Nikolaus Rath's Website
Total Page:16
File Type:pdf, Size:1020Kb

Load more
Recommended publications
-

The Kernel Report
The kernel report (ELC 2012 edition) Jonathan Corbet LWN.net [email protected] The Plan Look at a year's worth of kernel work ...with an eye toward the future Starting off 2011 2.6.37 released - January 4, 2011 11,446 changes, 1,276 developers VFS scalability work (inode_lock removal) Block I/O bandwidth controller PPTP support Basic pNFS support Wakeup sources What have we done since then? Since 2.6.37: Five kernel releases have been made 59,000 changes have been merged 3069 developers have contributed to the kernel 416 companies have supported kernel development February As you can see in these posts, Ralink is sending patches for the upstream rt2x00 driver for their new chipsets, and not just dumping a huge, stand-alone tarball driver on the community, as they have done in the past. This shows a huge willingness to learn how to deal with the kernel community, and they should be strongly encouraged and praised for this major change in attitude. – Greg Kroah-Hartman, February 9 Employer contributions 2.6.38-3.2 Volunteers 13.9% Wolfson Micro 1.7% Red Hat 10.9% Samsung 1.6% Intel 7.3% Google 1.6% unknown 6.9% Oracle 1.5% Novell 4.0% Microsoft 1.4% IBM 3.6% AMD 1.3% TI 3.4% Freescale 1.3% Broadcom 3.1% Fujitsu 1.1% consultants 2.2% Atheros 1.1% Nokia 1.8% Wind River 1.0% Also in February Red Hat stops releasing individual kernel patches March 2.6.38 released – March 14, 2011 (9,577 changes from 1198 developers) Per-session group scheduling dcache scalability patch set Transmit packet steering Transparent huge pages Hierarchical block I/O bandwidth controller Somebody needs to get a grip in the ARM community. -

Rootless Containers with Podman and Fuse-Overlayfs
CernVM Workshop 2019 (4th June 2019) Rootless containers with Podman and fuse-overlayfs Giuseppe Scrivano @gscrivano Introduction 2 Rootless Containers • “Rootless containers refers to the ability for an unprivileged user (i.e. non-root user) to create, run and otherwise manage containers.” (https://rootlesscontaine.rs/ ) • Not just about running the container payload as an unprivileged user • Container runtime runs also as an unprivileged user 3 Don’t confuse with... • sudo podman run --user foo – Executes the process in the container as non-root – Podman and the OCI runtime still running as root • USER instruction in Dockerfile – same as above – Notably you can’t RUN dnf install ... 4 Don’t confuse with... • podman run --uidmap – Execute containers as a non-root user, using user namespaces – Most similar to rootless containers, but still requires podman and runc to run as root 5 Motivation of Rootless Containers • To mitigate potential vulnerability of container runtimes • To allow users of shared machines (e.g. HPC) to run containers without the risk of breaking other users environments • To isolate nested containers 6 Caveat: Not a panacea • Although rootless containers could mitigate these vulnerabilities, it is not a panacea , especially it is powerless against kernel (and hardware) vulnerabilities – CVE 2013-1858, CVE-2015-1328, CVE-2018-18955 • Castle approach : it should be used in conjunction with other security layers such as seccomp and SELinux 7 Podman 8 Rootless Podman Podman is a daemon-less alternative to Docker • $ alias -

Dm-X: Protecting Volume-Level Integrity for Cloud Volumes and Local
dm-x: Protecting Volume-level Integrity for Cloud Volumes and Local Block Devices Anrin Chakraborti Bhushan Jain Jan Kasiak Stony Brook University Stony Brook University & Stony Brook University UNC, Chapel Hill Tao Zhang Donald Porter Radu Sion Stony Brook University & Stony Brook University & Stony Brook University UNC, Chapel Hill UNC, Chapel Hill ABSTRACT on Amazon’s Virtual Private Cloud (VPC) [2] (which provides The verified boot feature in recent Android devices, which strong security guarantees through network isolation) store deploys dm-verity, has been overwhelmingly successful in elim- data on untrusted storage devices residing in the public cloud. inating the extremely popular Android smart phone rooting For example, Amazon VPC file systems, object stores, and movement [25]. Unfortunately, dm-verity integrity guarantees databases reside on virtual block devices in the Amazon are read-only and do not extend to writable volumes. Elastic Block Storage (EBS). This paper introduces a new device mapper, dm-x, that This allows numerous attack vectors for a malicious cloud efficiently (fast) and reliably (metadata journaling) assures provider/untrusted software running on the server. For in- volume-level integrity for entire, writable volumes. In a direct stance, to ensure SEC-mandated assurances of end-to-end disk setup, dm-x overheads are around 6-35% over ext4 on the integrity, banks need to guarantee that the external cloud raw volume while offering additional integrity guarantees. For storage service is unable to remove log entries documenting cloud storage (Amazon EBS), dm-x overheads are negligible. financial transactions. Yet, without integrity of the storage device, a malicious cloud storage service could remove logs of a coordinated attack. -

ECE 598 – Advanced Operating Systems Lecture 19
ECE 598 { Advanced Operating Systems Lecture 19 Vince Weaver http://web.eece.maine.edu/~vweaver [email protected] 7 April 2016 Announcements • Homework #7 was due • Homework #8 will be posted 1 Why use FAT over ext2? • FAT simpler, easy to code • FAT supported on all major OSes • ext2 faster, more robust filename and permissions 2 btrfs • B-tree fs (similar to a binary tree, but with pages full of leaves) • overwrite filesystem (overwite on modify) vs CoW • Copy on write. When write to a file, old data not overwritten. Since old data not over-written, crash recovery better Eventually old data garbage collected • Data in extents 3 • Copy-on-write • Forest of trees: { sub-volumes { extent-allocation { checksum tree { chunk device { reloc • On-line defragmentation • On-line volume growth 4 • Built-in RAID • Transparent compression • Snapshots • Checksums on data and meta-data • De-duplication • Cloning { can make an exact snapshot of file, copy-on- write different than link, different inodles but same blocks 5 Embedded • Designed to be small, simple, read-only? • romfs { 32 byte header (magic, size, checksum,name) { Repeating files (pointer to next [0 if none]), info, size, checksum, file name, file data • cramfs 6 ZFS Advanced OS from Sun/Oracle. Similar in idea to btrfs indirect still, not extent based? 7 ReFS Resilient FS, Microsoft's answer to brtfs and zfs 8 Networked File Systems • Allow a centralized file server to export a filesystem to multiple clients. • Provide file level access, not just raw blocks (NBD) • Clustered filesystems also exist, where multiple servers work in conjunction. -

NOVA: a Log-Structured File System for Hybrid Volatile/Non
NOVA: A Log-structured File System for Hybrid Volatile/Non-volatile Main Memories Jian Xu and Steven Swanson, University of California, San Diego https://www.usenix.org/conference/fast16/technical-sessions/presentation/xu This paper is included in the Proceedings of the 14th USENIX Conference on File and Storage Technologies (FAST ’16). February 22–25, 2016 • Santa Clara, CA, USA ISBN 978-1-931971-28-7 Open access to the Proceedings of the 14th USENIX Conference on File and Storage Technologies is sponsored by USENIX NOVA: A Log-structured File System for Hybrid Volatile/Non-volatile Main Memories Jian Xu Steven Swanson University of California, San Diego Abstract Hybrid DRAM/NVMM storage systems present a host of opportunities and challenges for system designers. These sys- Fast non-volatile memories (NVMs) will soon appear on tems need to minimize software overhead if they are to fully the processor memory bus alongside DRAM. The result- exploit NVMM’s high performance and efficiently support ing hybrid memory systems will provide software with sub- more flexible access patterns, and at the same time they must microsecond, high-bandwidth access to persistent data, but provide the strong consistency guarantees that applications managing, accessing, and maintaining consistency for data require and respect the limitations of emerging memories stored in NVM raises a host of challenges. Existing file sys- (e.g., limited program cycles). tems built for spinning or solid-state disks introduce software Conventional file systems are not suitable for hybrid mem- overheads that would obscure the performance that NVMs ory systems because they are built for the performance char- should provide, but proposed file systems for NVMs either in- acteristics of disks (spinning or solid state) and rely on disks’ cur similar overheads or fail to provide the strong consistency consistency guarantees (e.g., that sector updates are atomic) guarantees that applications require. -

Oracle® Linux 7 Managing File Systems
Oracle® Linux 7 Managing File Systems F32760-07 August 2021 Oracle Legal Notices Copyright © 2020, 2021, Oracle and/or its affiliates. This software and related documentation are provided under a license agreement containing restrictions on use and disclosure and are protected by intellectual property laws. Except as expressly permitted in your license agreement or allowed by law, you may not use, copy, reproduce, translate, broadcast, modify, license, transmit, distribute, exhibit, perform, publish, or display any part, in any form, or by any means. Reverse engineering, disassembly, or decompilation of this software, unless required by law for interoperability, is prohibited. The information contained herein is subject to change without notice and is not warranted to be error-free. If you find any errors, please report them to us in writing. If this is software or related documentation that is delivered to the U.S. Government or anyone licensing it on behalf of the U.S. Government, then the following notice is applicable: U.S. GOVERNMENT END USERS: Oracle programs (including any operating system, integrated software, any programs embedded, installed or activated on delivered hardware, and modifications of such programs) and Oracle computer documentation or other Oracle data delivered to or accessed by U.S. Government end users are "commercial computer software" or "commercial computer software documentation" pursuant to the applicable Federal Acquisition Regulation and agency-specific supplemental regulations. As such, the use, reproduction, duplication, release, display, disclosure, modification, preparation of derivative works, and/or adaptation of i) Oracle programs (including any operating system, integrated software, any programs embedded, installed or activated on delivered hardware, and modifications of such programs), ii) Oracle computer documentation and/or iii) other Oracle data, is subject to the rights and limitations specified in the license contained in the applicable contract. -

Filesystem Considerations for Embedded Devices ELC2015 03/25/15
Filesystem considerations for embedded devices ELC2015 03/25/15 Tristan Lelong Senior embedded software engineer Filesystem considerations ABSTRACT The goal of this presentation is to answer a question asked by several customers: which filesystem should you use within your embedded design’s eMMC/SDCard? These storage devices use a standard block interface, compatible with traditional filesystems, but constraints are not those of desktop PC environments. EXT2/3/4, BTRFS, F2FS are the first of many solutions which come to mind, but how do they all compare? Typical queries include performance, longevity, tools availability, support, and power loss robustness. This presentation will not dive into implementation details but will instead summarize provided answers with the help of various figures and meaningful test results. 2 TABLE OF CONTENTS 1. Introduction 2. Block devices 3. Available filesystems 4. Performances 5. Tools 6. Reliability 7. Conclusion Filesystem considerations ABOUT THE AUTHOR • Tristan Lelong • Embedded software engineer @ Adeneo Embedded • French, living in the Pacific northwest • Embedded software, free software, and Linux kernel enthusiast. 4 Introduction Filesystem considerations Introduction INTRODUCTION More and more embedded designs rely on smart memory chips rather than bare NAND or NOR. This presentation will start by describing: • Some context to help understand the differences between NAND and MMC • Some typical requirements found in embedded devices designs • Potential filesystems to use on MMC devices 6 Filesystem considerations Introduction INTRODUCTION Focus will then move to block filesystems. How they are supported, what feature do they advertise. To help understand how they compare, we will present some benchmarks and comparisons regarding: • Tools • Reliability • Performances 7 Block devices Filesystem considerations Block devices MMC, EMMC, SD CARD Vocabulary: • MMC: MultiMediaCard is a memory card unveiled in 1997 by SanDisk and Siemens based on NAND flash memory. -

SUSE Linux Enterprise Server 15 SP2 Autoyast Guide Autoyast Guide SUSE Linux Enterprise Server 15 SP2
SUSE Linux Enterprise Server 15 SP2 AutoYaST Guide AutoYaST Guide SUSE Linux Enterprise Server 15 SP2 AutoYaST is a system for unattended mass deployment of SUSE Linux Enterprise Server systems. AutoYaST installations are performed using an AutoYaST control le (also called a “prole”) with your customized installation and conguration data. Publication Date: September 24, 2021 SUSE LLC 1800 South Novell Place Provo, UT 84606 USA https://documentation.suse.com Copyright © 2006– 2021 SUSE LLC and contributors. All rights reserved. Permission is granted to copy, distribute and/or modify this document under the terms of the GNU Free Documentation License, Version 1.2 or (at your option) version 1.3; with the Invariant Section being this copyright notice and license. A copy of the license version 1.2 is included in the section entitled “GNU Free Documentation License”. For SUSE trademarks, see https://www.suse.com/company/legal/ . All other third-party trademarks are the property of their respective owners. Trademark symbols (®, ™ etc.) denote trademarks of SUSE and its aliates. Asterisks (*) denote third-party trademarks. All information found in this book has been compiled with utmost attention to detail. However, this does not guarantee complete accuracy. Neither SUSE LLC, its aliates, the authors nor the translators shall be held liable for possible errors or the consequences thereof. Contents 1 Introduction to AutoYaST 1 1.1 Motivation 1 1.2 Overview and Concept 1 I UNDERSTANDING AND CREATING THE AUTOYAST CONTROL FILE 4 2 The AutoYaST Control -
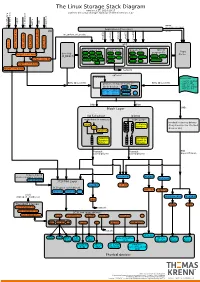
The Linux Storage Stack Diagram
The Linux Storage Stack Diagram version 3.17, 2014-10-17 outlines the Linux storage stack as of Kernel version 3.17 ISCSI USB mmap Fibre Channel Fibre over Ethernet Fibre Channel Fibre Virtual Host Virtual FireWire (anonymous pages) Applications (Processes) LIO malloc vfs_writev, vfs_readv, ... ... stat(2) read(2) open(2) write(2) chmod(2) VFS tcm_fc sbp_target tcm_usb_gadget tcm_vhost tcm_qla2xxx iscsi_target_mod block based FS Network FS pseudo FS special Page ext2 ext3 ext4 proc purpose FS target_core_mod direct I/O NFS coda sysfs Cache (O_DIRECT) xfs btrfs tmpfs ifs smbfs ... pipefs futexfs ramfs target_core_file iso9660 gfs ocfs ... devtmpfs ... ceph usbfs target_core_iblock target_core_pscsi network optional stackable struct bio - sector on disk BIOs (Block I/O) BIOs (Block I/O) - sector cnt devices on top of “normal” - bio_vec cnt block devices drbd LVM - bio_vec index - bio_vec list device mapper mdraid dm-crypt dm-mirror ... dm-cache dm-thin bcache BIOs BIOs Block Layer BIOs I/O Scheduler blkmq maps bios to requests multi queue hooked in device drivers noop Software (they hook in like stacked ... Queues cfq devices do) deadline Hardware Hardware Dispatch ... Dispatch Queue Queues Request Request BIO based Drivers based Drivers based Drivers request-based device mapper targets /dev/nullb* /dev/vd* /dev/rssd* dm-multipath SCSI Mid Layer /dev/rbd* null_blk SCSI upper level drivers virtio_blk mtip32xx /dev/sda /dev/sdb ... sysfs (transport attributes) /dev/nvme#n# /dev/skd* rbd Transport Classes nvme skd scsi_transport_fc network -

Effective Cache Apportioning for Performance Isolation Under
Effective Cache Apportioning for Performance Isolation Under Compiler Guidance Bodhisatwa Chatterjee Sharjeel Khan Georgia Institute of Technology Georgia Institute of Technology Atlanta, USA Atlanta, USA [email protected] [email protected] Santosh Pande Georgia Institute of Technology Atlanta, USA [email protected] Abstract cache partitioning to divide the LLC among the co-executing With a growing number of cores per socket in modern data- applications in the system. Ideally, a cache partitioning centers where multi-tenancy of a diverse set of applications scheme obtains overall gains in system performance by pro- must be efficiently supported, effective sharing of the last viding a dedicated region of cache memory to high-priority level cache is a very important problem. This is challenging cache-intensive applications and ensures security against because modern workloads exhibit dynamic phase behaviour cache-sharing attacks by the notion of isolated execution in - their cache requirements & sensitivity vary across different an otherwise shared LLC. Apart from achieving superior execution points. To tackle this problem, we propose Com- application performance and improving system throughput CAS, a compiler guided cache apportioning system that pro- [7, 20, 31], cache partitioning can also serve a variety of pur- vides smart cache allocation to co-executing applications in a poses - improving system power and energy consumption system. The front-end of Com-CAS is primarily a compiler- [6, 23], ensuring fairness in resource allocation [26, 36] and framework equipped with learning mechanisms to predict even enabling worst case execution-time analysis of real-time cache requirements, while the backend consists of allocation systems [18]. -

Bcache (Kernel-Modul Seit 3.11 ...)
DFN-Forum 2016: RZ Storage für die Virtualisierung Konrad Meier, Martin Ullrich, Dirk von Suchodoletz 31.05.2016 – Rechenzentrum Universität Rostock Ausgangslage . Praktiker-Beitrag, deshalb Fokus auf Problemlage und Ergebnisse / Erkenntnisse - Beschaffung neuen Speichersystems bereits in Ausschreibung - Übergangslösung für Problem für ca. halbes Jahr gesucht - Abt. eScience für Strat.entwicklung, bwCloud, HPC - Interessanter „Case“ im RZ-Geschäft, da Storage inzwischen sehr zentral - Storage im Übergang zu SSD/Flash aber All-Flash noch nicht bezahlbar - Flash attraktiver Beschleuniger/Cache - Bisher keine Erfahrung (wenig explizite Erfolgsberichte, jedoch viele Hinweise auf deutliche Verbesserungen), Probleme jedoch so groß, dass Risiko eines Scheiterns akzeptabel (Abschätzung Umbauaufwand etc.) 04.07.16 9. DFN-Forum in Rostock 2 Damalige Ausgangssituation . Zwei ESX-Cluster im Einsatz - Virtualisierung 1 Altsystem, klassiches FC-Setup - Virtualisierung 2 modernes System hoher Performance als zukünftiges Modell . Storage: Klass. Massen- speicher (nicht virt.-optimiert) . Für einfache Migration der VMs Einsatz von NFSv3 . Realisiert über Linux-Fileserver - Fibrechannel-Infrastruktur - LUNs mit Multipath-Anbindung als Blockdevices mit ext4 04.07.16 9. DFN-Forum in Rostock 3 Problem: Schlechte Storage Performance . Mehrfache Ausfälle des NFS-Kopfes mit unklaren Ursachen - Hohe Latenzen seit einigen Wochen - Last sollte aufgrund Semesterpause eher gering sein - Keine bekannten Veränderungen im Lastprofil der vorhandenen VMs . Aufschaukeleffekte - NFS „staut“ lange Queues auf (async Konfiguration) - Bei Crashes, je nach Gast-OS ziemlich kaputte FS - Linux-Gäste setzen bei langen Latenzen (virt.) Blockdevice ro, NTFS toleranter - Ungeschickte Konfigurationen in VMs verschlimmern Zustand . Ergebnisse von fio (iotop, htop ebenso betrachtet) lat(usec): 250=26.96%, 500=72.49%, 750=0.29%, 1000=0.07% lat(msec): 2=0.09%, 4=0.08%, 10=0.01%, 20=0.01%, 50=0.01% lat(msec): 100=0.01%, 250=0.01%, 500=0.01%, 750=0.01%, 2000=0.01% lat(msec): >=2000=0.01% 04.07.16 9. -

NOVA: the Fastest File System for Nvdimms
NOVA: The Fastest File System for NVDIMMs Steven Swanson, UC San Diego XFS F2FS NILFS EXT4 BTRFS © 2017 SNIA Persistent Memory Summit. All Rights Reserved. Disk-based file systems are inadequate for NVMM Disk-based file systems cannot 1-Sector 1-Block N-Block 1-Sector 1-Block N-Block Atomicity overwrit overwrit overwrit append append append exploit NVMM performance e e e Ext4 ✓ ✗ ✗ ✗ ✗ ✗ wb Ext4 ✓ ✓ ✗ ✓ ✗ ✓ Performance optimization Order Ext4 ✓ ✓ ✓ ✓ ✗ ✓ compromises consistency on Dataj system failure [1] Btrfs ✓ ✓ ✓ ✓ ✗ ✓ xfs ✓ ✓ ✗ ✓ ✗ ✓ Reiserfs ✓ ✓ ✗ ✓ ✗ ✓ [1] Pillai et al, All File Systems Are Not Created Equal: On the Complexity of Crafting Crash-Consistent Applications, OSDI '14. © 2017 SNIA Persistent Memory Summit. All Rights Reserved. BPFS SCMFS PMFS Aerie EXT4-DAX XFS-DAX NOVA M1FS © 2017 SNIA Persistent Memory Summit. All Rights Reserved. Previous Prototype NVMM file systems are not strongly consistent DAX does not provide data ATomic Atomicity Metadata Data Snapshot atomicity guarantee Mmap [1] So programming is more BPFS ✓ ✓ [2] ✗ ✗ difficult PMFS ✓ ✗ ✗ ✗ Ext4-DAX ✓ ✗ ✗ ✗ Xfs-DAX ✓ ✗ ✗ ✗ SCMFS ✗ ✗ ✗ ✗ Aerie ✓ ✗ ✗ ✗ © 2017 SNIA Persistent Memory Summit. All Rights Reserved. Ext4-DAX and xfs-DAX shortcomings No data atomicity support Single journal shared by all the transactions (JBD2- based) Poor performance Development teams are (rightly) “disk first”. © 2017 SNIA Persistent Memory Summit. All Rights Reserved. NOVA provides strong atomicity guarantees 1-Sector 1-Sector 1-Block 1-Block N-Block N-Block Atomicity Atomicity Metadata Data Mmap overwrite append overwrite append overwrite append Ext4 ✓ ✗ ✗ ✗ ✗ ✗ BPFS ✓ ✓ ✗ wb Ext4 ✓ ✓ ✗ ✓ ✗ ✓ PMFS ✓ ✗ ✗ Order Ext4 ✓ ✓ ✓ ✓ ✗ ✓ Ext4-DAX ✓ ✗ ✗ Dataj Btrfs ✓ ✓ ✓ ✓ ✗ ✓ Xfs-DAX ✓ ✗ ✗ xfs ✓ ✓ ✗ ✓ ✗ ✓ SCMFS ✗ ✗ ✗ Reiserfs ✓ ✓ ✗ ✓ ✗ ✓ Aerie ✓ ✗ ✗ © 2017 SNIA Persistent Memory Summit. All Rights Reserved.