Semantic Enrichment of Ontology Mappings
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Keeping St. Pete Special Thrown by Tom St. Petersburg Police Mounted Patrol Unit
JUL/AUG 2016 St. Petersburg, FL Est. September 2004 St. Petersburg Police Mounted Patrol Unit Jeannie Carlson In July, 2009 when the Boston Police t. Petersburg cannot be called a ‘one-horse Department was in the process of disbanding town.’ In fact, in addition to the quaint their historic mounted units, they donated two Shorse-drawn carriages along Beach Drive, of their trained, Percheron/Thoroughbred-cross the city has a Mounted Police Unit that patrols horses to the St. Petersburg Police Department. the downtown waterfront parks and The last time the St. Petersburg Police entertainment district. The Mounted Unit, Department employed a mounted unit was back which consists of two officers and two horses, in 1927. The donation of these horses facilitated is part of the Traffic Division of the St. Petersburg a resurgence of the unit in the bustling little Police Department as an enhancement to the metropolis that is now the City of St. Petersburg police presence downtown, particularly during in the 21st century. weekends and special events. Continued on page 28 Tom Davis and some of his finished pottery Thrown by Tom Linda Dobbs ranada Terrace resident Tom Davis is a true craftsman – even an artist. Craftsmen work with their hands and Gheads, but artists also work with their hearts according to St. Francis of Assisi. Well, Tom certainly has heart – he spends 4-6 hours per day at the Morean Center for Clay totally immersed in pottery. He even sometimes helps with the firing of ceramic creations. Imagine that in Florida’s summer heat. Tom first embraced pottery in South Korea in 1971-72 where he was stationed as a captain in the US Air Force. -

2020-Commencement-Program.Pdf
One Hundred and Sixty-Second Annual Commencement JUNE 19, 2020 One Hundred and Sixty-Second Annual Commencement 11 A.M. CDT, FRIDAY, JUNE 19, 2020 2982_STUDAFF_CommencementProgram_2020_FRONT.indd 1 6/12/20 12:14 PM UNIVERSITY SEAL AND MOTTO Soon after Northwestern University was founded, its Board of Trustees adopted an official corporate seal. This seal, approved on June 26, 1856, consisted of an open book surrounded by rays of light and circled by the words North western University, Evanston, Illinois. Thirty years later Daniel Bonbright, professor of Latin and a member of Northwestern’s original faculty, redesigned the seal, Whatsoever things are true, retaining the book and light rays and adding two quotations. whatsoever things are honest, On the pages of the open book he placed a Greek quotation from the Gospel of John, chapter 1, verse 14, translating to The Word . whatsoever things are just, full of grace and truth. Circling the book are the first three whatsoever things are pure, words, in Latin, of the University motto: Quaecumque sunt vera whatsoever things are lovely, (What soever things are true). The outer border of the seal carries the name of the University and the date of its founding. This seal, whatsoever things are of good report; which remains Northwestern’s official signature, was approved by if there be any virtue, the Board of Trustees on December 5, 1890. and if there be any praise, The full text of the University motto, adopted on June 17, 1890, is think on these things. from the Epistle of Paul the Apostle to the Philippians, chapter 4, verse 8 (King James Version). -
![P7ba9 [Read Now] Relentless: the Memoir Online](https://docslib.b-cdn.net/cover/7551/p7ba9-read-now-relentless-the-memoir-online-587551.webp)
P7ba9 [Read Now] Relentless: the Memoir Online
p7ba9 [Read now] Relentless: The Memoir Online [p7ba9.ebook] Relentless: The Memoir Pdf Free Par Yngwie J. Malmsteen ebooks | Download PDF | *ePub | DOC | audiobook Download Now Free Download Here Download eBook Détails sur le produit Rang parmi les ventes : #385491 dans eBooksPublié le: 2013-05-21Sorti le: 2013-05- 21Format: Ebook Kindle | File size: 76.Mb Par Yngwie J. Malmsteen : Relentless: The Memoir before purchasing it in order to gage whether or not it would be worth my time, and all praised Relentless: The Memoir: Commentaires clientsCommentaires clients les plus utiles6 internautes sur 6 ont trouvé ce commentaire utile. Encore des efforts à fairePar LEROY StephaneMitigé. Sentiment étrange pour celui qui suit la carrière de Malmsteen depuis l'achat du vinyle de Steeler (en import chez Juke Boxe au Centre Commercial Gaîté de Montparnasse en 1983 !!!) que ce livre. On occulte ou on réécrit les sujets qui fâchent en passant sous silence les protagonistes (l'index à ce titre est édifiant) : Quid de Goran Edman et du litige qui les opposa pour une histoire de droits d'auteurs, de Michael Vescera, etc... Le passage sur ses anciennes petites amies ou femmes est à lui seul un cas d'école (on ne cite pas nommément Tallee Savage, Greta Nelson, Erica Norberg, Amberdawn). Idem pour l'accident en Jaguar (on parle de Peter sans préciser le nom de Roth et sa qualité de guitar technicien). Règlement de compte en règle contre Marcel Jacob avec par contraste un portrait élogieux de Wally Voss (éphémère bassite des tournées 85-86)J'attendais des anecdotes un peu plus fouillées, comme par exemple sa première production pour l'album de 3Rd Stage Alert dont le guitariste rythmique Giulio Lomma s'occupait de l'entretien de sa piscine à L.A, sur le fait de dédier Icarus Dream à son chat Moje décédé en Suède pendant l'enregistrement de l'album Rising Force, etc.. -

National College Physical Education Association for Men 1201 Sixteenth Street Northrist Washington D.C
1 DOCUNENTRESUNE ED 116:576 SP .009877 - , . TITLE Proceedings (of the) Sixty Eighth Annual Meeting (of the) National College Physical Education Association ,,for Zen. INSTITUTION American Alliance for Health, Physical Education, and Recreation, Washington,"D.C. '. , PUB DATE 0 Jan 65 . NOTE 177p.; Proceeding's of the Annual Meeting of the Fationatl College Piysical Education Association for 'Men-(68th, Minneapolis, Minnesota, January 7-9, ... * -.1965) AVALABIE FROM kmeritan Alliance for Health, Physical Education, and Pedreation, 1201 Sixteenth Street, N.V., Washington, D. C: 20036' ($3.001 ,S. EDRS PRICE MR-$0.83 Plus Postage. HC Not Available from EDRS. -z DESCRIPTORS *Athletics; Cardiovascular System; Facility Planning; High Schools; History; Intercollegiate Programs; *Intramural Athletic Programs; Physical Activities; *Physical. Education; Physical Fitness; Psychology; *Teacher Education , . t ABSTRACT This document contains the 'proceedings of the, January 1965 Annual meeting of the .National, College Physical Education Association for Men (VCPEAM). In addition tp.,the special addresses "-- given al.-the meeting, the proceedings contain speeches on the followl.ng topics: (1) research, .(2) -imtercollegiate.athleticsf (3) history of sport,(4) teacher. education,(5) basicinstruction,and (6) intramurals. The research areas. discussed include the relationship-between physical activity'ind coronary heart disease and the effects of specific soCial7incentive conditions on performance on physical fitness tests. Also included 'are the. president's report, finantial reports, minutes frbm the previous ieeting,.and reports from the StandingCommittees, 'continuingCommittees, Joint Committees, and the-President's tommittees. The Constitution of the NCPEAg and lists of honorary members and active members complete the document. .. , .- (CD) - , 3,1 ***************************************************4******************* * .',Documents acquired by ERIC include many informal unpublished * materials .not available from other sources. -

12 Morphology and Lexical Semantics
248 Beth Levin and Malka Rappaport Hovav 12 Morphology and Lexical Semantics BETH LEVIN AND MALKA RAPPAPORT HOVAV The relation between lexical semantics and morphology has not been the subject of much study. This may seem surprising, since a morpheme is often viewed as a minimal Saussurean sign relating form and meaning: it is a concept with a phonologically composed name. On this view, morphology has both a semantic side and a structural side, the latter sometimes called “morphological realization” (Aronoff 1994, Zwicky 1986b). Since morphology is the study of the structure and derivation of complex signs, attention could be focused on the semantic side (the composition of complex concepts) and the structural side (the composition of the complex names for the concepts) and the relation between them. In fact, recent work in morphology has been concerned almost exclusively with the composition of complex names for concepts – that is, with the struc- tural side of morphology. This dissociation of “form” from “meaning” was foreshadowed by Aronoff’s (1976) demonstration that morphemes are not necessarily associated with a constant meaning – or any meaning at all – and that their nature is basically structural. Although in early generative treat- ments of word formation, semantic operations accompanied formal morpho- logical operations (as in Aronoff’s Word Formation Rules), many subsequent generative theories of morphology, following Lieber (1980), explicitly dissoci- ate the lexical semantic operations of composition from the formal structural -

Johansson Sonic Winter + Johansson Brothers Mp3, Flac, Wma
Johansson Sonic Winter + Johansson Brothers mp3, flac, wma DOWNLOAD LINKS (Clickable) Genre: Rock Album: Sonic Winter + Johansson Brothers Country: Argentina Released: 2000 Style: Prog Rock, Heavy Metal, Hard Rock MP3 version RAR size: 1503 mb FLAC version RAR size: 1921 mb WMA version RAR size: 1979 mb Rating: 4.1 Votes: 809 Other Formats: MP1 AIFF DMF TTA XM AHX ADX Tracklist Sonic Winter 1-1 Days Of Wonder 5:06 1-2 All Opposable Thumbs 8:54 1-3 Fill The Void 5:26 1-4 Enigma Suite 11:19 1-5 Nowhere To Run 5:16 1-6 Shine On Me 4:42 1-7 A Higher Place 4:05 1-8 The Flood 9:26 1-9 Back To Life 20:53 The Johansson Brothers 2-1 The Good Life 3:48 2-2 Deal With It 4:15 2-3 Quli 7:03 2-4 Slow Down 4:45 2-5 Stranded 4:29 2-6 Homeless 10:35 2-7 Loser 4:25 2-8 We All Pretend 4:58 2-9 Polyester Man 4:18 2-10 High As A Kite 3:37 2-11 Good Vibrations 21:46 Companies, etc. Licensed From – Heptagon Records Distributed By – Musicland Phonographic Copyright (p) – NEMS Enterprises Copyright (c) – Heptagon Records Pressed By – Laser Disc – 11530 Pressed By – Laser Disc – 11531 Recorded At – Starec Gramophone AB Recorded At – Moon Path A, Malmö, Sweden Recorded At – Sheep Valley Studios Recorded At – Studio 308, Miami, Fl Recorded At – RoastingHouse Recorded At – Greenpoint Studios Recorded At – Trippel Studios Mixed At – Moon Path A, Malmö, Sweden Mixed At – Smash Studios, NYC Mastered At – Stage Tech, Malmö Credits Artwork, Painting – Metalgate* (tracks: 2-1 to 2-11), Rainer Kalwitz (tracks: 2-1 to 2-11) Backing Vocals – Anders Johansson (tracks: 2-11) -

Studies in the Linguistic Sciences
UNIVERSITY OF ILLINOIS Llb'RARY AT URBANA-CHAMPAIGN MODERN LANGUAGE NOTICE: Return or renew all Library Materialsl The Minimum Fee (or each Lost Book is $50.00. The person charging this material is responsible for its return to the library from which it was withdrawn on or before the Latest Date stamped below. Theft, mutilation, and underlining of books are reasons for discipli- nary action and may result in dismissal from the University. To renew call Telephone Center, 333-8400 UNIVERSITY OF ILLINOIS LIBRARY AT URBANA-CHAMPAIGN ModeriJLanp & Lb Library ^rn 425 333-0076 L161—O-I096 Che Linguistic Sciences PAPERS IN GENERAL LINGUISTICS ANTHONY BRITTI Quantifier Repositioning SUSAN MEREDITH BURT Remarks on German Nominalization CHIN-CHUAN CHENG AND CHARLES KISSEBERTH Ikorovere Makua Tonology (Part 1) PETER COLE AND GABRIELLA HERMON Subject to Object Raising in an Est Framework: Evidence from Quechua RICHARD CURETON The Inclusion Constraint: Description and Explanation ALICE DAVISON Some Mysteries of Subordination CHARLES A. FERGUSON AND APIA DIL The Sociolinguistic Valiable (s) in Bengali: A Sound Change in Progress GABRIELLA HERMON Rule Ordering Versus Globality: Evidencefrom the Inversion Construction CHIN-W. KIM Neutralization in Korean Revisited DAVID ODDEN Principles of Stress Assignment: A Crosslinguistic View PAULA CHEN ROHRBACH The Acquisition of Chinese by Adult English Speakers: An Error Analysis MAURICE K.S. WONG Origin of the High Rising Changed Tone in Cantonese SORANEE WONGBIASAJ On the Passive in Thai Department of Linguistics University of Illinois^-^ STUDIES IN THE LINGUISTIC SCIENCES PUBLICATION OF THE DEPARTMENT OF LINGUISTICS UNIVERSITY OF ILLINOIS AT URBANA-CHAMPAIGN EDITORS: Charles W. Kisseberth, Braj B. -

Morphemes by Kirsten Mills Student, University of North Carolina at Pembroke, 1998
Morphemes by Kirsten Mills http://www.uncp.edu/home/canada/work/caneng/morpheme.htm Student, University of North Carolina at Pembroke, 1998 Introduction Morphemes are what make up words. Often, morphemes are thought of as words but that is not always true. Some single morphemes are words while other words have two or more morphemes within them. Morphemes are also thought of as syllables but this is incorrect. Many words have two or more syllables but only one morpheme. Banana, apple, papaya, and nanny are just a few examples. On the other hand, many words have two morphemes and only one syllable; examples include cats, runs, and barked. Definitions morpheme: a combination of sounds that have a meaning. A morpheme does not necessarily have to be a word. Example: the word cats has two morphemes. Cat is a morpheme, and s is a morpheme. Every morpheme is either a base or an affix. An affix can be either a prefix or a suffix. Cat is the base morpheme, and s is a suffix. affix: a morpheme that comes at the beginning (prefix) or the ending (suffix) of a base morpheme. Note: An affix usually is a morpheme that cannot stand alone. Examples: -ful, -ly, -ity, -ness. A few exceptions are able, like, and less. base: a morpheme that gives a word its meaning. The base morpheme cat gives the word cats its meaning: a particular type of animal. prefix: an affix that comes before a base morpheme. The in in the word inspect is a prefix. suffix: an affix that comes after a base morpheme. -

From Phoneme to Morpheme Author(S): Zellig S
Linguistic Society of America From Phoneme to Morpheme Author(s): Zellig S. Harris Source: Language, Vol. 31, No. 2 (Apr. - Jun., 1955), pp. 190-222 Published by: Linguistic Society of America Stable URL: http://www.jstor.org/stable/411036 Accessed: 09/02/2009 08:03 Your use of the JSTOR archive indicates your acceptance of JSTOR's Terms and Conditions of Use, available at http://www.jstor.org/page/info/about/policies/terms.jsp. JSTOR's Terms and Conditions of Use provides, in part, that unless you have obtained prior permission, you may not download an entire issue of a journal or multiple copies of articles, and you may use content in the JSTOR archive only for your personal, non-commercial use. Please contact the publisher regarding any further use of this work. Publisher contact information may be obtained at http://www.jstor.org/action/showPublisher?publisherCode=lsa. Each copy of any part of a JSTOR transmission must contain the same copyright notice that appears on the screen or printed page of such transmission. JSTOR is a not-for-profit organization founded in 1995 to build trusted digital archives for scholarship. We work with the scholarly community to preserve their work and the materials they rely upon, and to build a common research platform that promotes the discovery and use of these resources. For more information about JSTOR, please contact [email protected]. Linguistic Society of America is collaborating with JSTOR to digitize, preserve and extend access to Language. http://www.jstor.org FROM PHONEME TO MORPHEME ZELLIG S. HARRIS University of Pennsylvania 0.1. -

Streven. Jaargang 11
Streven. Jaargang 11 bron Streven. Jaargang 11. F. De Raedemaeker, Antwerpen 1943-1944 Zie voor verantwoording: http://www.dbnl.org/tekst/_str007194301_01/colofon.php © 2014 dbnl 1 [Nummer 1] De pauselijke wereldbrief over het mystisch lichaam van Christus(1) door Prof. Mag. E. Druwe S.J. Deze heerlijke brief over onze eenheid in Christus dankt zijn ontstaan, zooals we uit de inleiding kunnen opmaken, aan het schrijnend gevoelde kontrast tusschen de tegenwoordige verscheurdheid der volkeren, in een moordenden oorlog, en de verheven eenheid, die Christus onder alle menschen wil verwezenlijkt zien in zijn Kerk. Zoo innig als de band is, die in ieder van ons alle ledematen van ons lichaam tot één menschelijk organisme samenbindt, moet ook de band zijn, die de menschen van alle kleuren en rassen, van alle volkeren en naties, samensnoert tot het ééne mystisch Lichaam van Christus. Het mystisch Lichaam van Christus! Voor vele lezers klinkt die uitdrukking wellicht nieuw, of roept maar zeer vage denkbeelden op. De leer daardoor aangeduid is nochtans zoo oud als de Kerk. Reeds de H. Paulus hield haar in zijn brieven meermaals aan de eerste christenen voor. Zoo b.v. schrijft hij aan de Korinthiërs: 'Zooals het lichaam één is, ofschoon het veel leden heeft, en van den anderen kant al de leden van het lichaam, hoe talrijk ook, één lichaam vormen, zoo ook Christus. Allen toch, joden of heidenen, slaven of vrijen, allen zijn we in één Geest tot één lichaam gedoopt, en allen zijn we met één Geest gedrenkt. Want ook het lichaam bestaat niet uit één lid, maar uit meerdere leden. -
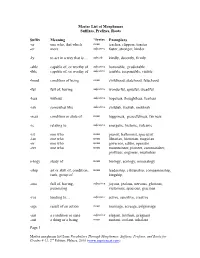
Morpheme Master List
Master List of Morphemes Suffixes, Prefixes, Roots Suffix Meaning *Syntax Exemplars -er one who, that which noun teacher, clippers, toaster -er more adjective faster, stronger, kinder -ly to act in a way that is… adverb kindly, decently, firmly -able capable of, or worthy of adjective honorable, predictable -ible capable of, or worthy of adjective terrible, responsible, visible -hood condition of being noun childhood, statehood, falsehood -ful full of, having adjective wonderful, spiteful, dreadful -less without adjective hopeless, thoughtless, fearless -ish somewhat like adjective childish, foolish, snobbish -ness condition or state of noun happiness, peacefulness, fairness -ic relating to adjective energetic, historic, volcanic -ist one who noun pianist, balloonist, specialist -ian one who noun librarian, historian, magician -or one who noun governor, editor, operator -eer one who noun mountaineer, pioneer, commandeer, profiteer, engineer, musketeer o-logy study of noun biology, ecology, mineralogy -ship art or skill of, condition, noun leadership, citizenship, companionship, rank, group of kingship -ous full of, having, adjective joyous, jealous, nervous, glorious, possessing victorious, spacious, gracious -ive tending to… adjective active, sensitive, creative -age result of an action noun marriage, acreage, pilgrimage -ant a condition or state adjective elegant, brilliant, pregnant -ant a thing or a being noun mutant, coolant, inhalant Page 1 Master morpheme list from Vocabulary Through Morphemes: Suffixes, Prefixes, and Roots for -

Générales Du Royaume Archives Géné Inventaire Des Archives Du Des Archives Inventaire
I 25 ARCHIVES GÉNÉRALES DU ROYAUME 2 I 25 AAGR 2 rchives généDÉPÔT JrOSEPHales CUVELIER N E duRANSS Royaume F Inventaire des archives du et Jérôme E Séquestre de la Brüsseler Treuhandgesellschaft et du Groupe 12 BB U TR y compris les archives du ‘Service Belgique’ de S R Filip yaumeol’Officey A deraumech Politiqueiv colonialees géné du NSDAP rales néralesFILIP STRUBBE du ET JÉRÔME F RANSSENRoyaum rchives gé générales du Royaume Archives géné Inventaire des archives du des archives Inventaire 5369 nérales du R Séquestre de la Brüsseler Treuhandgesellschaft et du Groupe 12 et du Groupe de la Brüsseler Treuhandgesellschaft Séquestre ISBN 978-90-5746-715-8 rchives générales du Royau Illustration de couverture : “Dossiers provenant du Groupe 12”. coloniale du NSDAP de Politique de l’Office du ‘Service Belgique’ les archives y compris 9789057467158 Archives gé INVENTAIRE DES ARCHIVES DU SÉQUESTRE DE LA BRÜSSELER TREUHANDGESELLSCHAFT ET DU GROUPE 12 Y COMPRIS LES ARCHIVES DU 'SERVICE BELGIQUE' DE L'OFFICE DE POLITIQUE COLONIALE DU NSDAP 1899-1988 (PRINCIPALEMENT 1940-1963) ARCHIVES GÉNÉRALES DU ROYAUME 2 DÉPÔT JOSEPH CUVELIER INVENTAIRES 25 Naamsvermelding - Niet Commercieel - Geen Afgeleide Werken CC BY-NC-ND http://creativecommons.org/licenses/by-nc-nd/3.0/nl/ Attribution - Pas d’Utilisation Commerciale - Pas de Modification CC BY-NC-ND http://creativecommons.org/licenses/by-nc-nd/3.0/fr/ ISBN : 978 90 5746 715 8 Archives générales du Royaume D/2014/531/062 Numéro de commande: Publ. 5369 Archives générales du Royaume 2 rue de Ruysbroeck 1000 Bruxelles La liste complète de nos publications peut être obtenue gratuitement sur simple demande ([email protected]) et est également consultable sur notre page électronique (http://arch.arch.be).