Classical Sanskrit Preverb Ordering: a Diachronic Study
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Studies on Language Change. Working Papers in Linguistics No. 34
DOCUMENT RESUME ED 286 382 FL 016 932 AUTHOR Joseph, Brian D., Ed. TITLE Studies on Language Change. Working Papers in Linguistics No. 34. INSTITUTION Ohio State Univ., Columbus. Dept. of Linguistics. PUB DATE Dec 86 NOTE 171p. PUB TYPE Reports - Evaluative/Feasibility (142) -- Collected Works - General (020) EDRS PRICE MF01/PC07 Plus Postage. DESCRIPTORS Arabic; Diachronic Linguistics; Dialects; *Diglossia; English; Estonian; *Etymology; Finnish; Foreign Countries; Language Variation; Linguistic Borrowing; *Linguistic Theory; *Morphemes; *Morphology (Languages); Old English; Sanskrit; Sociolinguistics; Syntax; *Uncommonly Taught Languages; Word Frequency IDENTIFIERS Saame ABSTRACT A collection of papers relevant to historical linguistics and description and explanation of language change includes: "Decliticization and Deaffixation in Saame: Abessive 'taga'" (Joel A. Nevis); "Decliticization in Old Estonian" (Joel A. Nevis); "On Automatic and Simultaneous Syntactic Changes" (Brian D. Joseph); "Loss of Nominal Case Endings in the Modern Arabic Sedentary Dialects" (Ann M. Miller); "One Rule or Many? Sanskrit Reduplication as Fragmented Affixation" (Richard D. Janda, Brian D. Joseph); "Fragmentation of Strong Verb Ablaut in Old English" (Keith Johnson); "The Etymology of 'bum': Mere Child's Play" (Mary E. Clark, Brian D. Joseph); "Small Group Lexical Innovation: Some Examples" (Christopher Kupec); "Word Frequency and Dialect Borrowing" (Debra A. Stollenwerk); "Introspection into a Stable Case of Variation in Finnish" (Riitta Valimaa-Blum); -

A Study of the Early Vedic Age in Ancient India
Journal of Arts and Culture ISSN: 0976-9862 & E-ISSN: 0976-9870, Volume 3, Issue 3, 2012, pp.-129-132. Available online at http://www.bioinfo.in/contents.php?id=53. A STUDY OF THE EARLY VEDIC AGE IN ANCIENT INDIA FASALE M.K.* Department of Histroy, Abasaheb Kakade Arts College, Bodhegaon, Shevgaon- 414 502, MS, India *Corresponding Author: Email- [email protected] Received: December 04, 2012; Accepted: December 20, 2012 Abstract- The Vedic period (or Vedic age) was a period in history during which the Vedas, the oldest scriptures of Hinduism, were composed. The time span of the period is uncertain. Philological and linguistic evidence indicates that the Rigveda, the oldest of the Vedas, was com- posed roughly between 1700 and 1100 BCE, also referred to as the early Vedic period. The end of the period is commonly estimated to have occurred about 500 BCE, and 150 BCE has been suggested as a terminus ante quem for all Vedic Sanskrit literature. Transmission of texts in the Vedic period was by oral tradition alone, and a literary tradition set in only in post-Vedic times. Despite the difficulties in dating the period, the Vedas can safely be assumed to be several thousands of years old. The associated culture, sometimes referred to as Vedic civilization, was probably centred early on in the northern and northwestern parts of the Indian subcontinent, but has now spread and constitutes the basis of contemporary Indian culture. After the end of the Vedic period, the Mahajanapadas period in turn gave way to the Maurya Empire (from ca. -

Linguistics Development Team
Development Team Principal Investigator: Prof. Pramod Pandey Centre for Linguistics / SLL&CS Jawaharlal Nehru University, New Delhi Email: [email protected] Paper Coordinator: Prof. K. S. Nagaraja Department of Linguistics, Deccan College Post-Graduate Research Institute, Pune- 411006, [email protected] Content Writer: Prof. K. S. Nagaraja Prof H. S. Ananthanarayana Content Reviewer: Retd Prof, Department of Linguistics Osmania University, Hyderabad 500007 Paper : Historical and Comparative Linguistics Linguistics Module : Indo-Aryan Language Family Description of Module Subject Name Linguistics Paper Name Historical and Comparative Linguistics Module Title Indo-Aryan Language Family Module ID Lings_P7_M1 Quadrant 1 E-Text Paper : Historical and Comparative Linguistics Linguistics Module : Indo-Aryan Language Family INDO-ARYAN LANGUAGE FAMILY The Indo-Aryan migration theory proposes that the Indo-Aryans migrated from the Central Asian steppes into South Asia during the early part of the 2nd millennium BCE, bringing with them the Indo-Aryan languages. Migration by an Indo-European people was first hypothesized in the late 18th century, following the discovery of the Indo-European language family, when similarities between Western and Indian languages had been noted. Given these similarities, a single source or origin was proposed, which was diffused by migrations from some original homeland. This linguistic argument is supported by archaeological and anthropological research. Genetic research reveals that those migrations form part of a complex genetical puzzle on the origin and spread of the various components of the Indian population. Literary research reveals similarities between various, geographically distinct, Indo-Aryan historical cultures. The Indo-Aryan migrations started in approximately 1800 BCE, after the invention of the war chariot, and also brought Indo-Aryan languages into the Levant and possibly Inner Asia. -

Deixis and Reference Tracing in Tsova-Tush (PDF)
DEIXIS AND REFERENCE TRACKING IN TSOVA-TUSH A DISSERTATION SUBMITTED TO THE GRADUATE DIVISION OF THE UNIVERSITY OF HAWAIʻI AT MĀNOA IN PARTIAL FULFILLMENT OF THE REQUIREMENTS FOR THE DEGREE OF DOCTOR OF PHILOSOPHY IN LINGUISTICS MAY 2020 by Bryn Hauk Dissertation committee: Andrea Berez-Kroeker, Chairperson Alice C. Harris Bradley McDonnell James N. Collins Ashley Maynard Acknowledgments I should not have been able to finish this dissertation. In the course of my graduate studies, enough obstacles have sprung up in my path that the odds would have predicted something other than a successful completion of my degree. The fact that I made it to this point is a testament to thekind, supportive, wise, and generous people who have picked me up and dusted me off after every pothole. Forgive me: these thank-yous are going to get very sappy. First and foremost, I would like to thank my Tsova-Tush host family—Rezo Orbetishvili, Nisa Baxtarishvili, and of course Tamar and Lasha—for letting me join your family every summer forthe past four years. Your time, your patience, your expertise, your hospitality, your sense of humor, your lovingly prepared meals and generously poured wine—these were the building blocks that supported all of my research whims. My sincerest gratitude also goes to Dantes Echishvili, Revaz Shankishvili, and to all my hosts and friends in Zemo Alvani. It is possible to translate ‘thank you’ as მადელ შუნ, but you have taught me that gratitude is better expressed with actions than with set phrases, sofor now I will just say, ღაზიშ ხილჰათ, ბედნიერ ხილჰათ, მარშმაკიშ ხილჰათ.. -

Headmost Accent Wins Headmost Accent Wins
Headmost Accent Wins Headmost Accent Wins Head Dominance and Ideal Prosodic Form in Lexical Accent Systems Proefschrift ter verkrijging van de graad van Doctor aan de Universiteit Leiden, op gezag van de Rector Magnificus Dr. W. A. Wagenaar, hoogleraar in de faculteit der Sociale Wetenschappen, volgens besluit van het College voor Promoties te verdedigen op woensdag 13 januari 1999 te klokke 16.15 uur door ANTHOULA REVITHIADOU geboren te Katerini (Griekenland) in 1971 Promotiecommissie promotor: Prof. dr. J. G. Kooij co-promotor: Dr. H. G. van der Hulst referent: Prof. dr. J. ItA, University of California, Santa Cruz overige leden: Prof. dr. G. E. Booij, Vrije Universiteit Amsterdam Prof. G. Drachman, Universit#t Salzburg Prof. dr. M. van Oostendorp, Universiteit van Amsterdam Dr. R. W. J. Kager, Rijksuniversiteit Utrecht ISBN 90-5569-059-7 © 1999 by Anthi Revithiadou. All rights reserved. Printed in The Netherlands *- ## ;J9 #/ )-# Martin Acknowledgments I am afraid that it is impossible to include in a few lines the names of all of those who have contributed in some way or other to the production of this thesis. Ironically, the rules concerning the public defense at Leiden University prevent me from mentioning the names of those who helped me most. Therefore I want to thank collectively all members at HIL for creating a friendly and stimulating environment. I would like, however, to mention a few who contributed to my development as a linguist and as a person during the last four years. I consider myself extremely fortunate for being surrounded by a great group of people in Leiden. -

AN EXPERIENCE of TRANSLATING NEPALI GRAMMAR INTO ENGLISH Govinda Raj Bhattarai and Bal Ram Adhikari [email protected]; [email protected]
AN EXPERIENCE OF TRANSLATING NEPALI GRAMMAR INTO ENGLISH Govinda Raj Bhattarai and Bal Ram Adhikari [email protected]; [email protected] 1. Introduction Translating a grammar from one language to another sounds impossible because two languages differ basically in terms of grammar which stands for different components from sound to discourse units. Despite this fact, the world has translated grammar between languages, as it is the most authentic door to enter into another language, its structure, form and function. Greek grammars were translated into Latin and it is from Latin that many western grammars have been reshaped, some in translation, some in adaptation and others in considerable degree of borrowing as well. The grammars of all young languages undergo such a process in course of evolution. This applies to Nepali as well. Pande's Chandrika Gorkha Bhasa Vyakaran (1912) and Sharma's Madhya Chandrika (1919) (quoted in Schmidt and Dahal 1993: x) are some seminal works in Nepali grammar. These works in their attempt to codify and describe the Nepali language adopted the model of Sanskrit grammar. The modern Nepali grammar has evolved through a long and exacting process. Whitney's Sanskrit Grammar (1879) is a best example of translation of classical grammar into contemporary languages. There have been some efforts made in Nepali too. Some works like Ayton (1820), Turnbull (1888) Kilgour and Duncan (1922), Turner (1931), Clark (1963) and Matthews (1984) border between translation and restructuring. Many other foreign scholars have contributed towards writing Nepali grammar till date. They have laid the foundation stone of Nepali grammar in English. -

2 the Theory of Lexical Accents
2 The Theory of Lexical Accents 2.1. Introduction This chapter develops a theory for the lexical specification of morphemes. Underlying metrical information is given the name ‘lexical accent’ or just ‘mark’.1 In this thesis I argue that a lexical accent is an autosegmental feature that does not provide any clues about its phonetic manifestation. A lexical accent is liable to the demands of the phonological constraints of the grammar and, if qualified, it will be phonetically assigned duration, pitch and intensity. This chapter starts with an outline of the theory of marking. Based on empirical evidence, I establish that it is better to view lexical accents as autosegmental features and not as prosodic roles (McCarthy and Prince 1995, McCarthy 1995, 1997). I further propose that the mapping between lexical accents and the vocalic peaks that sponsor them is established in terms of universal constraints and, more specifically, in terms of faithfulness constraints. The chapter continues with a brief review of other approaches on marking. There is little consensus in the literature on the nature of lexical stress. Three mainstream theories of lexical specification are examined. First, there are theories that argue that the mark is a prosodic constituent that is assigned to a morpheme in the lexicon. Two approaches are examined, Inkelas’s (1994) theory of exceptional stress in Turkish and Alderete’s (1997) theory of lexical 1 The terms ‘mark’, ‘marking’ and ‘markedness’ in this thesis refer to the lexical accent and the property of some morphemes to have accents in their lexical representation. This use of the terminology should not be confused with the role that markedness theory plays in OT. -

Journal of Irish and Scottish Studies Cultural Exchange: from Medieval
Journal of Irish and Scottish Studies Volume 1: Issue 1 Cultural Exchange: from Medieval to Modernity AHRC Centre for Irish and Scottish Studies JOURNAL OF IRISH AND SCOTTISH STUDIES Volume 1, Issue 1 Cultural Exchange: Medieval to Modern Published by the AHRC Centre for Irish and Scottish Studies at the University of Aberdeen in association with The universities of the The Irish-Scottish Academic Initiative and The Stout Research Centre Irish-Scottish Studies Programme Victoria University of Wellington ISSN 1753-2396 Journal of Irish and Scottish Studies Issue Editor: Cairns Craig Associate Editors: Stephen Dornan, Michael Gardiner, Rosalyn Trigger Editorial Advisory Board: Fran Brearton, Queen’s University, Belfast Eleanor Bell, University of Strathclyde Michael Brown, University of Aberdeen Ewen Cameron, University of Edinburgh Sean Connolly, Queen’s University, Belfast Patrick Crotty, University of Aberdeen David Dickson, Trinity College, Dublin T. M. Devine, University of Edinburgh David Dumville, University of Aberdeen Aaron Kelly, University of Edinburgh Edna Longley, Queen’s University, Belfast Peter Mackay, Queen’s University, Belfast Shane Alcobia-Murphy, University of Aberdeen Brad Patterson, Victoria University of Wellington Ian Campbell Ross, Trinity College, Dublin The Journal of Irish and Scottish Studies is a peer reviewed journal, published twice yearly in September and March, by the AHRC Centre for Irish and Scottish Studies at the University of Aberdeen. An electronic reviews section is available on the AHRC Centre’s website: http://www.abdn.ac.uk/riiss/ahrc- centre.shtml Editorial correspondence, including manuscripts for submission, should be addressed to The Editors,Journal of Irish and Scottish Studies, AHRC Centre for Irish and Scottish Studies, Humanity Manse, 19 College Bounds, University of Aberdeen, AB24 3UG or emailed to [email protected] Subscriptions and business correspondence should be address to The Administrator. -
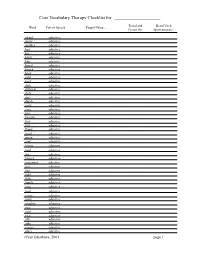
250 Word List
Core Vocabulary Therapy Checklist for ____________________ Tested and Heard Used Word Part of Speech Taught Using ... Passed On: Spontaneously: afraid adjective angry adjective another adjective bad adjective big adjective black adjective blue adjective bored adjective brown adjective busy adjective cold adjective cool adjective dark adjective different adjective dirty adjective dry adjective dumb adjective early adjective easy adjective fast adjective favorite adjective first adjective full adjective funny adjective good adjective green adjective grey adjective happy adjective hard adjective hot adjective hungry adjective important adjective last adjective late adjective light adjective little adjective lonely adjective long adjective mad adjective many adjective more adjective naughty adjective new adjective next adjective nice adjective old adjective only adjective orange adjective other adjective ©VanTatenhove, 2001 page 1 Core Vocabulary Therapy Checklist for ____________________ Word Part of Speech Taught Using ... Tested and Heard Used Passed On: Spontaneously: pink adjective purple adjective real adjective red adjective right adjective sad adjective same adjective sick adjective silly adjective sure adjective thirsty adjective tired adjective wet adjective white adjective wrong adjective yellow adjective adjective adjective adjective again adverb all right adverb almost adverb already adverb always adverb away adverb backwards adverb forward adverb here adverb indoors adverb just adverb maybe adverb much adverb never adverb not -

Indo-European Linguistics: an Introduction Indo-European Linguistics an Introduction
This page intentionally left blank Indo-European Linguistics The Indo-European language family comprises several hun- dred languages and dialects, including most of those spoken in Europe, and south, south-west and central Asia. Spoken by an estimated 3 billion people, it has the largest number of native speakers in the world today. This textbook provides an accessible introduction to the study of the Indo-European proto-language. It clearly sets out the methods for relating the languages to one another, presents an engaging discussion of the current debates and controversies concerning their clas- sification, and offers sample problems and suggestions for how to solve them. Complete with a comprehensive glossary, almost 100 tables in which language data and examples are clearly laid out, suggestions for further reading, discussion points and a range of exercises, this text will be an essential toolkit for all those studying historical linguistics, language typology and the Indo-European proto-language for the first time. james clackson is Senior Lecturer in the Faculty of Classics, University of Cambridge, and is Fellow and Direc- tor of Studies, Jesus College, University of Cambridge. His previous books include The Linguistic Relationship between Armenian and Greek (1994) and Indo-European Word For- mation (co-edited with Birgit Anette Olson, 2004). CAMBRIDGE TEXTBOOKS IN LINGUISTICS General editors: p. austin, j. bresnan, b. comrie, s. crain, w. dressler, c. ewen, r. lass, d. lightfoot, k. rice, i. roberts, s. romaine, n. v. smith Indo-European Linguistics An Introduction In this series: j. allwood, l.-g. anderson and o.¨ dahl Logic in Linguistics d. -

Proto-Indo-European Roots of the Vedic Aryans
3 (2016) Miscellaneous 1: A-V Proto-Indo-European Roots of the Vedic Aryans TRAVIS D. WEBSTER Center for Traditional Vedanta, USA © 2016 Ruhr-Universität Bochum Entangled Religions 3 (2016) ISSN 2363-6696 http://dx.doi.org/10.13154/er.v3.2016.A–V Proto-Indo-European Roots of the Vedic Aryans Proto-Indo-European Roots of the Vedic Aryans TRAVIS D. WEBSTER Center for Traditional Vedanta ABSTRACT Recent archaeological evidence and the comparative method of Indo-European historical linguistics now make it possible to reconstruct the Aryan migrations into India, two separate diffusions of which merge with elements of Harappan religion in Asko Parpola’s The Roots of Hinduism: The Early Aryans and the Indus Civilization (NY: Oxford University Press, 2015). This review of Parpola’s work emphasizes the acculturation of Rigvedic and Atharvavedic traditions as represented in the depiction of Vedic rites and worship of Indra and the Aśvins (Nāsatya). After identifying archaeological cultures prior to the breakup of Proto-Indo-European linguistic unity and demarcating the two branches of the Proto-Aryan community, the role of the Vrātyas leads back to mutual encounters with the Iranian Dāsas. KEY WORDS Asko Parpola; Aryan migrations; Vedic religion; Hinduism Introduction Despite the triumph of the world-religions paradigm from the late nineteenth century onwards, the fact remains that Indologists require more precise taxonomic nomenclature to make sense of their data. Although the Vedas are widely portrayed as the ‘Hindu scriptures’ and are indeed upheld as the sole arbiter of scriptural authority among Brahmins, for instance, the Vedic hymns actually play a very minor role in contemporary Indian religion. -

Outer and Inner Indo-Aryan, and Northern India As an Ancient Linguistic Area
Acta Orientalia 2016: 77, 71–132. Copyright © 2016 Printed in India – all rights reserved ACTA ORIENTALIA ISSN 0001-6483 Outer and Inner Indo-Aryan, and northern India as an ancient linguistic area Claus Peter Zoller University of Oslo Abstract The article presents a new approach to the old controversy concerning the veracity of a distinction between Outer and Inner Languages in Indo-Aryan. A number of arguments and data are presented which substantiate the reality of this distinction. This new approach combines this issue with a new interpretation of the history of Indo- Iranian and with the linguistic prehistory of northern India. Data are presented to show that prehistorical northern India was dominated by Munda/Austro-Asiatic languages. Keywords: Indo-Aryan, Indo-Iranian, Nuristani, Munda/Austro- Asiatic history and prehistory. Introduction This article gives a summary of the most important arguments contained in my forthcoming book on Outer and Inner languages before and after the arrival of Indo-Aryan in South Asia. The 72 Claus Peter Zoller traditional version of the hypothesis of Outer and Inner Indo-Aryan purports the idea that the Indo-Aryan Language immigration1 was not a singular event. Yet, even though it is known that the actual historical movements and processes in connection with this immigration were remarkably complex, the concerns of the hypothesis are not to reconstruct the details of these events but merely to show that the original non-singular immigrations have left revealing linguistic traces in the modern Indo-Aryan languages. Actually, this task is challenging enough, as the long-lasting controversy shows.2 Previous and present proponents of the hypothesis have tried to fix the difference between Outer and Inner Languages in terms of language geography (one graphical attempt as an example is shown below p.