Optimizing HLT Code for Run-Time Efficiency
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Towards Scalable Multiprocessor Virtual Machines
USENIX Association Proceedings of the Third Virtual Machine Research and Technology Symposium San Jose, CA, USA May 6–7, 2004 © 2004 by The USENIX Association All Rights Reserved For more information about the USENIX Association: Phone: 1 510 528 8649 FAX: 1 510 548 5738 Email: [email protected] WWW: http://www.usenix.org Rights to individual papers remain with the author or the author's employer. Permission is granted for noncommercial reproduction of the work for educational or research purposes. This copyright notice must be included in the reproduced paper. USENIX acknowledges all trademarks herein. Towards Scalable Multiprocessor Virtual Machines Volkmar Uhlig Joshua LeVasseur Espen Skoglund Uwe Dannowski System Architecture Group Universitat¨ Karlsruhe [email protected] Abstract of guests, such that they only ever access a fraction of the physical processors, or alternatively time-multiplex A multiprocessor virtual machine benefits its guest guests across a set of physical processors to, e.g., ac- operating system in supporting scalable job throughput commodate for spikes in guest OS workloads. It can and request latency—useful properties in server consol- also map guest operating systems to virtual processors idation where servers require several of the system pro- (which can exceed the number of physical processors), cessors for steady state or to handle load bursts. and migrate between physical processors without no- Typical operating systems, optimized for multipro- tifying the guest operating systems. This allows for, cessor systems in their use of spin-locks for critical sec- e.g., migration to other machine configurations or hot- tions, can defeat flexible virtual machine scheduling due swapping of CPUs without adequate support from the to lock-holder preemption and misbalanced load. -
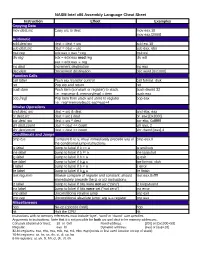
NASM Intel X86 Assembly Language Cheat Sheet
NASM Intel x86 Assembly Language Cheat Sheet Instruction Effect Examples Copying Data mov dest,src Copy src to dest mov eax,10 mov eax,[2000] Arithmetic add dest,src dest = dest + src add esi,10 sub dest,src dest = dest – src sub eax, ebx mul reg edx:eax = eax * reg mul esi div reg edx = edx:eax mod reg div edi eax = edx:eax reg inc dest Increment destination inc eax dec dest Decrement destination dec word [0x1000] Function Calls call label Push eip, transfer control call format_disk ret Pop eip and return ret push item Push item (constant or register) to stack. push dword 32 I.e.: esp=esp-4; memory[esp] = item push eax pop [reg] Pop item from stack and store to register pop eax I.e.: reg=memory[esp]; esp=esp+4 Bitwise Operations and dest, src dest = src & dest and ebx, eax or dest,src dest = src | dest or eax,[0x2000] xor dest, src dest = src ^ dest xor ebx, 0xfffffff shl dest,count dest = dest << count shl eax, 2 shr dest,count dest = dest >> count shr dword [eax],4 Conditionals and Jumps cmp b,a Compare b to a; must immediately precede any of cmp eax,0 the conditional jump instructions je label Jump to label if b == a je endloop jne label Jump to label if b != a jne loopstart jg label Jump to label if b > a jg exit jge label Jump to label if b > a jge format_disk jl label Jump to label if b < a jl error jle label Jump to label if b < a jle finish test reg,imm Bitwise compare of register and constant; should test eax,0xffff immediately precede the jz or jnz instructions jz label Jump to label if bits were not set (“zero”) jz looparound jnz label Jump to label if bits were set (“not zero”) jnz error jmp label Unconditional relative jump jmp exit jmp reg Unconditional absolute jump; arg is a register jmp eax Miscellaneous nop No-op (opcode 0x90) nop hlt Halt the CPU hlt Instructions with no memory references must include ‘byte’, ‘word’ or ‘dword’ size specifier. -

Understanding the Linux Kernel, 3Rd Edition by Daniel P
1 Understanding the Linux Kernel, 3rd Edition By Daniel P. Bovet, Marco Cesati ............................................... Publisher: O'Reilly Pub Date: November 2005 ISBN: 0-596-00565-2 Pages: 942 Table of Contents | Index In order to thoroughly understand what makes Linux tick and why it works so well on a wide variety of systems, you need to delve deep into the heart of the kernel. The kernel handles all interactions between the CPU and the external world, and determines which programs will share processor time, in what order. It manages limited memory so well that hundreds of processes can share the system efficiently, and expertly organizes data transfers so that the CPU isn't kept waiting any longer than necessary for the relatively slow disks. The third edition of Understanding the Linux Kernel takes you on a guided tour of the most significant data structures, algorithms, and programming tricks used in the kernel. Probing beyond superficial features, the authors offer valuable insights to people who want to know how things really work inside their machine. Important Intel-specific features are discussed. Relevant segments of code are dissected line by line. But the book covers more than just the functioning of the code; it explains the theoretical underpinnings of why Linux does things the way it does. This edition of the book covers Version 2.6, which has seen significant changes to nearly every kernel subsystem, particularly in the areas of memory management and block devices. The book focuses on the following topics: • Memory management, including file buffering, process swapping, and Direct memory Access (DMA) • The Virtual Filesystem layer and the Second and Third Extended Filesystems • Process creation and scheduling • Signals, interrupts, and the essential interfaces to device drivers • Timing • Synchronization within the kernel • Interprocess Communication (IPC) • Program execution Understanding the Linux Kernel will acquaint you with all the inner workings of Linux, but it's more than just an academic exercise. -

Virtualization in Linux KVM + QEMU
CS695 Topics in Virtualization and Cloud Computing Virtualization in Linux KVM + QEMU Senthil, Puru, Prateek and Shashank Virtualization in Linux 1 Topics covered • KVM and QEMU Architecture • VTx support • CPU virtualization in KMV • Memory virtualization techniques • shadow page table • EPT/NPT page table • IO virtualization in QEMU • KVM and QEMU usage • Virtual disk creation • Creating virtual machines • Copy-on-write disks Virtualization in Linux 2 KVM + QEMU - Architecture Virtualization in Linux 3 KVM + QEMU – Architecture • Need for hardware support • less privileged rings ( rings > 0) are not sufficient to run guest – sensitive unprivileged instructions • Should go for • Binary instrumentation/ patching • paravirtualization • VTx and AMD-V • 4 different address spaces - host physical, host virtual, guest physical and guest virtual Virtualization in Linux 4 X86 VTx support Guest 3 Guest User Guest 2 Guest 1 Guest 0 Guest Kernel Host 3 QEMU Host 2 Host 1 Host 0 KVM Communication Channels VMCS + vmx KVM /dev/kvm QEMU KVM Guest 0-3 instructions Virtualization in Linux 5 X86 VMX Instructions • Controls transition between VMX root and VMX non- root • VMX root -> VMX non-root - VM Entry • VMX non-root -> VMX root – VM Exit • Example instructions • VMXON – enables VMX Operation • VMXOFF – disable VMX Operation • VMLAUNCH – VM Entry • VMRESUME – VM Entry • VMREAD – read from VMCS • VMWRITE – write to VMCS Virtualization in Linux 6 X86 VMCS Structure • Controls CPU behavior in VTx non root mode • 4KB structure – configured by KVM • Also -

MS-DOS System Programmer's Guide I I Document No.: 819-000104-3001 Rev
~~ Advanced Ar-a..Personal Computer TM MSTM_DOS System Programmer's Guide NEe NEe Information Systems, Inc. 819-000104-3001 REV 00 9-83 , Important Notice (1) All rights reserved, This manual is protected by copyright. No part of this manual may be reproduced in any form whatsoever without the written permission of the copyright owner. (2) The policy of NEC being that of continuous product improvement, the contents of this manual are subject to change, from time to time, without notice. (3) All efforts have been made to ensure that the contents of this manual are correct; however, should any errors be detected, NEC would greatly appreciate being informed. (4) NEC can assume no responsibility for errors in this manual or their consequences. ©Copyright 1983 by NEC Corporation. MSTM-DOS, MACRO-86 Macro Assembler™, MS-LINK Linker UtilityTM, MS-LIB Library Mana gerTM, MS-CREpTM Cross Reference Utility, EDLIN Line Editor™ are registered trademarks of the Microsoft Corporation. PLEASE READ THE FOLLOWING TEXT CAREFULLY. IT COPYRIGHT CONSTITUTES A CONTINUATION OF THE PROGRAM LICENSE AGREEMENT FOR THE SOFTWARE APPLICA The name of the copyright holder of this software must be recorded TION PROGRAM CONTAINED IN THIS PACKAGE. exactly as it appears on the label of the original diskette as supplied by NECIS on a label attached to each additional copy you make. If you agree to all the terms and conditions contained in both parts You must maintain a record of the number and location of each of the Program License Agreement. please fill out the detachable copy of this program. -

KVM Message Passing Performance
Message Passing Workloads in KVM David Matlack, [email protected] 1 Overview Message Passing Workloads Loopback TCP_RR IPI and HLT DISCLAIMER: x86 and Intel VT-x Halt Polling Interrupts and questions are welcome! 2 Message Passing Workloads ● Usually, anything that frequently switches between running and idle. ● Event-driven workloads ○ Memcache ○ LAMP servers ○ Redis ● Multithreaded workloads using low latency wait/signal primitives for coordination. ○ Windows Event Objects ○ pthread_cond_wait / pthread_cond_signal ● Inter-process communication ○ TCP_RR (benchmark) 3 Message Passing Workloads Intuition: Workloads which don't involve IO virtualization should run at near native performance. Reality: Message Passing Workloads may not involve any IO but will still perform nX worse than native. ● (loopback) Memcache: 2x higher latency. ● Windows Event Objects: 3-4x higher latency. 4 Message Passing Workloads ● Microbenchmark: Loopback TCP_RR ○ Client and Server ping-pong 1-byte of data over an established TCP connection. ○ Loopback: No networking devices (real or virtual) involved. ○ Performance: Latency of each transaction. ● One transaction: 1. Send 1 byte 3. Receive 1 byte to server. (idle) from server. Client Server (idle) 2. Receive 1 byte from (idle) client. Send 1 byte back. 5 Loopback TCP_RR Performance Host: IvyBridge 3.11 Kernel Guest: Debian Wheezy Backports (3.16 Kernel) 3x higher latency 25 us slower 6 Virtual Overheads of TCP_RR ● Message Passing on 1 CPU ○ Context Switch ● Message Passing on >1 CPU ○ Interprocessor-Interrupts -

PIC12F752/HV752 Data Sheet
PIC12F752/HV752 8-Pin Flash-Based, 8-Bit CMOS Microcontrollers High-Performance RISC CPU Peripheral Features • Only 35 Instructions to Learn: • Five I/O Pins and One Input-only Pin - All single-cycle instructions except branches • High Current Source/Sink: • Operating Speed: - 50 mA I/O, (2 pins) - DC – 20 MHz clock input - 25 mA I/O, (3 pins) - DC – 200 ns instruction cycle • Two High-Speed Analog Comparator modules: • 1024 x 14 On-chip Flash Program Memory - 40 ns response time • Self Read/Write Program Memory - Fixed Voltage Reference (FVR) • 64 x 8 General Purpose Registers (SRAM) - Programmable on-chip voltage reference via • Interrupt Capability integrated 5-bit DAC • 8-Level Deep Hardware Stack - Internal/external inputs and outputs • Direct, Indirect and Relative Addressing modes (selectable) Microcontroller Features - Built-in Hysteresis (software selectable) • A/D Converter: • Precision Internal Oscillator: - 10-bit resolution - Factory calibrated to ±1%, typical - Four external channels - Software selectable frequency: - Two internal reference voltage channels 8 MHz, 4 MHz, 1 MHz or 31 kHz • Dual Range Digital-to-Analog Converter (DAC): - Software tunable - 5-bit resolution • Power-Saving Sleep mode - Full Range or Limited Range output • Voltage Range (PIC12F752): - 4 mV steps @ 2.0V (Limited Range) - 2.0V to 5.5V - 65 mV steps @ 2.0V (Full Range) • Shunt Voltage Regulator (PIC12HV752) • Fixed Voltage Reference (FVR), 1.2V reference - 2.0V to user defined • Capture, Compare, PWM (CCP) module: - 5-volt regulation - 16-bit Capture, max. resolution = 12.5 ns - 1 mA to 50 mA shunt range - Compare, max. resolution = 200 ns • Multiplexed Master Clear with Pull-up/Input Pin - 10-bit PWM, max. -

Intel X86 Assembly Language & Microarchitecture
Intel x86 Assembly Language & Microarchitecture #x86 Table of Contents About 1 Chapter 1: Getting started with Intel x86 Assembly Language & Microarchitecture 2 Remarks 2 Examples 2 x86 Assembly Language 2 x86 Linux Hello World Example 3 Chapter 2: Assemblers 6 Examples 6 Microsoft Assembler - MASM 6 Intel Assembler 6 AT&T assembler - as 7 Borland's Turbo Assembler - TASM 7 GNU assembler - gas 7 Netwide Assembler - NASM 8 Yet Another Assembler - YASM 9 Chapter 3: Calling Conventions 10 Remarks 10 Resources 10 Examples 10 32-bit cdecl 10 Parameters 10 Return Value 11 Saved and Clobbered Registers 11 64-bit System V 11 Parameters 11 Return Value 11 Saved and Clobbered Registers 11 32-bit stdcall 12 Parameters 12 Return Value 12 Saved and Clobbered Registers 12 32-bit, cdecl — Dealing with Integers 12 As parameters (8, 16, 32 bits) 12 As parameters (64 bits) 12 As return value 13 32-bit, cdecl — Dealing with Floating Point 14 As parameters (float, double) 14 As parameters (long double) 14 As return value 15 64-bit Windows 15 Parameters 15 Return Value 16 Saved and Clobbered Registers 16 Stack alignment 16 32-bit, cdecl — Dealing with Structs 16 Padding 16 As parameters (pass by reference) 17 As parameters (pass by value) 17 As return value 17 Chapter 4: Control Flow 19 Examples 19 Unconditional jumps 19 Relative near jumps 19 Absolute indirect near jumps 19 Absolute far jumps 19 Absolute indirect far jumps 20 Missing jumps 20 Testing conditions 20 Flags 21 Non-destructive tests 21 Signed and unsigned tests 22 Conditional jumps 22 Synonyms and terminology 22 Equality 22 Greater than 23 Less than 24 Specific flags 24 One more conditional jump (extra one) 25 Test arithmetic relations 25 Unsigned integers 25 Signed integers 26 a_label 26 Synonyms 27 Signed unsigned companion codes 27 Chapter 5: Converting decimal strings to integers 28 Remarks 28 Examples 28 IA-32 assembly, GAS, cdecl calling convention 28 MS-DOS, TASM/MASM function to read a 16-bit unsigned integer 29 Read a 16-bit unsigned integer from input. -

Intel® Architecture Instruction Set Extensions and Future Features
Intel® Architecture Instruction Set Extensions and Future Features Programming Reference May 2021 319433-044 Intel technologies may require enabled hardware, software or service activation. No product or component can be absolutely secure. Your costs and results may vary. You may not use or facilitate the use of this document in connection with any infringement or other legal analysis concerning Intel products described herein. You agree to grant Intel a non-exclusive, royalty-free license to any patent claim thereafter drafted which includes subject matter disclosed herein. No license (express or implied, by estoppel or otherwise) to any intellectual property rights is granted by this document. All product plans and roadmaps are subject to change without notice. The products described may contain design defects or errors known as errata which may cause the product to deviate from published specifications. Current characterized errata are available on request. Intel disclaims all express and implied warranties, including without limitation, the implied warranties of merchantability, fitness for a particular purpose, and non-infringement, as well as any warranty arising from course of performance, course of dealing, or usage in trade. Code names are used by Intel to identify products, technologies, or services that are in development and not publicly available. These are not “commercial” names and not intended to function as trademarks. Copies of documents which have an order number and are referenced in this document, or other Intel literature, may be ob- tained by calling 1-800-548-4725, or by visiting http://www.intel.com/design/literature.htm. Copyright © 2021, Intel Corporation. Intel, the Intel logo, and other Intel marks are trademarks of Intel Corporation or its subsidiaries. -

Controlling Processor C-State Usage in Linux
Controlling Processor C-State Usage in Linux A Dell technical white paper describing the use of C-states with Linux operating systems Stuart Hayes | Enterprise Linux Engineering Controlling Processor C-State Usage in Linux THIS DOCUMENT IS FOR INFORMATIONAL PURPOSES ONLY, AND MAY CONTAIN TYPOGRAPHICAL ERRORS AND TECHNICAL INACCURACIES. THE CONTENT IS PROVIDED AS IS, WITHOUT EXPRESS OR IMPLIED WARRANTIES OF ANY KIND. © 2013 Dell Inc. All rights reserved. Reproduction of this material in any manner whatsoever without the express written permission of Dell Inc. is strictly forbidden. For more information, contact Dell. Dell, the DELL logo, and the DELL badge are trademarks of Dell Inc. Intel and Xeon are registered trademarks of Intel Corporation in the U.S. and other countries. Other trademarks and trade names may be used in this document to refer to either the entities claiming the marks and names or their products. Dell Inc. disclaims any proprietary interest in trademarks and trade names other than its own. November 2013 | Revision 1.1 Page ii Controlling Processor C-State Usage in Linux Contents Introduction ................................................................................................................ 4 Background ................................................................................................................. 4 Checking C-State Usage .................................................................................................. 4 Disabling C-States for Low Latency ................................................................................... -

1 CS 3204 Operating Systems Pgy Announcements
Announcements • Please return your prerequisite forms if you haven’t done so CS 3204 • My office hours (MCB 637): – Tu 8-9:15am Oppgyerating Systems – Th 1:30pm-3:30pm (2:30pm if no one comes) • TA office hours announced later today, check website Lecture 2 • Start thinking about groups – (but *do not* collaborate on Project 0) Godmar Back • Project 0 due on Sep 7 – Other due dates posted later today CS 3204 Fall 20088/28/2008 2 Project 0 Outline for today • Implement User-level Memory Allocator • Motivation for teaching OS – Use address-ordered first-fit • Brief history • A survey of core issues OS address • What you should get out of this class start user object user object end free block used block free list CS 3204 Fall 20088/28/2008 3 CS 3204 Fall 20088/28/2008 4 Why are OS interesting? What does an OS do? • OS are “magic” • Software layer that sits – Most people don’t understand them – including sysadmins and computer scientists! between applications and hardware • OS are incredibly complex systems gcc csh X11 – “Hello, World” – program really 1 million lines of code • Studying OS is learning how to deal with • Performs services Operating System complexity – Abstracts hardware – Abstractions (+interfaces) Hardware – Modularity (+structure) – Provides protection CPU Memory Network Disk – Iteration (+learning from experience) – Manages resources CS 3204 Fall 20088/28/2008 5 CS 3204 Fall 20088/28/2008 6 1 OS vs Kernel Evolution of OS • Can take a wider view or a narrower definition what an • OSs as a library OS is – Abstracts away hardware, provide neat • Wide view: Windows, Linux, Mac OSX are operating systems interfaces – Includes system programs, system libraries, servers, shells, GUI • Makes software portable; allows software evolution etc. -

Torwards a More Scalable KVM Hypervisor
Torwards a more Scalable KVM Hypervisor KVM FORUM 2018 Wanpeng Li [email protected] Agenda • Paravirtualized TLB shootdown • Exitless IPIs • Disable mwait/hlt/pause vmexits to improve latency TLB Shootdown Preemption • When executing inside a virtual machine environment, OS level synchronization primitives such as locking, tlb shootdown and RCU are faced with significant challenges due to the scheduling behavior of the underlying host scheduler. Operations that are ensured to last only a short amount of time on bare-metal hardware, are capable of taking considerably longer when running virtualized. TLB Shootdown Preemption • A TLB is a cache of translation from memory virtual address to physical address. When a CPU changes virtual to physical mapping of an address, it needs to invalidate other CPUs' stale mapping in their respective caches. This process is called TLB shootdown. • Modern operating systems consider TLB shootdown operations to be performance critical and so optimize them to exhibit very low latency. The implementation of these operations is therefore architected to ensure that shootdowns can be completed with very low latencies through the use of IPI based signalling. TLB Shootdown Preemption • Remote TLB flush does a busy wait which is fine in bare-metal scenario. But with-in the guest, the vCPUs might have been pre-empted or blocked. In this scenario, the initiator vCPU would end up busy-waiting for a long amount of time; it also consumes CPU unnecessarily to wake up the target of the shootdown. TLB Shootdown Preemption • The time between the preemption and rescheduling of a remote target vCPU is often orders of magnitude larger than the latency that TLB Shootdown operations were designed for.