C/C++ Compiler Manual for SHARC® Processors
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Language Subsetting in an Industrial Context: a Comparison of MISRA C 1998 and MISRA C 2004
Language subsetting in an industrial context: a comparison of MISRA C 1998 and MISRA C 2004 Les Hatton CISM, University of Kingston∗ November 20, 2005 Abstract The MISRA C standard [7] first appeared in 1998 with the objective of providing a set of guidelines to restrict features in the ISO C language of known undefined or otherwise dangerous behaviour. The standard was assembled by representatives of a number of companies in the automobile sector in response to the rapidly growing use of C in electronic embedded systems in automobiles. The standard attempts to build on the earlier work of [6], [3] and others. Due to various perceived deficiencies, notably considerable ambiguity in the rule definitions, a revision was planned and eventually appeared in 2004. This paper measures how well the two stan- dards compare on the same population of software and also determines how well the 2004 version achieved its stated goals. Given its increasing influence, the results raise important concerns. Keywords: safer subsets, MISRA C, embedded control systems 1 Overview Pragmatic safer subsetting of languages to remove dependence on poorly defined features is finally becoming a mainstream activity with the recent recommen- dation to form a high-integrity study group under the auspices of the ISO, [8] with the intention of producing sets of rules to restrict features with undefined or otherwise dangerous behaviour in programming languages in common use. It frequently comes as a surprise to developers that significant parts of a pro- gramming language can fall into this category. In practice, all standardised programming languages contain problematic features for a variety of reasons which include the inability of the standardising committee to agree on the be- haviour of a particular feature, the use of unintentionally ambiguous language in the standards document itself, omitting to say anything at all and so on. -

MISRA-C Subset of the C Language for Critical Systems SAFETY-CRITICAL SYSTEMS
MISRA-C Subset of the C language for critical systems SAFETY-CRITICAL SYSTEMS System is safety-critical if people might die due to software bugs Examples Automobile stability / traction control Medical automation Many military applications You develop safety-critical software differently from non-critical software MISRA-C MISRA – Motor Industry Software Reliability Association Their bright idea: Can’t avoid C But can force developers to avoid features of C that are known to be problematic Some language flaws Some legitimate features that happen to be bad for embedded software Most of MISRA-C is just good common sense for any C programmer TERMINOLOGY Execution error: Something illegal done by a program Out-of-bounds array reference Divide by zero Uninitialized variable usage Trapped execution error: Immediately results in exception or program termination Untrapped execution error: Program keeps running But may fail in an unexpected way later on E.g., due to corrupted RAM In C, operations with undefined behavior are not trapped SAFETY A safe language does not allow untrapped execution errors A statically safe language catches all execution errors at compile time Useful languages can’t be completely statically safe Java is dynamically safe C and C++ are very unsafe MISRA C is not safe either However, adherence to MISRA-C can largely be statically checked This eliminates or reduces the likelihood of some kinds of untrapped execution errors MISRA-C RULE 1.2 No reliance shall be placed on undefined or unspecified behavior. Lots of things in C have undefined behavior Divide by zero Out-of-bounds memory access Signed integer overflow Lots of things in C have implementation-defined and unspecified behavior printf (“a”) + printf (“b”); Both of these hard to detect at compile time, in general Implementation-defined behavior is fine in MISRA-C Why? MISRA-C RULE 5.2 Identifiers in an inner scope shall not use the same name as an identifier in an outer scope, and therefore hide that identifier. -

Crosscore Embedded Studio 2.2.0 C/C++ Compiler Manual for SHARC
CrossCore Embedded Studio 2.2.0 C/C++ Compiler Manual for SHARC Processors Revision 1.5, February 2016 Part Number 82-100117-01 Analog Devices, Inc. One Technology Way Norwood, MA 02062-9106 Copyright Information ©2016 Analog Devices, Inc., ALL RIGHTS RESERVED. This document may not be reproduced in any form without prior, express written consent from Analog Devices, Inc. Printed in the USA. Disclaimer Analog Devices, Inc. reserves the right to change this product without prior notice. Information furnished by Ana- log Devices is believed to be accurate and reliable. However, no responsibility is assumed by Analog Devices for its use; nor for any infringement of patents or other rights of third parties which may result from its use. No license is granted by implication or otherwise under the patent rights of Analog Devices, Inc. Trademark and Service Mark Notice The Analog Devices logo, Blackfin, CrossCore, EngineerZone, EZ-Board, EZ-KIT, EZ-KIT Lite, EZ-Extender, SHARC, and VisualDSP++ are registered trademarks of Analog Devices, Inc. Blackfin+, SHARC+, and EZ-KIT Mini are trademarks of Analog Devices, Inc. All other brand and product names are trademarks or service marks of their respective owners. CrossCore Embedded Studio 2.2.0 i Contents Preface Purpose of This Manual................................................................................................................................. 1±1 Intended Audience........................................................................................................................................ -

MISRA-C:2004 Guidelines for the Use of the C Language in Critical Systems
MISRA-C:2004 Guidelines for the use of the C language in critical systems October 2004 Licensed to: Tyler Doering. 10 Sep 2008. Copy 1 of 1 First published October 2004 by MIRA Limited Watling Street Nuneaton Warwickshire CV10 0TU UK www.misra-c.com Edition 2 reprinted July 2008 incorporating Technical Corrigendum 1 © MIRA Limited, 2004, 2008. “MISRA”, “MISRA C” and the triangle logo are registered trademarks of MIRA Limited, held on behalf of the MISRA Consortium. All rights reserved. No part of this publication may be reproduced, stored in a retrieval system or transmitted in any form or by any means, electronic, mechanical or photocopying, recording or otherwise without the prior written permission of the Publisher. ISBN 978-0-9524156-2-6 paperback ISBN 978-0-9524156-4-0 PDF Printed by Hobbs the Printers Ltd British Library Cataloguing in Publication Data. A catalogue record for this book is available from the British Library This copy of MISRA-C:2004 - Guidelines for the use of the C language in critical systems is issued to Tyler Doering. The file must not be altered in any way. No permission is given for distribution of this file. This includes but is not exclusively limited to making the copy available to others by email, placing it on a server for access by intra- or inter-net, or by printing and distributing hardcopies. Any such use constitutes an infringement of copyright. MISRA gives no guarantees about the accuracy of the information contained in this PDF version of the Guidelines. The published paper document should be taken as authoritative. -

Evaluation of Open Source Operating Systems for Safety-Critical Applications Master’S Thesis in Embedded Electronic System Design
Evaluation of open source operating systems for safety-critical applications Master’s thesis in Embedded Electronic System Design Petter Sainio Berntsson Department of Computer Science and Engineering CHALMERS UNIVERSITY OF TECHNOLOGY UNIVERSITY OF GOTHENBURG Gothenburg, Sweden 2017 MASTER’S THESIS 2017 Evaluation of open source operating systems for Safety-critical applications Petter Sainio Berntsson Department of Computer Science and Engineering Chalmers University of Technology University of Gothenburg Gothenburg, Sweden 2017 Evaluation of open source operating systems for safety-critical applications Petter Sainio Berntsson © Petter Sainio Berntsson, 2017 Examiner: Per Larsson-Edefors Chalmers University of Technology Department of Computer Science and Engineering Academic supervisor: Jan Jonsson Chalmers University of Technology Department of Computer Science and Engineering Industrial supervisors: Lars Strandén RISE Research Institutes of Sweden Dependable Systems Fredrik Warg RISE Research Institutes of Sweden Dependable Systems Master’s Thesis 2017 Department of Computer Science and Engineering Chalmers University of Technology University of Gothenburg SE-412 96 Gothenburg Telephone +46(0) 31 772 1000 Abstract Today many embedded applications will have to handle multitasking with real-time time constraints and the solution for handling multitasking is to use a real-time operating system for scheduling and managing the real-time tasks. There are many different open source real-time operating systems available and the use of open source software for safety-critical applications is considered highly interesting by industries such as medical, aerospace and automotive as it enables a shorter time to market and lower development costs. If one would like to use open source software in a safety-critical context one would have to provide evidence that the software being used fulfills the requirement put forth by the industry specific standard for functional safety, such as the ISO 26262 standard for the automotive industry. -
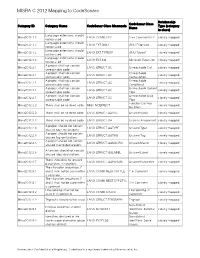
MISRA C 2012 Mapping to Codesonar®
MISRA C 2012 Mapping to CodeSonar® Relationship CodeSonar Class Category ID Category Name CodeSonar Class Mnemonic Type (category Name to class) Language extensions should Misra2012:1.2 LANG.COMM.CPP C++ Comment in C closely mapped not be used Language extensions should Misra2012:1.2 LANG.EXT.GNU GNU Extension closely mapped not be used Language extensions should Misra2012:1.2 LANG.EXT.TYPEOF GNU Typeof closely mapped not be used Language extensions should Misra2012:1.2 LANG.EXT.MS Microsoft Extension closely mapped not be used A project shall not contain Misra2012:2.1 LANG.STRUCT.UC Unreachable Call closely mapped unreachable code A project shall not contain Unreachable Misra2012:2.1 LANG.STRUCT.UC closely mapped unreachable code Computation A project shall not contain Unreachable Misra2012:2.1 LANG.STRUCT.UC closely mapped unreachable code Conditional A project shall not contain Unreachable Control Misra2012:2.1 LANG.STRUCT.UC closely mapped unreachable code Flow A project shall not contain Unreachable Data Misra2012:2.1 LANG.STRUCT.UC closely mapped unreachable code Flow Function Call Has Misra2012:2.2 There shall be no dead code MISC.NOEFFECT closely mapped No Effect Misra2012:2.2 There shall be no dead code LANG.STRUCT.UUVAL Unused Value closely mapped Misra2012:2.2 There shall be no dead code LANG.STRUCT.UA Useless Assignment closely mapped A project should not contain Misra2012:2.3 LANG.STRUCT.UUTYPE Unused Type closely mapped unused type declarations A project should not contain Misra2012:2.4 LANG.STRUCT.UUTAG Unused Tag closely -

C-STAT® Static Analysis Guide
C-STAT® Static Analysis Guide CSTAT-14 COPYRIGHT NOTICE © 2015–2021 IAR Systems AB and Synopsys, Inc. No part of this document may be reproduced without the prior written consent of IAR Systems AB. The software described in this document is furnished under a license and may only be used or copied in accordance with the terms of such a license. This publication incorporates portions of the Technical Report, “SEI CERT C Coding Standard Rules for Developing Safe, Reliable, and Secure Systems 2016 Edition,” by CERT. © 2016 Carnegie Mellon University, with special permission from its Software Engineering Institute. DISCLAIMERS The information in this document is subject to change without notice and does not represent a commitment on any part of IAR Systems. While the information contained herein is assumed to be accurate, IAR Systems assumes no responsibility for any errors or omissions. In no event shall IAR Systems, its employees, its contractors, or the authors of this document be liable for special, direct, indirect, or consequential damage, losses, costs, charges, claims, demands, claim for lost profits, fees, or expenses of any nature or kind. Any material of Carnegie Mellon University and/or its software engineering institute contained herein is furnished on an “as-is” basis. Carnegie Mellon University makes no warranties of any kind, either expressed or implied, as to any matter including, but not limited to, warranty of fitness for purpose or merchantability, exclusivity, or results obtained from use of the material. Carnegie Mellon University does not make any warranty of any kind with respect to freedom from patent, trademark, or copyright infringement. -

Embedded C Coding Standard Embedded C Coding Standard
Keeps Bugs Out EmbeddedEmbedded CC CodingCoding StandardStandard by Michael Barr ® Edition: BARR-C: 2018 | barrgroup.com BARR-C:2018 Embedded C Coding Standard Embedded C Coding Standard ii Embedded C Coding Standard Embedded C Coding Standard by Michael Barr Edition: BARR-C:2018 | barrgroup.com iii Embedded C Coding Standard Embedded C Coding Standard by Michael Barr Copyright © 2018 Integrated Embedded, LLC (dba Barr Group). All rights reserved. Published by: Barr Group 20251 Century Blvd, Suite 330 Germantown, MD 20874 This book may be purchased in print and electronic editions. A free online edition is also available. For more information see https://barrgroup.com/coding-standard. While every precaution has been taken in the preparation of this book, the publisher and author assume no responsibility for errors or omissions, or for damages resulting from the use of the information contained herein. Compliance with the coding standard rules in this book neither ensures against software defects nor legal liability. Product safety and security are your responsibility. Barr Group, the Barr Group logo, The Embedded Systems Experts, and BARR-C are trademarks or registered trademarks of Integrated Embedded, LLC. Any other trademarks used in this book are property of their respective owners. ISBN-13: 978-1-72112-798-6 ISBN-10: 1-72112-798-4 iv Embedded C Coding Standard Document License By obtaining Barr Group’s copyrighted “Embedded C Coding Standard” (the “Document”), you are agreeing to be bound by the terms of this Document License (“Agreement”). 1. RIGHTS GRANTED. For good and valuable consideration, the receipt, adequacy, and sufficiency of which is hereby acknowledged, Barr Group grants you a license to use the Document as follows: You may publish the Document for your own internal use and for the use of your internal staff in conducting your business only. -
Methods of Achieving High Color Rendering Index with Leds
Special Features: Embedded Wireless electronica Preview Boards & Modules Cover Story Methods of achieving high Color Rendering Index with LEDs VIEWPOINT Dear Readers, Once more its showtime again: the electronics industry will meet from November 11th to 14th at the fair- grounds of Messe München. Th is year electronica is celebrating its 50th birthday – evidence for the long lasting success of this event. Beside all other aspects and com- ponents of electronic embedded systems will play a major role in the exhibition and also in the embed- ded platform conference program. Th e conference is being held in conjunction with electronica in Munich on November 11 and 12. Participants of the embedded platforms conference will get an overview of and insights into the ecosystems of modern embedded platforms. Speakers may make pre- sentations on the following topics: cores and peripherals, 8-/16-bit controllers, 32-bit processors, DSP platforms, FPGAs, multicore chips, SoC approaches, security and safety, saving energy, testing, debugging, trace as well as porting and migration, RTOS and other operating systems, initializing and booting, standardization, tool chains and ecosystems, obsolescence, simulation, emulation and modelling platforms. More information about electronica 2014 and the Embedded Forum organized by ICC Media and Messe München you´ll fi nd starting at page 10 of this issue. One sector of the electronics industry which combines nearly all aspects of embedded systems is automotive electronics. Latest trend are energy effi ciency, lighting, electromobility, connected cars, and autonomous driving. Th is means that the future of driving will be electrifi ed, automated and networked. Th erefore it is expected that the value of hardware and soft ware in cars will continue to grow in the years to come. -

C++ for Safety-Critical Systems
C++ for Safety-Critical Systems Günter Obiltschnig Applied Informatics Software Engineering GmbH St. Peter 33 9184 St. Jakob im Rosental Austria [email protected] Abstract. C++ is now widely used in the development of software for embedded systems, even safety-critical and hard-real-time systems. Even if, due to their design, other programming languages may be better suited for the development of safety- critical systems, there are other relevant factors in favor of C++. Examples are availability of skilled developers and tool support. The use of C++ in the development of air vehicle software for the Joint Strike Fighter (JSF), and the public release of the C++ coding standard used in that project (JSF C++), has certainly increased the interest in using C++ for safety-critical systems. In June 2008 the MISRA C++ standard "Guidelines for the use of the C++ language in critical systems" has been released by the Motor Industry Software Reliability Association. Similar to the JSF C++ standard, the MISRA C++ standard defines rules, as well as a "safe" subset of the C++ language for the development of safety-critical systems. This paper gives an overview of both the JSF C++ and MISRA C++ standards and also looks in detail at some of their rules and the rationale behind them. An interesting aspect that is covered is also where both standard differ. For example, JSF C++ does not allow the use of C++ exceptions at all, whereas MISRA C++ specifies detailed rules for their use. 1 Introduction C++ [1] is now widely used in the development of software for embedded systems, even safety-critical and hard-real-time systems. -

Embedded Systems
Embedded Systems Peter Marwedel Embedded System Design Embedded Systems Foundations of Cyber-Physical Systems, and the Internet of Things Fourth Edition Embedded Systems Series editors Nikil D. Dutt, Irvine, CA, USA Grant Martin, Santa Clara, CA, USA Peter Marwedel, Dortmund, Germany This Series addresses current and future challenges pertaining to embedded hard- ware, software, specifications and techniques. Titles in the Series cover a focused set of embedded topics relating to traditional computing devices as well as high- tech appliances used in newer, personal devices, and related topics. The material will vary by topic but in general most volumes will include fundamental material (when appropriate), methods, designs, and techniques. More information about this series at http://www.springer.com/series/8563 Peter Marwedel Embedded System Design Embedded Systems Foundations of Cyber-Physical Systems, and the Internet of Things Fourth Edition 123 Peter Marwedel TU Dortmund Dortmund, Germany ISSN 2193-0155 ISSN 2193-0163 (electronic) Embedded Systems ISBN 978-3-030-60909-2 ISBN 978-3-030-60910-8 (eBook) https://doi.org/10.1007/978-3-030-60910-8 1st edition: Springer US 2006 2nd edition: Springer Netherlands 2011 3rd edition: Springer International Publishing 2018 © The Editor(s) (if applicable) and The Author(s) 2021. This book is an open access publication. Open Access This book is licensed under the terms of the Creative Commons Attribution 4.0 International License (http://creativecommons.org/licenses/by/4.0/), which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons license and indicate if changes were made. -

Coverity Support for MISRA Coding Standards
Coverity Support for MISRA Coding Standards Fully ensure the safety, Overview reliability, and security Software is eating the world. Industries that have traditionally relied on mechanical, of software written in C electronic, and analog control systems are increasingly replacing them with software- and C++ driven systems. For example, the average car is expected to contain 300 million lines of code in the next decade—up from 100 million lines of code today. But with the growth of software comes the growth of software defects—which can manifest themselves in these systems with tangible and life-threatening consequences. More importantly, malicious actors can deliberately trigger failures for their own purposes. Highly complex industries involve many vendors and suppliers simultaneously contributing to the software that goes into the final product. Every participant in this software supply chain must reach consensus on coding standards, defect reporting structures, and so on. The confluence of these two factors—increasing complexity in software systems and longer software supply chains—creates the demand for new tools. The MISRA C and C++ coding standards are widely used in safety-critical industries, such as automotive, medical, military, and aerospace. The standards provide a set of best practices for writing C and C++ code, facilitating the authorship of safe, secure, and portable code. With Coverity® static analysis, Synopsys provides a comprehensive solution for MISRA standard compliance that is scalable from individual developers all the way to complex software supply chains. | synopsys.com | 1 MISRA C:2004 MISRA C:2004 rule coverage The MISRA C:2004 coding standard supports the C90 language specification.