Table of Contents
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Glibc and System Calls Documentation Release 1.0
Glibc and System Calls Documentation Release 1.0 Rishi Agrawal <[email protected]> Dec 28, 2017 Contents 1 Introduction 1 1.1 Acknowledgements...........................................1 2 Basics of a Linux System 3 2.1 Introduction...............................................3 2.2 Programs and Compilation........................................3 2.3 Libraries.................................................7 2.4 System Calls...............................................7 2.5 Kernel.................................................. 10 2.6 Conclusion................................................ 10 2.7 References................................................ 11 3 Working with glibc 13 3.1 Introduction............................................... 13 3.2 Why this chapter............................................. 13 3.3 What is glibc .............................................. 13 3.4 Download and extract glibc ...................................... 14 3.5 Walkthrough glibc ........................................... 14 3.6 Reading some functions of glibc ................................... 17 3.7 Compiling and installing glibc .................................... 18 3.8 Using new glibc ............................................ 21 3.9 Conclusion................................................ 23 4 System Calls On x86_64 from User Space 25 4.1 Setting Up Arguements......................................... 25 4.2 Calling the System Call......................................... 27 4.3 Retrieving the Return Value...................................... -

Red Hat Enterprise Linux 6 Developer Guide
Red Hat Enterprise Linux 6 Developer Guide An introduction to application development tools in Red Hat Enterprise Linux 6 Dave Brolley William Cohen Roland Grunberg Aldy Hernandez Karsten Hopp Jakub Jelinek Developer Guide Jeff Johnston Benjamin Kosnik Aleksander Kurtakov Chris Moller Phil Muldoon Andrew Overholt Charley Wang Kent Sebastian Red Hat Enterprise Linux 6 Developer Guide An introduction to application development tools in Red Hat Enterprise Linux 6 Edition 0 Author Dave Brolley [email protected] Author William Cohen [email protected] Author Roland Grunberg [email protected] Author Aldy Hernandez [email protected] Author Karsten Hopp [email protected] Author Jakub Jelinek [email protected] Author Jeff Johnston [email protected] Author Benjamin Kosnik [email protected] Author Aleksander Kurtakov [email protected] Author Chris Moller [email protected] Author Phil Muldoon [email protected] Author Andrew Overholt [email protected] Author Charley Wang [email protected] Author Kent Sebastian [email protected] Editor Don Domingo [email protected] Editor Jacquelynn East [email protected] Copyright © 2010 Red Hat, Inc. and others. The text of and illustrations in this document are licensed by Red Hat under a Creative Commons Attribution–Share Alike 3.0 Unported license ("CC-BY-SA"). An explanation of CC-BY-SA is available at http://creativecommons.org/licenses/by-sa/3.0/. In accordance with CC-BY-SA, if you distribute this document or an adaptation of it, you must provide the URL for the original version. Red Hat, as the licensor of this document, waives the right to enforce, and agrees not to assert, Section 4d of CC-BY-SA to the fullest extent permitted by applicable law. -

Yutaka Oiwa. "Implementation of a Fail-Safe ANSI C Compiler"
Implementation of a Fail-Safe ANSI C Compiler 安全な ANSI C コンパイラの実装手法 Doctoral Dissertation 博士論文 Yutaka Oiwa 大岩 寛 Submitted to Department of Computer Science, Graduate School of Information Science and Technology, The University of Tokyo on December 16, 2004 in partial fulfillment of the requirements for the degree of Doctor of Philosophy Abstract Programs written in the C language often suffer from nasty errors due to dangling pointers and buffer overflow. Such errors in Internet server programs are often ex- ploited by malicious attackers to “crack” an entire system, and this has become a problem affecting society as a whole. The root of these errors is usually corruption of on-memory data structures caused by out-of-bound array accesses. The C lan- guage does not provide any protection against such out-of-bound access, although recent languages such as Java, C#, Lisp and ML provide such protection. Never- theless, the C language itself should not be blamed for this shortcoming—it was designed to provide a replacement for assembly languages (i.e., to provide flexible direct memory access through a light-weight high-level language). In other words, lack of array boundary protection is “by design.” In addition, the C language was designed more than thirty years ago when there was not enough computer power to perform a memory boundary check for every memory access. The real prob- lem is the use of the C language for current casual programming, which does not usually require such direct memory accesses. We cannot realistically discard the C language right away, though, because there are many legacy programs written in the C language and many legacy programmers accustomed to the C language and its programming style. -

Reference Architecture Specification
Linux based 3G Multimedia Mobile-phone Reference Architecture Specification Draft 1.0 NEC Corporation Panasonic Mobile Communication Ltd. CE Linux Forum Technical Document Contents Preface......................................................................................................................................iii 1. Introduction.............................................................................................................................1 2. Scope .....................................................................................................................................1 3. Reference................................................................................................................................1 4. Definitions and abbreviations ....................................................................................................1 5. Architecture ............................................................................................................................3 5.1 A-CPU ..................................................................................................................................3 5.2 C-CPU..................................................................................................................................5 6. Description of functional entities ..............................................................................................5 6.1 Kernel....................................................................................................................................5 -

WWW-Based Collaboration Environments with Distributed Tool Services
WWWbased Collab oration Environments with Distributed To ol Services Gail E Kaiser Stephen E Dossick Wenyu Jiang Jack Jingshuang Yang SonnyXiYe Columbia University Department of Computer Science Amsterdam Avenue Mail Co de New York NY UNITED STATES fax kaisercscolumbiaedu CUCS February Abstract Wehave develop ed an architecture and realization of a framework for hyp ermedia collab oration environments that supp ort purp oseful work by orchestrated teams The hyp ermedia represents all plausible multimedia artifacts concerned with the collab orative tasks at hand that can b e placed or generated online from applicationsp ecic materials eg source co de chip layouts blueprints to formal do cumentation to digital library resources to informal email and chat transcripts The environment capabilities include b oth internal hyp ertext and external link server links among these artifacts which can b e added incrementally as useful connections are discovered pro jectsp ecic hyp ermedia search and browsing automated construction of artifacts and hyp erlinks according to the semantics of the group and individual tasks and the overall pro cess workow application of to ols to the artifacts and collab orativework for geographically disp ersed teams We present a general architecture for what wecallhyp ermedia subwebs and imp osition of groupspace services op erating on shared subwebs based on World Wide Web technology which could b e applied over the Internet andor within an organizational intranet We describ e our realization in OzWeb which -

Programmability Configuration Guide, Cisco IOS XE Bengaluru 17.6.X
Programmability Configuration Guide, Cisco IOS XE Bengaluru 17.6.x First Published: 2021-07-31 Americas Headquarters Cisco Systems, Inc. 170 West Tasman Drive San Jose, CA 95134-1706 USA http://www.cisco.com Tel: 408 526-4000 800 553-NETS (6387) Fax: 408 527-0883 THE SPECIFICATIONS AND INFORMATION REGARDING THE PRODUCTS IN THIS MANUAL ARE SUBJECT TO CHANGE WITHOUT NOTICE. ALL STATEMENTS, INFORMATION, AND RECOMMENDATIONS IN THIS MANUAL ARE BELIEVED TO BE ACCURATE BUT ARE PRESENTED WITHOUT WARRANTY OF ANY KIND, EXPRESS OR IMPLIED. USERS MUST TAKE FULL RESPONSIBILITY FOR THEIR APPLICATION OF ANY PRODUCTS. THE SOFTWARE LICENSE AND LIMITED WARRANTY FOR THE ACCOMPANYING PRODUCT ARE SET FORTH IN THE INFORMATION PACKET THAT SHIPPED WITH THE PRODUCT AND ARE INCORPORATED HEREIN BY THIS REFERENCE. IF YOU ARE UNABLE TO LOCATE THE SOFTWARE LICENSE OR LIMITED WARRANTY, CONTACT YOUR CISCO REPRESENTATIVE FOR A COPY. The Cisco implementation of TCP header compression is an adaptation of a program developed by the University of California, Berkeley (UCB) as part of UCB's public domain version of the UNIX operating system. All rights reserved. Copyright © 1981, Regents of the University of California. NOTWITHSTANDING ANY OTHER WARRANTY HEREIN, ALL DOCUMENT FILES AND SOFTWARE OF THESE SUPPLIERS ARE PROVIDED “AS IS" WITH ALL FAULTS. CISCO AND THE ABOVE-NAMED SUPPLIERS DISCLAIM ALL WARRANTIES, EXPRESSED OR IMPLIED, INCLUDING, WITHOUT LIMITATION, THOSE OF MERCHANTABILITY, FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT OR ARISING FROM A COURSE OF DEALING, USAGE, OR TRADE PRACTICE. IN NO EVENT SHALL CISCO OR ITS SUPPLIERS BE LIABLE FOR ANY INDIRECT, SPECIAL, CONSEQUENTIAL, OR INCIDENTAL DAMAGES, INCLUDING, WITHOUT LIMITATION, LOST PROFITS OR LOSS OR DAMAGE TO DATA ARISING OUT OF THE USE OR INABILITY TO USE THIS MANUAL, EVEN IF CISCO OR ITS SUPPLIERS HAVE BEEN ADVISED OF THE POSSIBILITY OF SUCH DAMAGES. -

Auditing Overhead, Auditing Adaptation, and Benchmark Evaluation in Linux Lei Zeng1, Yang Xiao1* and Hui Chen2
SECURITY AND COMMUNICATION NETWORKS Security Comm. Networks 2015; 8:3523–3534 Published online 4 June 2015 in Wiley Online Library (wileyonlinelibrary.com). DOI: 10.1002/sec.1277 RESEARCH ARTICLE Auditing overhead, auditing adaptation, and benchmark evaluation in Linux Lei Zeng1, Yang Xiao1* and Hui Chen2 1 Department of Computer Science, The University of Alabama, Tuscaloosa 35487-0290, AL, U.S.A. 2 Department of Mathematics and Computer Science, Virginia State University, Petersburg 23806, VA, U.S.A. ABSTRACT Logging is a critical component of Linux auditing. However, our experiments indicate that the logging overhead can be significant. The paper aims to leverage the performance overhead introduced by Linux audit framework under various us- age patterns. The study on the problem leads to an adaptive audit-logging mechanism. Many security incidents or other im- portant events are often accompanied with precursory events. We identify important precursory events – the vital signs of system activity and the audit events that must be recorded. We then design an adaptive auditing mechanism that increases or reduces the type of events collected and the frequency of events collected based upon the online analysis of the vital-sign events. The adaptive auditing mechanism reduces the overall system overhead and achieves a similar level of protection on the system and network security. We further adopt LMbench to evaluate the performance of key operations in Linux with compliance to four security standards. Copyright © 2015 John Wiley & Sons, Ltd. KEYWORDS logging; overhead; Linux; auditing *Correspondence Yang Xiao, Department of Computer Science, The University of Alabama, 101 Houser Hall, PO Box 870290, Tuscaloosa 35487-0290, AL, U.S.A. -

Titans and Trolls of the Open Source Arena
Titans and Trolls Enter the Open-Source Arena * by DEBRA BRUBAKER BURNS I. Introduction .................................................................................... 34 II. Legal Theories for Open Source Software License Enforcement ................................................................................... 38 A. OSS Licensing .......................................................................... 38 B. Legal Theories and Remedies for OSS Claims .................... 40 1. Legal Protections for OSS under Copyright and Contract Law ..................................................................... 40 Stronger Protections for OSS License under Copyright Law ................................................................... 40 2. Copyright-Ownership Challenges in OSS ....................... 42 3. Potential Legal Minefields for OSS under Patent Law ...................................................................................... 45 4. Added Legal Protection for OSS under Trademark Law ...................................................................................... 46 5. ITC 337 Action as Uncommon Legal Protection for OSS ..................................................................................... 49 III. Enforcement Within the OSS Community .................................. 49 A. Software Freedom Law Center Enforces OSS Licenses .... 50 B. Federal Circuit Finds OSS License Enforceable Under Copyright Law ......................................................................... 53 C. Commercial OSS -
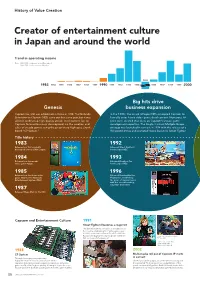
History of Value Creation
History of Value Creation Creator of entertainment culture in Japan and around the world Trend in operating income Note: 1983–1988: Fiscal years ended December 31 1989–2020: Fiscal years ended March 31 1995 1983 1984 1985 1986 1987 1988 1989 1990 1991 1992 1993 1994 1996 1997 1998 1999 2000 Big hits drive Genesis business expansion Capcom Co., Ltd. was established in Osaka in 1983. The Nintendo In the 1990s, the arrival of Super NES prompted Capcom to Entertainment System (NES) came out that same year, but it was formally enter home video game development. Numerous hit difficult to develop high-quality arcade-level content for, so titles were created that drew on Capcom’s arcade game Capcom focused business development on the creation and development expertise. The Single Content Multiple Usage sales of arcade games using the proprietary high-spec circuit strategy was launched in earnest in 1994 with the release of a board “CP System.” Hollywood movie and animated movie based on Street Fighter. Title history 1983 1992 Released our first originally Released Street Fighter II developed coin-op Little League. for the Super NES. 1984 1993 Released our first arcade Released Breath of Fire video game Vulgus. for the Super NES. 1985 1996 Released our first home video Released Resident Evil for game 1942 for the Nintendo PlayStation, establishing Entertainment System (NES). the genre of survival horror with this record-breaking, long-time best-seller. 1987 Released Mega Man for the NES. Capcom and Entertainment Culture 1991 Street Fighter II becomes a major hit The game became a sensation in arcades across the country, establishing the fighting game genre. -

Adecuándose a La Norma ISO/IEC 1799 Mediante Software Libre
Adecu´andose a la norma ISO/IEC 1799 mediante software libre * Jose Fernando Carvajal Vi´on Grupo de Inter´esen Seguridad de ATI (ATI-GISI) <[email protected]> Javier Fern´andez-Sanguino Pe˜na Grupo de Inter´esen Seguridad de ATI (ATI-GISI) <[email protected]> 28 de octubre de 2002 Resumen Este art´ıculo muestra la forma de adecuar a la norma ISO/IEC 17999 un sistema de informaci´onimplementado en un servidor cuyo software de sistema operativo se basa en alguna alternativa de software Libre y c´odigo abierto. La utilizaci´onde una distribuci´onDebian GNU/Linux sirve como base a la que a˜nadir las utilidades y paquetes necesarios para conseguir el objetivo. ´Indice 1. Introducci´on 1 2. Objetivo y Asunciones 2 3. Cumplimiento de la Norma ISO/IEC 17799 en GNU/Linux 4 4. Conclusiones 4 5. Referencias 5 6. Referencias de herramientas 7 7. Referencias Generales 11 *Copyright (c) 2002 Jose Fernando Carvajal y Javier Fern´andez-Sanguino. Se otorga permiso para copiar, distribuir y/o modificar este documento bajo los t´erminos de la Licencia de Documen- taci´onLibre GNU, Versi´on1.1 o cualquier otra versi´onposterior publicada por la Free Software Foundation. Puede consultar una copia de la licencia en: http://www.gnu.org/copyleft/fdl.html 1 1. Introducci´on De forma general para mantener la seguridad de los activos de informaci´on se deben preservar las caracter´ısticas siguientes [1]. 1. Confidencialidad: s´oloel personal o equipos autorizados pueden acceder a la informaci´on. 2. Integridad: la informaci´on y sus m´etodos de proceso son exactos y completos. -

Linux Journal | January 2016 | Issue
™ AUTOMATE Full Disk Encryption Since 1994: The Original Magazine of the Linux Community JANUARY 2016 | ISSUE 261 | www.linuxjournal.com IMPROVE + Enhance File Transfer Client-Side Performance Security for Users Making Sense of Profiles and RC Scripts ABINIT for Computational Chemistry Research Leveraging Ad Blocking WATCH: ISSUE Audit Serial OVERVIEW Console Access V LJ261-January2016.indd 1 12/17/15 8:35 PM Improve Finding Your Business Way: Mapping Processes with Your Network Practical books an Enterprise to Improve Job Scheduler Manageability for the most technical Author: Author: Mike Diehl Bill Childers Sponsor: Sponsor: people on the planet. Skybot InterMapper DIY Combating Commerce Site Infrastructure Sprawl Author: Reuven M. Lerner Author: GEEK GUIDES Sponsor: GeoTrust Bill Childers Sponsor: Puppet Labs Get in the Take Control Fast Lane of Growing with NVMe Redis NoSQL Author: Server Clusters Mike Diehl Author: Sponsor: Reuven M. Lerner Silicon Mechanics Sponsor: IBM & Intel Download books for free with a Linux in Apache Web simple one-time registration. the Time Servers and of Malware SSL Encryption Author: Author: http://geekguide.linuxjournal.com Federico Kereki Reuven M. Lerner Sponsor: Sponsor: GeoTrust Bit9 + Carbon Black LJ261-January2016.indd 2 12/17/15 8:35 PM Improve Finding Your Business Way: Mapping Processes with Your Network Practical books an Enterprise to Improve Job Scheduler Manageability for the most technical Author: Author: Mike Diehl Bill Childers Sponsor: Sponsor: people on the planet. Skybot InterMapper DIY Combating Commerce Site Infrastructure Sprawl Author: Reuven M. Lerner Author: GEEK GUIDES Sponsor: GeoTrust Bill Childers Sponsor: Puppet Labs Get in the Take Control Fast Lane of Growing with NVMe Redis NoSQL Author: Server Clusters Mike Diehl Author: Sponsor: Reuven M. -

Redhawk Linux User's Guide
Linux® User’s Guide 0898004-510 May 2006 Copyright 2006 by Concurrent Computer Corporation. All rights reserved. This publication or any part thereof is intended for use with Concurrent products by Concurrent personnel, customers, and end–users. It may not be reproduced in any form without the written permission of the publisher. The information contained in this document is believed to be correct at the time of publication. It is subject to change without notice. Concurrent makes no warranties, expressed or implied, concerning the information contained in this document. To report an error or comment on a specific portion of the manual, photocopy the page in question and mark the correction or comment on the copy. Mail the copy (and any additional comments) to Concurrent Computer Corporation, 2881 Gateway Drive, Pompano Beach, Florida, 33069. Mark the envelope “Attention: Publications Department.” This publication may not be reproduced for any other reason in any form without written permission of the publisher. RedHawk, iHawk, NightStar, NightTrace, NightSim, NightProbe and NightView are trademarks of Concurrent Computer Corporation. Linux is used pursuant to a sublicense from the Linux Mark Institute. Red Hat is a registered trademark of Red Hat, Inc. POSIX is a registered trademark of the Institute of Electrical and Electronics Engineers, Inc. AMD Opteron and AMD64 are trademarks of Advanced Micro Devices, Inc. The X Window System is a trademark of The Open Group. OSF/Motif is a registered trademark of the Open Software Foundation, Inc. Ethernet is a trademark of the Xerox Corporation. NFS is a trademark of Sun Microsystems, Inc. HyperTransport is a licensed trademark of the HyperTransport Technology Consortium.