Controlling Processor C-State Usage in Linux
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Enea® Linux 4.0 Release Information
Enea® Linux 4.0 Release Information 4.0-docupdate1 Enea® Linux 4.0 Release Information Enea® Linux 4.0 Release Information Copyright Copyright © Enea Software AB 2014. This User Documentation consists of confidential information and is protected by Trade Secret Law. This notice of copyright does not indicate any actual or intended publication of this information. Except to the extent expressly stipulated in any software license agreement covering this User Documentation and/or corresponding software, no part of this User Documentation may be reproduced, transmitted, stored in a retrieval system, or translated, in any form or by any means, without the prior written permission of Enea Software AB. However, permission to print copies for personal use is hereby granted. Disclaimer The information in this User Documentation is subject to change without notice, and unless stipulated in any software license agreement covering this User Documentation and/or corresponding software, should not be construed as a commitment of Enea Software AB. Trademarks Enea®, Enea OSE®, and Polyhedra® are the registered trademarks of Enea AB and its subsidiaries. Enea OSE®ck, Enea OSE® Epsilon, Enea® Element, Enea® Optima, Enea® Linux, Enea® LINX, Enea® LWRT, Enea® Accelerator, Polyhedra® Flash DBMS, Polyhedra® Lite, Enea® dSPEED, Accelerating Network Convergence™, Device Software Optimized™, and Embedded for Leaders™ are unregistered trademarks of Enea AB or its subsidiaries. Any other company, product or service names mentioned in this document are the registered or unregistered trade- marks of their respective owner. Acknowledgements and Open Source License Conditions Information is found in the Release Information manual. © Enea Software AB 2014 4.0-docupdate1 ii Enea® Linux 4.0 Release Information Table of Contents 1 - About This Release ..................................................................................................... -

Towards Scalable Multiprocessor Virtual Machines
USENIX Association Proceedings of the Third Virtual Machine Research and Technology Symposium San Jose, CA, USA May 6–7, 2004 © 2004 by The USENIX Association All Rights Reserved For more information about the USENIX Association: Phone: 1 510 528 8649 FAX: 1 510 548 5738 Email: [email protected] WWW: http://www.usenix.org Rights to individual papers remain with the author or the author's employer. Permission is granted for noncommercial reproduction of the work for educational or research purposes. This copyright notice must be included in the reproduced paper. USENIX acknowledges all trademarks herein. Towards Scalable Multiprocessor Virtual Machines Volkmar Uhlig Joshua LeVasseur Espen Skoglund Uwe Dannowski System Architecture Group Universitat¨ Karlsruhe [email protected] Abstract of guests, such that they only ever access a fraction of the physical processors, or alternatively time-multiplex A multiprocessor virtual machine benefits its guest guests across a set of physical processors to, e.g., ac- operating system in supporting scalable job throughput commodate for spikes in guest OS workloads. It can and request latency—useful properties in server consol- also map guest operating systems to virtual processors idation where servers require several of the system pro- (which can exceed the number of physical processors), cessors for steady state or to handle load bursts. and migrate between physical processors without no- Typical operating systems, optimized for multipro- tifying the guest operating systems. This allows for, cessor systems in their use of spin-locks for critical sec- e.g., migration to other machine configurations or hot- tions, can defeat flexible virtual machine scheduling due swapping of CPUs without adequate support from the to lock-holder preemption and misbalanced load. -

Linux Kernel and Driver Development Training Slides
Linux Kernel and Driver Development Training Linux Kernel and Driver Development Training © Copyright 2004-2021, Bootlin. Creative Commons BY-SA 3.0 license. Latest update: October 9, 2021. Document updates and sources: https://bootlin.com/doc/training/linux-kernel Corrections, suggestions, contributions and translations are welcome! embedded Linux and kernel engineering Send them to [email protected] - Kernel, drivers and embedded Linux - Development, consulting, training and support - https://bootlin.com 1/470 Rights to copy © Copyright 2004-2021, Bootlin License: Creative Commons Attribution - Share Alike 3.0 https://creativecommons.org/licenses/by-sa/3.0/legalcode You are free: I to copy, distribute, display, and perform the work I to make derivative works I to make commercial use of the work Under the following conditions: I Attribution. You must give the original author credit. I Share Alike. If you alter, transform, or build upon this work, you may distribute the resulting work only under a license identical to this one. I For any reuse or distribution, you must make clear to others the license terms of this work. I Any of these conditions can be waived if you get permission from the copyright holder. Your fair use and other rights are in no way affected by the above. Document sources: https://github.com/bootlin/training-materials/ - Kernel, drivers and embedded Linux - Development, consulting, training and support - https://bootlin.com 2/470 Hyperlinks in the document There are many hyperlinks in the document I Regular hyperlinks: https://kernel.org/ I Kernel documentation links: dev-tools/kasan I Links to kernel source files and directories: drivers/input/ include/linux/fb.h I Links to the declarations, definitions and instances of kernel symbols (functions, types, data, structures): platform_get_irq() GFP_KERNEL struct file_operations - Kernel, drivers and embedded Linux - Development, consulting, training and support - https://bootlin.com 3/470 Company at a glance I Engineering company created in 2004, named ”Free Electrons” until Feb. -

Fixing USB Autosuspend Serge Y
Fixing USB Autosuspend Serge Y. Stroobandt Copyright 2015–2017, licensed under Creative Commons BY-NC-SA Problem The Linux kernel automatically suspends USB de- vices when there is driver support and the devices are not in use.1 This saves quite a bit of power. How- ever, some USB devices are not compatible with USB autosuspend and will misbehave at some point. Af- fected devices are most commonly USB mice and keyboards.2 Personally,I had only one Microsoft™ Wheel Mouse Optical affected, despitewning o other mod- els of the same brand. In essence, this is not really a USB hardware problem, but perhaps more a Lin- ux problem. The actual fault lies with a misinterpretation of the eXtensible Host Controller Interface (xHCI) specification. This issueviousl pre y did not exist with the older Enhanced Host Controller Interface (EHCI) specification. A «Sharp» explanation is available online.3 The Linux kernel patch for this problem will probably one day automatically trickle in downstream and onto my affectedubuntu X LTS 14.04 system. Nonetheless, with a crashing computer mouse at hand, things cannot wait. However, patching my current 3.13.0-35-generic x86_64 kernel is out of the question! We will rather grab this opportunity to learn a bit about writing rules for udev , the device manager for the Linux kernel. I am writing “for the Linux kernel”, because udev executes entirely in user space. Identify the device First, one needs to properly identify the affected USBvice de by its vendor and product ID. Run the following command and look for the device description. -
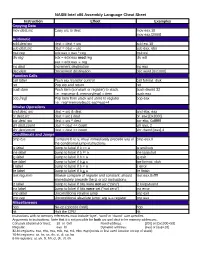
NASM Intel X86 Assembly Language Cheat Sheet
NASM Intel x86 Assembly Language Cheat Sheet Instruction Effect Examples Copying Data mov dest,src Copy src to dest mov eax,10 mov eax,[2000] Arithmetic add dest,src dest = dest + src add esi,10 sub dest,src dest = dest – src sub eax, ebx mul reg edx:eax = eax * reg mul esi div reg edx = edx:eax mod reg div edi eax = edx:eax reg inc dest Increment destination inc eax dec dest Decrement destination dec word [0x1000] Function Calls call label Push eip, transfer control call format_disk ret Pop eip and return ret push item Push item (constant or register) to stack. push dword 32 I.e.: esp=esp-4; memory[esp] = item push eax pop [reg] Pop item from stack and store to register pop eax I.e.: reg=memory[esp]; esp=esp+4 Bitwise Operations and dest, src dest = src & dest and ebx, eax or dest,src dest = src | dest or eax,[0x2000] xor dest, src dest = src ^ dest xor ebx, 0xfffffff shl dest,count dest = dest << count shl eax, 2 shr dest,count dest = dest >> count shr dword [eax],4 Conditionals and Jumps cmp b,a Compare b to a; must immediately precede any of cmp eax,0 the conditional jump instructions je label Jump to label if b == a je endloop jne label Jump to label if b != a jne loopstart jg label Jump to label if b > a jg exit jge label Jump to label if b > a jge format_disk jl label Jump to label if b < a jl error jle label Jump to label if b < a jle finish test reg,imm Bitwise compare of register and constant; should test eax,0xffff immediately precede the jz or jnz instructions jz label Jump to label if bits were not set (“zero”) jz looparound jnz label Jump to label if bits were set (“not zero”) jnz error jmp label Unconditional relative jump jmp exit jmp reg Unconditional absolute jump; arg is a register jmp eax Miscellaneous nop No-op (opcode 0x90) nop hlt Halt the CPU hlt Instructions with no memory references must include ‘byte’, ‘word’ or ‘dword’ size specifier. -

Optimizing HLT Code for Run-Time Efficiency
Optimizing HLT code for run-time efficiency Public Note Issue: 1 Revision: 0 Reference: LHCb-PUB-2010-017 Created: September 6, 2010 Last modified: November 4, 2010 LHCb-PUB-2010-017 04/11/2010 Prepared by: Axel Thuressona, Niko Neufeldb aLund,Sweden bCERN, PH Optimizing HLT code for run-time efficiency Ref: LHCb-PUB-2010-017 Public Note Issue: 1 Date: November 4, 2010 Abstract An upgrade of the High level trigger (HLT) farm at LHCb will be inevitable due to the increase in luminosity at the LHC. The upgrade will be done in two main ways. The first way is to make the software more efficient and faster. The second way is to increase the number of servers in the farm. This paper will concern both of these two ways divided into three parts. The first part is about NUMA, modern servers are all built with NUMA so an upgrade of the HLT farm will consist of this new architecture. The present HLT farm servers consists of the architecture UMA. After several tests it turned out that the Intel-servers that was used for testing (having 2 nodes) had very little penalty when comparing the worst-case the optimal-case. The conclusions for Intel-servers are that the NUMA architecture doesn’t affect the existing software negative. Several tests was done on an AMD-server having 8 nodes, and hence a more complicated structure. Non-optimal effects could be observed for this server and when comparing the worst-case with the optimal-case a big difference was found. So for the AMD-server the NUMA architecture can affect the existing software negative under certain circumstances. -

Powerkap - a Tool for Improving Energy Transparency for Software Developers on GNU/Linux (X86) Platforms
Project Report Department of Computing Imperial College of Science, Technology and Medicine PowerKap - A tool for Improving Energy Transparency for Software Developers on GNU/Linux (x86) platforms Author: Supervisor: Krish De Souza Dr. Anandha Gopalan Submitted in partial fulfilment of the requirements for the M.Eng Computing 4 of Imperial College London Contents 1 Introduction 6 1.1 Motivation . .6 1.2 Objectives . .7 1.3 Achievements . .7 2 Background 9 2.1 The relationship between power and energy. .9 2.2 Power controls on x86 platforms . .9 2.3 Improving software for power efficiency . 10 2.3.1 Algorithm . 10 2.3.2 Multithreading . 10 2.3.3 Vectorisation . 10 2.3.4 Improper sleep loops . 12 2.3.5 OS Timers . 13 2.3.6 Context aware programming . 13 2.4 Current methods of monitoring energy. 14 2.4.1 Out of Band Energy Monitor . 14 2.4.2 In-Band Energy Monitor . 14 2.4.2.1 Powertop . 15 2.4.2.2 Turbostat . 16 2.5 Related Work . 16 2.5.1 ENTRA 2012-2015 . 16 2.5.1.1 Common Assertion Language . 16 2.5.1.2 Compiler Optimisation and Power Trade-offs . 18 2.5.1.3 Superoptimization . 18 2.5.1.4 Thermal trade-off . 20 2.5.2 eProf . 20 2.5.2.1 Asynchronous vs Synchronous . 20 2.5.2.2 Profiling implementation . 21 2.5.3 Energy Formal Definitions . 21 2.5.3.1 Java Based Energy Formalism . 22 2.5.3.2 Energy Application Model . 22 2.5.4 Impact of language, Compiler, Optimisations . -

SUSE Linux Enterprise Server 12 SP4 System Analysis and Tuning Guide System Analysis and Tuning Guide SUSE Linux Enterprise Server 12 SP4
SUSE Linux Enterprise Server 12 SP4 System Analysis and Tuning Guide System Analysis and Tuning Guide SUSE Linux Enterprise Server 12 SP4 An administrator's guide for problem detection, resolution and optimization. Find how to inspect and optimize your system by means of monitoring tools and how to eciently manage resources. Also contains an overview of common problems and solutions and of additional help and documentation resources. Publication Date: September 24, 2021 SUSE LLC 1800 South Novell Place Provo, UT 84606 USA https://documentation.suse.com Copyright © 2006– 2021 SUSE LLC and contributors. All rights reserved. Permission is granted to copy, distribute and/or modify this document under the terms of the GNU Free Documentation License, Version 1.2 or (at your option) version 1.3; with the Invariant Section being this copyright notice and license. A copy of the license version 1.2 is included in the section entitled “GNU Free Documentation License”. For SUSE trademarks, see https://www.suse.com/company/legal/ . All other third-party trademarks are the property of their respective owners. Trademark symbols (®, ™ etc.) denote trademarks of SUSE and its aliates. Asterisks (*) denote third-party trademarks. All information found in this book has been compiled with utmost attention to detail. However, this does not guarantee complete accuracy. Neither SUSE LLC, its aliates, the authors nor the translators shall be held liable for possible errors or the consequences thereof. Contents About This Guide xii 1 Available Documentation xiii -

Understanding the Linux Kernel, 3Rd Edition by Daniel P
1 Understanding the Linux Kernel, 3rd Edition By Daniel P. Bovet, Marco Cesati ............................................... Publisher: O'Reilly Pub Date: November 2005 ISBN: 0-596-00565-2 Pages: 942 Table of Contents | Index In order to thoroughly understand what makes Linux tick and why it works so well on a wide variety of systems, you need to delve deep into the heart of the kernel. The kernel handles all interactions between the CPU and the external world, and determines which programs will share processor time, in what order. It manages limited memory so well that hundreds of processes can share the system efficiently, and expertly organizes data transfers so that the CPU isn't kept waiting any longer than necessary for the relatively slow disks. The third edition of Understanding the Linux Kernel takes you on a guided tour of the most significant data structures, algorithms, and programming tricks used in the kernel. Probing beyond superficial features, the authors offer valuable insights to people who want to know how things really work inside their machine. Important Intel-specific features are discussed. Relevant segments of code are dissected line by line. But the book covers more than just the functioning of the code; it explains the theoretical underpinnings of why Linux does things the way it does. This edition of the book covers Version 2.6, which has seen significant changes to nearly every kernel subsystem, particularly in the areas of memory management and block devices. The book focuses on the following topics: • Memory management, including file buffering, process swapping, and Direct memory Access (DMA) • The Virtual Filesystem layer and the Second and Third Extended Filesystems • Process creation and scheduling • Signals, interrupts, and the essential interfaces to device drivers • Timing • Synchronization within the kernel • Interprocess Communication (IPC) • Program execution Understanding the Linux Kernel will acquaint you with all the inner workings of Linux, but it's more than just an academic exercise. -

Virtualization in Linux KVM + QEMU
CS695 Topics in Virtualization and Cloud Computing Virtualization in Linux KVM + QEMU Senthil, Puru, Prateek and Shashank Virtualization in Linux 1 Topics covered • KVM and QEMU Architecture • VTx support • CPU virtualization in KMV • Memory virtualization techniques • shadow page table • EPT/NPT page table • IO virtualization in QEMU • KVM and QEMU usage • Virtual disk creation • Creating virtual machines • Copy-on-write disks Virtualization in Linux 2 KVM + QEMU - Architecture Virtualization in Linux 3 KVM + QEMU – Architecture • Need for hardware support • less privileged rings ( rings > 0) are not sufficient to run guest – sensitive unprivileged instructions • Should go for • Binary instrumentation/ patching • paravirtualization • VTx and AMD-V • 4 different address spaces - host physical, host virtual, guest physical and guest virtual Virtualization in Linux 4 X86 VTx support Guest 3 Guest User Guest 2 Guest 1 Guest 0 Guest Kernel Host 3 QEMU Host 2 Host 1 Host 0 KVM Communication Channels VMCS + vmx KVM /dev/kvm QEMU KVM Guest 0-3 instructions Virtualization in Linux 5 X86 VMX Instructions • Controls transition between VMX root and VMX non- root • VMX root -> VMX non-root - VM Entry • VMX non-root -> VMX root – VM Exit • Example instructions • VMXON – enables VMX Operation • VMXOFF – disable VMX Operation • VMLAUNCH – VM Entry • VMRESUME – VM Entry • VMREAD – read from VMCS • VMWRITE – write to VMCS Virtualization in Linux 6 X86 VMCS Structure • Controls CPU behavior in VTx non root mode • 4KB structure – configured by KVM • Also -

MS-DOS System Programmer's Guide I I Document No.: 819-000104-3001 Rev
~~ Advanced Ar-a..Personal Computer TM MSTM_DOS System Programmer's Guide NEe NEe Information Systems, Inc. 819-000104-3001 REV 00 9-83 , Important Notice (1) All rights reserved, This manual is protected by copyright. No part of this manual may be reproduced in any form whatsoever without the written permission of the copyright owner. (2) The policy of NEC being that of continuous product improvement, the contents of this manual are subject to change, from time to time, without notice. (3) All efforts have been made to ensure that the contents of this manual are correct; however, should any errors be detected, NEC would greatly appreciate being informed. (4) NEC can assume no responsibility for errors in this manual or their consequences. ©Copyright 1983 by NEC Corporation. MSTM-DOS, MACRO-86 Macro Assembler™, MS-LINK Linker UtilityTM, MS-LIB Library Mana gerTM, MS-CREpTM Cross Reference Utility, EDLIN Line Editor™ are registered trademarks of the Microsoft Corporation. PLEASE READ THE FOLLOWING TEXT CAREFULLY. IT COPYRIGHT CONSTITUTES A CONTINUATION OF THE PROGRAM LICENSE AGREEMENT FOR THE SOFTWARE APPLICA The name of the copyright holder of this software must be recorded TION PROGRAM CONTAINED IN THIS PACKAGE. exactly as it appears on the label of the original diskette as supplied by NECIS on a label attached to each additional copy you make. If you agree to all the terms and conditions contained in both parts You must maintain a record of the number and location of each of the Program License Agreement. please fill out the detachable copy of this program. -

KVM Message Passing Performance
Message Passing Workloads in KVM David Matlack, [email protected] 1 Overview Message Passing Workloads Loopback TCP_RR IPI and HLT DISCLAIMER: x86 and Intel VT-x Halt Polling Interrupts and questions are welcome! 2 Message Passing Workloads ● Usually, anything that frequently switches between running and idle. ● Event-driven workloads ○ Memcache ○ LAMP servers ○ Redis ● Multithreaded workloads using low latency wait/signal primitives for coordination. ○ Windows Event Objects ○ pthread_cond_wait / pthread_cond_signal ● Inter-process communication ○ TCP_RR (benchmark) 3 Message Passing Workloads Intuition: Workloads which don't involve IO virtualization should run at near native performance. Reality: Message Passing Workloads may not involve any IO but will still perform nX worse than native. ● (loopback) Memcache: 2x higher latency. ● Windows Event Objects: 3-4x higher latency. 4 Message Passing Workloads ● Microbenchmark: Loopback TCP_RR ○ Client and Server ping-pong 1-byte of data over an established TCP connection. ○ Loopback: No networking devices (real or virtual) involved. ○ Performance: Latency of each transaction. ● One transaction: 1. Send 1 byte 3. Receive 1 byte to server. (idle) from server. Client Server (idle) 2. Receive 1 byte from (idle) client. Send 1 byte back. 5 Loopback TCP_RR Performance Host: IvyBridge 3.11 Kernel Guest: Debian Wheezy Backports (3.16 Kernel) 3x higher latency 25 us slower 6 Virtual Overheads of TCP_RR ● Message Passing on 1 CPU ○ Context Switch ● Message Passing on >1 CPU ○ Interprocessor-Interrupts