Powerpc 750/7400 PMC Module
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

CPU ボードカタログ サポート CPU Intel :Core I7、Xeon-E5 Freescale :T4240、P4080、MPC8640D AMD :Radeon HD 6970M、HD 7970M GPGPU NVIDIA :Fermi、Kepler Architecture GPGPU
組込みシステム向け CPU ボードカタログ サポート CPU Intel :Core i7、Xeon-E5 Freescale :T4240、P4080、MPC8640D AMD :Radeon HD 6970M、HD 7970M GPGPU NVIDIA :Fermi、Kepler Architecture GPGPU サポートバス規格 OpenVPX VME/VXS CompactPCI PMC/XMC ATCA/AMC PCI Express 403102 Ⓒ MISH International Co., Ltd. MISH International Co., Ltd. ミッシュインターナショナルでは CPU ボードをスピーディに 導入頂けますよう、次のような サービスを提供しております CPU ボードのお貸出しサービス CPU ボードの性能評価検証サービス ミッシュインターナショナルでは、ユーザが実際に製品を導入する前に性能評価を実施していただけ ミッシュインターナショナルでは、専門の CPU ボードサポート技術者がお客様のご要望に応じて CPU ますよう各種評価用 CPU ボードをお貸出ししています。お貸出し時には、リアルタイム OS を含めた ボードの性能を評価・検証させていただきます。たとえばFFT の処理速度やボード間のデータ転送スピー CPU ボードに関するトータルな技術サポートを行っております。 ドの測定などユーザがシステムインテグレーションする上で必要なデータを検証の上、レポートさせて いただきます。(お客様のご要望内容によっては別途有償の場合もあります) CPU ボードの技術サポート ミッシュインターナショナルでは、専門のCPU ボードサポート技術者が導入前はもちろん、導入後もハー ド・ソフトの両面からお客様の技術サポートをいたします。CPU ボードのドライバソフトウェアやアプ リケーションの開発方法等をトータルにバックアップいたします。また、リアルタイム OS を含んだシ CPU ボード用フレームワークソフトウェアの開発サービス ステムインテグレーッションに関するアドバイスも対応しています。 CPU ボードを含んだ組込み用システムを構 築する上では、CPU ボードのハード・ソフ トに関する技術的な知識経験はもちろんです が、CPU ボード以外の A/D、D/A、DIO ボー ド等の各種 I/O ボードとのシームレスな高速 データ通信やリアルタイム OS を使用したイ ンテグレーションが必要です。当社では複数 のボードを使ったマルチ CPU ボードシステ ムやレーダ、ソナー、移動体通信等の無線信 号のリアルタイム処理等をトータルにサポートしています。全体的なデータのパスをサポートした『フ レームワークソフトウェア』の開発もお手伝いしています。ユーザは『フレームワークソフトウェア』 の開発を当社へ外注することにより、アプリケーションソフトウェアの開発や FPGA の開発に専念する ことが出来ます。(お客様のご要望内容によっては別途有償の場合もあります) インテル製 プロセッサ搭載 CPU ボード ボード CPU スピード 拡張 USB 耐環境 型名 プロセッサ メモリ NVRAM Ethernet インテル製 プロセッサ Core i7(Ivy Bridge)、 タイプ (Max) メザニン 2.0 仕様 Xeon E5-2648L x 2 32GB DDR3- 8MB NOR 1000BASE-T x 1 Level HDS6601 6U VPX 1.8GHz - 3 Xeon(8 Core) 搭載 CPU ボード (Sandy Bridge) -

Charactersing the Limits of the Openflow Slow-Path
Charactersing the Limits of the OpenFlow Slow-Path Richard Sanger, [email protected] Brad Cowie, [email protected] Matthew Luckie, [email protected] Richard Nelson, [email protected] University of Waikato, New Zealand 28 November 2018 The Question How slow is the slow-path? © THE UNIVERSITY OF WAIKATO • TE WHARE WANANGA O WAIKATO 2 Contents • Introduction to the Slow-Path • Motivation • Test Suite • Test Methodology • Results • Conclusions © THE UNIVERSITY OF WAIKATO • TE WHARE WANANGA O WAIKATO 3 OpenFlow Packet-in and Packet-out To move packets between the controller and network, packets are encapsulated in OpenFlow packet-in and packet-out messages and sent via the slow-path. © THE UNIVERSITY OF WAIKATO • TE WHARE WANANGA O WAIKATO 4 The Fast-Path ASIC OpenFlow Agent Ingress Egress OpenFlow Switch Network © THE UNIVERSITY OF WAIKATO • TE WHARE WANANGA O WAIKATO 5 The Slow-Path (Packet In) ASIC OpenFlow Agent Packet in OpenFlow Switch Network Control-Plane Network OpenFlow Application NIC Controller © THE UNIVERSITY OF WAIKATO • TE WHARE WANANGA O WAIKATO 6 Motivation: Control Traffic Requirements Control traffic is sensitive to bandwidth and latency Latency • Keep-alives • Flow Establishment (Reactive control) Bandwidth • Initial route exchange (BGP etc.) • Capture (Network debugging) • DoS (Misconfiguration, ICMP, etc.) © THE UNIVERSITY OF WAIKATO • TE WHARE WANANGA O WAIKATO 7 Motivation: Control Traffic Requirements Control traffic requirements must be met simultaneously. Example: consider the requirement of link detection probing. • Typical Bidirectional Forwarding Detection (BFD) requirements • < 50ms • 2,880pps (48 port switch) © THE UNIVERSITY OF WAIKATO • TE WHARE WANANGA O WAIKATO 8 Motivation: Shared Resource The slow-path is shared with all other OpenFlow messages. -

Avionics Hardware Issues 2010/11/19 Chih-Hao Sun Avionics Software--Hardware Issue -History
Avionics Hardware Issues 2010/11/19 Chih-hao Sun Avionics Software--Hardware Issue -History -HW Concepts History -FPGA vs ASIC The Gyroscope, the first auto-pilot device, was -Issues on • Avionics Computer introduced a decade after the Wright Brothers -Avionics (1910s) Computer -PowerPC • holds the plane level automatically -Examples -Energy Issue • is connected to computers for missions(B-17 and - Certification B-29 bombers) and Verification • German V-2 rocket(WWII) used the earliest automatic computer control system (automatic gyro control) • contains two free gyroscopes (a horizontal and a vertical) 2 Avionics Software--Hardware Issue -History -HW Concepts History -FPGA vs ASIC Avro Canada CF-105 Arrow fighter (1958) first used -Issues on • Avionics Computer analog computer to improve flyability -Avionics Computer is used to reduce tendency to yaw back and forth -PowerPC • -Examples F-16 (1970s) was the first operational jet fighter to use a -Energy Issue • fully-automatic analog flight control system (FLCS) - Certification and Verification • the rudder pedals and joysticks are connected to “Fly-by-wire” control system, and the system adjusts controls to maintain planes • contains three computers (for redundancy) 3 Avionics Software--Hardware Issue -History -HW Concepts History -FPGA vs ASIC NASA modified Navy F-8 with digital fly-by wire system in -Issues on • Avionics Computer 1972. -Avionics Computer • MD-11(1970s) was the first commercial aircraft to adopt -PowerPC computer-assisted flight control -Examples -Energy Issue The Airbus A320 series, late 1980s, used the first fully-digital - • Certification fly-by-wire controls in a commercial airliner and Verification • incorporates “flight envelope protection” • calculates that flight envelope (and adds a margin of safety) and uses this information to stop pilots from making aircraft outside that flight envelope. -

Vxworks Architecture Supplement, 6.2
VxWorks Architecture Supplement VxWorks® ARCHITECTURE SUPPLEMENT 6.2 Copyright © 2005 Wind River Systems, Inc. All rights reserved. No part of this publication may be reproduced or transmitted in any form or by any means without the prior written permission of Wind River Systems, Inc. Wind River, the Wind River logo, Tornado, and VxWorks are registered trademarks of Wind River Systems, Inc. Any third-party trademarks referenced are the property of their respective owners. For further information regarding Wind River trademarks, please see: http://www.windriver.com/company/terms/trademark.html This product may include software licensed to Wind River by third parties. Relevant notices (if any) are provided in your product installation at the following location: installDir/product_name/3rd_party_licensor_notice.pdf. Wind River may refer to third-party documentation by listing publications or providing links to third-party Web sites for informational purposes. Wind River accepts no responsibility for the information provided in such third-party documentation. Corporate Headquarters Wind River Systems, Inc. 500 Wind River Way Alameda, CA 94501-1153 U.S.A. toll free (U.S.): (800) 545-WIND telephone: (510) 748-4100 facsimile: (510) 749-2010 For additional contact information, please visit the Wind River URL: http://www.windriver.com For information on how to contact Customer Support, please visit the following URL: http://www.windriver.com/support VxWorks Architecture Supplement, 6.2 11 Oct 05 Part #: DOC-15660-ND-00 Contents 1 Introduction -

SIMD Extensions
SIMD Extensions PDF generated using the open source mwlib toolkit. See http://code.pediapress.com/ for more information. PDF generated at: Sat, 12 May 2012 17:14:46 UTC Contents Articles SIMD 1 MMX (instruction set) 6 3DNow! 8 Streaming SIMD Extensions 12 SSE2 16 SSE3 18 SSSE3 20 SSE4 22 SSE5 26 Advanced Vector Extensions 28 CVT16 instruction set 31 XOP instruction set 31 References Article Sources and Contributors 33 Image Sources, Licenses and Contributors 34 Article Licenses License 35 SIMD 1 SIMD Single instruction Multiple instruction Single data SISD MISD Multiple data SIMD MIMD Single instruction, multiple data (SIMD), is a class of parallel computers in Flynn's taxonomy. It describes computers with multiple processing elements that perform the same operation on multiple data simultaneously. Thus, such machines exploit data level parallelism. History The first use of SIMD instructions was in vector supercomputers of the early 1970s such as the CDC Star-100 and the Texas Instruments ASC, which could operate on a vector of data with a single instruction. Vector processing was especially popularized by Cray in the 1970s and 1980s. Vector-processing architectures are now considered separate from SIMD machines, based on the fact that vector machines processed the vectors one word at a time through pipelined processors (though still based on a single instruction), whereas modern SIMD machines process all elements of the vector simultaneously.[1] The first era of modern SIMD machines was characterized by massively parallel processing-style supercomputers such as the Thinking Machines CM-1 and CM-2. These machines had many limited-functionality processors that would work in parallel. -

Chapter 1. Origins of Mac OS X
1 Chapter 1. Origins of Mac OS X "Most ideas come from previous ideas." Alan Curtis Kay The Mac OS X operating system represents a rather successful coming together of paradigms, ideologies, and technologies that have often resisted each other in the past. A good example is the cordial relationship that exists between the command-line and graphical interfaces in Mac OS X. The system is a result of the trials and tribulations of Apple and NeXT, as well as their user and developer communities. Mac OS X exemplifies how a capable system can result from the direct or indirect efforts of corporations, academic and research communities, the Open Source and Free Software movements, and, of course, individuals. Apple has been around since 1976, and many accounts of its history have been told. If the story of Apple as a company is fascinating, so is the technical history of Apple's operating systems. In this chapter,[1] we will trace the history of Mac OS X, discussing several technologies whose confluence eventually led to the modern-day Apple operating system. [1] This book's accompanying web site (www.osxbook.com) provides a more detailed technical history of all of Apple's operating systems. 1 2 2 1 1.1. Apple's Quest for the[2] Operating System [2] Whereas the word "the" is used here to designate prominence and desirability, it is an interesting coincidence that "THE" was the name of a multiprogramming system described by Edsger W. Dijkstra in a 1968 paper. It was March 1988. The Macintosh had been around for four years. -

With the New Power Mac G4, You'll Be Able to Make Movies
Power Mac G4 With the new Power Mac G4, you’ll be able to make movies, create music CDs, and even produce your own DVD videos. Now with five slots—one AGP 4X graphics slot and four high-performance PCI slots—it’s the most expandable Macintosh ever. Most of all, the Power Mac G4 is fast—with a PowerPC G4 processor at up to 733 megahertz, a state-of-the-art NVIDIA GeForce2 graphics card, and an improved system architecture. In fact, the multitalented Power Mac G4 redefines all previous notions of what a desktop computer can do. Power Mac G4 Features With outstanding performance, state-of-the-art graphics, and incredible expandability, the new Power Mac G4 is the fastest and most expandable Macintosh ever. But the Power Mac G4 Speed redefined • Fastest-ever PowerPC G4 with Velocity Engine, goes even further by including innovative tools for creating movies, music CDs, and even up to 733-MHz processing speed DVD videos. • Optional dual 533-MHz PowerPC G4 processors • New on-chip level 2 cache and backside level 3 Supercomputing-caliber processors and an improved system architecture give this computer cache (667-MHz and 733-MHz systems) • New high-performance graphics cards and AGP its power. Processor-intensive tasks such as color conversions, Gaussian blurs, and video special 4X slot effects execute faster than ever. In optimized applications such as Adobe Photoshop and Apple • 133-MHz system bus and PC133 SDRAM up Final Cut Pro, multiprocessor Power Mac G4 systems can achieve exponential gains in speed 1 to 1.5GB over single-processor systems. -
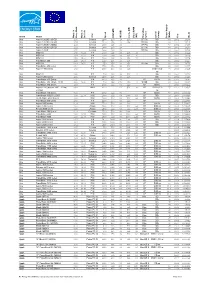
EC Energy Star Database Laptop Computers Archive 2001-2005
Brand Model Watts in Watts Mode Sleep in Watts On / Idle CPU Speed RAM (MB) HD (GB) (KB) Cache RAM Video (MB) Operating system optical storage Supply Power (Watts) Year PD_ID Acer Aspire 1202XC (10 GB) 2.76 Celeron 1200 256 10 256 XP Pro CD r 60 2002 10104 Acer Aspire 1202XC (20 GB) 2.74 Celeron 1200 256 20 256 XP Pro CD r 60 2002 10105 Acer Aspire 1200XV (10GB) 2.72 Celeron 1000 128 10 XP Pro CD r 60 2002 10106 Acer Aspire 1200XV (20 GB) 2.72 Celeron 1000 256 20 XP Pro CD r 60 2002 10107 Acer Aspire 1200X 2.72 Celeron 1000 128 10 XP Pro CD r 60 2002 10108 Acer MS2110 1.40 40.20 P 4 1700 128 20 256 16 CD r 70 2002 10112 Acer MS2114 1.60 41.00 P 4 1700 128 40 256 16 CD r 70 2002 10113 Acer MS2103 1.50 35.00 P 3 1200 128 20 256 11 CD r 70 2002 10114 Acer TravelMate 260 2.20 19.50 P 3 1130 256 20 256 CD r 60 2002 10115 Acer MS2109 2.20 19.50 P 3 150 256 20 256 XP Pro CD r 60 2002 10116 Acer TravelMate 270 series 2.12 P 4 1700 256 30 512 CD r 65 2002 10117 Acer Aspire 1400 Series 1.63 P 4 2000 256 30 512 DVD r / CD 90 2002 10118 rw Acer MS2101 1.40 P 3 700 128 30 512 8 CD r 50 2002 10119 Acer Aspire 1200 Series 2.66 Celeron 1300 256 20 256 CD r 60 2002 10120 Acer TravelMate 420 Series 2.15 P 4 2400 256 40 XP DVD r 90 2002 10121 Acer TravelMate 350 (XGA, 13.3") 8.80 18.80 P 3 700 248 9.59 256 8 W ME CD r 60 2003 10081 Acer TravelMate 530 Series 2.00 P 4 2400 512 40 512 XP DVD r 75 2003 1000211 Acer Aspire 1310 (also in 14.1", 2.9 kg 0.80 AMD 2000 60 512 32 XP DVD r / CD 75 2003 1003531 version) rw Acer TravelMate 430 Series 4.50 P 4 3060 512 -

Powerpc G5 White Paper December 2003 White Paper 2 Powerpc G5
PowerPC G5 White Paper December 2003 White Paper 2 PowerPC G5 Contents Page 3 Introduction Page 4 The World’s First 64-Bit Desktop Processor An Exponential Leap in Computing Power Memory Addressing up to 18 Exabytes High-Precision Calculations in a Single Clock Cycle Clock Speeds up to 2GHz Industry-Leading 1GHz Frontside Bus Full Support for Symmetric Multiprocessing Native Compatibility with 32-Bit Application Code Page 7 Next-Generation PowerPC Architecture Ultrafast Access to Data and Instructions Highly Parallel Execution Core Aggressive Queuing and Register Renaming Optimized 128-Bit Velocity Engine Two Double-Precision Floating-Point Units Two Integer Units Two Load/Store Units Condition Register Three-Component Branch Prediction Logic State-of-the-Art Process Technology from IBM Page 11 Technical Specifications White Paper 3 PowerPC G5 Introduction Key Features The revolutionary PowerPC G5 changes everything you know about personal computing. Suddenly, the next generation of high-performance applications for design and graphics, • 64-bit architecture, capable of addressing media production, and scientific research is possible and practical on the desktop. That’s 18 exabytes of memory • Clock speeds up to 2GHz because the PowerPC G5 brings a 64-bit architecture to the Mac platform—ushering in • 1GHz frontside bus for throughput of up to an exciting new era in personal computing. 8 GBps per processor The introduction of the PowerPC G5 is a product of Apple’s partnership with IBM, lever- • Dual independent 1GHz frontside buses in aging the most advanced chip design and manufacturing expertise in the world. The dual processor systems results are phenomenal: 130-nanometer fabrication technology, 2GHz clock speeds, and • Superscalar execution core supporting up to an all-new PowerPC architecture. -

Multi-Platform Auto-Vectorization
H-0236 (H0512-002) November 30, 2005 Computer Science IBM Research Report Multi-Platform Auto-Vectorization Dorit Naishlos, Richard Henderson* IBM Research Division Haifa Research Laboratory Mt. Carmel 31905 Haifa, Israel *Red Hat Research Division Almaden - Austin - Beijing - Haifa - India - T. J. Watson - Tokyo - Zurich LIMITED DISTRIBUTION NOTICE: This report has been submitted for publication outside of IBM and will probably be copyrighted if accepted for publication. I thas been issued as a Research Report for early dissemination of its contents. In view of the transfer of copyright to the outside publisher, its distribution outside of IBM prior to publication should be limited to peer communications and specific requests. After outside publication, requests should be filled only by reprints or legally obtained copies of the article (e.g ,. payment of royalties). Copies may be requested from IBM T. J. Watson Research Center , P. O. Box 218, Yorktown Heights, NY 10598 USA (email: [email protected]). Some reports are available on the internet at http://domino.watson.ibm.com/library/CyberDig.nsf/home . Multi-Platform Auto-Vectorization Dorit Naishlos Richard Henderson IBM Haifa Labs Red Hat [email protected] [email protected] Abstract. The recent proliferation of the Single Instruction Multiple Data (SIMD) model has lead to a wide variety of implementations. These have been incorporated into many platforms, from gaming machines and em- bedded DSPs to general purpose architectures. In this paper we present an automatic vectorizer as implemented in GCC - the most multi-targetable compiler available today. We discuss the considerations that are involved in developing a multi-platform vectorization technology, and demonstrate how our vectorization scheme is suited to a variety of SIMD architectures. -

A Bibliography of Publications in IEEE Micro
A Bibliography of Publications in IEEE Micro Nelson H. F. Beebe University of Utah Department of Mathematics, 110 LCB 155 S 1400 E RM 233 Salt Lake City, UT 84112-0090 USA Tel: +1 801 581 5254 FAX: +1 801 581 4148 E-mail: [email protected], [email protected], [email protected] (Internet) WWW URL: http://www.math.utah.edu/~beebe/ 16 September 2021 Version 2.108 Title word cross-reference -Core [MAT+18]. -Cubes [YW94]. -D [ASX19, BWMS19, DDG+19, Joh19c, PZB+19, ZSS+19]. -nm [ABG+16, KBN16, TKI+14]. #1 [Kah93i]. 0.18-Micron [HBd+99]. 0.9-micron + [Ano02d]. 000-fps [KII09]. 000-Processor $1 [Ano17-58, Ano17-59]. 12 [MAT 18]. 16 + + [ABG+16]. 2 [DTH+95]. 21=2 [Ste00a]. 28 [BSP 17]. 024-Core [JJK 11]. [KBN16]. 3 [ASX19, Alt14e, Ano96o, + AOYS95, BWMS19, CMAS11, DDG+19, 1 [Ano98s, BH15, Bre10, PFC 02a, Ste02a, + + Ste14a]. 1-GHz [Ano98s]. 1-terabits DFG 13, Joh19c, LXB07, LX10, MKT 13, + MAS+07, PMM15, PZB+19, SYW+14, [MIM 97]. 10 [Loc03]. 10-Gigabit SCSR93, VPV12, WLF+08, ZSS+19]. 60 [Gad07, HcF04]. 100 [TKI+14]. < [BMM15]. > [BMM15]. 2 [Kir84a, Pat84, PSW91, YSMH91, ZACM14]. [WHCK18]. 3 [KBW95]. II [BAH+05]. ∆ 100-Mops [PSW91]. 1000 [ES84]. 11- + [Lyl04]. 11/780 [Abr83]. 115 [JBF94]. [MKG 20]. k [Eng00j]. µ + [AT93, Dia95c, TS95]. N [YW94]. x 11FO4 [ASD 05]. 12 [And82a]. [DTB01, Dur96, SS05]. 12-DSP [Dur96]. 1284 [Dia94b]. 1284-1994 [Dia94b]. 13 * [CCD+82]. [KW02]. 1394 [SB00]. 1394-1955 [Dia96d]. 1 2 14 [WD03]. 15 [FD04]. 15-Billion-Dollar [KR19a]. -

Characterising the Limits of the Openflow Slow-Path
Characterising the Limits of the OpenFlow Slow-Path Richard Sanger Brad Cowie Matthew Luckie Richard Nelson University of Waikato University of Waikato University of Waikato University of Waikato [email protected] [email protected] [email protected] [email protected] Abstract—The OpenFlow standard accommodates network whole network. Their paper identified issues that still needed control traffic by providing packet in and out messages for investigating, including the scalability of the slow-path and the sending packets between the network and controller. We conduct need for additional performance profiling. comprehensive measurements of the performance of this control architecture in different configurations across five hardware The exact requirements on control traffic will vary depend- switches, each from a different vendor, representing a broad ing on the mix protocols used, so we use the requirements range of OpenFlow offerings, from implementations built on of Bidirectional Forwarding Detection (BFD) [3] to illustrate legacy ASIC architectures, to those implemented solely with challenging requirements on both latency and bandwidth. OpenFlow in mind. The best performing switch achieved a BFD is a technique used to detect failure of the forwarding- maximum mean packet-in rate of 5,145 messages per second, representing less than 3Mbps of traffic. Additionally, all switches plane quickly. BFD is usually implemented in hardware by tested failed to maintain control traffic latency under 50ms in the switch, but an SDN controller may provide a practical one or more tests. We find the slow-path performance of these alternative if a switch does not support BFD. A typical failure hardware switches is easily overloaded and is insufficient for detection time of 50ms requires 60 packets per second [3] modern network control architectures.