Design and Implementation of Central Processing Unit Based Programmable Reversible Gate
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Comparison of Parallel and Pipelined CORDIC Algorithm Using RCA and CSA
Comparison of Parallel and Pipelined CORDIC algorithm using RCA and CSA Diego Barragan´ Guerrero Lu´ıs Geraldo P. Meloni FEEC - UNICAMP FEEC - UNICAMP Campinas, Sao˜ Paulo, Brazil, 13083-852 Campinas, Sao˜ Paulo, Brazil, 13083-852 +5519 9308-9952 +5519 9778-1523 [email protected] [email protected] Abstract— This paper presents an implementation of the algorithm has two modes of operation: the rotational mode CORDIC algorithm in digital hardware using two types of (RM) where the vector (xi; yi) is rotated by an angle θ to algebraic adders: Ripple-Carry Adder (RCA) and Carry-Select obtain a new vector (x ; y ), and the vectoring mode (VM) Adder (CSA), both in parallel and pipelined architectures. Anal- N N ysis of time performance and resources utilization was carried in which the algorithm computes the modulus R and phase α out by changing the algorithm number of iterations. These results from the x-axis of the vector (x0; y0). The basic principle of demonstrate the efficiency in operating frequency of the pipelined the algorithm is shown in Figure 1. architecture with respect to the parallel architecture. Also it is shown that the use of CSA reduce the timing processing without significantly increasing the slice use. The code was synthesized us- ing FPGA development tools for the Xilinx Spartan-3E xc3s500e ' ' E N y family. N E N Index Terms— CORDIC, pipelined, parallel, RCA, CSA, y N trigonometrics functions. Rotação Pseudo-rotação R N I. INTRODUCTION E i In Digital Signal Processing with FPGA, trigonometric y i R i functions are used in many signal algorithms, for instance N synchronization and equalization [12]. -

Basics of Logic Design Arithmetic Logic Unit (ALU) Today's Lecture
Basics of Logic Design Arithmetic Logic Unit (ALU) CPS 104 Lecture 9 Today’s Lecture • Homework #3 Assigned Due March 3 • Project Groups assigned & posted to blackboard. • Project Specification is on Web Due April 19 • Building the building blocks… Outline • Review • Digital building blocks • An Arithmetic Logic Unit (ALU) Reading Appendix B, Chapter 3 © Alvin R. Lebeck CPS 104 2 Review: Digital Design • Logic Design, Switching Circuits, Digital Logic Recall: Everything is built from transistors • A transistor is a switch • It is either on or off • On or off can represent True or False Given a bunch of bits (0 or 1)… • Is this instruction a lw or a beq? • What register do I read? • How do I add two numbers? • Need a method to reason about complex expressions © Alvin R. Lebeck CPS 104 3 Review: Boolean Functions • Boolean functions have arguments that take two values ({T,F} or {0,1}) and they return a single or a set of ({T,F} or {0,1}) value(s). • Boolean functions can always be represented by a table called a “Truth Table” • Example: F: {0,1}3 -> {0,1}2 a b c f1f2 0 0 0 0 1 0 0 1 1 1 0 1 0 1 0 0 1 1 0 0 1 0 0 1 0 1 1 0 0 1 1 1 1 1 1 © Alvin R. Lebeck CPS 104 4 Review: Boolean Functions and Expressions F(A, B, C) = (A * B) + (~A * C) ABCF 0000 0011 0100 0111 1000 1010 1101 1111 © Alvin R. Lebeck CPS 104 5 Review: Boolean Gates • Gates are electronics devices that implement simple Boolean functions Examples a a AND(a,b) OR(a,b) a NOT(a) b b a XOR(a,b) a NAND(a,b) b b a NOR(a,b) a XNOR(a,b) b b © Alvin R. -

Synthesis and Verification of Digital Circuits Using Functional Simulation and Boolean Satisfiability
Synthesis and Verification of Digital Circuits using Functional Simulation and Boolean Satisfiability by Stephen M. Plaza A dissertation submitted in partial fulfillment of the requirements for the degree of Doctor of Philosophy (Computer Science and Engineering) in The University of Michigan 2008 Doctoral Committee: Associate Professor Igor L. Markov, Co-Chair Assistant Professor Valeria M. Bertacco, Co-Chair Professor John P. Hayes Professor Karem A. Sakallah Associate Professor Dennis M. Sylvester Stephen M. Plaza 2008 c All Rights Reserved To my family, friends, and country ii ACKNOWLEDGEMENTS I would like to thank my advisers, Professor Igor Markov and Professor Valeria Bertacco, for inspiring me to consider various fields of research and providing feedback on my projects and papers. I also want to thank my defense committee for their comments and in- sights: Professor John Hayes, Professor Karem Sakallah, and Professor Dennis Sylvester. I would like to thank Professor David Kieras for enhancing my knowledge and apprecia- tion for computer programming and providing invaluable advice. Over the years, I have been fortunate to know and work with several wonderful stu- dents. I have collaborated extensively with Kai-hui Chang and Smita Krishnaswamy and have enjoyed numerous research discussions with them and have benefited from their in- sights. I would like to thank Ian Kountanis and Zaher Andraus for our many fun discus- sions on parallel SAT. I also appreciate the time spent collaborating with Kypros Constan- tinides and Jason Blome. Although I have not formally collaborated with Ilya Wagner, I have enjoyed numerous discussions with him during my doctoral studies. I also thank my office mates Jarrod Roy, Jin Hu, and Hector Garcia. -

A Logic Synthesis Toolbox for Reducing the Multiplicative Complexity in Logic Networks
A Logic Synthesis Toolbox for Reducing the Multiplicative Complexity in Logic Networks Eleonora Testa∗, Mathias Soekeny, Heinz Riener∗, Luca Amaruz and Giovanni De Micheli∗ ∗Integrated Systems Laboratory, EPFL, Lausanne, Switzerland yMicrosoft, Switzerland zSynopsys Inc., Design Group, Sunnyvale, California, USA Abstract—Logic synthesis is a fundamental step in the real- correlates to the resistance of the function against algebraic ization of modern integrated circuits. It has traditionally been attacks [10], while the multiplicative complexity of a logic employed for the optimization of CMOS-based designs, as well network implementing that function only provides an upper as for emerging technologies and quantum computing. Recently, bound. Consequently, minimizing the multiplicative complexity it found application in minimizing the number of AND gates in of a network is important to assess the real multiplicative cryptography benchmarks represented as xor-and graphs (XAGs). complexity of the function, and therefore its vulnerability. The number of AND gates in an XAG, which is called the logic net- work’s multiplicative complexity, plays a critical role in various Second, the number of AND gates plays an important role cryptography and security protocols such as fully homomorphic in high-level cryptography protocols such as zero-knowledge encryption (FHE) and secure multi-party computation (MPC). protocols, fully homomorphic encryption (FHE), and secure Further, the number of AND gates is also important to assess multi-party computation (MPC) [11], [12], [6]. For example, the the degree of vulnerability of a Boolean function, and influences size of the signature in post-quantum zero-knowledge signatures the cost of techniques to protect against side-channel attacks. -

Implementation of Carry Tree Adders and Compare with RCA and CSLA
International Journal of Emerging Engineering Research and Technology Volume 4, Issue 1, January 2016, PP 1-11 ISSN 2349-4395 (Print) & ISSN 2349-4409 (Online) Implementation of Carry Tree Adders and Compare with RCA and CSLA 1 2 G. Venkatanaga Kumar , C.H Pushpalatha Department of ECE, GONNA INSTITUTE OF TECHNOLOGY, Vishakhapatnam, India (PG Scholar) Department of ECE, GONNA INSTITUTE OF TECHNOLOGY, Vishakhapatnam, India (Associate Professor) ABSTRACT The binary adder is the critical element in most digital circuit designs including digital signal processors (DSP) and microprocessor data path units. As such, extensive research continues to be focused on improving the power delay performance of the adder. In VLSI implementations, parallel-prefix adders are known to have the best performance. Binary adders are one of the most essential logic elements within a digital system. In addition, binary adders are also helpful in units other than Arithmetic Logic Units (ALU), such as multipliers, dividers and memory addressing. Therefore, binary addition is essential that any improvement in binary addition can result in a performance boost for any computing system and, hence, help improve the performance of the entire system. Parallel-prefix adders (also known as carry-tree adders) are known to have the best performance in VLSI designs. This paper investigates three types of carry-tree adders (the Kogge- Stone, sparse Kogge-Stone, Ladner-Fischer and spanning tree adder) and compares them to the simple Ripple Carry Adder (RCA) and Carry Skip Adder (CSA). In this project Xilinx-ISE tool is used for simulation, logical verification, and further synthesizing. This algorithm is implemented in Xilinx 13.2 version and verified using Spartan 3e kit. -

Logic Optimization and Synthesis: Trends and Directions in Industry
Logic Optimization and Synthesis: Trends and Directions in Industry Luca Amaru´∗, Patrick Vuillod†, Jiong Luo∗, Janet Olson∗ ∗ Synopsys Inc., Design Group, Sunnyvale, California, USA † Synopsys Inc., Design Group, Grenoble, France Abstract—Logic synthesis is a key design step which optimizes of specific logic styles and cell layouts. Embedding as much abstract circuit representations and links them to technology. technology information as possible early in the logic optimiza- With CMOS technology moving into the deep nanometer regime, tion engine is key to make advantageous logic restructuring logic synthesis needs to be aware of physical informations early in the flow. With the rise of enhanced functionality nanodevices, opportunities carry over at the end of the design flow. research on technology needs the help of logic synthesis to capture In this paper, we examine the synergy between logic synthe- advantageous design opportunities. This paper deals with the syn- sis and technology, from an industrial perspective. We present ergy between logic synthesis and technology, from an industrial technology aware synthesis methods incorporating advanced perspective. First, we present new synthesis techniques which physical information at the core optimization engine. Internal embed detailed physical informations at the core optimization engine. Experiments show improved Quality of Results (QoR) and results evidence faster timing closure and better correlation better correlation between RTL synthesis and physical implemen- between RTL synthesis and physical implementation. We elab- tation. Second, we discuss the application of these new synthesis orate on synthesis aware technology development, where logic techniques in the early assessment of emerging nanodevices with synthesis enables a fair system-level assessment on emerging enhanced functionality. -
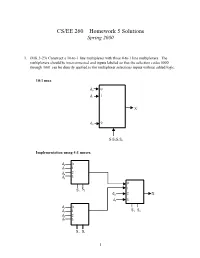
CS/EE 260 – Homework 5 Solutions Spring 2000
CS/EE 260 – Homework 5 Solutions Spring 2000 1. (MK 3-23) Construct a 10-to-1 line multiplexer with three 4-to-1 line multiplexers. The multiplexers should be interconnected and inputs labeled so that the selection codes 0000 through 1001 can be directly applied to the multiplexer selections inputs without added logic. 10:1 mux d0 0 1 d1 1 X d9 9 S3S2S1S0 Implementation using 4:1 muxes. d0 0 d2 1 d4 2 d6 3 0 S 1 S2 1 d8 2 X d9 3 d 0 1 S S d3 1 3 0 d5 2 d7 3 S2 S1 1 2. (MK 3-27) Implement a binary full adder with a dual 4-to-1 line multiplexer and a single inverter. AB Ci S Co 00 0 0 0 C 0 00 1 1 i 0 01 0 1 0 C ´ C 01 1 0 i 1 i 10 0 1 0 10 1 0Ci´ 1 Ci 11 0 0 1 C 1 11 1 1 i 1 0 C 1 i 4:1 2 S 3 mux S1 S0 A B 0 0 1 4:1 Co 2 mux 1 3 S1S0 2 3. (MK 3-34) Design a combinational circuit that forms the 2-bit binary sum S1S0 of two 2-bit numbers A1A0 and B1B0 and has both input C0 and a carry output C2. Do not use half adders or full adders, but instead use a two-level circuit plus inverters for the input variables, as needed. Design the circuit by starting with the following equations for each of the two bits of the adder. -

UNIT 8B a Full Adder
UNIT 8B Computer Organization: Levels of Abstraction 15110 Principles of Computing, 1 Carnegie Mellon University - CORTINA A Full Adder C ABCin Cout S in 0 0 0 A 0 0 1 0 1 0 B 0 1 1 1 0 0 1 0 1 C S out 1 1 0 1 1 1 15110 Principles of Computing, 2 Carnegie Mellon University - CORTINA 1 A Full Adder C ABCin Cout S in 0 0 0 0 0 A 0 0 1 0 1 0 1 0 0 1 B 0 1 1 1 0 1 0 0 0 1 1 0 1 1 0 C S out 1 1 0 1 0 1 1 1 1 1 ⊕ ⊕ S = A B Cin ⊕ ∧ ∨ ∧ Cout = ((A B) C) (A B) 15110 Principles of Computing, 3 Carnegie Mellon University - CORTINA Full Adder (FA) AB 1-bit Cout Full Cin Adder S 15110 Principles of Computing, 4 Carnegie Mellon University - CORTINA 2 Another Full Adder (FA) http://students.cs.tamu.edu/wanglei/csce350/handout/lab6.html AB 1-bit Cout Full Cin Adder S 15110 Principles of Computing, 5 Carnegie Mellon University - CORTINA 8-bit Full Adder A7 B7 A2 B2 A1 B1 A0 B0 1-bit 1-bit 1-bit 1-bit ... Cout Full Full Full Full Cin Adder Adder Adder Adder S7 S2 S1 S0 AB 8 ⁄ ⁄ 8 C 8-bit C out FA in ⁄ 8 S 15110 Principles of Computing, 6 Carnegie Mellon University - CORTINA 3 Multiplexer (MUX) • A multiplexer chooses between a set of inputs. D1 D 2 MUX F D3 D ABF 4 0 0 D1 AB 0 1 D2 1 0 D3 1 1 D4 http://www.cise.ufl.edu/~mssz/CompOrg/CDAintro.html 15110 Principles of Computing, 7 Carnegie Mellon University - CORTINA Arithmetic Logic Unit (ALU) OP 1OP 0 Carry In & OP OP 0 OP 1 F 0 0 A ∧ B 0 1 A ∨ B 1 0 A 1 1 A + B http://cs-alb-pc3.massey.ac.nz/notes/59304/l4.html 15110 Principles of Computing, 8 Carnegie Mellon University - CORTINA 4 Flip Flop • A flip flop is a sequential circuit that is able to maintain (save) a state. -

Designing a RISC CPU in Reversible Logic
Designing a RISC CPU in Reversible Logic Robert Wille Mathias Soeken Daniel Große Eleonora Schonborn¨ Rolf Drechsler Institute of Computer Science, University of Bremen, 28359 Bremen, Germany frwille,msoeken,grosse,eleonora,[email protected] Abstract—Driven by its promising applications, reversible logic In this paper, the recent progress in the field of reversible cir- received significant attention. As a result, an impressive progress cuit design is employed in order to design a complex system, has been made in the development of synthesis approaches, i.e. a RISC CPU composed of reversible gates. Starting from implementation of sequential elements, and hardware description languages. In this paper, these recent achievements are employed a textual specification, first the core components of the CPU in order to design a RISC CPU in reversible logic that can are identified. Previously introduced approaches are applied execute software programs written in an assembler language. The next to realize the respective combinational and sequential respective combinational and sequential components are designed elements. More precisely, the combinational components are using state-of-the-art design techniques. designed using the reversible hardware description language SyReC [17], whereas for the realization of the sequential I. INTRODUCTION elements an external controller (as suggested in [16]) is utilized. With increasing miniaturization of integrated circuits, the Plugging the respective components together, a CPU design reduction of power dissipation has become a crucial issue in results which can process software programs written in an today’s hardware design process. While due to high integration assembler language. This is demonstrated in a case study, density and new fabrication processes, energy loss has sig- where the execution of a program determining Fibonacci nificantly been reduced over the last decades, physical limits numbers is simulated. -

Design of High Speed and Low Power Six Transistor Full Adder Using Two Transistor Xor Gate
International Journal of Electronics, Communication & Instrumentation Engineering Research and Development (IJECIERD) ISSN 2249-684X Vol. 3, Issue 1, Mar 2013, 87-96 © TJPRC Pvt. Ltd. DESIGN OF HIGH SPEED AND LOW POWER SIX TRANSISTOR FULL ADDER USING TWO TRANSISTOR XOR GATE B. DILLI KUMAR, K. CHARAN KUMAR & T. NAVEEN KUMAR M. Tech (VLSI), Department of ECE, Sree Vidyanikethan Engineering College (Autonomous), Tirupati, India ABSTRACT Full adder is one of the major components in the design of many sophisticated hardware circuits. In this paper the full adder has been designed by using a new efficient design with less number of transistors. A 2 transistor XOR gate has been proposed with the help of two PMOS (Positive Metal Oxide Semiconductor) transistors. By using this 2T XOR gate the size of the full adder has been decreased to a large extent which can be implemented with only 6 transistors. The proposed full adder has a significant improvement in silicon area and power delay product when compared to the previous 8T full adder circuits. Further the proposed adder requires less area to perform a required logic function. Further, the proposed full adder has less power dissipation which makes it suitable for many of the low power applications and because of less area requirement the proposed design can be used in many of the portable applications also . KEYWORDS: Full Adder, XOR, Less Area, Speed, Low Power, Delay, Less Transistor Count, Low Power VLSI INTRODUCTION Full adder is one of the basic building blocks of many of the digital VLSI circuits. Several refinements has been made regarding its structure since its invention. -

Logic Synthesis Meets Machine Learning: Trading Exactness for Generalization
Logic Synthesis Meets Machine Learning: Trading Exactness for Generalization Shubham Raif,6,y, Walter Lau Neton,10,y, Yukio Miyasakao,1, Xinpei Zhanga,1, Mingfei Yua,1, Qingyang Yia,1, Masahiro Fujitaa,1, Guilherme B. Manskeb,2, Matheus F. Pontesb,2, Leomar S. da Rosa Juniorb,2, Marilton S. de Aguiarb,2, Paulo F. Butzene,2, Po-Chun Chienc,3, Yu-Shan Huangc,3, Hoa-Ren Wangc,3, Jie-Hong R. Jiangc,3, Jiaqi Gud,4, Zheng Zhaod,4, Zixuan Jiangd,4, David Z. Pand,4, Brunno A. de Abreue,5,9, Isac de Souza Camposm,5,9, Augusto Berndtm,5,9, Cristina Meinhardtm,5,9, Jonata T. Carvalhom,5,9, Mateus Grellertm,5,9, Sergio Bampie,5, Aditya Lohanaf,6, Akash Kumarf,6, Wei Zengj,7, Azadeh Davoodij,7, Rasit O. Topalogluk,7, Yuan Zhoul,8, Jordan Dotzell,8, Yichi Zhangl,8, Hanyu Wangl,8, Zhiru Zhangl,8, Valerio Tenacen,10, Pierre-Emmanuel Gaillardonn,10, Alan Mishchenkoo,y, and Satrajit Chatterjeep,y aUniversity of Tokyo, Japan, bUniversidade Federal de Pelotas, Brazil, cNational Taiwan University, Taiwan, dUniversity of Texas at Austin, USA, eUniversidade Federal do Rio Grande do Sul, Brazil, fTechnische Universitaet Dresden, Germany, jUniversity of Wisconsin–Madison, USA, kIBM, USA, lCornell University, USA, mUniversidade Federal de Santa Catarina, Brazil, nUniversity of Utah, USA, oUC Berkeley, USA, pGoogle AI, USA The alphabetic characters in the superscript represent the affiliations while the digits represent the team numbers yEqual contribution. Email: [email protected], [email protected], [email protected], [email protected] Abstract—Logic synthesis is a fundamental step in hard- artificial intelligence. -

Half Adder, Which Finds the Sum of Two Bits
CMSC 313 COMPUTER ORGANIZATION & ASSEMBLY LANGUAGE PROGRAMMING LECTURE 21, SPRING 2013 TOPICS TODAY • Circuits for Addition • Standard Logic Components • Logisim Demo CIRCUITS FOR ADDITION 3.5 Combinational Circuits • Combinational logic circuits give us many useful devices. • One of the simplest is the half adder, which finds the sum of two bits. • We can gain some insight as to the construction of a half adder by looking at its truth table, shown at the right. 30 Half Adder • Inputs: A and B • Outputs: S = lower bit of A + B, cout = carry bit A B S cout 0 0 0 0 0 1 1 0 1 0 1 0 1 1 0 1 • Using Sum-of-Products: S = AB + AB, cout = AB. • Alternatively, we could use XOR: S = A ⊕ B. ! ! ! ! 1 3.5 Combinational Circuits • As we see, the sum can be found using the XOR operation and the carry using the AND operation. 31 3.5 Combinational Circuits • We can change our half adder into to a full adder by including gates for processing the carry bit. • The truth table for a full adder is shown at the right. 32 Full Adder • Inputs: A, B and cin • Outputs: S = lower bit of A + B, cout = carry bit A B cin S cout 0 0 0 0 0 0 0 1 1 0 0 1 0 1 0 0 1 1 0 1 1 0 0 1 0 1 0 1 0 1 1 1 0 0 1 1 1 1 1 1 • S = A BC + ABC + AB C + ABC = A ⊕ B ⊕ C.