Caverphone Revisited
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Public Notices & the Courts
PUBLIC NOTICES B1 DAILY BUSINESS REVIEW TUESDAY, SEPTEMBER 28, 2021 dailybusinessreview.com & THE COURTS BROWARD PUBLIC NOTICES BUSINESS LEADS THE COURTS WEB SEARCH FORECLOSURE NOTICES: Notices of Action, NEW CASES FILED: US District Court, circuit court, EMERGENCY JUDGES: Listing of emergency judges Search our extensive database of public notices for Notices of Sale, Tax Deeds B5 family civil and probate cases B2 on duty at night and on weekends in civil, probate, FREE. Search for past, present and future notices in criminal, juvenile circuit and county courts. Also duty Miami-Dade, Broward and Palm Beach. SALES: Auto, warehouse items and other BUSINESS TAX RECEIPTS (OCCUPATIONAL Magistrate and Federal Court Judges B14 properties for sale B8 LICENSES): Names, addresses, phone numbers Simply visit: CALENDARS: Suspensions in Miami-Dade, Broward, FICTITIOUS NAMES: Notices of intent and type of business of those who have received https://www.law.com/dailybusinessreview/public-notices/ and Palm Beach. Confirmation of judges’ daily motion to register business licenses B3 calendars in Miami-Dade B14 To search foreclosure sales by sale date visit: MARRIAGE LICENSES: Name, date of birth and city FAMILY MATTERS: Marriage dissolutions, adoptions, https://www.law.com/dailybusinessreview/foreclosures/ DIRECTORIES: Addresses, telephone numbers, and termination of parental rights B8 of those issued marriage licenses B3 names, and contact information for circuit and CREDIT INFORMATION: Liens filed against PROBATE NOTICES: Notices to Creditors, county -

UNITED STATES DISTRICT COURT for the ______District District of Columbia of ______
Case 1:12-cr-00149-JEB Document 1 Filed 05/07/10 Page 1 of 1 AO 91 (Rev. 08/09) Criminal Complaint UNITED STATES DISTRICT COURT for the __________ District District of Columbia of __________ United States of America ) v. ) ) Case No. ) ) Carline M. Charles ) Defendant(s) CRIMINAL COMPLAINT I, the complainant in this case, state that the following is true to the best of my knowledge and belief. On or about the date(s) ofApril 2005 and August 2007 in the county of Washington, D.C. in the District ofColumbia & elsewhere , the defendant(s) violated: Code Section Offense Description 18 U.S.C. Section 1341 Mail Fraud 18 U.S.C. Section 1343 Wire Fraud 18 U.S.C. Section 2(b) Causing an Act to be Done This criminal complaint is based on these facts: SEE ATTACHED AFFIDAVIT ✔ Continued on the attached sheet. Complainant’s signature Mary E. Soudrette, Special Agent Printed name and title Sworn to before me and signed in my presence. Date: 05/07/2010 Judge’s signature City and state: Washington, D.C. United States Magistrate Judge Printed name and title Case 1:12-cr-00149-JEB Document 1-1 Filed 05/07/10 Page 1 of 17 AFFIDAVIT IN SUPPORT OF CRIMINAL COMPLAINT AND ARREST WARRANT I, MARY E. SOUDRETTE (hereinafter “affiant”), a Special Agent with the Federal Bureau of Investigation (hereinafter “FBI”), having been duly sworn, hereby depose and state as follows: I. OBJECTIVE This affidavit is presented in support of a criminal complaint against and an arrest warrant for Carline Marie Charles (hereinafter “CHARLES”) charging her with wire and mail fraud in violation of 18 U.S.C. -

Oregon Obituaries II
Oregon Obituaries II GFO Members may view this collection in MemberSpace > Digital Collections > Indexed Images > Oregon Obituaries II. Non-members may order a copy at GFO.org > Resources > Indexes > All Indexes > Oregon Obituaries II Newspaper Newspaper Surname Given Name Article Type Comments Scan # Article Date Title City Aaben Alide Funeral notice Aaben Alide 1992 1992 (NG) (NG) Aamodt Edwin D Obituary Clarke M4 (7) 1994 Statesman Journal Salem Aasby Jerry G Obituary Clarke M4 (19) 1993 Statesman Journal Salem Abacherli Zeno Anton Obituary Clarke M4 (6) 1994 Statesman Journal Salem Abell Rowena Marie Obituary Clarke M4 (12) 1993 Statesman Journal Salem Absten Leila Heinz Obituary Clarke M4 (17) 1990 Statesman Journal Salem Absten Margaret Middleton Obituary Clarke M4 (9) 1994 Statesman Journal Salem Acevedo Pedro Vasquez Obituary Acevedo Pedro 1999 1999 (NG) (NG) Ackerson Jean L Obituary Clarke M4 (14) 1994 Statesman Journal Salem Adair Laverne Obituary Clarke M4 (18) 1996 Statesman Journal Salem Adams Anna G Obituary Clarke M4 (4) 1993 Statesman Journal Salem Adams Beatrice M Obituary Adams Beatrice 1992 1992 (NG) (NG) Adams Daisy Irene Obituary Clarke M4 (7) 1996 Statesman Journal Salem Adams Edward Obituary Clarke M4 (1) 1994 Statesman Journal Salem Adams Ella Lee Obituary Clarke M4 (4) 1995 Statesman Journal Salem Adams Gladys Obituary Clarke M4 (11) 1993 Statesman Journal Salem Adams Joseph Z Obituary Adams Joseph 1993 1993 (NG) (NG) Adams Joyce Elaine Obituary Clarke M4 (10) 1993 Statesman Journal Salem Adams Juanita V Obituary -
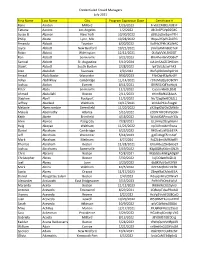
Credentialed Crowd Managers July 2021 First Name Last
Credentialed Crowd Managers July 2021 First Name Last Name City Program Expiration Date Certificate # Rano Aarden Milford 1/26/2023 FrvbECM3ELNUErF Tatiana Aarons Los Angeles 1/2/2022 J8r2x6PSVpDZGKC Susan B. Abanor New York 10/30/2022 s8lELzyDw2qmPTH Philip Abate Lynn, MA 10/28/2022 WqaslYQvPLZk07G Amanda Abbott Taunton 6/20/2022 Ka9Hs2Pkh1KUNAC Joyce Abbott New Bedford 10/21/2021 zVHllaFMm8dCTeK Robin Abbott Wilmington 12/12/2021 0fz5pVVXLSI60OT Ron Abbott Somerville 9/22/2023 8hk4henBxVDbBv7 Samuel Abbott St. Augustine 5/10/2024 xiA1mSAdZE0HG4m Stuart Abbott South Boston 2/28/2022 lpY1blLJbzwFhK3 Alan Abdallah Swansea 2/9/2022 WxFq0DJ9mPqGHof Amaal Abdelkader Worcester 9/30/2023 FYtrOqHF3pfkzOY Adiya Abdilkhay Cambridge 11/14/2021 r97oMqQly3OBcNY Joshua Abdon Everett 8/11/2021 8VW51lQEYwhliyk Peter Abdu Somerville 11/2/2022 Cuaserkl6OLDbIZ Ahmed Abdullahi Boston 2/11/2023 tHImRAfKLS8JsxA Stephen Abell Rockport 11/5/2023 NoT2agXeKIOBZL1 Jeffrey Abellard Waltham 10/17/2021 eCG3eP61sFxog9l Melanie Abercrombie Greenfield 11/20/2022 aY2bpJ0WOsCMN0v Makyla Abernathy Atlanta 5/15/2022 cODN7RFDYaYpDcH Keith Abete Brimfield 4/18/2022 Wxh4f0APmovh33s Alvin Abinas Pasig City 7/28/2021 ULzHHuZOsydr6mI Haig Aboyan Waltham 11/26/2022 np3UfnoLfzH5wca Daniel Abraham Cambridge 6/25/2022 9HDvxEuWGiLiE7A Jeff Abraham Worcester 5/14/2023 gj0TzUxgE5rmA9F Mark Abraham Methuen 4/7/2024 FxZZL4mXMf6JwRY Thomas Abraham Reston 11/28/2021 EVLm0eLZSHSmsq9 Joshua Abrahams Somerville 5/19/2022 Kdp8QRqKtAmGN2h Chris Abrams Boston 10/8/2021 MSbGbeMkEgADg9P Christopher -

Annex 2 USAID South Sudan Gender Based Violence Prevention And
USAID/SOUTH SUDAN GENDER-BASED VIOLENCE PREVENTION AND RESPONSE ROADMAP SEPTEMBER 2019 Contract No.: AID-OAA-TO-17-00018 September 26, 2019 This publication was produced for review by the United States Agency for International Development. It was prepared by Banyan Global. Contract No.: AID-OAA-TO-17-00018 Submitted to: USAID/South Sudan DISCLAIMER The authors’ views expressed in this publication do not necessarily reflect the views of the United States Agency for International Development (USAID) or the United States Government. Recommended Citation: Gardsbane, Diane and Aluel Atem. USAID/South Sudan Gender-Based Violence Prevention and Response Roadmap. Prepared by Banyan Global. 2019. Cover photo credit: USAID Back Cover photo credit: USAID USAID/SOUTH SUDAN GENDER- BASED VIOLENCE PREVENTION AND RESPONSE ROADMAP SEPTEMBER 2019 Contract No.: AID-OAA-TO-17-00018 4 USAID/SOUTH SUDAN GENDER-BASED VIOLENCE PREVENTION AND RESPONSE ROADMAP CONTENTS 1. INTRODUCTION 9 1.1 ROADMAP OBJECTIVE 9 1.2 STRUCTURE OF ROADMAP 9 2. INTEGRATING GBV IN THE USAID/SOUTH SUDAN OPERATIONAL FRAMEWORK 11 2.1 THEORY OF CHANGE 11 2.2 INTEGRATING THE THEORY OF CHANGE INTO THE USAID/SOUTH SUDAN OPERATIONAL FRAMEWORK 12 3. GBV PREVENTION AND RESPONSE ROADMAP PROGRAMMATIC GUIDING PRINCIPLES 19 4. BRINGING IT ALL TOGETHER – GBV PREVENTION, MITIGATION AND RESPONSE ROADMAP 27 5. GUIDELINES TO ADDRESS GBV IN MONITORING, EVALUATION AND LEARNING 39 6. KEY RESOURCES 41 ANNEX A: GBV PREVENTION AND RESPONSE ROADMAP LITERATURE REVIEW 57 ANNEX B: PROGRAM AND DONOR REPORT 73 ANNEX C: GBV LITERACY TRAINING 95 ANNEX D: LIST OF KEY DOCUMENTS CONSULTED 99 ANNEX E. -

Ix. Omb Contributors to the 1998 Budget
IX. OMB CONTRIBUTORS TO THE 1998 BUDGET 341 OMB CONTRIBUTORS TO THE 1998 BUDGET The following personnel contributed to the preparation of this publication. Hundreds, perhaps thousands, of others throughout the Government also deserve credit for their valuable contributions. A Donald P. Bradford Elizabeth Cowan Adrienne C. Erbach James Bradford, Jr. Michael F. Crowley Frank Esposito Rein Abel Betty I. Bradshaw James C. Crutchfield Jim R. Esquea Andrew Abrams Nancy Brandel Rebecca Culberson Margaret Evans David S. Adams Denise M. Bray William P. Curtis Suzann K. Evinger Gordon Adams Jonathan D. Breul Margaret Cvrkel Rowe Ewell Marsha D. Adams Anna M. Briatico Quincy Ewing III Gordon P. Agress Edward A. Brigham D Allison H. Eydt Steven D. Aitken Allan E. Brown Susan Alesi James A. Brown Josie R. Dade F Richard M. Allen Thomas M. Brown Rosemarie W. Dale Lois E. Altoft Paul Bugg Philip R. Dame Timothy R. Fain Barry B. Anderson Ann M. Burget Robert G. Damus Chris Fairhall Robert B. Anderson John D. Burnim J. Michael Daniel Lisa B. Fairhall Kenneth S. Apfel Caroline B. Davis Robert S. Fairweather Donald R. Arbuckle C Jozelyn Davis Jeffrey A. Farkas John B. Arthur Peter O. Davis Evan T. Farley Jeffrey H. Ashford Philip T. Calbos Lorraine Day William R. Feezle Renee Austin Susan M. Carr Stacy L. Dean Jack D. Fellows Michael Casella Michael Deich Patricia A. Ferrell B Lester D. Cash Arline P. Dell John W. Fielding Mary I. Cassell Carol R. Dennis Desiree Filippone Paul W. Baker Winifred Y. Chang G. Edward DeSeve Joseph Firschein Jonathan C. -

Dear Graduates, Nova Southeastern University Takes
Dear Graduates, Nova Southeastern University takes enormous pride in your success. On behalf of NSU’s faculty, staff, and Board of Trustees, I salute your academic and personal achievement. You have reached this milestone through hard work and intellectual effort, and we are pleased to recognize your dedication with today’s commencement ceremony. Reflect on the gifts of knowledge and support you have received. Celebrate the friendships, skills, and strengths you have forged. Embrace the opportunity to apply these treasures as you start a new chapter in your life, hopefully, following your passion, not your fortune. Our best wishes are with you today and in the future. Congratulations! George L. Hanbury II, Ph.D. NSU President and CEO CEREMONY SCHEDULE May 16, 2021, at 9:30 a.m. Shepard Broad College of Law May 17, 2021, at 9:30 a.m. All Undergraduate Degrees May 17, 2021, at 3:00 p.m. H. Wayne Huizenga College of Business and Entrepreneurship May 18, 2021, at 9:30 a.m. College of Dental Medicine Dr. Kiran C. Patel College of Allopathic Medicine Dr. Kiran C. Patel College of Osteopathic Medicine College of Psychology May 18, 2021, at 3:00 p.m. College of Optometry College of Pharmacy Ron and Kathy Assaf College of Nursing May 19, 2021, at 9:30 a.m. Abraham S. Fischler College of Education and School of Criminal Justice Halmos College of Arts and Sciences College of Computing and Engineering May 19, 2021, at 3:00 p.m. Dr. Pallavi Patel College of Health Care Sciences 2 CLASS OF 2021 THE ACADEMIC PROCESSION Grand Marshal Degree Candidates Members of the Faculty Members of the Board of Trustees Distinguished Guests University Officials 3 WELCOME TO THE 2021 COMMENCEMENT CEREMONIES for NOVA SOUTHEASTERN UNIVERSITY May 16 to 19, 2021 4 CLASS OF 2021 ORDER OF EXERCISES SHEPARD BROAD COLLEGE OF LAW MAY 16, 2021, AT 9:30 A.M. -

CUNY Baccalaureate for Unique and Interdisciplinary Studies
Greetings from the President May 30, 2018 Dear Graduates: Congratulations! You have reached a most significant milestone in your life. Your hard work, determination, and commitment to your education have been rewarded, and you and your loved ones should take pride in your accomplishments and successes. Hunter College certainly takes pride in you. ' Your Hunter education has prepared you to meet the challenges of a world that is rapidly changing politically, socially, economically, ~ . technologically. As part of the next generation of thoughtful, responsible, and intelligent leacfets;·: you will make a real difference wherever you apply your knowledge and skills. Endless 'Opportunities await you. As you pursue your goals and move forward with your professional and personal lives., please carry with you Hunter's commitment to community, diversity, and service to others. We look forward to hearing great things about you, and we hope you will stay connected to the exciting activities and developments on campus. Please remember Hunter College and know that you will always be part of our family. Best wishes for continued success. Sincerely, ~vi Jennifer J. Raab President Order ofExercises Presiding Jennifer J. Raab, President Eija Ayravainen, Vice President for Student Affairs and Dean ofStudents Opening Ceremony Michael F. Mazzeo, Macaulay Honors College, Bachelor ofArts '18 Processional President's Party and Members of the Faculty Graduates and Candidates for Graduation National Anthem Joanna Malaszczyk, Master ofArts '18 Bagpiper Ian A. Sherman, Doctor ofNursing Practice '18 Greetings William C. Thompson, Jr., Chair, Board ofTrustees of The City University ofNew York Matthew Sapienza, Senior Vice Chancellor and ChiefFinancial Officer of The City University ofNew York ' Charge to the Graduates and Candidates for Graduation President Jennifer J. -
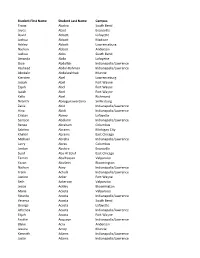
Spring-2018-Deans-List.Pdf
Student First Name Student Last Name Campus Tiwaa Ababio South Bend Joyce Abad Evansville David Abbott Lafayette Joshua Abbott Madison Ashley Abbott Lawrenceburg Nathan Abbott Anderson Joshua Abbs South Bend Amanda Abdo Lafayette Skye Abdullah Indianapolis/Lawrence Rasheed Abdul-Rahman Indianapolis/Lawrence Abobakr Abdulwahhab Muncie Kiersten Abel Lawrenceburg Josiah Abel Fort Wayne Elijah Abel Fort Wayne Isaiah Abel Fort Wayne Kelly Abel Richmond Nilanthi Abeygunawardana Sellersburg Zakia Abid Indianapolis/Lawrence Hina Abidi Indianapolis/Lawrence Cristan Abney Lafayette Samson Abolarin Indianapolis/Lawrence Renee Abraham Columbus Sabrina Abrams Michigan City Khalial Abrams East Chicago Michael Abreha Indianapolis/Lawrence Larry Abreu Columbus Jordan Abshire Evansville Suad Abu Al Zoluf East Chicago Tamim Abulhassan Valparaiso Yazan AbuSeini Bloomington Nathan Acey Indianapolis/Lawrence Frank Achulli Indianapolis/Lawrence Justine Acker Fort Wayne Seth Ackerson Valparaiso Jessie Ackley Bloomington Maria Acosta Valparaiso Ricardo Acosta Indianapolis/Lawrence Yesenia Acosta South Bend George Acosta Lafayette Athenea Acosta Indianapolis/Lawrence Elijah Acosta Fort Wayne Faythe Acquaye Indianapolis/Lawrence Blake Acra Anderson Jessica Acrey Muncie Kenneth Adams Indianapolis/Lawrence Justin Adams Indianapolis/Lawrence Pamela Adams Indianapolis/Lawrence Felicya Adams Indianapolis/Lawrence Hannah Adams Evansville Ariel Adams Bloomington Gunnar Adams Fort Wayne Stevie Adams Terre Haute Cameron Adams Indianapolis/Lawrence Alex Adams South Bend -

List of RN/LPN Required to Complete Fingerprinting by June 30, 2021
List of RN/LPN Required to Complete Fingerprinting by June 30, 2021 RN 74156 ABAD CHARLES U RN 61837 ACASIO KYRA K RN 75958 ADVINCULA ROLAND D J RN 75271 ABAD GLORY GAY M RN 59937 ACCOUSTI NEAL O RN 42910 ADZUARA MARY JANE R RN 76449 ABALOS JUDY S RN 52918 ACEBO RUSSELL J RN 72683 AETO JUSTIN RN 38427 ABALOS TRICIA H M RN 43188 ACEVEDO JUNE D RN 86091 AFONG CLAREN C D RN 70657 ABANES JANE J RN 68208 ACIDERA NORIVIE S RN 72856 AGACID MARIE JOY H RN 46560 ABANIA JONATHAN R RN 59880 ACIO ROSARIO A D RN 78671 AGANOS DAWN Y A V RN 67772 ABARQUEZ BLESSILDA C RN 72528 ACKLIN JUSTIN P RN 85438 AGARAN NOBEMEN O RN 67707 ABATAYO LIEZL P RN 68066 ACOB FERLITA D RN 52928 AGARAN TINA K LPN 7498 ABBEY LORI J RN 35794 ACOBA BETH MARY BARN RN 33999 AGASID GLISERIA D RN 77337 ABE DAVID K RN 73632 ACOBA JULIA R LPN 18148 AGATON KRYSTLE LIAAN RN 57015 ABE JAYSON K RN 53744 ACOPAN MARK N RN 66375 AGBAYANI REYNANTE LPN 6111 ABE LORI R RN 55133 ACOSTA MARISSA R RN 58450 AGCAOILI ANNABEL RN 18300 ABE LYNN Y LPN 18682 ACOSTA MYLEEN G A RN 54002 AGCAOILI FLORENCE A RN 73517 ABE SUN-HWA K RN 69274 ACRE-PICKRELL ALEXAN RN 79169 AGDEPPA MARK J RN 84126 ABE TIFFANY K RN 45793 ACZON-ARMSTRONG MARI RN 41739 AGENA DALE S RN 69525 ABEE JENNIFER E RN 19550 ADAMS CAROLYN L RN 33363 AGLIAM MARILYN A RN 69992 ABEE KEVIN ANDREW RN 73979 ADAMS JENNIFER N RN 46748 AGLIBOT NANCY A RN 69993 ABELLADA MARINEL G RN 39164 ADAMS MARIA V RN 38303 AGLUGUB AURORA A RN 66502 ABELLANIDA STEPHANIE RN 52798 ADAMSKI MAUREEN RN 68068 AGNELLO TAI D RN 83403 ABERILLA JEREMY J RN 84737 ADDUCCI -

MIAA/MSAA CERTIFIED COACHES First Last School Kerin Biggins
MIAA/MSAA CERTIFIED COACHES First Last School Kerin Biggins Abby Kelley Foster Charter School Patrick Biggins Abby Kelley Foster Charter School Jennifer Bridgers Abby Kelley Foster Charter School Cheryl Corey Abby Kelley Foster Charter School Cheryl Corey Abby Kelley Foster Charter School Dave Ferraro Abby Kelley Foster Charter School Rebecca Gamble Abby Kelley Foster Charter School Chris Girardi Abby Kelley Foster Charter School Tamara Hampton Abby Kelley Foster Charter School Matt Howard Abby Kelley Foster Charter School Jamie LaFlash Abby Kelley Foster Charter School Mathew Lemire Abby Kelley Foster Charter School Francis Martell Abby Kelley Foster Charter School Grace Milner Abby Kelley Foster Charter School Brian Morse Abby Kelley Foster Charter School Michael Penney Abby Kelley Foster Charter School Henry Zussman Abby Kelley Foster Charter School Matthew MacLean Abington High School Lauren Pietrasik Abington High School Jason Brown Abington High School Michael Bruning Abington High School Matt Campbell Abington High School Kate Casey Abington High School Kristin Gerhart Abington High School Jennifer Krouse Abington High School Chris Madden Abington High School John McGInnis Abington High School Dan Norton Abington High School Steven Perakslis Abington High School Scott Pifer Abington High School Thomas Rogers Abington High School Peter Serino Abington High School James Smith Abington High School Judy Hamilton Abington Public Schools Gary Abrams Academy of Notre Dame Wally Armstrong Academy of Notre Dame Kevin Bailey Academy of Notre -

Nebraska Education Directory 2008-2009
NEBRASKA EDUCATION DIRECTORY 2008-2009 Roger D. Breed Commissioner of Education Scott Swisher Deputy Commissioner Nebraska Department of Education 301 Centennial Mall South P.O. Box 94987 Lincoln, Nebraska 68509-4987 Phone: (402) 471- 2295 FAX: (402) 471- 0117 WEB SITE: http://www.nde.state.ne.us Ann Ahrens of Minden High School in Minden, NE designed the feature artwork for the 2008-2009 Nebraska Education Directory. Ann is the daughter of Rhonda and Kirk Ahrens. Ann’s artwork is entitled “Step & Spin.” Chris Dolan was Ann’s art teacher. Printed copies are not available for the 2008-2009 Education Directory. The Department of Education will use electronic means whenever possible to publish information to our customers. The Directory is accessible on the Internet through our web site in various formats to view, print, or download. http://ess.nde.state.ne.us This information is current as of January 2009. Any changes after that time will not be reflected here. Go to “DIRECTORY SEARCH” listed under the “A-Z Topic List” at http://www.nde.state.ne.us for the most up-to-date information. 2008-2009 Nebraska Education Directory TABLE OF CONTENTS Page SEARCH THE DIRECTORY ................................................................................. 3 NDE Organizational Structure ............................................................................... 4 Department of Education Staff and Services Directory ......................................... 5 Job Position and Assignment Abbreviations ........................................................