Powerpc G5 White Paper December 2003 White Paper 2 Powerpc G5
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

CPU ボードカタログ サポート CPU Intel :Core I7、Xeon-E5 Freescale :T4240、P4080、MPC8640D AMD :Radeon HD 6970M、HD 7970M GPGPU NVIDIA :Fermi、Kepler Architecture GPGPU
組込みシステム向け CPU ボードカタログ サポート CPU Intel :Core i7、Xeon-E5 Freescale :T4240、P4080、MPC8640D AMD :Radeon HD 6970M、HD 7970M GPGPU NVIDIA :Fermi、Kepler Architecture GPGPU サポートバス規格 OpenVPX VME/VXS CompactPCI PMC/XMC ATCA/AMC PCI Express 403102 Ⓒ MISH International Co., Ltd. MISH International Co., Ltd. ミッシュインターナショナルでは CPU ボードをスピーディに 導入頂けますよう、次のような サービスを提供しております CPU ボードのお貸出しサービス CPU ボードの性能評価検証サービス ミッシュインターナショナルでは、ユーザが実際に製品を導入する前に性能評価を実施していただけ ミッシュインターナショナルでは、専門の CPU ボードサポート技術者がお客様のご要望に応じて CPU ますよう各種評価用 CPU ボードをお貸出ししています。お貸出し時には、リアルタイム OS を含めた ボードの性能を評価・検証させていただきます。たとえばFFT の処理速度やボード間のデータ転送スピー CPU ボードに関するトータルな技術サポートを行っております。 ドの測定などユーザがシステムインテグレーションする上で必要なデータを検証の上、レポートさせて いただきます。(お客様のご要望内容によっては別途有償の場合もあります) CPU ボードの技術サポート ミッシュインターナショナルでは、専門のCPU ボードサポート技術者が導入前はもちろん、導入後もハー ド・ソフトの両面からお客様の技術サポートをいたします。CPU ボードのドライバソフトウェアやアプ リケーションの開発方法等をトータルにバックアップいたします。また、リアルタイム OS を含んだシ CPU ボード用フレームワークソフトウェアの開発サービス ステムインテグレーッションに関するアドバイスも対応しています。 CPU ボードを含んだ組込み用システムを構 築する上では、CPU ボードのハード・ソフ トに関する技術的な知識経験はもちろんです が、CPU ボード以外の A/D、D/A、DIO ボー ド等の各種 I/O ボードとのシームレスな高速 データ通信やリアルタイム OS を使用したイ ンテグレーションが必要です。当社では複数 のボードを使ったマルチ CPU ボードシステ ムやレーダ、ソナー、移動体通信等の無線信 号のリアルタイム処理等をトータルにサポートしています。全体的なデータのパスをサポートした『フ レームワークソフトウェア』の開発もお手伝いしています。ユーザは『フレームワークソフトウェア』 の開発を当社へ外注することにより、アプリケーションソフトウェアの開発や FPGA の開発に専念する ことが出来ます。(お客様のご要望内容によっては別途有償の場合もあります) インテル製 プロセッサ搭載 CPU ボード ボード CPU スピード 拡張 USB 耐環境 型名 プロセッサ メモリ NVRAM Ethernet インテル製 プロセッサ Core i7(Ivy Bridge)、 タイプ (Max) メザニン 2.0 仕様 Xeon E5-2648L x 2 32GB DDR3- 8MB NOR 1000BASE-T x 1 Level HDS6601 6U VPX 1.8GHz - 3 Xeon(8 Core) 搭載 CPU ボード (Sandy Bridge) -

Charactersing the Limits of the Openflow Slow-Path
Charactersing the Limits of the OpenFlow Slow-Path Richard Sanger, [email protected] Brad Cowie, [email protected] Matthew Luckie, [email protected] Richard Nelson, [email protected] University of Waikato, New Zealand 28 November 2018 The Question How slow is the slow-path? © THE UNIVERSITY OF WAIKATO • TE WHARE WANANGA O WAIKATO 2 Contents • Introduction to the Slow-Path • Motivation • Test Suite • Test Methodology • Results • Conclusions © THE UNIVERSITY OF WAIKATO • TE WHARE WANANGA O WAIKATO 3 OpenFlow Packet-in and Packet-out To move packets between the controller and network, packets are encapsulated in OpenFlow packet-in and packet-out messages and sent via the slow-path. © THE UNIVERSITY OF WAIKATO • TE WHARE WANANGA O WAIKATO 4 The Fast-Path ASIC OpenFlow Agent Ingress Egress OpenFlow Switch Network © THE UNIVERSITY OF WAIKATO • TE WHARE WANANGA O WAIKATO 5 The Slow-Path (Packet In) ASIC OpenFlow Agent Packet in OpenFlow Switch Network Control-Plane Network OpenFlow Application NIC Controller © THE UNIVERSITY OF WAIKATO • TE WHARE WANANGA O WAIKATO 6 Motivation: Control Traffic Requirements Control traffic is sensitive to bandwidth and latency Latency • Keep-alives • Flow Establishment (Reactive control) Bandwidth • Initial route exchange (BGP etc.) • Capture (Network debugging) • DoS (Misconfiguration, ICMP, etc.) © THE UNIVERSITY OF WAIKATO • TE WHARE WANANGA O WAIKATO 7 Motivation: Control Traffic Requirements Control traffic requirements must be met simultaneously. Example: consider the requirement of link detection probing. • Typical Bidirectional Forwarding Detection (BFD) requirements • < 50ms • 2,880pps (48 port switch) © THE UNIVERSITY OF WAIKATO • TE WHARE WANANGA O WAIKATO 8 Motivation: Shared Resource The slow-path is shared with all other OpenFlow messages. -

Avionics Hardware Issues 2010/11/19 Chih-Hao Sun Avionics Software--Hardware Issue -History
Avionics Hardware Issues 2010/11/19 Chih-hao Sun Avionics Software--Hardware Issue -History -HW Concepts History -FPGA vs ASIC The Gyroscope, the first auto-pilot device, was -Issues on • Avionics Computer introduced a decade after the Wright Brothers -Avionics (1910s) Computer -PowerPC • holds the plane level automatically -Examples -Energy Issue • is connected to computers for missions(B-17 and - Certification B-29 bombers) and Verification • German V-2 rocket(WWII) used the earliest automatic computer control system (automatic gyro control) • contains two free gyroscopes (a horizontal and a vertical) 2 Avionics Software--Hardware Issue -History -HW Concepts History -FPGA vs ASIC Avro Canada CF-105 Arrow fighter (1958) first used -Issues on • Avionics Computer analog computer to improve flyability -Avionics Computer is used to reduce tendency to yaw back and forth -PowerPC • -Examples F-16 (1970s) was the first operational jet fighter to use a -Energy Issue • fully-automatic analog flight control system (FLCS) - Certification and Verification • the rudder pedals and joysticks are connected to “Fly-by-wire” control system, and the system adjusts controls to maintain planes • contains three computers (for redundancy) 3 Avionics Software--Hardware Issue -History -HW Concepts History -FPGA vs ASIC NASA modified Navy F-8 with digital fly-by wire system in -Issues on • Avionics Computer 1972. -Avionics Computer • MD-11(1970s) was the first commercial aircraft to adopt -PowerPC computer-assisted flight control -Examples -Energy Issue The Airbus A320 series, late 1980s, used the first fully-digital - • Certification fly-by-wire controls in a commercial airliner and Verification • incorporates “flight envelope protection” • calculates that flight envelope (and adds a margin of safety) and uses this information to stop pilots from making aircraft outside that flight envelope. -

Chapter 1. Origins of Mac OS X
1 Chapter 1. Origins of Mac OS X "Most ideas come from previous ideas." Alan Curtis Kay The Mac OS X operating system represents a rather successful coming together of paradigms, ideologies, and technologies that have often resisted each other in the past. A good example is the cordial relationship that exists between the command-line and graphical interfaces in Mac OS X. The system is a result of the trials and tribulations of Apple and NeXT, as well as their user and developer communities. Mac OS X exemplifies how a capable system can result from the direct or indirect efforts of corporations, academic and research communities, the Open Source and Free Software movements, and, of course, individuals. Apple has been around since 1976, and many accounts of its history have been told. If the story of Apple as a company is fascinating, so is the technical history of Apple's operating systems. In this chapter,[1] we will trace the history of Mac OS X, discussing several technologies whose confluence eventually led to the modern-day Apple operating system. [1] This book's accompanying web site (www.osxbook.com) provides a more detailed technical history of all of Apple's operating systems. 1 2 2 1 1.1. Apple's Quest for the[2] Operating System [2] Whereas the word "the" is used here to designate prominence and desirability, it is an interesting coincidence that "THE" was the name of a multiprogramming system described by Edsger W. Dijkstra in a 1968 paper. It was March 1988. The Macintosh had been around for four years. -

Apple, Inc. Education Price List
Apple, Inc. Education Price List April 15, 2008 Table Of Contents [More information can be found on our web site at http://www.apple.com/education] Page • Revisions to the Price List • Apple Price Lists for Education 2 • Education Solutions 2 SECTION A: HARDWARE PRODUCTS 5-14 • iMac 5 • MacBook 6 • MacBook Pro 7 • Mac Pro 8 • Xserve 9 • Macintosh Displays & Video Accessories 12 • Wireless Connectivity 13 • iBook Accessories 13 • PowerBook Accessories 13 • Xserve Accessories 14 • Miscellaneous Accessories 15 SECTION B: APPLE PROFESSIONAL SERVICES & AppleCare SUPPORT 15-23 • Apple Professional Services - Project Management 15 • Apple Professional Services - Integration Services 16 • Apple Professional Services - System Setup Services 17 • AppleCare Products 20 Purchase orders for all products may be submitted to: Apple Attn: Apple Education Sales Support 12545 Riata Vista Circle Mail Stop: 198-3ED Austin, TX 78727-6524 Phone: 1-800-800-2775 K-12 Fax: (512) 674-2992 Revisions to the March 17, 2008 Education Price List Effective April 15, 2008 PRODUCTS ADDED TO THE PRICE LIST BD624LL/A Apple Digital Learning Series: Digital Media Creation Kit 899.00 MB560Z/A NVIDIA GeForce 8800 GT Graphics Upgrade Kit 251.00 PRODUCTS REPRICED ON THE PRICE LIST MB137Z/A NVIDIA GeForce 8800 GT Graphics Upgrade Kit for Mac Pro 251.00 MB198Z/A ATI Radeon HD 2600 XT Graphics Upgrade Kit for Mac Pro 116.00 PRODUCTS REMOVED FROM THE PRICE LIST BC744LL/A Apple Digital Learning Series: Digital Media Creation Kit TM740LL/A Nike+ Armband w/ Window for nano-Black M9479LL/A AirPort Extreme Power Supply MA504G/A 750GB Serial ATA Apple Drive Module for Xserve MA598Z/A Apple MagSafe (Airline) Power Adapter Prices on this Price List supersede previous Price Lists. -

An Expansion on Applied Computer Cooling
An Expansion on Applied Computer Cooling By Spencer Ellsworth LAES 400 November 29, 2012 Abstract In the world of professional technology, many businesses utilize servers and Ap- ple products in their day-to-day work, relying upon these machines for the liveli- hood of their operations. However, the technology being used is limited by a single, ever-important factor: heat. The key to improved performance, increased computer longevity, and lower upkeep costs lies in managing machine temperatures. Previously, this topic was investigated for the world of PCs. In this paper, modifications, upgrades, and available components that improve cooling are discussed in regard to servers and Apple products. Through the use of these methodologies, the aformentioned improve- ments may be achieved. Contents 1 Introduction 1 2 Background 1 3 Servers 2 3.1 Freestanding . 3 3.2 Rack Mount . 3 4 Apple Products 5 4.1 Difficulties . 5 4.2 Mac Desktops . 5 4.2.1 iMac . 6 4.2.2 Mac Pro . 6 4.3 Mac Mini . 7 4.4 Apple TV . 7 4.5 MacBook . 8 5 Business Economics 8 5.1 Servers . 8 5.2 Apple . 9 6 Related Work 9 7 Conclusion 10 1 Introduction freestanding and rack mount servers, as their differences are significant. The topics of \Now this is not the end. It is not even this paper then make a transition to Ap- the beginning of the end. But it is, per- ple products, touching upon the difficulties haps, the end of the beginning." -Sir Win- in improving cooling for Apple machines, as ston Churchill, 1942 well as individual investigations of the iMac, Six months ago, the author completed a Mac Pro, Mac Mini, Apple TV, and Mac- research, analysis, and experimentation pa- Book. -

Apple, Inc. Education Price List July 13, 2010
Apple, Inc. Education Price List July 13, 2010 Table Of Contents [More information can be found on our web site at http://www.apple.com/education] Page • Revisions to the Price List • Apple Price Lists for Education • Education Solutions 2 SECTION A: HARDWARE PRODUCTS 4-15 • iMac 4 • MacBook 5 • MacBook Pro 6 • Mac Pro 7 • Xserve 9 • Macintosh Displays & Video Accessories 12 • Wireless Connectivity 13 • iBook Accessories 13 • PowerBook Accessories 13 • Xserve Accessories 14 • Miscellaneous Accessories 15 SECTION B: APPLE PROFESSIONAL SERVICES & AppleCare SUPPORT 16-20 • Apple Professional Services 16 • AppleCare Products 17 Purchase orders for all products may be submitted to: Apple Attn: Apple Education Sales Support 12545 Riata Vista Circle Mail Stop: 198-3ED Austin, TX 78727-6524 Phone: 1-800-800-2775 K-12 Fax: (512) 674-2992 Revisions to the June 22, 2010 Education Price List Effective July 13, 2010 PRODUCTS ADDED TO THE PRICE LIST MA591G/B Apple Dock Connector to USB Cable 19.00 MB770G/B Apple Earphones with Remote and Mic 29.00 MA850G/B Apple In-ear Headphones with Remote and Mic 79.00 MB039ZM/D AppleCare Help Desk Support 2239.00 MB038ZM/D AppleCare Help Desk Tools 799.00 MC667ZM/A AppleCare OS Support - Select 4796.00 D5690ZM/A AppleCare OS Support - Preferred 15996.00 D5691ZM/A AppleCare OS Support - Alliance 39996.00 MA714Z/B AppleCare Technician Training 239.00 M9754ZM/C AppleCare Xsan Support 639.00 PRODUCTS REPRICED ON THE PRICE LIST PRODUCTS REMOVED FROM THE PRICE LIST MA591G/A Apple Dock Connector to USB Cable MB770G/A Apple Earphones with Remote and Mic MA850G/A Apple In-ear Headphones with Remote and Mic MB039ZM/C AppleCare Help Desk Support MB038ZM/C AppleCare Help Desk Tools MA714Z/A AppleCare Technician Training M9754ZM/B AppleCare Xsan Support MB040ZM/C Mac OS X Server Software Support - Select D2652LL/D Mac OS X Server Software Support - Preferred D2653LL/D Mac OS X Server Software Support - Alliance Prices on this Price List supersede previous Price Lists. -

With the New Power Mac G4, You'll Be Able to Make Movies
Power Mac G4 With the new Power Mac G4, you’ll be able to make movies, create music CDs, and even produce your own DVD videos. Now with five slots—one AGP 4X graphics slot and four high-performance PCI slots—it’s the most expandable Macintosh ever. Most of all, the Power Mac G4 is fast—with a PowerPC G4 processor at up to 733 megahertz, a state-of-the-art NVIDIA GeForce2 graphics card, and an improved system architecture. In fact, the multitalented Power Mac G4 redefines all previous notions of what a desktop computer can do. Power Mac G4 Features With outstanding performance, state-of-the-art graphics, and incredible expandability, the new Power Mac G4 is the fastest and most expandable Macintosh ever. But the Power Mac G4 Speed redefined • Fastest-ever PowerPC G4 with Velocity Engine, goes even further by including innovative tools for creating movies, music CDs, and even up to 733-MHz processing speed DVD videos. • Optional dual 533-MHz PowerPC G4 processors • New on-chip level 2 cache and backside level 3 Supercomputing-caliber processors and an improved system architecture give this computer cache (667-MHz and 733-MHz systems) • New high-performance graphics cards and AGP its power. Processor-intensive tasks such as color conversions, Gaussian blurs, and video special 4X slot effects execute faster than ever. In optimized applications such as Adobe Photoshop and Apple • 133-MHz system bus and PC133 SDRAM up Final Cut Pro, multiprocessor Power Mac G4 systems can achieve exponential gains in speed 1 to 1.5GB over single-processor systems. -
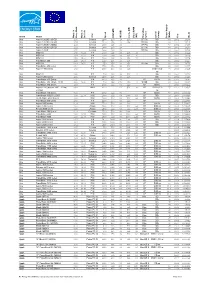
EC Energy Star Database Laptop Computers Archive 2001-2005
Brand Model Watts in Watts Mode Sleep in Watts On / Idle CPU Speed RAM (MB) HD (GB) (KB) Cache RAM Video (MB) Operating system optical storage Supply Power (Watts) Year PD_ID Acer Aspire 1202XC (10 GB) 2.76 Celeron 1200 256 10 256 XP Pro CD r 60 2002 10104 Acer Aspire 1202XC (20 GB) 2.74 Celeron 1200 256 20 256 XP Pro CD r 60 2002 10105 Acer Aspire 1200XV (10GB) 2.72 Celeron 1000 128 10 XP Pro CD r 60 2002 10106 Acer Aspire 1200XV (20 GB) 2.72 Celeron 1000 256 20 XP Pro CD r 60 2002 10107 Acer Aspire 1200X 2.72 Celeron 1000 128 10 XP Pro CD r 60 2002 10108 Acer MS2110 1.40 40.20 P 4 1700 128 20 256 16 CD r 70 2002 10112 Acer MS2114 1.60 41.00 P 4 1700 128 40 256 16 CD r 70 2002 10113 Acer MS2103 1.50 35.00 P 3 1200 128 20 256 11 CD r 70 2002 10114 Acer TravelMate 260 2.20 19.50 P 3 1130 256 20 256 CD r 60 2002 10115 Acer MS2109 2.20 19.50 P 3 150 256 20 256 XP Pro CD r 60 2002 10116 Acer TravelMate 270 series 2.12 P 4 1700 256 30 512 CD r 65 2002 10117 Acer Aspire 1400 Series 1.63 P 4 2000 256 30 512 DVD r / CD 90 2002 10118 rw Acer MS2101 1.40 P 3 700 128 30 512 8 CD r 50 2002 10119 Acer Aspire 1200 Series 2.66 Celeron 1300 256 20 256 CD r 60 2002 10120 Acer TravelMate 420 Series 2.15 P 4 2400 256 40 XP DVD r 90 2002 10121 Acer TravelMate 350 (XGA, 13.3") 8.80 18.80 P 3 700 248 9.59 256 8 W ME CD r 60 2003 10081 Acer TravelMate 530 Series 2.00 P 4 2400 512 40 512 XP DVD r 75 2003 1000211 Acer Aspire 1310 (also in 14.1", 2.9 kg 0.80 AMD 2000 60 512 32 XP DVD r / CD 75 2003 1003531 version) rw Acer TravelMate 430 Series 4.50 P 4 3060 512 -

Characterising the Limits of the Openflow Slow-Path
Characterising the Limits of the OpenFlow Slow-Path Richard Sanger Brad Cowie Matthew Luckie Richard Nelson University of Waikato University of Waikato University of Waikato University of Waikato [email protected] [email protected] [email protected] [email protected] Abstract—The OpenFlow standard accommodates network whole network. Their paper identified issues that still needed control traffic by providing packet in and out messages for investigating, including the scalability of the slow-path and the sending packets between the network and controller. We conduct need for additional performance profiling. comprehensive measurements of the performance of this control architecture in different configurations across five hardware The exact requirements on control traffic will vary depend- switches, each from a different vendor, representing a broad ing on the mix protocols used, so we use the requirements range of OpenFlow offerings, from implementations built on of Bidirectional Forwarding Detection (BFD) [3] to illustrate legacy ASIC architectures, to those implemented solely with challenging requirements on both latency and bandwidth. OpenFlow in mind. The best performing switch achieved a BFD is a technique used to detect failure of the forwarding- maximum mean packet-in rate of 5,145 messages per second, representing less than 3Mbps of traffic. Additionally, all switches plane quickly. BFD is usually implemented in hardware by tested failed to maintain control traffic latency under 50ms in the switch, but an SDN controller may provide a practical one or more tests. We find the slow-path performance of these alternative if a switch does not support BFD. A typical failure hardware switches is easily overloaded and is insufficient for detection time of 50ms requires 60 packets per second [3] modern network control architectures. -

Is Mac OS 9 Still a Player?
Home Profiles Articles Groups Deals News Software Mac Help News Feed Miscellaneous Ramblings Is Mac OS 9 Still a Player? Low End Mac Reader Specials TypeStyler For Mac OS X is Now Shipping! Search Mac OS 9 Compatibility, Upgrades, Hacks, and Download The Free Fully Functional 60 Day Resources, 2006 Edition Tryout at www.typestyler.com Custom Search A 'Best of Miscellaneous Ramblings' Column Don't install Parallels to play poker online! Share Poker Mac will show you how to download Charles Moore - 2006.05.15 - Tip Jar and install a native Mac poker application Follow LEM on such as Full Tilt Poker Mac. Twitter 8 Compare products like desktop computers, LEM on Facebook apple laptops, apple macs, and LCD This has been one of the most popular columns in the Monitors side by side! All the information history of Miscellaneous Ramblings. This article has been and reviews to make the best purchasing superceded by Low End Mac's Compleat Guide to Mac OS 9, decision for new mobile phones, sat nav Navigation 2008 Edition. dk systems, or MP3 players. The Ciao online shopping community makes searching Used Mac Dealers Last Friday's The Future of PowerPC Macs in the Intel Era products easy for you. Apple History Video Cards pointed to support of Classic mode as one of the primary Email Lists reasons to stick with PowerPC-based Macs. That raises the question: Is OS 9 still a useful, productive operating system? Favorite Sites It depends. My recommendation at this stage of the game is that if you have the hardware to run OS X with MacSurfer reasonable performance (my personal, arbitrary threshold would be a 500 MHz G3 with at least 512 MB of MacMinute RAM), then it's time to join the X-perience. -

Powerbook G4 Computer
Developer Note PowerBook G4 Computer December 2000 Apple Computer, Inc. Helvetica and Palatino are registered © 1999, 2000Apple Computer, Inc. trademarks of Heidelberger All rights reserved. Druckmaschinen AG, available from Linotype Library GmbH. No part of this publication may be reproduced, stored in a retrieval ITC Zapf Dingbats is a registered system, or transmitted, in any form trademark of International Typeface or by any means, mechanical, Corporation. electronic, photocopying, recording, OpenGL is a registered trademark of or otherwise, without prior written Silicon Graphics, Inc. permission of Apple Computer, Inc., PowerPC is a trademark of except to make a backup copy of any International Business Machines documentation provided on Corporation, used under license CD-ROM. therefrom. The Apple logo is a trademark of Apple Computer, Inc. Simultaneously published in the Use of the “keyboard” Apple logo United States and Canada. (Option-Shift-K) for commercial purposes without the prior written Even though Apple has reviewed this consent of Apple may constitute manual, APPLE MAKES NO trademark infringement and unfair WARRANTY OR REPRESENTATION, competition in violation of federal EITHER EXPRESS OR IMPLIED, WITH and state laws. RESPECT TO THIS MANUAL, ITS No licenses, express or implied, are QUALITY, ACCURACY, granted with respect to any of the MERCHANTABILITY, OR FITNESS technology described in this book. FOR A PARTICULAR PURPOSE. AS A Apple retains all intellectual RESULT, THIS MANUAL IS SOLD “AS property rights associated with the IS,” AND YOU, THE PURCHASER, ARE technology described in this book. ASSUMING THE ENTIRE RISK AS TO This book is intended to assist ITS QUALITY AND ACCURACY. application developers to develop IN NO EVENT WILL APPLE BE LIABLE applications only for Apple-labeled FOR DIRECT, INDIRECT, SPECIAL, or Apple-licensed computers.