Modeling Morpheme Meanings with Compositional Distributional Semantics
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Lexical Semantics I
Semantic Theory: Lexical Semantics I Summer 2007 M.Pinkal/ S. Thater • 03-07-07 Lecture: Lexical Semantics I • 05-07-07 Lecture: Lexical Semantics II • 10-07-07 Lecture: Everything else • 12-07-07 Exercise: lexical Semantics • 17-07-07 Question time, Sample exam • 19-07-07 Individual question time • 25-07-07 Final exam, 11:00 (s.t.) Semantic Theory, SS 2007 © M. Pinkal, S. Thater 2 Structure of this course • Sentence semantics • Discourse semantics • Lexical semantics Semantic Theory, SS 2007 © M. Pinkal, S. Thater 3 Dolphins in First-order Logic Dolphins are mammals, not fish. !d (dolphin'(d)"mammal'(d) #¬fish'(d)) Dolphins live-in pods. !d (dolphin'(d)" $x (pod'(p)live-in'(d,p)) Dolphins give birth to one baby at a time. !d (dolphin'(d)" !x !y !t (give-birth-to' (d,x,t)give-birth-to' (d,y,t) " x=y) Semantic Theory, SS 2007 © M. Pinkal, S. Thater 4 Dolphins in First-order Logic Dolphins are mammals, not fish. !d (dolphin'(d)"mammal'(d) #¬fish'(d)) Dolphins live-in pods. !d (dolphin'(d)" $x (pod'(p)live-in'(d,p)) Dolphins give birth to one baby at a time. !d (dolphin'(d)" !x !y !t (give-birth-to' (d,x,t)give-birth-to' (d,y,t) " x=y) Semantic Theory, SS 2007 © M. Pinkal, S. Thater 5 The dolphin text Dolphins are mammals, not fish. They are warm blooded like man, and give birth to one baby called a calf at a time. At birth a bottlenose dolphin calf is about 90-130 cms long and will grow to approx. -

LEXADV - a Multilingual Semantic Lexicon for Adverbs
LEXADV - a multilingual semantic Lexicon for Adverbs Sanni Nimb Center for Sprogteknologi (CST) – Københavns Universitet Njalsgade 80, Copenhagen, Denmark [email protected] Abstract The LEXADV-project is a Scandinavian research project (2004-2006, financed by Nordplus Sprog) with the aim of extending three Scandinavian semantic lexicons building on the SIMPLE lexicon model (Lenci et al., 2000) with the word class of adverbs. In the lexicons of approx. 400 Danish, Norwegian and Swedish adverbs the different senses are described with a semantic type and a set of semantic features. A classification covering the many meanings that adverbs can have has been established and integrated in the original SIMPLE ontology. Similarly new features have been added to the model in order to describe the adverb senses. The working method of the project builds on the fact that the vocabularies of Danish, Norwegian and Swedish are closely related. An encoding tool has been developed with the special purpose of permitting easy transfer of semantic types and features between entries in the three languages. The Danish adverb senses have been described first, based on the definition in a modern, comprehensive Danish dictionary. Afterwards the lemmas have been translated and the semantic data have been copied into the Swedish as well as into the Norwegian equivalent entry. Finally these copies have been evaluated and when necessary adjusted by native speakers. ’Telic’, ’Agentive’ and ’Constitutive’ has been extended 1. The Scandinavian SIMPLE Lexicons with three more semantic types. The first one, ’Functional’, covers adverb senses of 1.1. Background which the meaning must be described by logic expressions referring to sets, either in the context or in The Danish and the Swedish SIMPLE lexicons are the discourse. -

A New Semantic Lexicon and Similarity Measure in Bangla
A New Semantic Lexicon and Similarity Measure in Bangla Manjira Sinha, Abhik Jana, Tirthankar Dasgupta, Anupam Basu Indian Institute of Technology Kharagpur {manjira87, abhikjana1, iamtirthankar, anupambas}@gmail.com ABSTRACT The Mental Lexicon (ML) refers to the organization of lexical entries of a language in the human mind.A clear knowledge of the structure of ML will help us to understand how the human brain processes language. The knowledge of semantic association among the words in ML is essential to many applications. Although, there are works on the representation of lexical entries based on their semantic association in the form of a lexicon in English and other languages, such works of Bangla is in a nascent stage. In this paper, we have proposed a distinct lexical organization based on semantic association between Bangla words which can be accessed efficiently by different applications. We have developed a novel approach of measuring the semantic similarity between words and verified it against user study. Further, a GUI has been designed for easy and efficient access. KEYWORDS : Bangla Lexicon, Synset, Semantic Similarity, Hierarchical Graph 1 Introduction The lexicon of a language is a collection of lexical entries consisting of information regarding words and expressions, comprising both form and meaning (Levelt,). Form refers to the orthography, phonology and morphology of the lexical item and Meaning refers to its syntactic and semantic information. The term Mental Lexicon refers to the organization and interaction of lexical entries of a language in the human mind. Depending on the definition of word , an adult knows and uses around 40000 to 150000 words. -

The Diachronic Semantic Lexicon of Dutch As Linked Open Data
The Diachronic Semantic Lexicon of Dutch as Linked Open Data Katrien Depuydt, Jesse de Does Instituut voor de Nederlandse Taal Rapenburg 61, 2311GJ Leiden, The Netherlands [email protected], [email protected] Abstract This paper describes the Linked Open Data (LOD) model for the diachronic semantic lexicon DiaMaNT, currently under development at the Instituut voor de Nederlandse Taal (INT; Dutch Language Institute). The lexicon is part of a digital historical language infrastructure for Dutch at INT. This infrastructure, for which the core data is formed by the four major historical dictionaries of Dutch covering Dutch language from ca. 500 - ca 1976, currently consists of three modules: a dictionary portal, giving access to the historical dictionaries, a computational lexicon GiGaNT, providing information on words, their inflectional and spelling variation, and DiaMaNT, aimed at providing information on diachronic lexical variation (both semasiological and onomasiological). The DiaMaNT lexicon is built by adding a semantic layer to the word form lexicon GiGaNT, using the semantic information in the historical dictionaries. Ontolex-Lemon is a good point of departure for the LOD model, but we need extensions to be able to deal with the historical dictionary content incorporated in our lexicon. Keywords: Linked Open Data, Ontolex, Diachronic Lexicon, Semantic Lexicon, Historical Lexicography, Language Resources 1. Background digital, based on a closed corpus, in digital format. Hav- Even though Dutch lexicography1 can be dated back to the ing four scholarly dictionaries of Dutch in digital format 13th century with the glossarium Bernense, a Latin-Middle opened up opportunities for further exploitation of the con- Dutch word list, we had to wait until the 19th century for tents of these dictionaries. -

Natural Language Processing
Chowdhury, G. (2003) Natural language processing. Annual Review of Information Science and Technology, 37. pp. 51-89. ISSN 0066-4200 http://eprints.cdlr.strath.ac.uk/2611/ This is an author-produced version of a paper published in The Annual Review of Information Science and Technology ISSN 0066-4200 . This version has been peer-reviewed, but does not include the final publisher proof corrections, published layout, or pagination. Strathprints is designed to allow users to access the research output of the University of Strathclyde. Copyright © and Moral Rights for the papers on this site are retained by the individual authors and/or other copyright owners. Users may download and/or print one copy of any article(s) in Strathprints to facilitate their private study or for non-commercial research. You may not engage in further distribution of the material or use it for any profitmaking activities or any commercial gain. You may freely distribute the url (http://eprints.cdlr.strath.ac.uk) of the Strathprints website. Any correspondence concerning this service should be sent to The Strathprints Administrator: [email protected] Natural Language Processing Gobinda G. Chowdhury Dept. of Computer and Information Sciences University of Strathclyde, Glasgow G1 1XH, UK e-mail: [email protected] Introduction Natural Language Processing (NLP) is an area of research and application that explores how computers can be used to understand and manipulate natural language text or speech to do useful things. NLP researchers aim to gather knowledge on how human beings understand and use language so that appropriate tools and techniques can be developed to make computer systems understand and manipulate natural languages to perform the desired tasks. -

12 Morphology and Lexical Semantics
248 Beth Levin and Malka Rappaport Hovav 12 Morphology and Lexical Semantics BETH LEVIN AND MALKA RAPPAPORT HOVAV The relation between lexical semantics and morphology has not been the subject of much study. This may seem surprising, since a morpheme is often viewed as a minimal Saussurean sign relating form and meaning: it is a concept with a phonologically composed name. On this view, morphology has both a semantic side and a structural side, the latter sometimes called “morphological realization” (Aronoff 1994, Zwicky 1986b). Since morphology is the study of the structure and derivation of complex signs, attention could be focused on the semantic side (the composition of complex concepts) and the structural side (the composition of the complex names for the concepts) and the relation between them. In fact, recent work in morphology has been concerned almost exclusively with the composition of complex names for concepts – that is, with the struc- tural side of morphology. This dissociation of “form” from “meaning” was foreshadowed by Aronoff’s (1976) demonstration that morphemes are not necessarily associated with a constant meaning – or any meaning at all – and that their nature is basically structural. Although in early generative treat- ments of word formation, semantic operations accompanied formal morpho- logical operations (as in Aronoff’s Word Formation Rules), many subsequent generative theories of morphology, following Lieber (1980), explicitly dissoci- ate the lexical semantic operations of composition from the formal structural -

Studies in the Linguistic Sciences
UNIVERSITY OF ILLINOIS Llb'RARY AT URBANA-CHAMPAIGN MODERN LANGUAGE NOTICE: Return or renew all Library Materialsl The Minimum Fee (or each Lost Book is $50.00. The person charging this material is responsible for its return to the library from which it was withdrawn on or before the Latest Date stamped below. Theft, mutilation, and underlining of books are reasons for discipli- nary action and may result in dismissal from the University. To renew call Telephone Center, 333-8400 UNIVERSITY OF ILLINOIS LIBRARY AT URBANA-CHAMPAIGN ModeriJLanp & Lb Library ^rn 425 333-0076 L161—O-I096 Che Linguistic Sciences PAPERS IN GENERAL LINGUISTICS ANTHONY BRITTI Quantifier Repositioning SUSAN MEREDITH BURT Remarks on German Nominalization CHIN-CHUAN CHENG AND CHARLES KISSEBERTH Ikorovere Makua Tonology (Part 1) PETER COLE AND GABRIELLA HERMON Subject to Object Raising in an Est Framework: Evidence from Quechua RICHARD CURETON The Inclusion Constraint: Description and Explanation ALICE DAVISON Some Mysteries of Subordination CHARLES A. FERGUSON AND APIA DIL The Sociolinguistic Valiable (s) in Bengali: A Sound Change in Progress GABRIELLA HERMON Rule Ordering Versus Globality: Evidencefrom the Inversion Construction CHIN-W. KIM Neutralization in Korean Revisited DAVID ODDEN Principles of Stress Assignment: A Crosslinguistic View PAULA CHEN ROHRBACH The Acquisition of Chinese by Adult English Speakers: An Error Analysis MAURICE K.S. WONG Origin of the High Rising Changed Tone in Cantonese SORANEE WONGBIASAJ On the Passive in Thai Department of Linguistics University of Illinois^-^ STUDIES IN THE LINGUISTIC SCIENCES PUBLICATION OF THE DEPARTMENT OF LINGUISTICS UNIVERSITY OF ILLINOIS AT URBANA-CHAMPAIGN EDITORS: Charles W. Kisseberth, Braj B. -

WORD ORDER and W O R D ORDER Chatjge
Linguistics WORD ORDER AND WORD ORDER CHAtjGE The University of Texas Press Austin 1975 REVIEWED BY JAMES M. DUNN Princeton Unlversi ty This is a collection of twelve of the thirteen papers pre- sented at the Conference on Word Order and dord Order Change that was held at tne University of California, Santa Barbara, on January 26 - 27, 1974. The first eight deal with the diachk'onic aspect of word order, while the other four represent a synchronic treatment of the subject. In the preface the editor acknowledges the influence of Joseph Greenberg on these proceedings. Bis 1961 paper, Some universals of grammar with particular reference to the order of meaningful elements' , is seen as ' the starting point* for mos't of the papers in this volume. The papers in this collection appeal to a great diversity of interests r sign language, languages of the Niger-Congo group, Chinese, Indo-European, drift, discourse grammar, rnetatheory, the evaluation me-tric, and, of course, language typology. Obviously, their common purpose is to move toward a clearer ex- planation of the causal relationships between the surface con- stituents of a sentence both synch~onicdllyand diachronically. 54 But many of the papers actually share more than the commom denom- inator of interest in word order. At several points where other mutual interests overlap, the discussions assume the nature of a dialog (or, more often, a debate), and the reader finds transi- tion from paper to paper relatively smooth. I shall withhold further comment on the merits of this book as a whole until the conclusion of this review. -

Morphemes by Kirsten Mills Student, University of North Carolina at Pembroke, 1998
Morphemes by Kirsten Mills http://www.uncp.edu/home/canada/work/caneng/morpheme.htm Student, University of North Carolina at Pembroke, 1998 Introduction Morphemes are what make up words. Often, morphemes are thought of as words but that is not always true. Some single morphemes are words while other words have two or more morphemes within them. Morphemes are also thought of as syllables but this is incorrect. Many words have two or more syllables but only one morpheme. Banana, apple, papaya, and nanny are just a few examples. On the other hand, many words have two morphemes and only one syllable; examples include cats, runs, and barked. Definitions morpheme: a combination of sounds that have a meaning. A morpheme does not necessarily have to be a word. Example: the word cats has two morphemes. Cat is a morpheme, and s is a morpheme. Every morpheme is either a base or an affix. An affix can be either a prefix or a suffix. Cat is the base morpheme, and s is a suffix. affix: a morpheme that comes at the beginning (prefix) or the ending (suffix) of a base morpheme. Note: An affix usually is a morpheme that cannot stand alone. Examples: -ful, -ly, -ity, -ness. A few exceptions are able, like, and less. base: a morpheme that gives a word its meaning. The base morpheme cat gives the word cats its meaning: a particular type of animal. prefix: an affix that comes before a base morpheme. The in in the word inspect is a prefix. suffix: an affix that comes after a base morpheme. -

Linking Wordnet to the SIL Semantic Domains
Bringing together over- and under-represented languages: Linking Wordnet to the SIL Semantic Domains Muhammad Zulhelmy bin Mohd Rosman Francis Bond and Frantisekˇ Kratochv´ıl Linguistics and Multilingual Studies, Nanyang Technological University, Singapore [email protected], [email protected], [email protected] Abstract English, Japanese and Finnish (Bond and Paik, 2012). We have created an open-source mapping SD is designed for rapid construction and in- between the SIL’s semantic domains (used tuitive organization of lexicons, not primarily for for rapid lexicon building and organiza- the analysis of the resulting data. As a result, tion for under-resourced languages) and many potentially interesting relationships are only WordNet, the standard resource for lexical implicitly realized. By linking SD to WN we semantics in natural language processing. can take advantage of the relationships modeled in We show that the resources complement WN to make more of these explicit. For example, each other, and suggest ways in which the the semantic relations in WN would be a useful mapping can be improved even further. input into SD while the domains hierarchy would The semantic domains give more general enforce the existing WN relations. This will al- domain and associative links, which word- low more quantitative computational modeling of net still has few of, while wordnet gives under-resourced languages. explicit semantic relations between senses, It is currently an exciting time for field lexicog- which the domains lack. raphy with better tools and hardware allowing for rapid digitization of lexical resources. Typically, 1 Introduction linguists tag text soon after they collect it. -

From Phoneme to Morpheme Author(S): Zellig S
Linguistic Society of America From Phoneme to Morpheme Author(s): Zellig S. Harris Source: Language, Vol. 31, No. 2 (Apr. - Jun., 1955), pp. 190-222 Published by: Linguistic Society of America Stable URL: http://www.jstor.org/stable/411036 Accessed: 09/02/2009 08:03 Your use of the JSTOR archive indicates your acceptance of JSTOR's Terms and Conditions of Use, available at http://www.jstor.org/page/info/about/policies/terms.jsp. JSTOR's Terms and Conditions of Use provides, in part, that unless you have obtained prior permission, you may not download an entire issue of a journal or multiple copies of articles, and you may use content in the JSTOR archive only for your personal, non-commercial use. Please contact the publisher regarding any further use of this work. Publisher contact information may be obtained at http://www.jstor.org/action/showPublisher?publisherCode=lsa. Each copy of any part of a JSTOR transmission must contain the same copyright notice that appears on the screen or printed page of such transmission. JSTOR is a not-for-profit organization founded in 1995 to build trusted digital archives for scholarship. We work with the scholarly community to preserve their work and the materials they rely upon, and to build a common research platform that promotes the discovery and use of these resources. For more information about JSTOR, please contact [email protected]. Linguistic Society of America is collaborating with JSTOR to digitize, preserve and extend access to Language. http://www.jstor.org FROM PHONEME TO MORPHEME ZELLIG S. HARRIS University of Pennsylvania 0.1. -
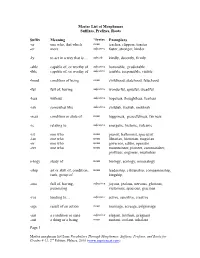
Morpheme Master List
Master List of Morphemes Suffixes, Prefixes, Roots Suffix Meaning *Syntax Exemplars -er one who, that which noun teacher, clippers, toaster -er more adjective faster, stronger, kinder -ly to act in a way that is… adverb kindly, decently, firmly -able capable of, or worthy of adjective honorable, predictable -ible capable of, or worthy of adjective terrible, responsible, visible -hood condition of being noun childhood, statehood, falsehood -ful full of, having adjective wonderful, spiteful, dreadful -less without adjective hopeless, thoughtless, fearless -ish somewhat like adjective childish, foolish, snobbish -ness condition or state of noun happiness, peacefulness, fairness -ic relating to adjective energetic, historic, volcanic -ist one who noun pianist, balloonist, specialist -ian one who noun librarian, historian, magician -or one who noun governor, editor, operator -eer one who noun mountaineer, pioneer, commandeer, profiteer, engineer, musketeer o-logy study of noun biology, ecology, mineralogy -ship art or skill of, condition, noun leadership, citizenship, companionship, rank, group of kingship -ous full of, having, adjective joyous, jealous, nervous, glorious, possessing victorious, spacious, gracious -ive tending to… adjective active, sensitive, creative -age result of an action noun marriage, acreage, pilgrimage -ant a condition or state adjective elegant, brilliant, pregnant -ant a thing or a being noun mutant, coolant, inhalant Page 1 Master morpheme list from Vocabulary Through Morphemes: Suffixes, Prefixes, and Roots for