UNICODE STANDARD Indic Scripts
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

UNICODE for Kannada General Information & Description
UNICODE for Kannada (U+0C80 to U+0CFF) General Information & Description Written by: C V Srinatha Sastry Issued by: Director Directorate of Information Technology Government of Karnataka Multi Storied Buildings, Vidhana Veedhi BANGALORE 560 001 INDIA PDF created with FinePrint pdfFactory Pro trial version http://www.pdffactory.com UNICODE for Kannada Introduction The Kannada script is a South Indian script. It is used to write Kannada language of Karnataka State in India. This is also used in many parts of Tamil Nadu, Kerala, Andhra Pradesh and Maharashtra States of India. In addition, the Kannada script is also used to write Tulu, Konkani and Kodava languages. Kannada along with other Indian language scripts shares a large number of structural features. The Kannada block of Unicode Standard (0C80 to 0CFF) is based on ISCII-1988 (Indian Standard Code for Information Interchange). The Unicode Standard (version 3) encodes Kannada characters in the same relative positions as those coded in the ISCII-1988 standard. The Writing system that employs Kannada script constitutes a cross between syllabic writing systems and phonemic writing systems (alphabets). The effective unit of writing Kannada is the orthographic syllable consisting of a consonant (Vyanjana) and vowel (Vowel) (CV) core and optionally, one or more preceding consonants, with a canonical structure of ((C)C)CV. The orthographic syllable need not correspond exactly with a phonological syllable, especially when a consonant cluster is involved, but the writing system is built on phonological principles and tends to correspond quite closely to pronunciation. The orthographic syllable is built up of alphabetic pieces, the actual letters of Kannada script. -

A Practical Sanskrit Introductory
A Practical Sanskrit Intro ductory This print le is available from ftpftpnacaczawiknersktintropsjan Preface This course of fteen lessons is intended to lift the Englishsp eaking studentwho knows nothing of Sanskrit to the level where he can intelligently apply Monier DhatuPat ha Williams dictionary and the to the study of the scriptures The rst ve lessons cover the pronunciation of the basic Sanskrit alphab et Devanagar together with its written form in b oth and transliterated Roman ash cards are included as an aid The notes on pronunciation are largely descriptive based on mouth p osition and eort with similar English Received Pronunciation sounds oered where p ossible The next four lessons describ e vowel emb ellishments to the consonants the principles of conjunct consonants Devanagar and additions to and variations in the alphab et Lessons ten and sandhi eleven present in grid form and explain their principles in sound The next three lessons p enetrate MonierWilliams dictionary through its four levels of alphab etical order and suggest strategies for nding dicult words The artha DhatuPat ha last lesson shows the extraction of the from the and the application of this and the dictionary to the study of the scriptures In addition to the primary course the rst eleven lessons include a B section whichintro duces the student to the principles of sentence structure in this fully inected language Six declension paradigms and class conjugation in the present tense are used with a minimal vo cabulary of nineteen words In the B part of -
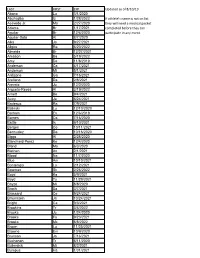
LAST FIRST EXP Updated As of 8/10/19 Abano Lu 3/1/2020 Abuhadba Iz 1/28/2022 If Athlete's Name Is Not on List Acevedo Jr
LAST FIRST EXP Updated as of 8/10/19 Abano Lu 3/1/2020 Abuhadba Iz 1/28/2022 If athlete's name is not on list Acevedo Jr. Ma 2/27/2020 they will need a medical packet Adams Br 1/17/2021 completed before they can Aguilar Br 12/6/2020 participate in any event. Aguilar-Soto Al 8/7/2020 Alka Ja 9/27/2021 Allgire Ra 6/20/2022 Almeida Br 12/27/2021 Amason Ba 5/19/2022 Amy De 11/8/2019 Anderson Ca 4/17/2021 Anderson Mi 5/1/2021 Ardizone Ga 7/16/2021 Arellano Da 2/8/2021 Arevalo Ju 12/2/2020 Argueta-Reyes Al 3/19/2022 Arnett Be 9/4/2021 Autry Ja 6/24/2021 Badeaux Ra 7/9/2021 Balinski Lu 12/10/2020 Barham Ev 12/6/2019 Barnes Ca 7/16/2020 Battle Is 9/10/2021 Bergen Co 10/11/2021 Bermudez Da 10/16/2020 Biggs Al 2/28/2020 Blanchard-Perez Ke 12/4/2020 Bland Ma 6/3/2020 Blethen An 2/1/2021 Blood Na 11/7/2020 Blue Am 10/10/2021 Bontempo Lo 2/12/2021 Bowman Sk 2/26/2022 Boyd Ka 5/9/2021 Boyd Ty 11/29/2021 Boyzo Mi 8/8/2020 Brach Sa 3/7/2021 Brassard Ce 9/24/2021 Braunstein Ja 10/24/2021 Bright Ca 9/3/2021 Brookins Tr 3/4/2022 Brooks Ju 1/24/2020 Brooks Fa 9/23/2021 Brooks Mc 8/8/2022 Brown Lu 11/25/2021 Browne Em 10/9/2020 Brunson Jo 7/16/2021 Buchanan Tr 6/11/2020 Bullerdick Mi 8/2/2021 Bumpus Ha 1/31/2021 LAST FIRST EXP Updated as of 8/10/19 Burch Co 11/7/2020 Burch Ma 9/9/2021 Butler Ga 5/14/2022 Byers Je 6/14/2021 Cain Me 6/20/2021 Cao Tr 11/19/2020 Carlson Be 5/29/2021 Cerda Da 3/9/2021 Ceruto Ri 2/14/2022 Chang Ia 2/19/2021 Channapati Di 10/31/2021 Chao Et 8/20/2021 Chase Em 8/26/2020 Chavez Fr 6/13/2020 Chavez Vi 11/14/2021 Chidambaram Ga 10/13/2019 -

Kharosthi Manuscripts: a Window on Gandharan Buddhism*
KHAROSTHI MANUSCRIPTS: A WINDOW ON GANDHARAN BUDDHISM* Andrew GLASS INTRODUCTION In the present article I offer a sketch of Gandharan Buddhism in the centuries around the turn of the common era by looking at various kinds of evidence which speak to us across the centuries. In doing so I hope to shed a little light on an important stage in the transmission of Buddhism as it spread from India, through Gandhara and Central Asia to China, Korea, and ultimately Japan. In particular, I will focus on the several collections of Kharo~thi manuscripts most of which are quite new to scholarship, the vast majority of these having been discovered only in the past ten years. I will also take a detailed look at the contents of one of these manuscripts in order to illustrate connections with other text collections in Pali and Chinese. Gandharan Buddhism is itself a large topic, which cannot be adequately described within the scope of the present article. I will therefore confine my observations to the period in which the Kharo~thi script was used as a literary medium, that is, from the time of Asoka in the middle of the third century B.C. until about the third century A.D., which I refer to as the Kharo~thi Period. In addition to looking at the new manuscript materials, other forms of evidence such as inscriptions, art and architecture will be touched upon, as they provide many complementary insights into the Buddhist culture of Gandhara. The travel accounts of the Chinese pilgrims * This article is based on a paper presented at Nagoya University on April 22nd 2004. -

Assessment of Options for Handling Full Unicode Character Encodings in MARC21 a Study for the Library of Congress
1 Assessment of Options for Handling Full Unicode Character Encodings in MARC21 A Study for the Library of Congress Part 1: New Scripts Jack Cain Senior Consultant Trylus Computing, Toronto 1 Purpose This assessment intends to study the issues and make recommendations on the possible expansion of the character set repertoire for bibliographic records in MARC21 format. 1.1 “Encoding Scheme” vs. “Repertoire” An encoding scheme contains codes by which characters are represented in computer memory. These codes are organized according to a certain methodology called an encoding scheme. The list of all characters so encoded is referred to as the “repertoire” of characters in the given encoding schemes. For example, ASCII is one encoding scheme, perhaps the one best known to the average non-technical person in North America. “A”, “B”, & “C” are three characters in the repertoire of this encoding scheme. These three characters are assigned encodings 41, 42 & 43 in ASCII (expressed here in hexadecimal). 1.2 MARC8 "MARC8" is the term commonly used to refer both to the encoding scheme and its repertoire as used in MARC records up to 1998. The ‘8’ refers to the fact that, unlike Unicode which is a multi-byte per character code set, the MARC8 encoding scheme is principally made up of multiple one byte tables in which each character is encoded using a single 8 bit byte. (It also includes the EACC set which actually uses fixed length 3 bytes per character.) (For details on MARC8 and its specifications see: http://www.loc.gov/marc/.) MARC8 was introduced around 1968 and was initially limited to essentially Latin script only. -

OSU WPL # 27 (1983) 140- 164. the Elimination of Ergative Patterns Of
OSU WPL # 27 (1983) 140- 164. The Elimination of Ergative Patterns of Case-Marking and Verbal Agreement in Modern Indic Languages Gregory T. Stump Introduction. As is well known, many of the modern Indic languages are partially ergative, showing accusative patterns of case- marking and verbal agreement in nonpast tenses, but ergative patterns in some or all past tenses. This partial ergativity is not at all stable in these languages, however; what I wish to show in the present paper, in fact, is that a large array of factors is contributing to the elimination of partial ergativity in the modern Indic languages. The forces leading to the decay of ergativity are diverse in nature; and any one of these may exert a profound influence on the syntactic development of one language but remain ineffectual in another. Before discussing this erosion of partial ergativity in Modern lndic, 1 would like to review the history of what the I ndian grammar- ians call the prayogas ('constructions') of a past tense verb with its subject and direct object arguments; the decay of Indic ergativity is, I believe, best envisioned as the effect of analogical develop- ments on or within the system of prayogas. There are three prayogas in early Modern lndic. The first of these is the kartariprayoga, or ' active construction' of intransitive verbs. In the kartariprayoga, the verb agrees (in number and p,ender) with its subject, which is in the nominative case--thus, in Vernacular HindOstani: (1) kartariprayoga: 'aurat chali. mard chala. woman (nom.) went (fern. sg.) man (nom.) went (masc. -

Tai Lü / ᦺᦑᦟᦹᧉ Tai Lùe Romanization: KNAB 2012
Institute of the Estonian Language KNAB: Place Names Database 2012-10-11 Tai Lü / ᦺᦑᦟᦹᧉ Tai Lùe romanization: KNAB 2012 I. Consonant characters 1 ᦀ ’a 13 ᦌ sa 25 ᦘ pha 37 ᦤ da A 2 ᦁ a 14 ᦍ ya 26 ᦙ ma 38 ᦥ ba A 3 ᦂ k’a 15 ᦎ t’a 27 ᦚ f’a 39 ᦦ kw’a 4 ᦃ kh’a 16 ᦏ th’a 28 ᦛ v’a 40 ᦧ khw’a 5 ᦄ ng’a 17 ᦐ n’a 29 ᦜ l’a 41 ᦨ kwa 6 ᦅ ka 18 ᦑ ta 30 ᦝ fa 42 ᦩ khwa A 7 ᦆ kha 19 ᦒ tha 31 ᦞ va 43 ᦪ sw’a A A 8 ᦇ nga 20 ᦓ na 32 ᦟ la 44 ᦫ swa 9 ᦈ ts’a 21 ᦔ p’a 33 ᦠ h’a 45 ᧞ lae A 10 ᦉ s’a 22 ᦕ ph’a 34 ᦡ d’a 46 ᧟ laew A 11 ᦊ y’a 23 ᦖ m’a 35 ᦢ b’a 12 ᦋ tsa 24 ᦗ pa 36 ᦣ ha A Syllable-final forms of these characters: ᧅ -k, ᧂ -ng, ᧃ -n, ᧄ -m, ᧁ -u, ᧆ -d, ᧇ -b. See also Note D to Table II. II. Vowel characters (ᦀ stands for any consonant character) C 1 ᦀ a 6 ᦀᦴ u 11 ᦀᦹ ue 16 ᦀᦽ oi A 2 ᦰ ( ) 7 ᦵᦀ e 12 ᦵᦀᦲ oe 17 ᦀᦾ awy 3 ᦀᦱ aa 8 ᦶᦀ ae 13 ᦺᦀ ai 18 ᦀᦿ uei 4 ᦀᦲ i 9 ᦷᦀ o 14 ᦀᦻ aai 19 ᦀᧀ oei B D 5 ᦀᦳ ŭ,u 10 ᦀᦸ aw 15 ᦀᦼ ui A Indicates vowel shortness in the following cases: ᦀᦲᦰ ĭ [i], ᦵᦀᦰ ĕ [e], ᦶᦀᦰ ăe [ ∎ ], ᦷᦀᦰ ŏ [o], ᦀᦸᦰ ăw [ ], ᦀᦹᦰ ŭe [ ɯ ], ᦵᦀᦲᦰ ŏe [ ]. -

The Kharoṣṭhī Documents from Niya and Their Contribution to Gāndhārī Studies
The Kharoṣṭhī Documents from Niya and Their Contribution to Gāndhārī Studies Stefan Baums University of Munich [email protected] Niya Document 511 recto 1. viśu͚dha‐cakṣ̄u bhavati tathāgatānaṃ bhavatu prabhasvara hiterṣina viśu͚dha‐gātra sukhumāla jināna pūjā suchavi paramārtha‐darśana 4 ciraṃ ca āyu labhati anālpakaṃ 5. pratyeka‐budha ca karoṃti yo s̄ātravivegam āśṛta ganuktamasya 1 ekābhirāma giri‐kaṃtarālaya 2. na tasya gaṃḍa piṭakā svakartha‐yukta śamathe bhavaṃti gune rata śilipataṃ tatra vicārcikaṃ teṣaṃ pi pūjā bhavatu [v]ā svayaṃbhu[na] 4 1 suci sugaṃdha labhati sa āśraya 6. koḍinya‐gotra prathamana karoṃti yo s̄ātraśrāvaka {?} ganuktamasya 2 teṣaṃ ca yo āsi subha͚dra pac̄ima 3. viśāla‐netra bhavati etasmi abhyaṃdare ye prabhasvara atīta suvarna‐gātra abhirūpa jinorasa te pi bhavaṃtu darśani pujita 4 2 samaṃ ca pādo utarā7. imasmi dāna gana‐rāya prasaṃṭ́hita u͚tama karoṃti yo s̄ātra sthaira c̄a madhya navaka ganuktamasya 3 c̄a bhikṣ̄u m It might be going to far to say that Torwali is the direct lineal descendant of the Niya Prakrit, but there is no doubt that out of all the modern languages it shows the closest resemblance to it. [...] that area around Peshawar, where [...] there is most reason to believe was the original home of Niya Prakrit. That conclusion, which was reached for other reasons, is thus confirmed by the distribution of the modern dialects. (Burrow 1936) Under this name I propose to include those inscriptions of Aśoka which are recorded at Shahbazgaṛhi and Mansehra in the Kharoṣṭhī script, the vehicle for the remains of much of this dialect. To be included also are the following sources: the Buddhist literary text, the Dharmapada found in Khotan, written likewise in Kharoṣṭhī [...]; the Kharoṣṭhī documents on wood, leather, and silk from Caḍ́ota (the Niya site) on the border of the ancient kingdom of Khotan, which represented the official language of the capital Krorayina [...]. -

Sanskrit Alphabet
Sounds Sanskrit Alphabet with sounds with other letters: eg's: Vowels: a* aa kaa short and long ◌ к I ii ◌ ◌ к kii u uu ◌ ◌ к kuu r also shows as a small backwards hook ri* rri* on top when it preceeds a letter (rpa) and a ◌ ◌ down/left bar when comes after (kra) lri lree ◌ ◌ к klri e ai ◌ ◌ к ke o au* ◌ ◌ к kau am: ah ◌ं ◌ः कः kah Consonants: к ka х kha ga gha na Ê ca cha ja jha* na ta tha Ú da dha na* ta tha Ú da dha na pa pha º ba bha ma Semivowels: ya ra la* va Sibilants: sa ш sa sa ha ksa** (**Compound Consonant. See next page) *Modern/ Hindi Versions a Other ऋ r ॠ rr La, Laa (retro) औ au aum (stylized) ◌ silences the vowel, eg: к kam झ jha Numero: ण na (retro) १ ५ ॰ la 1 2 3 4 5 6 7 8 9 0 @ Davidya.ca Page 1 Sounds Numero: 0 1 2 3 4 5 6 7 8 910 १॰ ॰ १ २ ३ ४ ६ ७ varient: ५ ८ (shoonya eka- dva- tri- catúr- pancha- sás- saptán- astá- návan- dásan- = empty) works like our Arabic numbers @ Davidya.ca Compound Consanants: When 2 or more consonants are together, they blend into a compound letter. The 12 most common: jna/ tra ttagya dya ddhya ksa kta kra hma hna hva examples: for a whole chart, see: http://www.omniglot.com/writing/devanagari_conjuncts.php that page includes a download link but note the site uses the modern form Page 2 Alphabet Devanagari Alphabet : к х Ê Ú Ú º ш @ Davidya.ca Page 3 Pronounce Vowels T pronounce Consonants pronounce Semivowels pronounce 1 a g Another 17 к ka v Kit 42 ya p Yoga 2 aa g fAther 18 х kha v blocKHead -

Proposal to Encode 0D5F MALAYALAM LETTER ARCHAIC II
Proposal to encode 0D5F MALAYALAM LETTER ARCHAIC II Shriramana Sharma, jamadagni-at-gmail-dot-com, India 2012-May-22 §1. Introduction In the Malayalam Unicode encoding, the independent letter form for the long vowel Ī is: ഈ where the length mark ◌ൗ is appended to the short vowel ഇ to parallel the symbols for U/UU i.e. ഉ/ഊ. However, Ī was originally written as: As these are entirely different representations of Ī, although their sound value may be the same, it is proposed to encode the archaic form as a separate character. §2. Background As the core Unicode encoding for the major Indic scripts is based on ISCII, and the ISCII code chart for Malayalam only contained the modern form for the independent Ī [1, p 24]: … thus it is this written form that came to be encoded as 0D08 MALAYALAM LETTER II. While this “new” written form is seen in print as early as 1936 CE [2]: … there is no doubt that the much earlier form was parallel to the modern Grantha , both of which are derived from the old Grantha Ī as seen below: 1 ma - īdṛgvidhā | tatarāya īṇ Old Grantha from the Iḷaiyānputtūr copper plates [3, p 13]. Also seen is the Vatteḻuttu Ī of the same time (line 2, 2nd char from right) which also exhibits the two dots. Of course, both are derived from old South Indian Brahmi Ī which again has the two dots. It is said [entire paragraph: Radhakrishna Warrier, personal communication] that it was the poet Vaḷḷattōḷ Nārāyaṇa Mēnōn (1878–1958) who introduced the new form of Ī ഈ. -

Proposal for a Kannada Script Root Zone Label Generation Ruleset (LGR)
Proposal for a Kannada Script Root Zone Label Generation Ruleset (LGR) Proposal for a Kannada Script Root Zone Label Generation Ruleset (LGR) LGR Version: 3.0 Date: 2019-03-06 Document version: 2.6 Authors: Neo-Brahmi Generation Panel [NBGP] 1. General Information/ Overview/ Abstract The purpose of this document is to give an overview of the proposed Kannada LGR in the XML format and the rationale behind the design decisions taken. It includes a discussion of relevant features of the script, the communities or languages using it, the process and methodology used and information on the contributors. The formal specification of the LGR can be found in the accompanying XML document: proposal-kannada-lgr-06mar19-en.xml Labels for testing can be found in the accompanying text document: kannada-test-labels-06mar19-en.txt 2. Script for which the LGR is Proposed ISO 15924 Code: Knda ISO 15924 N°: 345 ISO 15924 English Name: Kannada Latin transliteration of the native script name: Native name of the script: ಕನ#ಡ Maximal Starting Repertoire (MSR) version: MSR-4 Some languages using the script and their ISO 639-3 codes: Kannada (kan), Tulu (tcy), Beary, Konkani (kok), Havyaka, Kodava (kfa) 1 Proposal for a Kannada Script Root Zone Label Generation Ruleset (LGR) 3. Background on Script and Principal Languages Using It 3.1 Kannada language Kannada is one of the scheduled languages of India. It is spoken predominantly by the people of Karnataka State of India. It is one of the major languages among the Dravidian languages. Kannada is also spoken by significant linguistic minorities in the states of Andhra Pradesh, Telangana, Tamil Nadu, Maharashtra, Kerala, Goa and abroad. -

Proposal for a Gujarati Script Root Zone Label Generation Ruleset (LGR)
Proposal for a Gujarati Root Zone LGR Neo-Brahmi Generation Panel Proposal for a Gujarati Script Root Zone Label Generation Ruleset (LGR) LGR Version: 3.0 Date: 2019-03-06 Document version: 3.6 Authors: Neo-Brahmi Generation Panel [NBGP] 1 General Information/ Overview/ Abstract The purpose of this document is to give an overview of the proposed Gujarati LGR in the XML format and the rationale behind the design decisions taken. It includes a discussion of relevant features of the script, the communities or languages using it, the process and methodology used and information on the contributors. The formal specification of the LGR can be found in the accompanying XML document: proposal-gujarati-lgr-06mar19-en.xml Labels for testing can be found in the accompanying text document: gujarati-test-labels-06mar19-en.txt 2 Script for which the LGR is proposed ISO 15924 Code: Gujr ISO 15924 Key N°: 320 ISO 15924 English Name: Gujarati Latin transliteration of native script name: gujarâtî Native name of the script: ગજુ રાતી Maximal Starting Repertoire (MSR) version: MSR-4 1 Proposal for a Gujarati Root Zone LGR Neo-Brahmi Generation Panel 3 Background on the Script and the Principal Languages Using it1 Gujarati (ગજુ રાતી) [also sometimes written as Gujerati, Gujarathi, Guzratee, Guujaratee, Gujrathi, and Gujerathi2] is an Indo-Aryan language native to the Indian state of Gujarat. It is part of the greater Indo-European language family. It is so named because Gujarati is the language of the Gujjars. Gujarati's origins can be traced back to Old Gujarati (circa 1100– 1500 AD).