Intel X86 Assembly Language Cheat Sheet
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

6.004 Computation Structures Spring 2009
MIT OpenCourseWare http://ocw.mit.edu 6.004 Computation Structures Spring 2009 For information about citing these materials or our Terms of Use, visit: http://ocw.mit.edu/terms. M A S S A C H U S E T T S I N S T I T U T E O F T E C H N O L O G Y DEPARTMENT OF ELECTRICAL ENGINEERING AND COMPUTER SCIENCE 6.004 Computation Structures β Documentation 1. Introduction This handout is a reference guide for the β, the RISC processor design for 6.004. This is intended to be a complete and thorough specification of the programmer-visible state and instruction set. 2. Machine Model The β is a general-purpose 32-bit architecture: all registers are 32 bits wide and when loaded with an address can point to any location in the byte-addressed memory. When read, register 31 is always 0; when written, the new value is discarded. Program Counter Main Memory PC always a multiple of 4 0x00000000: 3 2 1 0 0x00000004: 32 bits … Registers SUB(R3,R4,R5) 232 bytes R0 ST(R5,1000) R1 … … R30 0xFFFFFFF8: R31 always 0 0xFFFFFFFC: 32 bits 32 bits 3. Instruction Encoding Each β instruction is 32 bits long. All integer manipulation is between registers, with up to two source operands (one may be a sign-extended 16-bit literal), and one destination register. Memory is referenced through load and store instructions that perform no other computation. Conditional branch instructions are separated from comparison instructions: branch instructions test the value of a register that can be the result of a previous compare instruction. -

Mac Labs. More Creativity
Mac labs. More creativity. More engagement. More learning. Every Mac comes ready for 21st-century learning. Mac OS X Server creates the ultimate lab environment. Creativity and innovation are critical skills in the modern Mac OS X Server includes simplified tools for creating wikis and workplace, which makes them critical skills to teach today’s blogs, so students and staff can set up and manage them with students. Apple offers comprehensive lab solutions for your little or no help from IT. The Spotlight Server feature makes it school or university that will creatively engage students and easy for students collaborating on projects to find and view motivate them to take an interest in their own learning. The content stored anywhere on the network. Of course, access iLife ’09 suite of applications comes standard on every Mac, controls are built in, so they only get the search results they’re so students can immediately begin creating podcasts, editing authorised to see. Mac OS X Server also allows for real-time videos, composing music, producing photo essays and more. streaming of audio and video content, which lets everyone get right to work instead of waiting for downloads – saving major Mac or PC? Have both. storage across your network. Now one lab really can solve all your computing needs. Every Mac is powered by an Intel processor and features Launch careers from your Mac lab. Mac OS X – the world’s most advanced operating system. As an Apple Authorised Training Centre for Education, your Mac OS X comes with an amazing dual-boot feature called school can build a bridge between students and real-world Boot Camp that lets students run Windows XP or Vista natively careers. -

Lecture Notes in Assembly Language
Lecture Notes in Assembly Language Short introduction to low-level programming Piotr Fulmański Łódź, 12 czerwca 2015 Spis treści Spis treści iii 1 Before we begin1 1.1 Simple assembler.................................... 1 1.1.1 Excercise 1 ................................... 2 1.1.2 Excercise 2 ................................... 3 1.1.3 Excercise 3 ................................... 3 1.1.4 Excercise 4 ................................... 5 1.1.5 Excercise 5 ................................... 6 1.2 Improvements, part I: addressing........................... 8 1.2.1 Excercise 6 ................................... 11 1.3 Improvements, part II: indirect addressing...................... 11 1.4 Improvements, part III: labels............................. 18 1.4.1 Excercise 7: find substring in a string .................... 19 1.4.2 Excercise 8: improved polynomial....................... 21 1.5 Improvements, part IV: flag register ......................... 23 1.6 Improvements, part V: the stack ........................... 24 1.6.1 Excercise 12................................... 26 1.7 Improvements, part VI – function stack frame.................... 29 1.8 Finall excercises..................................... 34 1.8.1 Excercise 13................................... 34 1.8.2 Excercise 14................................... 34 1.8.3 Excercise 15................................... 34 1.8.4 Excercise 16................................... 34 iii iv SPIS TREŚCI 1.8.5 Excercise 17................................... 34 2 First program 37 2.1 Compiling, -

ARM Instruction Set
4 ARM Instruction Set This chapter describes the ARM instruction set. 4.1 Instruction Set Summary 4-2 4.2 The Condition Field 4-5 4.3 Branch and Exchange (BX) 4-6 4.4 Branch and Branch with Link (B, BL) 4-8 4.5 Data Processing 4-10 4.6 PSR Transfer (MRS, MSR) 4-17 4.7 Multiply and Multiply-Accumulate (MUL, MLA) 4-22 4.8 Multiply Long and Multiply-Accumulate Long (MULL,MLAL) 4-24 4.9 Single Data Transfer (LDR, STR) 4-26 4.10 Halfword and Signed Data Transfer 4-32 4.11 Block Data Transfer (LDM, STM) 4-37 4.12 Single Data Swap (SWP) 4-43 4.13 Software Interrupt (SWI) 4-45 4.14 Coprocessor Data Operations (CDP) 4-47 4.15 Coprocessor Data Transfers (LDC, STC) 4-49 4.16 Coprocessor Register Transfers (MRC, MCR) 4-53 4.17 Undefined Instruction 4-55 4.18 Instruction Set Examples 4-56 ARM7TDMI-S Data Sheet 4-1 ARM DDI 0084D Final - Open Access ARM Instruction Set 4.1 Instruction Set Summary 4.1.1 Format summary The ARM instruction set formats are shown below. 3 3 2 2 2 2 2 2 2 2 2 2 1 1 1 1 1 1 1 1 1 1 9876543210 1 0 9 8 7 6 5 4 3 2 1 0 9 8 7 6 5 4 3 2 1 0 Cond 0 0 I Opcode S Rn Rd Operand 2 Data Processing / PSR Transfer Cond 0 0 0 0 0 0 A S Rd Rn Rs 1 0 0 1 Rm Multiply Cond 0 0 0 0 1 U A S RdHi RdLo Rn 1 0 0 1 Rm Multiply Long Cond 0 0 0 1 0 B 0 0 Rn Rd 0 0 0 0 1 0 0 1 Rm Single Data Swap Cond 0 0 0 1 0 0 1 0 1 1 1 1 1 1 1 1 1 1 1 1 0 0 0 1 Rn Branch and Exchange Cond 0 0 0 P U 0 W L Rn Rd 0 0 0 0 1 S H 1 Rm Halfword Data Transfer: register offset Cond 0 0 0 P U 1 W L Rn Rd Offset 1 S H 1 Offset Halfword Data Transfer: immediate offset Cond 0 -

Integrated Step-Down Converter with SVID Interface for Intel® CPU
Product Order Technical Tools & Support & Folder Now Documents Software Community TPS53820 SLUSE33 –FEBRUARY 2020 Integrated Step-Down Converter with SVID Interface for Intel® CPU Power Supply 1 Features 3 Description The TPS53820 device is D-CAP+ mode integrated 1• Single chip to support Intel VR13.HC SVID POL applications step-down converter for low current SVID rails of Intel CPU power supply. It provides up to two outputs to • Two outputs to support VCCANA (5.5 A) and power the low current SVID rails such as VCCANA P1V8 (4 A) (5.5 A) and P1V8 (4 A). The device employs D-CAP+ • D-CAP+™ Control for Fast Transient Response mode control to provide fast load transient • Wide Input Voltage (4.5 V to 15 V) performance. Internal compensation allows ease of use and reduces external components. • Differential Remote Sense • Programmable Internal Loop Compensation The device also provides telemetry, including input voltage, output voltage, output current and • Per-Phase Cycle-by-Cycle Current Limit temperature reporting. Over voltage, over current and • Programmable Frequency from 800 kHz to 2 MHz over temperature protections are provided as well. 2 • I C System Interface for Telemetry of Voltage, The TPS53820 device is packaged in a thermally Current, Output Power, Temperature, and Fault enhanced 35-pin QFN and operates between –40°C Conditions and 125°C. • Over-Current, Over-Voltage, Over-Temperature (1) protections Table 1. Device Information • Low Quiescent Current PART NUMBER PACKAGE BODY SIZE (NOM) • 5 mm × 5 mm, 35-Pin QFN, PowerPAD Package TPS53820 RWZ (35) 5 mm × 5 mm (1) For all available packages, see the orderable addendum at 2 Applications the end of the data sheet. -

Introduction to Intel® FPGA IP Cores
Introduction to Intel® FPGA IP Cores Updated for Intel® Quartus® Prime Design Suite: 20.3 Subscribe UG-01056 | 2020.11.09 Send Feedback Latest document on the web: PDF | HTML Contents Contents 1. Introduction to Intel® FPGA IP Cores..............................................................................3 1.1. IP Catalog and Parameter Editor.............................................................................. 4 1.1.1. The Parameter Editor................................................................................. 5 1.2. Installing and Licensing Intel FPGA IP Cores.............................................................. 5 1.2.1. Intel FPGA IP Evaluation Mode.....................................................................6 1.2.2. Checking the IP License Status.................................................................... 8 1.2.3. Intel FPGA IP Versioning............................................................................. 9 1.2.4. Adding IP to IP Catalog...............................................................................9 1.3. Best Practices for Intel FPGA IP..............................................................................10 1.4. IP General Settings.............................................................................................. 11 1.5. Generating IP Cores (Intel Quartus Prime Pro Edition)...............................................12 1.5.1. IP Core Generation Output (Intel Quartus Prime Pro Edition)..........................13 1.5.2. Scripting IP Core Generation.................................................................... -

Introducing the New 11Th Gen Intel® Core™ Desktop Processors
Product Brief 11th Gen Intel® Core™ Desktop Processors Introducing the New 11th Gen Intel® Core™ Desktop Processors The 11th Gen Intel® Core™ desktop processor family puts you in control of your compute experience. It features an innovative new architecture for reimag- ined performance, immersive display and graphics for incredible visuals, and a range of options and technologies for enhanced tuning. When these advances come together, you have everything you need for fast-paced professional work, elite gaming, inspired creativity, and extreme tuning. The 11th Gen Intel® Core™ desktop processor family gives you the power to perform, compete, excel, and power your greatest contributions. Product Brief 11th Gen Intel® Core™ Desktop Processors PERFORMANCE Reimagined Performance 11th Gen Intel® Core™ desktop processors are intelligently engineered to push the boundaries of performance. The new processor core architecture transforms hardware and software efficiency and takes advantage of Intel® Deep Learning Boost to accelerate AI performance. Key platform improvements include memory support up to DDR4-3200, up to 20 CPU PCIe 4.0 lanes,1 integrated USB 3.2 Gen 2x2 (20G), and Intel® Optane™ memory H20 with SSD support.2 Together, these technologies bring the power and the intelligence you need to supercharge productivity, stay in the creative flow, and game at the highest level. Product Brief 11th Gen Intel® Core™ Desktop Processors Experience rich, stunning, seamless visuals with the high-performance graphics on 11th Gen Intel® Core™ desktop -

Towards Scalable Multiprocessor Virtual Machines
USENIX Association Proceedings of the Third Virtual Machine Research and Technology Symposium San Jose, CA, USA May 6–7, 2004 © 2004 by The USENIX Association All Rights Reserved For more information about the USENIX Association: Phone: 1 510 528 8649 FAX: 1 510 548 5738 Email: [email protected] WWW: http://www.usenix.org Rights to individual papers remain with the author or the author's employer. Permission is granted for noncommercial reproduction of the work for educational or research purposes. This copyright notice must be included in the reproduced paper. USENIX acknowledges all trademarks herein. Towards Scalable Multiprocessor Virtual Machines Volkmar Uhlig Joshua LeVasseur Espen Skoglund Uwe Dannowski System Architecture Group Universitat¨ Karlsruhe [email protected] Abstract of guests, such that they only ever access a fraction of the physical processors, or alternatively time-multiplex A multiprocessor virtual machine benefits its guest guests across a set of physical processors to, e.g., ac- operating system in supporting scalable job throughput commodate for spikes in guest OS workloads. It can and request latency—useful properties in server consol- also map guest operating systems to virtual processors idation where servers require several of the system pro- (which can exceed the number of physical processors), cessors for steady state or to handle load bursts. and migrate between physical processors without no- Typical operating systems, optimized for multipro- tifying the guest operating systems. This allows for, cessor systems in their use of spin-locks for critical sec- e.g., migration to other machine configurations or hot- tions, can defeat flexible virtual machine scheduling due swapping of CPUs without adequate support from the to lock-holder preemption and misbalanced load. -

Introduction to X86 Assembly
CS342 Computer Security Handout # 5 Prof. Lyn Turbak Monday, Oct. 04, 2010 Wellesley College Lab 4: Introduction to x86 Assembly Reading: Hacking, 0x250, 0x270 Overview Today, we continue to cover low-level programming details that are essential for understanding software vulnerabilities like buffer overflow attacks and format string exploits. You will get exposure to the following: • Understanding conventions used by compiler to translate high-level programs to low-level assembly code (in our case, using Gnu C Compiler (gcc) to compile C programs). • The ability to read low-level assembly code (in our case, Intel x86). • Understanding how assembly code instructions are represented as machine code. • Being able to use gdb (the Gnu Debugger) to read the low-level code produced by gcc and understand its execution. In tutorials based on this handout, we will learn about all of the above in the context of some simple examples. Intel x86 Assembly Language Since Intel x86 processors are ubiquitous, it is helpful to know how to read assembly code for these processors. We will use the following terms: byte refers to 8-bit quantities; short word refers to 16-bit quantities; word refers to 32-bit quantities; and long word refers to 64-bit quantities. There are many registers, but we mostly care about the following: • EAX, EBX, ECX, EDX are 32-bit registers used for general storage. • ESI and EDI are 32-bit indexing registers that are sometimes used for general storage. • ESP is the 32-bit register for the stack pointer, which holds the address of the element currently at the top of the stack. -

Superh RISC Engine SH-1/SH-2
SuperH RISC Engine SH-1/SH-2 Programming Manual September 3, 1996 Hitachi America Ltd. Notice When using this document, keep the following in mind: 1. This document may, wholly or partially, be subject to change without notice. 2. All rights are reserved: No one is permitted to reproduce or duplicate, in any form, the whole or part of this document without Hitachi’s permission. 3. Hitachi will not be held responsible for any damage to the user that may result from accidents or any other reasons during operation of the user’s unit according to this document. 4. Circuitry and other examples described herein are meant merely to indicate the characteristics and performance of Hitachi’s semiconductor products. Hitachi assumes no responsibility for any intellectual property claims or other problems that may result from applications based on the examples described herein. 5. No license is granted by implication or otherwise under any patents or other rights of any third party or Hitachi, Ltd. 6. MEDICAL APPLICATIONS: Hitachi’s products are not authorized for use in MEDICAL APPLICATIONS without the written consent of the appropriate officer of Hitachi’s sales company. Such use includes, but is not limited to, use in life support systems. Buyers of Hitachi’s products are requested to notify the relevant Hitachi sales offices when planning to use the products in MEDICAL APPLICATIONS. Introduction The SuperH RISC engine family incorporates a RISC (Reduced Instruction Set Computer) type CPU. A basic instruction can be executed in one clock cycle, realizing high performance operation. A built-in multiplier can execute multiplication and addition as quickly as DSP. -
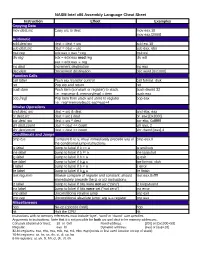
NASM Intel X86 Assembly Language Cheat Sheet
NASM Intel x86 Assembly Language Cheat Sheet Instruction Effect Examples Copying Data mov dest,src Copy src to dest mov eax,10 mov eax,[2000] Arithmetic add dest,src dest = dest + src add esi,10 sub dest,src dest = dest – src sub eax, ebx mul reg edx:eax = eax * reg mul esi div reg edx = edx:eax mod reg div edi eax = edx:eax reg inc dest Increment destination inc eax dec dest Decrement destination dec word [0x1000] Function Calls call label Push eip, transfer control call format_disk ret Pop eip and return ret push item Push item (constant or register) to stack. push dword 32 I.e.: esp=esp-4; memory[esp] = item push eax pop [reg] Pop item from stack and store to register pop eax I.e.: reg=memory[esp]; esp=esp+4 Bitwise Operations and dest, src dest = src & dest and ebx, eax or dest,src dest = src | dest or eax,[0x2000] xor dest, src dest = src ^ dest xor ebx, 0xfffffff shl dest,count dest = dest << count shl eax, 2 shr dest,count dest = dest >> count shr dword [eax],4 Conditionals and Jumps cmp b,a Compare b to a; must immediately precede any of cmp eax,0 the conditional jump instructions je label Jump to label if b == a je endloop jne label Jump to label if b != a jne loopstart jg label Jump to label if b > a jg exit jge label Jump to label if b > a jge format_disk jl label Jump to label if b < a jl error jle label Jump to label if b < a jle finish test reg,imm Bitwise compare of register and constant; should test eax,0xffff immediately precede the jz or jnz instructions jz label Jump to label if bits were not set (“zero”) jz looparound jnz label Jump to label if bits were set (“not zero”) jnz error jmp label Unconditional relative jump jmp exit jmp reg Unconditional absolute jump; arg is a register jmp eax Miscellaneous nop No-op (opcode 0x90) nop hlt Halt the CPU hlt Instructions with no memory references must include ‘byte’, ‘word’ or ‘dword’ size specifier. -

Assembly Language
Assembly Language University of Texas at Austin CS310H - Computer Organization Spring 2010 Don Fussell Human-Readable Machine Language Computers like ones and zeros… 0001110010000110 Humans like symbols… ADD R6,R2,R6 ; increment index reg. Assembler is a program that turns symbols into machine instructions. ISA-specific: close correspondence between symbols and instruction set mnemonics for opcodes labels for memory locations additional operations for allocating storage and initializing data University of Texas at Austin CS310H - Computer Organization Spring 2010 Don Fussell 2 An Assembly Language Program ; ; Program to multiply a number by the constant 6 ; .ORIG x3050 LD R1, SIX LD R2, NUMBER AND R3, R3, #0 ; Clear R3. It will ; contain the product. ; The inner loop ; AGAIN ADD R3, R3, R2 ADD R1, R1, #-1 ; R1 keeps track of BRp AGAIN ; the iteration. ; HALT ; NUMBER .BLKW 1 SIX .FILL x0006 ; .END University of Texas at Austin CS310H - Computer Organization Spring 2010 Don Fussell 3 LC-3 Assembly Language Syntax Each line of a program is one of the following: an instruction an assember directive (or pseudo-op) a comment Whitespace (between symbols) and case are ignored. Comments (beginning with “;”) are also ignored. An instruction has the following format: LABEL OPCODE OPERANDS ; COMMENTS optional mandatory University of Texas at Austin CS310H - Computer Organization Spring 2010 Don Fussell 4 Opcodes and Operands Opcodes reserved symbols that correspond to LC-3 instructions listed in Appendix A ex: ADD, AND, LD, LDR, … Operands registers