Culturomics of Anaerobic Sludge
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-
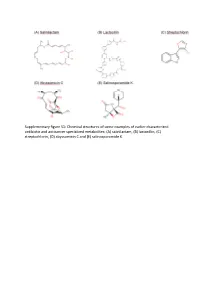
Chemical Structures of Some Examples of Earlier Characterized Antibiotic and Anticancer Specialized
Supplementary figure S1: Chemical structures of some examples of earlier characterized antibiotic and anticancer specialized metabolites: (A) salinilactam, (B) lactocillin, (C) streptochlorin, (D) abyssomicin C and (E) salinosporamide K. Figure S2. Heat map representing hierarchical classification of the SMGCs detected in all the metagenomes in the dataset. Table S1: The sampling locations of each of the sites in the dataset. Sample Sample Bio-project Site depth accession accession Samples Latitude Longitude Site description (m) number in SRA number in SRA AT0050m01B1-4C1 SRS598124 PRJNA193416 Atlantis II water column 50, 200, Water column AT0200m01C1-4D1 SRS598125 21°36'19.0" 38°12'09.0 700 and above the brine N "E (ATII 50, ATII 200, 1500 pool water layers AT0700m01C1-3D1 SRS598128 ATII 700, ATII 1500) AT1500m01B1-3C1 SRS598129 ATBRUCL SRS1029632 PRJNA193416 Atlantis II brine 21°36'19.0" 38°12'09.0 1996– Brine pool water ATBRLCL1-3 SRS1029579 (ATII UCL, ATII INF, N "E 2025 layers ATII LCL) ATBRINP SRS481323 PRJNA219363 ATIID-1a SRS1120041 PRJNA299097 ATIID-1b SRS1120130 ATIID-2 SRS1120133 2168 + Sea sediments Atlantis II - sediments 21°36'19.0" 38°12'09.0 ~3.5 core underlying ATII ATIID-3 SRS1120134 (ATII SDM) N "E length brine pool ATIID-4 SRS1120135 ATIID-5 SRS1120142 ATIID-6 SRS1120143 Discovery Deep brine DDBRINP SRS481325 PRJNA219363 21°17'11.0" 38°17'14.0 2026– Brine pool water N "E 2042 layers (DD INF, DD BR) DDBRINE DD-1 SRS1120158 PRJNA299097 DD-2 SRS1120203 DD-3 SRS1120205 Discovery Deep 2180 + Sea sediments sediments 21°17'11.0" -

Motiliproteus Sediminis Gen. Nov., Sp. Nov., Isolated from Coastal Sediment
Antonie van Leeuwenhoek (2014) 106:615–621 DOI 10.1007/s10482-014-0232-2 ORIGINAL PAPER Motiliproteus sediminis gen. nov., sp. nov., isolated from coastal sediment Zong-Jie Wang • Zhi-Hong Xie • Chao Wang • Zong-Jun Du • Guan-Jun Chen Received: 3 April 2014 / Accepted: 4 July 2014 / Published online: 20 July 2014 Ó Springer International Publishing Switzerland 2014 Abstract A novel Gram-stain-negative, rod-to- demonstrated that the novel isolate was 93.3 % similar spiral-shaped, oxidase- and catalase- positive and to the type strain of Neptunomonas antarctica, 93.2 % facultatively aerobic bacterium, designated HS6T, was to Neptunomonas japonicum and 93.1 % to Marino- isolated from marine sediment of Yellow Sea, China. bacterium rhizophilum, the closest cultivated rela- It can reduce nitrate to nitrite and grow well in marine tives. The polar lipid profile of the novel strain broth 2216 (MB, Hope Biol-Technology Co., Ltd) consisted of phosphatidylethanolamine, phosphatidyl- with an optimal temperature for growth of 30–33 °C glycerol and some other unknown lipids. Major (range 12–45 °C) and in the presence of 2–3 % (w/v) cellular fatty acids were summed feature 3 (C16:1 NaCl (range 0.5–7 %, w/v). The pH range for growth x7c/iso-C15:0 2-OH), C18:1 x7c and C16:0 and the main was pH 6.2–9.0, with an optimum at 6.5–7.0. Phylo- respiratory quinone was Q-8. The DNA G?C content genetic analysis based on 16S rRNA gene sequences of strain HS6T was 61.2 mol %. Based on the phylogenetic, physiological and biochemical charac- teristics, strain HS6T represents a novel genus and The GenBank accession number for the 16S rRNA gene T species and the name Motiliproteus sediminis gen. -

Compile.Xlsx
Silva OTU GS1A % PS1B % Taxonomy_Silva_132 otu0001 0 0 2 0.05 Bacteria;Acidobacteria;Acidobacteria_un;Acidobacteria_un;Acidobacteria_un;Acidobacteria_un; otu0002 0 0 1 0.02 Bacteria;Acidobacteria;Acidobacteriia;Solibacterales;Solibacteraceae_(Subgroup_3);PAUC26f; otu0003 49 0.82 5 0.12 Bacteria;Acidobacteria;Aminicenantia;Aminicenantales;Aminicenantales_fa;Aminicenantales_ge; otu0004 1 0.02 7 0.17 Bacteria;Acidobacteria;AT-s3-28;AT-s3-28_or;AT-s3-28_fa;AT-s3-28_ge; otu0005 1 0.02 0 0 Bacteria;Acidobacteria;Blastocatellia_(Subgroup_4);Blastocatellales;Blastocatellaceae;Blastocatella; otu0006 0 0 2 0.05 Bacteria;Acidobacteria;Holophagae;Subgroup_7;Subgroup_7_fa;Subgroup_7_ge; otu0007 1 0.02 0 0 Bacteria;Acidobacteria;ODP1230B23.02;ODP1230B23.02_or;ODP1230B23.02_fa;ODP1230B23.02_ge; otu0008 1 0.02 15 0.36 Bacteria;Acidobacteria;Subgroup_17;Subgroup_17_or;Subgroup_17_fa;Subgroup_17_ge; otu0009 9 0.15 41 0.99 Bacteria;Acidobacteria;Subgroup_21;Subgroup_21_or;Subgroup_21_fa;Subgroup_21_ge; otu0010 5 0.08 50 1.21 Bacteria;Acidobacteria;Subgroup_22;Subgroup_22_or;Subgroup_22_fa;Subgroup_22_ge; otu0011 2 0.03 11 0.27 Bacteria;Acidobacteria;Subgroup_26;Subgroup_26_or;Subgroup_26_fa;Subgroup_26_ge; otu0012 0 0 1 0.02 Bacteria;Acidobacteria;Subgroup_5;Subgroup_5_or;Subgroup_5_fa;Subgroup_5_ge; otu0013 1 0.02 13 0.32 Bacteria;Acidobacteria;Subgroup_6;Subgroup_6_or;Subgroup_6_fa;Subgroup_6_ge; otu0014 0 0 1 0.02 Bacteria;Acidobacteria;Subgroup_6;Subgroup_6_un;Subgroup_6_un;Subgroup_6_un; otu0015 8 0.13 30 0.73 Bacteria;Acidobacteria;Subgroup_9;Subgroup_9_or;Subgroup_9_fa;Subgroup_9_ge; -

S41598-017-07241-5.Pdf
www.nature.com/scientificreports OPEN In silico analyses of conservational, functional and phylogenetic distribution of the LuxI and LuxR Received: 16 December 2016 Accepted: 26 June 2017 homologs in Gram-positive bacteria Published online: 10 August 2017 Akanksha Rajput & Manoj Kumar LuxI and LuxR are key factors that drive quorum sensing (QS) in bacteria through secretion and perception of the signaling molecules e.g. N-Acyl homoserine lactones (AHLs). The role of these proteins is well established in Gram-negative bacteria for intercellular communication but remain under-explored in Gram-positive bacteria where QS peptides are majorly responsible for cell-to- cell communication. Therefore, in the present study, we explored conservation, potential function, topological arrangements and evolutionarily aspects of these proteins in Gram-positive bacteria. Putative LuxI/LuxR containing proteins were retrieved using the domain-based strategy from InterPro v62.0 meta-database. Conservational analyses via multiple sequence alignment and domain showed that these are well conserved in Gram-positive bacteria and possess relatedness with Gram- negative bacteria. Further, Gene ontology and ligand-based functional annotation explain their active involvement in signal transduction mechanism via QS signaling molecules. Moreover, Phylogenetic analyses (LuxI, LuxR, LuxI + LuxR and 16s rRNA) revealed horizontal gene transfer events with signifcant statistical support among Gram-positive and Gram-negative bacteria. This in-silico study ofers a detailed overview of potential LuxI/LuxR distribution in Gram-positive bacteria (mainly Firmicutes and Actinobacteria) and their functional role in QS. It would further help in understanding the extent of interspecies communications between Gram-positive and Gram-negative bacteria through QS signaling molecules. -

And Gas Condensate-Degrading Marine Bacteria
The ISME Journal (2017) 11, 2793–2808 © 2017 International Society for Microbial Ecology All rights reserved 1751-7362/17 www.nature.com/ismej ORIGINAL ARTICLE Chemical dispersants enhance the activity of oil- and gas condensate-degrading marine bacteria Julien Tremblay1, Etienne Yergeau2, Nathalie Fortin1, Susan Cobanli3, Miria Elias1, Thomas L King3, Kenneth Lee4 and Charles W Greer1 1National Research Council Canada, Montreal, Quebec, Canada; 2INRS—Institut Armand-Frappier, Laval, Quebec, Canada; 3COOGER, Fisheries and Oceans Canada, Dartmouth, NS, Canada and 4CSIRO, Australian Resources Research Centre, Kensington, WA, Australia Application of chemical dispersants to oil spills in the marine environment is a common practice to disperse oil into the water column and stimulate oil biodegradation by increasing its bioavailability to indigenous bacteria capable of naturally metabolizing hydrocarbons. In the context of a spill event, the biodegradation of crude oil and gas condensate off eastern Canada is an essential component of a response strategy. In laboratory experiments, we simulated conditions similar to an oil spill with and without the addition of chemical dispersant under both winter and summer conditions and evaluated the natural attenuation potential for hydrocarbons in near-surface sea water from the vicinity of crude oil and natural gas production facilities off eastern Canada. Chemical analyses were performed to determine hydrocarbon degradation rates, and metagenome binning combined with metatranscrip- tomics was used to reconstruct abundant bacterial genomes and estimate their oil degradation gene abundance and activity. Our results show important and rapid structural shifts in microbial populations in all three different oil production sites examined following exposure to oil, oil with dispersant and dispersant alone. -

Microbial Biodegradation of Alaska North Slope Crude Oil and Corexit 9500 in the Arctic Marine Environment
Microbial biodegradation of Alaska North Slope crude oil and Corexit 9500 in the Arctic marine environment Principal Investigators Mary Beth Leigh1, Sarah Hardy2 Graduate Students Alexis Walker2, Taylor Gofstein3 1 Institute of Arctic Biology, University of Alaska Fairbanks 2 College of Fisheries and Ocean Sciences, University of Alaska Fairbanks 3 Department of Chemistry and Biochemistry, University of Alaska Fairbanks Final Report OCS Study BOEM 2020-033 May 2020 Contact Information: Email: [email protected] Phone: 907.474.6782 Coastal Marine Institute College of Fisheries and Ocean Sciences University of Alaska Fairbanks P. O. Box 757220 Fairbanks, AK 99775-7220 This study was funded in part by the U.S. Department of the Interior, Bureau of Ocean Energy Management (BOEM) under cooperative agreement M17AC00005 between BOEM Alaska Outer Continental Shelf Region and the University of Alaska Fairbanks. This report, BOEM 2020-033 is available through the Coastal Marine Institute, select federal depository libraries, and electronically from https://www.boem.gov/BOEM- Newsroom/Library/ Publications/Alaska-Scientific-and-Technical- Publications.aspx The views and conclusions contained in this document are those of the authors and should not be interpreted as representing the opinions or policies of the U.S. Government. Mention of trade names or commercial products does not constitute their endorsement by the U.S. Government. TABLE OF CONTENTS LIST OF FIGURES ...................................................................................................................... -

Genomic Versatility and Functional Variation Between Two Dominant Heterotrophic Symbionts of Deep-Sea Osedax Worms
The ISME Journal (2013), 1–17 & 2013 International Society for Microbial Ecology All rights reserved 1751-7362/13 www.nature.com/ismej ORIGINAL ARTICLE Genomic versatility and functional variation between two dominant heterotrophic symbionts of deep-sea Osedax worms Shana K Goffredi1,5, Hana Yi2,5,6, Qingpeng Zhang3, Jane E Klann1, Isabelle A Struve1, Robert C Vrijenhoek4 and C Titus Brown3 1Department of Biology, Occidental College, Los Angeles, CA, USA; 2Institute of Molecular Biology and Genetics, Seoul National University, Seoul, Republic of Korea; 3Computer Science and Engineering, Michigan State University, East Lansing, MI, USA and 4Monterey Bay Aquarium Research Institute, Moss Landing, CA, USA An unusual symbiosis, first observed at B3000 m depth in the Monterey Submarine Canyon, involves gutless marine polychaetes of the genus Osedax and intracellular endosymbionts belonging to the order Oceanospirillales. Ecologically, these worms and their microbial symbionts have a substantial role in the cycling of carbon from deep-sea whale fall carcasses. Microheter- ogeneity exists among the Osedax symbionts examined so far, and in the present study the genomes of the two dominant symbionts, Rs1 and Rs2, were sequenced. The genomes revealed heterotrophic versatility in carbon, phosphate and iron uptake, strategies for intracellular survival, evidence for an independent existence, and numerous potential virulence capabilities. The presence of specific permeases and peptidases (of glycine, proline and hydroxyproline), and numerous peptide transporters, suggests the use of degraded proteins, likely originating from collagenous bone matter, by the Osedax symbionts. 13C tracer experiments confirmed the assimilation of glycine/ proline, as well as monosaccharides, by Osedax. The Rs1 and Rs2 symbionts are genomically distinct in carbon and sulfur metabolism, respiration, and cell wall composition, among others. -

The Eastern Oyster Microbiome and Its Implications in the Marine Nitrogen Cycle
W&M ScholarWorks Dissertations, Theses, and Masters Projects Theses, Dissertations, & Master Projects 2017 The Eastern Oyster Microbiome and its Implications in the Marine Nitrogen Cycle Ann Arfken College of William and Mary - Virginia Institute of Marine Science, [email protected] Follow this and additional works at: https://scholarworks.wm.edu/etd Part of the Aquaculture and Fisheries Commons, Marine Biology Commons, and the Microbiology Commons Recommended Citation Arfken, Ann, "The Eastern Oyster Microbiome and its Implications in the Marine Nitrogen Cycle" (2017). Dissertations, Theses, and Masters Projects. Paper 1516639592. http://dx.doi.org/doi:10.21220/V5QT7T This Dissertation is brought to you for free and open access by the Theses, Dissertations, & Master Projects at W&M ScholarWorks. It has been accepted for inclusion in Dissertations, Theses, and Masters Projects by an authorized administrator of W&M ScholarWorks. For more information, please contact [email protected]. The Eastern Oyster Microbiome and Its Implications in the Marine Nitrogen Cycle A Dissertation Presented to The Faculty of the School of Marine Science The College of William and Mary in Virginia In Partial Fulfillment of the Requirements for the Degree of Doctor of Philosophy by Ann M. Arfken January 2018 APPROVAL SHEET This dissertation is submitted in partial fulfillment of the requirements for the degree of Doctor of Philosophy Ann M. Arfken Approved by the Committee, December 2017 Bongkeun Song, Ph.D. Committee Chair / Advisor Iris C. Anderson, Ph.D. Ryan B. Carnegie, Ph.D. Lisa M. Kellogg, Ph.D. Michael F. Piehler, Ph.D. University of North Carolina at Chapel Hill Morehead City, North Carolina TABLE OF CONTENTS ACKNOWLEDGEMENTS .......................................................................................... -

Pontibacterium Granulatum Gen. Nov., Sp. Nov., Isolated from a Tidal Flat
TAXONOMIC DESCRIPTION Hyeon et al., Int J Syst Evol Microbiol 2017;67:3784–3790 DOI 10.1099/ijsem.0.002190 Pontibacterium granulatum gen. nov., sp. nov., isolated from a tidal flat Jong Woo Hyeon, Kyung Hyun Kim, Byung Hee Chun and Che Ok Jeon* Abstract A Gram-stain-negative, strictly aerobic, moderately halophilic bacterium, designated A-1T, was isolated from a tidal flat of the Taean coast in South Korea. Cells were motile rods with a single flagellum showing oxidase-negative and catalase- positive activities and contained poly-b-hydroxyalkanoic acid granules. Growth of strain A-1T was observed at 20–40 C (optimum, 30 C), pH 6.0–10.5 (optimum, pH 7.0) and in the presence of 1.0–6.0 % (w/v) NaCl (optimum, 2.0 %). Strain A-1T contained C16 : 0, summed feature 3 (comprising C16 : 1!7c and/or C16 : 1!6c) and summed feature 8 (comprising C18 : 1!7c T and/or C18 : 1!6c) as the major fatty acids. The major polar lipids of strain A-1 were phosphatidylethanolamine, phosphatidylglycerol and diphosphatidylglycerol. The isoprenoid quinones detected were ubiquinone-7 and ubiquinone-8. The G+C content of the genomic DNA was 51.5 mol%. Phylogenetic analysis based on 16S rRNA gene sequences showed that strain A-1T formed a distinct phylogenetic lineage from other genera within the family Oceanospirillaceae. Strain A-1T shared low 16S rRNA gene sequence similarities with other taxa (94.9 %). On the basis of phenotypic, chemotaxonomic and molecular properties, it is clear that strain A-1T represents a novel genus and species of the family Oceanospirillaceae, for which the name Pontibacterium granulatum gen. -

Taxonomía Y Diversidad De Microorganismos Asociados a Moluscos
ESPECIAL TAXONOMÍA, FILOGENIA Y DIVERSIDAD SEM@FORO NUM. 65 | JUNIO 2018 Taxonomía y diversidad de microorganismos asociados a moluscos Sabela Balboa, Ana L. Diéguez y Jesús L. Romalde [email protected] Dpto. Microbiología y Parasitología. Facultad de Farmacia, Univ. de Santiago de Compostela Algunos miembros del grupo de investigación. De izquierda a derecha: Ana L. Diéguez, Jesús L. Romalde, Sabela Balboa, Diego Gerpe y Rubén Barcia. El Grupo de Ictiopatología de la Universida- DIVERSIDAD MICROBIANA ASOCIADA cas del año diferentes. Se detectaron más de de Santiago de Compostela comenzó sus A MOLUSCOS GALLEGOS de 15 phyla bacterianos diferentes, además de investigaciones en microbiología del medio numerosos taxones que no pudieron ser identi- acuático con estudios de Vibrios patógenos Una de las principales líneas de investiga- ficados, sugiriendo que las almejas, y todos los para ostra y rodaballo en la década de los ción de nuestro grupo has sido el estudio de moluscos en general, constituyen un “almacén años 1980. Desde entonces, y con la incor- la microbiota asociada a moluscos cultivados bacteriano” que es necesario estudiar. poración de nuevos miembros, las investiga- en Galicia. El estudio más exhaustivo llevado ciones del grupo se han ido diversificando y, a cabo hasta la fecha se centró en el análisis La mayor parte de taxones pertenecieron en concreto, la línea dedicada al estudio de de la microbiota asociada a los cultivos de a las Proteobacteria, Actinobacteria y Bacte- la microbiota de moluscos ha crecido enor- almeja japonesa (Ruditapes philippinarum) riodetes. Cabe destacar que aquellos grupos memente gracias a diferentes proyectos tanto y almeja fina (R. -

The Effect of Carbon Subsidies on Marine Planktonic Niche Partitioning
bioRxiv preprint doi: https://doi.org/10.1101/013938; this version posted June 19, 2015. The copyright holder for this preprint (which was not certified by peer review) is the author/funder, who has granted bioRxiv a license to display the preprint in perpetuity. It is made available under aCC-BY-NC-ND 4.0 International license. 1 The effect of carbon subsidies on marine planktonic niche partitioning and recruitment during biofilm assembly 1 2, Charles Pepe-Ranney , Edward Hall ⇤ 1Cornell University, Department of Crop and Soil Sciences, Ithaca, NY, USA 2Colorado State University, Natural Resource and Ecology Laboratory, Fort Collins, CO, USA Correspondence*: Edward Hall Colorado State University, Natural Resource and Ecology Laboratory, Fort Collins, CO 80523-1499, USA, [email protected] 2 ABSTRACT 3 The influence of resource availability on planktonic and biofilm microbial community 4 membership is poorly understood. Heterotrophic bacteria derive some to all of their organic 5 carbon (C) from photoautotrophs while simultaneously competing with photoautotrophs for 6 inorganic nutrients such as phosphorus (P) or nitrogen (N). Therefore, C inputs have the 7 potential to shift the competitive balance of aquatic microbial communities by increasing the 8 resource space available to heterotrophs (more C) while decreasing the resource space 9 available to photoautotrophs (less mineral nutrients due to increased competition from 10 heterotrophs). To test how resource dynamics affect membership of planktonic communities 11 and assembly of biofilm communities we amended a series of flow-through mesocosms with C 12 to alter the availability of C among treatments. Each mesocosm was fed with unfiltered seawater 13 and incubated with sterilized microscope slides as surfaces for biofilm formation. -

Supplementary Materials
Supplementary Materials Supporting methods Sequence comparison to DNA isolation kit blank and drilling fluid (For Costa Rica sediment samples) Because DNA concentrations were very low in many of the sediment samples, and PCR tests indicated that in a few of the samples, if present at all, DNA may not be in high enough amounts to overcome the “background” DNA from the DNA extraction kits, a representative DNA extraction kit blank was sequenced along with all other samples. To remove any signal from the extraction kit in all samples, as well as to remove any samples whose genuine DNA was not in high enough abundance to overcome the extraction kit background, sequence results from the SILVA pipeline were processed initially as follows: 1. Classification of reads was examined at the “fully expanded” taxonomic depth from the SILVA pipeline output, and all lineages present in the extraction blank in any amount were flagged. 2. To account for sequencing error in classification, further lineages were added to the flagged ones by going up in taxonomic level to “order” and flagging every sequence identified as being from the same order as any sequence present in the extraction blank. There were a few cases where the taxonomy of sequences in the extraction blank did not go down as far as the level of "order", and for those, the most specific level identified above order was used to assess any further matches. For example, if the sequence was classified down to "class," then any remaining sequences in that class would also be removed. Those cases