that the data line. There is very little indication of do not follow the line. The assumption non-normality. of normality is clearly violated. ii) Histogram: Look for a “bell-shape”. Severe skewness and/or outliers are indications of non-normality. 5 16 14 4 12 10 3 8 2 6 4 1 Std. Dev = 60.29 Std. Dev = 992.11 2 Mean = 274.3 Mean = 573.1 0 N = 20.00 0 N = 25.00 150.0 200.0 250.0 300.0 350.0 0.0 1000.0 2000.0 3000.0 4000.0 175.0 225.0 275.0 325.0 375.0 500.0 1500.0 2500.0 3500.0 4500.0 BLOOD V1 Although the histogram is not perfectly There is a clear indication that the data symmetric and bell-shaped, there is no are right-skewed with some strong clear violation of normality. outliers. The assumption of normality is clearly violated. Caution: Histograms are not useful for small sample sizes as it is difficult to get a clear picture of the distribution. -

Lesson 7: Measuring Variability for Skewed Distributions (Interquartile Range)
NYS COMMON CORE MATHEMATICS CURRICULUM Lesson 7 M2 ALGEBRA I Lesson 7: Measuring Variability for Skewed Distributions (Interquartile Range) Student Outcomes . Students explain why a median is a better description of a typical value for a skewed distribution. Students calculate the 5-number summary of a data set. Students construct a box plot based on the 5-number summary and calculate the interquartile range (IQR). Students interpret the IQR as a description of variability in the data. Students identify outliers in a data distribution. Lesson Notes Distributions that are not symmetrical pose some challenges in students’ thinking about center and variability. The observation that the distribution is not symmetrical is straightforward. The difficult part is to select a measure of center and a measure of variability around that center. In Lesson 3, students learned that, because the mean can be affected by unusual values in the data set, the median is a better description of a typical data value for a skewed distribution. This lesson addresses what measure of variability is appropriate for a skewed data distribution. Students construct a box plot of the data using the 5-number summary and describe variability using the interquartile range. Classwork Exploratory Challenge 1/Exercises 1–3 (10 minutes): Skewed Data and Their Measure of Center Verbally introduce the data set as described in the introductory paragraph and dot plot shown below. Exploratory Challenge 1/Exercises 1–3: Skewed Data and Their Measure of Center Consider the following scenario. A television game show, Fact or Fiction, was cancelled after nine shows. Many people watched the nine shows and were rather upset when it was taken off the air. -

Normal Probability Distribution
MATH2114 Week 8, Thursday The Normal Distribution Slides Adopted & modified from “Business Statistics: A First Course” 7th Ed, by Levine, Szabat and Stephan, 2016 Pearson Education Inc. Objective/Goals To compute probabilities from the normal distribution How to use the normal distribution to solve practical problems To use the normal probability plot to determine whether a set of data is approximately normally distributed Continuous Probability Distributions A continuous variable is a variable that can assume any value on a continuum (can assume an uncountable number of values) thickness of an item time required to complete a task temperature of a solution height, in inches These can potentially take on any value depending only on the ability to precisely and accurately measure The Normal Distribution Bell Shaped f(X) Symmetrical Mean=Median=Mode σ Location is determined by X the mean, μ μ Spread is determined by the standard deviation, σ Mean The random variable has an = Median infinite theoretical range: = Mode + to The Normal Distribution Density Function The formula for the normal probability density function is 2 1 (X μ) 1 f(X) e 2 2π Where e = the mathematical constant approximated by 2.71828 π = the mathematical constant approximated by 3.14159 μ = the population mean σ = the population standard deviation X = any value of the continuous variable The Normal Distribution Density Function By varying 휇 and 휎, we obtain different normal distributions Image taken from Wikipedia, released under public domain The -

2018 Statistics Final Exam Academic Success Programme Columbia University Instructor: Mark England
2018 Statistics Final Exam Academic Success Programme Columbia University Instructor: Mark England Name: UNI: You have two hours to finish this exam. § Calculators are necessary for this exam. § Always show your working and thought process throughout so that even if you don’t get the answer totally correct I can give you as many marks as possible. § It has been a pleasure teaching you all. Try your best and good luck! Page 1 Question 1 True or False for the following statements? Warning, in this question (and only this question) you will get minus points for wrong answers, so it is not worth guessing randomly. For this question you do not need to explain your answer. a) Correlation values can only be between 0 and 1. False. Correlation values are between -1 and 1. b) The Student’s t distribution gives a lower percentage of extreme events occurring compared to a normal distribution. False. The student’s t distribution gives a higher percentage of extreme events. c) The units of the standard deviation of � are the same as the units of �. True. d) For a normal distribution, roughly 95% of the data is contained within one standard deviation of the mean. False. It is within two standard deviations of the mean e) For a left skewed distribution, the mean is larger than the median. False. This is a right skewed distribution. f) If an event � is independent of �, then � (�) = �(�|�) is always true. True. g) For a given confidence level, increasing the sample size of a survey should increase the margin of error. -

L-Moments Based Assessment of a Mixture Model for Frequency Analysis of Rainfall Extremes
Advances in Geosciences, 2, 331–334, 2006 SRef-ID: 1680-7359/adgeo/2006-2-331 Advances in European Geosciences Union Geosciences © 2006 Author(s). This work is licensed under a Creative Commons License. L-moments based assessment of a mixture model for frequency analysis of rainfall extremes V. Tartaglia, E. Caporali, E. Cavigli, and A. Moro Dipartimento di Ingegneria Civile, Universita` degli Studi di Firenze, Italy Received: 2 December 2004 – Revised: 2 October 2005 – Accepted: 3 October 2005 – Published: 23 January 2006 Abstract. In the framework of the regional analysis of hy- events in Tuscany (central Italy), a statistical methodology drological extreme events, a probabilistic mixture model, for parameter estimation of a probabilistic mixture model is given by a convex combination of two Gumbel distributions, here developed. The use of a probabilistic mixture model in is proposed for rainfall extremes modelling. The papers con- the regional analysis of rainfall extreme events, comes from cerns with statistical methodology for parameter estimation. the hypothesis that rainfall phenomenon arises from two in- With this aim, theoretical expressions of the L-moments of dependent populations (Becchi et al., 2000; Caporali et al., the mixture model are here defined. The expressions have 2002). The first population describes the basic components been tested on the time series of the annual maximum height corresponding to the more frequent events of low magnitude, of daily rainfall recorded in Tuscany (central Italy). controlled by the local morpho-climatic conditions. The sec- ond population characterizes the outlier component of more intense and rare events, which is here considered due to the aggregation at the large scale of meteorological phenomena. -

Estimation of Quantiles and the Interquartile Range in Complex Surveys Carol Ann Francisco Iowa State University
Iowa State University Capstones, Theses and Retrospective Theses and Dissertations Dissertations 1987 Estimation of quantiles and the interquartile range in complex surveys Carol Ann Francisco Iowa State University Follow this and additional works at: https://lib.dr.iastate.edu/rtd Part of the Statistics and Probability Commons Recommended Citation Francisco, Carol Ann, "Estimation of quantiles and the interquartile range in complex surveys " (1987). Retrospective Theses and Dissertations. 11680. https://lib.dr.iastate.edu/rtd/11680 This Dissertation is brought to you for free and open access by the Iowa State University Capstones, Theses and Dissertations at Iowa State University Digital Repository. It has been accepted for inclusion in Retrospective Theses and Dissertations by an authorized administrator of Iowa State University Digital Repository. For more information, please contact [email protected]. INFORMATION TO USERS While the most advanced technology has been used to photograph and reproduce this manuscript, the quality of the reproduction is heavily dependent upon the quality of the material submitted. For example: • Manuscript pages may have indistinct print. In such cases, the best available copy has been filmed. • Manuscripts may not always be complete. In such cases, a note will indicate that it is not possible to obtain missing pages. • Copyrighted material may have been removed from the manuscript. In such cases, a note will indicate the deletion. Oversize materials (e.g., maps, drawings, and charts) are photographed by sectioning the original, beginning at the upper left-hand corner and continuing from left to right in equal sections with small overlaps. Each oversize page is also filmed as one exposure and is available, for an additional charge, as a standard 35mm slide or as a 17"x 23" black and white photographic print. -

Boxplots for Grouped and Clustered Data in Toxicology
Penultimate version. If citing, please refer instead to the published version in Archives of Toxicology, DOI: 10.1007/s00204-015-1608-4. Boxplots for grouped and clustered data in toxicology Philip Pallmann1, Ludwig A. Hothorn2 1 Department of Mathematics and Statistics, Lancaster University, Lancaster LA1 4YF, UK, Tel.: +44 (0)1524 592318, [email protected] 2 Institute of Biostatistics, Leibniz University Hannover, 30419 Hannover, Germany Abstract The vast majority of toxicological papers summarize experimental data as bar charts of means with error bars. While these graphics are easy to generate, they often obscure essen- tial features of the data, such as outliers or subgroups of individuals reacting differently to a treatment. Especially raw values are of prime importance in toxicology, therefore we argue they should not be hidden in messy supplementary tables but rather unveiled in neat graphics in the results section. We propose jittered boxplots as a very compact yet comprehensive and intuitively accessible way of visualizing grouped and clustered data from toxicological studies together with individual raw values and indications of statistical significance. A web application to create these plots is available online. Graphics, statistics, R software, body weight, micronucleus assay 1 Introduction Preparing a graphical summary is usually the first if not the most important step in a data analysis procedure, and it can be challenging especially with many-faceted datasets as they occur frequently in toxicological studies. However, even in simple experimental setups many researchers have a hard time presenting their results in a suitable manner. Browsing recent volumes of this journal, we have realized that the least favorable ways of displaying toxicological data appear to be the most popular ones (according to the number of publications that use them). -

Hand-Book on STATISTICAL DISTRIBUTIONS for Experimentalists
Internal Report SUF–PFY/96–01 Stockholm, 11 December 1996 1st revision, 31 October 1998 last modification 10 September 2007 Hand-book on STATISTICAL DISTRIBUTIONS for experimentalists by Christian Walck Particle Physics Group Fysikum University of Stockholm (e-mail: [email protected]) Contents 1 Introduction 1 1.1 Random Number Generation .............................. 1 2 Probability Density Functions 3 2.1 Introduction ........................................ 3 2.2 Moments ......................................... 3 2.2.1 Errors of Moments ................................ 4 2.3 Characteristic Function ................................. 4 2.4 Probability Generating Function ............................ 5 2.5 Cumulants ......................................... 6 2.6 Random Number Generation .............................. 7 2.6.1 Cumulative Technique .............................. 7 2.6.2 Accept-Reject technique ............................. 7 2.6.3 Composition Techniques ............................. 8 2.7 Multivariate Distributions ................................ 9 2.7.1 Multivariate Moments .............................. 9 2.7.2 Errors of Bivariate Moments .......................... 9 2.7.3 Joint Characteristic Function .......................... 10 2.7.4 Random Number Generation .......................... 11 3 Bernoulli Distribution 12 3.1 Introduction ........................................ 12 3.2 Relation to Other Distributions ............................. 12 4 Beta distribution 13 4.1 Introduction ....................................... -

Length of Stay Outlier Detection Through Cluster Analysis: a Case Study in Pediatrics Daniel Gartnera, Rema Padmanb
Length of Stay Outlier Detection through Cluster Analysis: A Case Study in Pediatrics Daniel Gartnera, Rema Padmanb aSchool of Mathematics, Cardiff University, United Kingdom bThe H. John Heinz III College, Carnegie Mellon University, Pittsburgh, USA Abstract The increasing availability of detailed inpatient data is enabling the develop- ment of data-driven approaches to provide novel insights for the management of Length of Stay (LOS), an important quality metric in hospitals. This study examines clustering of inpatients using clinical and demographic attributes to identify LOS outliers and investigates the opportunity to reduce their LOS by comparing their order sequences with similar non-outliers in the same cluster. Learning from retrospective data on 353 pediatric inpatients admit- ted for appendectomy, we develop a two-stage procedure that first identifies a typical cluster with LOS outliers. Our second stage analysis compares orders pairwise to determine candidates for switching to make LOS outliers simi- lar to non-outliers. Results indicate that switching orders in homogeneous inpatient sub-populations within the limits of clinical guidelines may be a promising decision support strategy for LOS management. Keywords: Machine Learning; Clustering; Health Care; Length of Stay Email addresses: [email protected] (Daniel Gartner), [email protected] (Rema Padman) 1. Introduction Length of Stay (LOS) is an important quality metric in hospitals that has been studied for decades Kim and Soeken (2005); Tu et al. (1995). However, the increasing digitization of healthcare with Electronic Health Records and other clinical information systems is enabling the collection and analysis of vast amounts of data using advanced data-driven methods that may be par- ticularly valuable for LOS management Gartner (2015); Saria et al. -

Descriptive Statistics
NCSS Statistical Software NCSS.com Chapter 200 Descriptive Statistics Introduction This procedure summarizes variables both statistically and graphically. Information about the location (center), spread (variability), and distribution is provided. The procedure provides a large variety of statistical information about a single variable. Kinds of Research Questions The use of this module for a single variable is generally appropriate for one of four purposes: numerical summary, data screening, outlier identification (which sometimes is incorporated into data screening), and distributional shape. We will briefly discuss each of these now. Numerical Descriptors The numerical descriptors of a sample are called statistics. These statistics may be categorized as location, spread, shape indicators, percentiles, and interval estimates. Location or Central Tendency One of the first impressions that we like to get from a variable is its general location. You might think of this as the center of the variable on the number line. The average (mean) is a common measure of location. When investigating the center of a variable, the main descriptors are the mean, median, mode, and the trimmed mean. Other averages, such as the geometric and harmonic mean, have specialized uses. We will now briefly compare these measures. If the data come from the normal distribution, the mean, median, mode, and the trimmed mean are all equal. If the mean and median are very different, most likely there are outliers in the data or the distribution is skewed. If this is the case, the median is probably a better measure of location. The mean is very sensitive to extreme values and can be seriously contaminated by just one observation. -

Measures of Variability
CHAPTER 4 Measures of Variability Chapter 3 introduced descriptive statistics, the purpose of which is to numerically describe or summarize data for a Chapter Outline variable. As we learned in Chapter 3, a set of data is often 4.1 An Example From the described in terms of the most typical, common, or frequently Research: How Many “Sometimes” occurring score by using a measure of central tendency such in an “Always”? as the mode, median, or mean. Measures of central ten- 4.2 Understanding Variability dency numerically describe two aspects of a distribution of scores, modality and symmetry, based ondistribute what the scores 4.3 The Range have in common with each other. However, researchers • Strengths and weaknesses of also describe the amount of differences among the scores of a the range variable in analyzing and reportingor their data. This chapter 4.4 The Interquartile Range introduces measures of variability, which are designed to rep- • Strengths and weaknesses of resent the amount of differences in a distribution of data. In the interquartile range this chapter, we will present and evaluate different measures 4.5 The Variance (s2) of variability in terms of their relative strengths and weak- • Definitional formula for the nesses. As in the previous chapters, our presentation will variance depend heavily on the findings and analysis from a published • Computational formula for the research study.post, variance • Why not use the absolute value of the deviation in 4.1 An Example From the calculating the variance? Research: How Many • Why divide by N – 1 rather than “Sometimes” in an “Always”? N in calculating the variance? 4.6 The Standard Deviation (s) copy,Throughout our daily lives, we are constantly asked to fill out • Definitional formula for the questionnaires and surveys. -

Non-Parametric Vs. Parametric Tests in SAS® Venita Depuy and Paul A
NESUG 17 Analysis Perusing, Choosing, and Not Mis-using: ® Non-parametric vs. Parametric Tests in SAS Venita DePuy and Paul A. Pappas, Duke Clinical Research Institute, Durham, NC ABSTRACT spread is less easy to quantify but is often represented by Most commonly used statistical procedures, such as the t- the interquartile range, which is simply the difference test, are based on the assumption of normality. The field between the first and third quartiles. of non-parametric statistics provides equivalent procedures that do not require normality, but often require DETERMINING NORMALITY assumptions such as equal variances. Parametric tests (OR LACK THEREOF) (which assume normality) are often used on non-normal One of the first steps in test selection should be data; even non-parametric tests are used when their investigating the distribution of the data. PROC assumptions are violated. This paper will provide an UNIVARIATE can be implemented to help determine overview of parametric tests and their non-parametric whether or not your data are normal. This procedure equivalents; what assumptions are required for each test; ® generates a variety of summary statistics, such as the how to perform the tests in SAS ; and guidelines for when mean and median, as well as numerical representations of both sets of assumptions are violated. properties such as skewness and kurtosis. Procedures covered will include PROCs ANOVA, CORR, If the population from which the data are obtained is NPAR1WAY, TTEST and UNIVARIATE. Discussion will normal, the mean and median should be equal or close to include assumptions and assumption violations, equal. The skewness coefficient, which is a measure of robustness, and exact versus approximate tests.