Stage-Aware Scheduling in a Library OS
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Towards Scalable Multiprocessor Virtual Machines
USENIX Association Proceedings of the Third Virtual Machine Research and Technology Symposium San Jose, CA, USA May 6–7, 2004 © 2004 by The USENIX Association All Rights Reserved For more information about the USENIX Association: Phone: 1 510 528 8649 FAX: 1 510 548 5738 Email: [email protected] WWW: http://www.usenix.org Rights to individual papers remain with the author or the author's employer. Permission is granted for noncommercial reproduction of the work for educational or research purposes. This copyright notice must be included in the reproduced paper. USENIX acknowledges all trademarks herein. Towards Scalable Multiprocessor Virtual Machines Volkmar Uhlig Joshua LeVasseur Espen Skoglund Uwe Dannowski System Architecture Group Universitat¨ Karlsruhe [email protected] Abstract of guests, such that they only ever access a fraction of the physical processors, or alternatively time-multiplex A multiprocessor virtual machine benefits its guest guests across a set of physical processors to, e.g., ac- operating system in supporting scalable job throughput commodate for spikes in guest OS workloads. It can and request latency—useful properties in server consol- also map guest operating systems to virtual processors idation where servers require several of the system pro- (which can exceed the number of physical processors), cessors for steady state or to handle load bursts. and migrate between physical processors without no- Typical operating systems, optimized for multipro- tifying the guest operating systems. This allows for, cessor systems in their use of spin-locks for critical sec- e.g., migration to other machine configurations or hot- tions, can defeat flexible virtual machine scheduling due swapping of CPUs without adequate support from the to lock-holder preemption and misbalanced load. -

Thread Management for High Performance Database Systems - Design and Implementation
Nr.: FIN-003-2018 Thread Management for High Performance Database Systems - Design and Implementation Robert Jendersie, Johannes Wuensche, Johann Wagner, Marten Wallewein-Eising, Marcus Pinnecke, Gunter Saake Arbeitsgruppe Database and Software Engineering Fakultät für Informatik Otto-von-Guericke-Universität Magdeburg Nr.: FIN-003-2018 Thread Management for High Performance Database Systems - Design and Implementation Robert Jendersie, Johannes Wuensche, Johann Wagner, Marten Wallewein-Eising, Marcus Pinnecke, Gunter Saake Arbeitsgruppe Database and Software Engineering Technical report (Internet) Elektronische Zeitschriftenreihe der Fakultät für Informatik der Otto-von-Guericke-Universität Magdeburg ISSN 1869-5078 Fakultät für Informatik Otto-von-Guericke-Universität Magdeburg Impressum (§ 5 TMG) Herausgeber: Otto-von-Guericke-Universität Magdeburg Fakultät für Informatik Der Dekan Verantwortlich für diese Ausgabe: Otto-von-Guericke-Universität Magdeburg Fakultät für Informatik Marcus Pinnecke Postfach 4120 39016 Magdeburg E-Mail: [email protected] http://www.cs.uni-magdeburg.de/Technical_reports.html Technical report (Internet) ISSN 1869-5078 Redaktionsschluss: 21.08.2018 Bezug: Otto-von-Guericke-Universität Magdeburg Fakultät für Informatik Dekanat Thread Management for High Performance Database Systems - Design and Implementation Technical Report Robert Jendersie1, Johannes Wuensche2, Johann Wagner1, Marten Wallewein-Eising2, Marcus Pinnecke1, and Gunter Saake1 Database and Software Engineering Group, Otto-von-Guericke University -

Concurrency & Parallel Programming Patterns
Concurrency & Parallel programming patterns Evgeny Gavrin Outline 1. Concurrency vs Parallelism 2. Patterns by groups 3. Detailed overview of parallel patterns 4. Summary 5. Proposal for language Concurrency vs Parallelism ● Parallelism is the simultaneous execution of computations “doing lots of things at once” ● Concurrency is the composition of independently execution processes “dealing with lots of thing at once” Patterns by groups Architectural Patterns These patterns define the overall architecture for a program: ● Pipe-and-filter: view the program as filters (pipeline stages) connected by pipes (channels). Data flows through the filters to take input and transform into output. ● Agent and Repository: a collection of autonomous agents update state managed on their behalf in a central repository. ● Process control: the program is structured analogously to a process control pipeline with monitors and actuators moderating feedback loops and a pipeline of processing stages. ● Event based implicit invocation: The program is a collection of agents that post events they watch for and issue events for other agents. The architecture enforces a high level abstraction so invocation of an agent is implicit; i.e. not hardwired to a specific controlling agent. ● Model-view-controller: An architecture with a central model for the state of the program, a controller that manages the state and one or more agents that export views of the model appropriate to different uses of the model. ● Bulk Iterative (AKA bulk synchronous): A program that proceeds iteratively … update state, check against a termination condition, complete coordination, and proceed to the next iteration. ● Map reduce: the program is represented in terms of two classes of functions. -
NASM Intel X86 Assembly Language Cheat Sheet
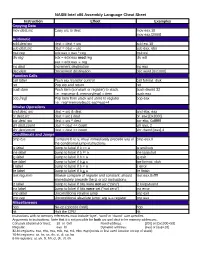
NASM Intel x86 Assembly Language Cheat Sheet Instruction Effect Examples Copying Data mov dest,src Copy src to dest mov eax,10 mov eax,[2000] Arithmetic add dest,src dest = dest + src add esi,10 sub dest,src dest = dest – src sub eax, ebx mul reg edx:eax = eax * reg mul esi div reg edx = edx:eax mod reg div edi eax = edx:eax reg inc dest Increment destination inc eax dec dest Decrement destination dec word [0x1000] Function Calls call label Push eip, transfer control call format_disk ret Pop eip and return ret push item Push item (constant or register) to stack. push dword 32 I.e.: esp=esp-4; memory[esp] = item push eax pop [reg] Pop item from stack and store to register pop eax I.e.: reg=memory[esp]; esp=esp+4 Bitwise Operations and dest, src dest = src & dest and ebx, eax or dest,src dest = src | dest or eax,[0x2000] xor dest, src dest = src ^ dest xor ebx, 0xfffffff shl dest,count dest = dest << count shl eax, 2 shr dest,count dest = dest >> count shr dword [eax],4 Conditionals and Jumps cmp b,a Compare b to a; must immediately precede any of cmp eax,0 the conditional jump instructions je label Jump to label if b == a je endloop jne label Jump to label if b != a jne loopstart jg label Jump to label if b > a jg exit jge label Jump to label if b > a jge format_disk jl label Jump to label if b < a jl error jle label Jump to label if b < a jle finish test reg,imm Bitwise compare of register and constant; should test eax,0xffff immediately precede the jz or jnz instructions jz label Jump to label if bits were not set (“zero”) jz looparound jnz label Jump to label if bits were set (“not zero”) jnz error jmp label Unconditional relative jump jmp exit jmp reg Unconditional absolute jump; arg is a register jmp eax Miscellaneous nop No-op (opcode 0x90) nop hlt Halt the CPU hlt Instructions with no memory references must include ‘byte’, ‘word’ or ‘dword’ size specifier. -

Model Checking Multithreaded Programs With
View metadata, citation and similar papers at core.ac.uk brought to you by CORE provided by Illinois Digital Environment for Access to Learning and Scholarship Repository Model Checking Multithreaded Programs with Asynchronous Atomic Methods Koushik Sen and Mahesh Viswanathan Department of Computer Science, University of Illinois at Urbana-Champaign. {ksen,vmahesh}@uiuc.edu Abstract. In order to make multithreaded programming manageable, program- mers often follow a design principle where they break the problem into tasks which are then solved asynchronously and concurrently on different threads. This paper investigates the problem of model checking programs that follow this id- iom. We present a programming language SPL that encapsulates this design pat- tern. SPL extends simplified form of sequential Java to which we add the ca- pability of making asynchronous method invocations in addition to the standard synchronous method calls and the ability to execute asynchronous methods in threads atomically and concurrently. Our main result shows that the control state reachability problem for finite SPL programs is decidable. Therefore, such mul- tithreaded programs can be model checked using the counter-example guided abstraction-refinement framework. 1 Introduction Multithreaded programming is often used in software as it leads to reduced latency, improved response times of interactive applications, and more optimal use of process- ing power. Multithreaded programming also allows an application to progress even if one thread is blocked for an I/O operation. However, writing correct programs that use multiple threads is notoriously difficult, especially in the presence of a shared muta- ble memory. Since threads can interleave, there can be unintended interference through concurrent access of shared data and result in software errors due to data race and atom- icity violations. -

Lecture 26: Creational Patterns
Creational Patterns CSCI 4448/5448: Object-Oriented Analysis & Design Lecture 26 — 11/29/2012 © Kenneth M. Anderson, 2012 1 Goals of the Lecture • Cover material from Chapters 20-22 of the Textbook • Lessons from Design Patterns: Factories • Singleton Pattern • Object Pool Pattern • Also discuss • Builder Pattern • Lazy Instantiation © Kenneth M. Anderson, 2012 2 Pattern Classification • The Gang of Four classified patterns in three ways • The behavioral patterns are used to manage variation in behaviors (think Strategy pattern) • The structural patterns are useful to integrate existing code into new object-oriented designs (think Bridge) • The creational patterns are used to create objects • Abstract Factory, Builder, Factory Method, Prototype & Singleton © Kenneth M. Anderson, 2012 3 Factories & Their Role in OO Design • It is important to manage the creation of objects • Code that mixes object creation with the use of objects can become quickly non-cohesive • A system may have to deal with a variety of different contexts • with each context requiring a different set of objects • In design patterns, the context determines which concrete implementations need to be present © Kenneth M. Anderson, 2012 4 Factories & Their Role in OO Design • The code to determine the current context, and thus which objects to instantiate, can become complex • with many different conditional statements • If you mix this type of code with the use of the instantiated objects, your code becomes cluttered • often the use scenarios can happen in a few lines of code • if combined with creational code, the operational code gets buried behind the creational code © Kenneth M. Anderson, 2012 5 Factories provide Cohesion • The use of factories can address these issues • The conditional code can be hidden within them • pass in the parameters associated with the current context • and get back the objects you need for the situation • Then use those objects to get your work done • Factories concern themselves just with creation, letting your code focus on other things © Kenneth M. -

Optimizing HLT Code for Run-Time Efficiency
Optimizing HLT code for run-time efficiency Public Note Issue: 1 Revision: 0 Reference: LHCb-PUB-2010-017 Created: September 6, 2010 Last modified: November 4, 2010 LHCb-PUB-2010-017 04/11/2010 Prepared by: Axel Thuressona, Niko Neufeldb aLund,Sweden bCERN, PH Optimizing HLT code for run-time efficiency Ref: LHCb-PUB-2010-017 Public Note Issue: 1 Date: November 4, 2010 Abstract An upgrade of the High level trigger (HLT) farm at LHCb will be inevitable due to the increase in luminosity at the LHC. The upgrade will be done in two main ways. The first way is to make the software more efficient and faster. The second way is to increase the number of servers in the farm. This paper will concern both of these two ways divided into three parts. The first part is about NUMA, modern servers are all built with NUMA so an upgrade of the HLT farm will consist of this new architecture. The present HLT farm servers consists of the architecture UMA. After several tests it turned out that the Intel-servers that was used for testing (having 2 nodes) had very little penalty when comparing the worst-case the optimal-case. The conclusions for Intel-servers are that the NUMA architecture doesn’t affect the existing software negative. Several tests was done on an AMD-server having 8 nodes, and hence a more complicated structure. Non-optimal effects could be observed for this server and when comparing the worst-case with the optimal-case a big difference was found. So for the AMD-server the NUMA architecture can affect the existing software negative under certain circumstances. -

An Enhanced Thread Synchronization Mechanism for Java
SOFTWARE—PRACTICE AND EXPERIENCE Softw. Pract. Exper. 2001; 31:667–695 (DOI: 10.1002/spe.383) An enhanced thread synchronization mechanism for Java Hsin-Ta Chiao and Shyan-Ming Yuan∗,† Department of Computer and Information Science, National Chiao Tung University, 1001 Ta Hsueh Road, Hsinchu 300, Taiwan SUMMARY The thread synchronization mechanism of Java is derived from Hoare’s monitor concept. In the authors’ view, however, it is over simplified and suffers the following four drawbacks. First, it belongs to a category of no-priority monitor, the design of which, as reported in the literature on concurrent programming, is not well rated. Second, it offers only one condition queue. Where more than one long-term synchronization event is required, this restriction both degrades performance and further complicates the ordering problems that a no-priority monitor presents. Third, it lacks the support for building more elaborate scheduling programs. Fourth, during nested monitor invocations, deadlock may occur. In this paper, we first analyze these drawbacks in depth before proceeding to present our own proposal, which is a new monitor-based thread synchronization mechanism that we term EMonitor. This mechanism is implemented solely by Java, thus avoiding the need for any modification to the underlying Java Virtual Machine. A preprocessor is employed to translate the EMonitor syntax into the pure Java codes that invoke the EMonitor class libraries. We conclude with a comparison of the performance of the two monitors and allow the experimental results to demonstrate that, in most cases, replacing the Java version with the EMonitor version for developing concurrent Java objects is perfectly feasible. -

Designing for Performance: Concurrency and Parallelism COS 518: Computer Systems Fall 2015
Designing for Performance: Concurrency and Parallelism COS 518: Computer Systems Fall 2015 Logan Stafman Adapted from slides by Mike Freedman 2 Definitions • Concurrency: – Execution of two or more tasks overlap in time. • Parallelism: – Execution of two or more tasks occurs simultaneous. Concurrency without 3 parallelism? • Parts of tasks interact with other subsystem – Network I/O, Disk I/O, GPU, ... • Other task can be scheduled while first waits on subsystem’s response Concurrency without parrallelism? Source: bjoor.me 5 Scheduling for fairness • On time-sharing system also want to schedule between tasks, even if one not blocking – Otherwise, certain tasks can keep processing – Leads to starvation of other tasks • Preemptive scheduling – Interrupt processing of tasks to process another task (why with tasks and not network packets?) • Many scheduling disciplines – FIFO, Shortest Remaining Time, Strict Priority, Round-Robin Preemptive Scheduling Source: embeddedlinux.org.cn Concurrency with 7 parallelism • Execute code concurrently across CPUs – Clusters – Cores • CPU parallelism different from distributed systems as ready availability to shared memory – Yet to avoid difference between parallelism b/w local and remote cores, many apps just use message passing between both (like HPC’s use of MPI) Symmetric Multiprocessors 8 (SMPs) Non-Uniform Memory Architectures 9 (NUMA) 10 Pros/Cons of NUMA • Pros Applications split between different processors can share memory close to hardware Reduced bus bandwidth usage • Cons Must ensure applications sharing memory are run on processors sharing memory 11 Forms of task parallelism • Processes – Isolated process address space – Higher overhead between switching processes • Threads – Concurrency within process – Shared address space – Three forms • Kernel threads (1:1) : Kernel support, can leverage hardware parallelism • User threads (N:1): Thread library in system runtime, fastest context switching, but cannot benefit from multi- threaded/proc hardware • Hybrid (M:N): Schedule M user threads on N kernel threads. -

Assessment of Barrier Implementations for Fine-Grain Parallel Regions on Current Multi-Core Architectures
Assessment of Barrier Implementations for Fine-Grain Parallel Regions on Current Multi-core Architectures Simon A. Berger and Alexandros Stamatakis The Exelixis Lab Department of Computer Science Technische Universitat¨ Munchen¨ Boltzmannstr. 3, D-85748 Garching b. Munchen,¨ Germany Email: [email protected], [email protected] WWW: http://wwwkramer.in.tum.de/exelixis/ time Abstract—Barrier performance for synchronizing threads master thread on current multi-core systems can be critical for scientific applications that traverse a large number of relatively small parallel regions, that is, that exhibit an unfavorable com- fork putation to synchronization ratio. By means of a synthetic and a real-world benchmark we assess 4 alternative barrier worker threads parallel region implementations on 7 current multi-core systems with 2 up to join 32 cores. We find that, barrier performance is application- and data-specific with respect to cache utilization, but that a rather fork na¨ıve lock-free barrier implementation yields good results across all applications and multi-core systems tested. We also worker threads parallel region assess distinct implementations of reduction operations that join are computed in conjunction with the barriers. The synthetic and real-world benchmarks are made available as open-source code for further testing. Keywords-barriers; multi-cores; threads; RAxML Figure 1. Classic fork-join paradigm. I. INTRODUCTION The performance of barriers for synchronizing threads on modern general-purpose multi-core systems is of vital In addition, we analyze the efficient implementation of importance for the efficiency of scientific codes. Barrier reduction operations (sums over the double values produced performance can become critical, if a scientific code exhibits by each for-loop iteration), that are frequently required a high number of relatively small (with respect to the in conjunction with barriers. -

Understanding the Linux Kernel, 3Rd Edition by Daniel P
1 Understanding the Linux Kernel, 3rd Edition By Daniel P. Bovet, Marco Cesati ............................................... Publisher: O'Reilly Pub Date: November 2005 ISBN: 0-596-00565-2 Pages: 942 Table of Contents | Index In order to thoroughly understand what makes Linux tick and why it works so well on a wide variety of systems, you need to delve deep into the heart of the kernel. The kernel handles all interactions between the CPU and the external world, and determines which programs will share processor time, in what order. It manages limited memory so well that hundreds of processes can share the system efficiently, and expertly organizes data transfers so that the CPU isn't kept waiting any longer than necessary for the relatively slow disks. The third edition of Understanding the Linux Kernel takes you on a guided tour of the most significant data structures, algorithms, and programming tricks used in the kernel. Probing beyond superficial features, the authors offer valuable insights to people who want to know how things really work inside their machine. Important Intel-specific features are discussed. Relevant segments of code are dissected line by line. But the book covers more than just the functioning of the code; it explains the theoretical underpinnings of why Linux does things the way it does. This edition of the book covers Version 2.6, which has seen significant changes to nearly every kernel subsystem, particularly in the areas of memory management and block devices. The book focuses on the following topics: • Memory management, including file buffering, process swapping, and Direct memory Access (DMA) • The Virtual Filesystem layer and the Second and Third Extended Filesystems • Process creation and scheduling • Signals, interrupts, and the essential interfaces to device drivers • Timing • Synchronization within the kernel • Interprocess Communication (IPC) • Program execution Understanding the Linux Kernel will acquaint you with all the inner workings of Linux, but it's more than just an academic exercise. -

Virtualization in Linux KVM + QEMU
CS695 Topics in Virtualization and Cloud Computing Virtualization in Linux KVM + QEMU Senthil, Puru, Prateek and Shashank Virtualization in Linux 1 Topics covered • KVM and QEMU Architecture • VTx support • CPU virtualization in KMV • Memory virtualization techniques • shadow page table • EPT/NPT page table • IO virtualization in QEMU • KVM and QEMU usage • Virtual disk creation • Creating virtual machines • Copy-on-write disks Virtualization in Linux 2 KVM + QEMU - Architecture Virtualization in Linux 3 KVM + QEMU – Architecture • Need for hardware support • less privileged rings ( rings > 0) are not sufficient to run guest – sensitive unprivileged instructions • Should go for • Binary instrumentation/ patching • paravirtualization • VTx and AMD-V • 4 different address spaces - host physical, host virtual, guest physical and guest virtual Virtualization in Linux 4 X86 VTx support Guest 3 Guest User Guest 2 Guest 1 Guest 0 Guest Kernel Host 3 QEMU Host 2 Host 1 Host 0 KVM Communication Channels VMCS + vmx KVM /dev/kvm QEMU KVM Guest 0-3 instructions Virtualization in Linux 5 X86 VMX Instructions • Controls transition between VMX root and VMX non- root • VMX root -> VMX non-root - VM Entry • VMX non-root -> VMX root – VM Exit • Example instructions • VMXON – enables VMX Operation • VMXOFF – disable VMX Operation • VMLAUNCH – VM Entry • VMRESUME – VM Entry • VMREAD – read from VMCS • VMWRITE – write to VMCS Virtualization in Linux 6 X86 VMCS Structure • Controls CPU behavior in VTx non root mode • 4KB structure – configured by KVM • Also