Climatic Controls on the Flood Frequency Distribution
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Ambito Della Lucera E Delle Serre Dei Monti Dauni
LEGENDA Progetto Tratti in viadotto Tratti in galleria Tratti allo scoperto Confini Regionali 245,49 Confini comunali 246,66 247,63 271,39 254,27 247,26 245,37 NORD 259,07 261,37 243,13 240,8 240,61 269,87 265,96 251,21 243,09 238,35 254,62 247,69 232,93 271,98 263,35 231,65 265,58 256,09 261,38 231,24 260,88 235,29 233,4 258,15 243,85 238,35 247,91 254,79 227,69 244,26 274,17 260,1 239,14 237,3 232,99 224,45 251,84 247,55 273,84 229,79 226,85 262,16 254,28 224,21 265,41 244,89 233,07 265,14 225,62 242,03 252,19 237,2 267,52 247,32 227,1 269,07 233,73 TROIA 236,47 239,11 BA-01 243,56 239,84 H9-L.390m 227,63 247,23 259,55 BARICASTELLUCCIO DEI SAURI 269,08 271,96 223,1 REGIONE CAMPANIAREGIONE PUGLIA 232,79 ORSARA DI 238,57 226,24 223,52 PROVINCIA DI FOGGIA PUGLIA BOVINO 228,88 Tav 1 di 2 242,63 2+484.15 Prog. 248,07 GRECI PROVINCIA DI BENEVENTO 251,83 MONTAGUTO 265,46 221,11 262,86 PROVINCIA DI AVELLINO DELICETO Prog= 29+045.95 (BD) 29+045.95 Prog= INIZIO PROGETTO DEFINITIVO BOVINO-ORSARA DEFINITIVO PROGETTO INIZIO 238,18 N.90 STATALE STRADA DEVIAZIONE FINE 233,66 PANNI 236,95 SAVIGNANO 221,37 IRPINO KM 31 229,3 223,83 258,52 237,53 240,14 NAPOLI 243,93 ACCADIA KM 31 219,39 221,79 SANT'AGATA H3 226,86 ARIANO dispari VA .1 VA dispari FA01B V4 M1 225,32 FA01D 230,15 IRPINO DI PUGLIA FA01C FA01D 232,16 QMT MONTELEONE FA01D PLINTO 221,85 PER PALO GSM-R 237,33 KM 30 KM DI PUGLIA NORD 251,2 225,07 219,34 233,21 .1 VA pari 234,9 5 238,8 30 KM 240,45 6 225,07 PASSAGGIO DOPPIO/SINGOLO BINARIO LINEA ESISTENTE CERVARO-BOVINO COMUNICAZIONE P/D S 60U/1200/0.040dx -

Real Collegio Di Lucera. Appendice
ARCHIVIO DI STATO DI FOGGIA INTENDENZA, GOVERNO E PREFETTURA DI CAPITANATA - PUBBLICA ISTRUZIONE REAL COLLEGIO DI LUCERA - APPENDICE 1809 - 1861 Busta Fascicolo Oggetto Anni Osservazioni L'inventariazione delle scritture dell'Appendice, tutte riguardanti il Real Collegio di Lucera, è stata curata dalla dr.ssa Maria De Lisi, documentalista, nel 1986. 1 1 Disposizioni relative alla ristrutturazione dei locali del 1809 Contiene una piantina del Real Collegio adibiti a scuole, refettorio e cucina. Collegio. 1 2 Disposizioni relative ai debitori del Collegio. 1809-1812 1 3 Compensi spettanti al rettore ed al suo segretario. 1812 1 4 Ordinativi di pagamento relativi alle spese per l'istruzione 1812-1813 pubblica nell'esercizio del 1812. 1 5 Deliberazione della Commissione amministrativa sullo 1813-1814 stanziamento di somme da utilizzare per forniture varie per la riattazione del muraglione del Real Collegio e per i bruchi. 1 6 Manifesto per l'appalto delle rendite del Real Collegio. 1816 1 7 Invio di un certificato dalla Gran Corte dei Conti da notificare 1818 all'Economo Saverio Prisari. 1 8 Circolare del Ministero degli Affari Interni relativa alle 1818 disposizioni impartite con D.R. 11-05-1816 sulla presentazione del conto annuale da rimettere all'esame della Gran Corte dei Conti. 1 9 Delibera relativa al nuovo sistema di esazione delle rendite 1820 da adottarsi a cura del contabile del Real Collegio. 1 10 Ordinativi di pagamento relativi alle somme reclamate dal 1821 rettore per gratificazioni spettanti ai professori. 1 11 Spesa per il restauro della Chiesa del Real Collegio e degli 1824 arredi sacri. 1 12 Assegnazione di fondi al Real Collegio per il saldo 1826 dell'esercizio finanziario 1825. -

Cronaca Di Sant'agata Di Puglia
- E a DI PIGLI o o o - l - - - - - - A cronaca DI SANTAGATA DI PUGLIA PER ſorrnzo Agnetti v- - SCIACCA TI P O G R A FIA G U TT E M B E R G 1869. vm - l Nacqui Pur io su un colle, che sereno e svelto I piedi allarga tra lo Speca e il Frugno, E, qual desto gigante, agli ampli piani, Da vér l'occaso, della Daunia l'occhio Drizza ed a scolta secolar riposa Tra boschive colline. Fa coperchio Al dritto capo una torrita rocca, Ai miti affetti or di famiglia vòlta, Ma un dì pugnace, e guardiana intenta Di genti all'odio baronale invise. I monti della Calabria. Proprietà letteraria AI, . CH. AVV. COSTANTINO VOLPE Gentilissimo Costantino Antico e continuo affetto ci lega, nè può venir meno. La nostra giovinezza si aprì con i canti, ispi rati dalla limpidezza del nostro cielo, dai bisogni del nostro popolo, dalla giustizia e serenità delle spe ranze nostre, che pure altrui sembravan sogni; ora non più. Per diverse strade movemmo, ma c'incon trammo sempre nella virtù e nella costanza di fare qualche cosa di bene pel nostro comune luogo nativo. Io peregrino di qua e di là, trascinato ora da pen siero di vedere e saper meglio cose ed uomini, ora da una mano segreta, che mi spingea, ora dal bisogno di un cuore ardente, tra i patiti disinganni e le ma linconiche veglie, ho guardato sempre la collina, che ci vide nascere, studiando se non ad arricchirla di gloria, a non oltraggiarla almeno. Tu più fortunato, dopo largamente disfogato il cuore in tenere e care poesie, con un angelo di consorte accanto, che ti arricchisce di figli, hai consacrato te - º medesimo per sei anni ad aprire il paese al commercio, ed alle lettere, a migliorar le strade e gli edifici, ad accrescerne le rendite. -

Bovino -Deliceto - Castelluccio Dei Sauri Località "Monte Livagni"
REGIONE PUGLIA PROVINCIA DI FOGGIA Comune: Bovino -Deliceto - Castelluccio dei Sauri Località "Monte Livagni" PROGETTO DEFINITIVO PER LA REALIZZAZIONE DI UN IMPIANTO DI PRODUZIONE DI ENERGIA ELETTRICA DA FONTE EOLICA E RELATIVE OPERE DI CONNESSIONE - 10 AEROGENERATORI - Sezione 0: RELAZIONI GENERALI Titolo elaborato: STUDIO DI COMPATIBILITA’ IDROLOGICA E IDRAULICA - ALLEGATO 8 - Output dei risultati ottenuti con il software Hec-Ras in corrispondenza di ogni sezione di calcolo N. Elaborato: 0.7.8 Scala: - Committente Progettazione WINDERG S.r.l. Via Trento, 64 sede legale e operativa Vimercate (MB) San Giorgio Del Sannio (BN) via de Gasperi 61 P.IVA 04702520968 sede operativa Lucera (FG) S.S.17 loc. Vaccarella snc c/o Villaggio Don Bosco P.IVA 01465940623 $]LHQGDFRQVLVWHPDJHVWLRQHTXDOLWj&HUWLILFDWR1 Amministratore Unico Progettista Michele GIAMBELLI Dott. Ing. Nicola FORTE 00 OTTOBRE 2018 LR NF NF Emissione Progetto Definitivo sigla sigla sigla Data DESCRIZIONE Rev. Elaborazione Approvazione Emissione Nome File sorgente GE.BOV01.PD.0.7.8.dwg Nome file stampa GE.BOV01.PD.0.7.8.pdf Formato di stampa A4 Studio di compatibilità idrologica e idraulica - Codice GE.BOV01.PD.0.5 Revisione 00 Relazione idrologica Data 16/04/2018 Pagina 1 di 33 Sommario 1. PREMESSA ..................................................................................... 3 2. DESCRIZIONE SINTETICA DELL’IMPIANTO ............................................ 8 2.1 Generalità .................................................................................................................. -
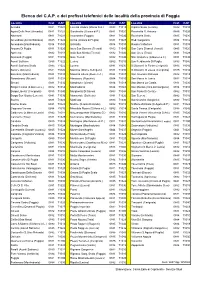
CAP Località Pref
Elenco dei C.A.P. e dei prefissi telefonici delle località della provincia di Foggia Località Pref. CAP Località Pref. CAP Località Pref. CAP Accadia 0881 71021 Foresta Umbra (Monte S.A.) 0884 71018 Ripalta Scalo (Lesina) 0882 71010 Agata Delle Noci (Accadia) 0881 71021 Giardinetto (Orsara di P.) 0881 71020 Rocchetta S. Antonio 0885 71020 Alberona 0881 71031 Incoronata (Foggia) 0881 71040 Rocchetta Scalo 0885 71020 Amendola (Ascoli Satriano) 0885 71022 Ischia (Orsara di Puglia) 0881 71027 Rodi Garganico 0884 71012 Amendola (Manfredonia) 0884 71043 Ischitella 0884 71010 Roseto Valfortore 0881 71039 Anzano Di Puglia 0881 71020 Isola San Domino (Tremiti) 0882 71040 San Carlo D'ascoli (Ascoli) 0885 71020 Apricena 0882 71011 Isola San Nicola (Tremiti) 0882 71040 San Cireo (Troia) 0881 71029 Arpinova (Foggia) 0881 71010 Isole Tremiti 0882 71040 San Cristoforo (S.Marco La C.) 0881 71030 Ascoli Satriano 0885 71022 Lesina 0882 71010 San Ferdinando Di Puglia 0883 71046 Ascoli Satriano Scalo 0885 71022 Lucera 0881 71036 S.Giovanni In Fonte (Cerignola) 0885 71042 Barone Deliceto) 0881 71026 Macchia (Monte S.Angelo) 0884 71030 S.Giovanni In Zezza (Cerignola) 0885 71042 Beccarini (Manfredonia) 0884 71043 Macchia Libera (Monte S.A.) 0884 71037 San Giovanni Rotondo 0882 71013 Berardinone (Biccari) 0881 71032 Manacore (Peschici) 0884 71010 San Marco In Lamis 0882 71014 Biccari 0881 71032 Mandrione (Vieste) 0884 71019 San Marco La Catola 0881 71030 Borgo Celano (S.Marco in L.) 0882 71014 Manfredonia 0884 71043 San Menaio (Vico del Gargano) 0884 71010 Borgo -

Page 1 ISSN 0376-9453 Amtsblatt L 194 Der Europäischen
ISSN 0376-9453 Amtsblatt L 194 34 . Jahrgang der Europäischen Gemeinschaften 17. Juli 1991 \usgabe in deutscher Sprache Rechtsvorschriften Inhalt I Veröffentlichungsbedürftige Rechtsakte Verordnung (EWG) Nr. 2091/91 der Kommission vom 12. Juli 1991 zur Festlegung der durchschnittlichen Erträge an Oliven und Olivenöl für die vier Wirtschaftsjahre 1986/87 bis 1989/90 1 Preis : 20 ECU Bei Rechtsakten, deren Titel in magerer Schrift gedruckt sind, handelt es sich um Rechtsakte der laufenden Verwaltung im Bereich der Agrarpolitik, die normalerweise nur eine begrenzte Geltungsdauer haben. Rechtsakte, deren Titel in fetter Schrift gedruckt sind und denen ein Sternchen vorangestellt ist, sind sonstige Rechtsakte . 17. 7 . 91 Amtsblatt der Europäischen Gemeinschaften Nr. L 194/ 1 I (Veröffentlichungsbedürftige Rechtsakte) VERORDNUNG (EWG) Nr. 2091 /91 DER KOMMISSION vom 12. Juli 1991 zur Festlegung der durchschnittlichen Erträge an Oliven und Olivenöl für die vier Wirt schaftsjahre 1986/87 bis 1989/90 DIE KOMMISSION DER EUROPÄISCHEN laufenden Wirtschaftsjahres die Durchschnitte der Oli GEMEINSCHAFTEN — ven- und Olivenölerträge der vier letzten Wirtschafts jahre festlegt. Diese Durchschnittserträge sind deshalb gestützt auf den Vertrag zur Gründung der Europäi wie im Anhang angegeben festzulegen . schen Wirtschaftsgemeinschaft, gestützt auf die Verordnung Nr. 136/66/EWG des Ra Die in dieser Verordnung vorgesehenen Maßnahmen tes vom 22. September 1966 über die Errichtung einer entsprechen der Stellungnahme des Verwaltungsaus gemeinsamen Marktorganisation für Fette ( 1 ), zuletzt ge schusses für Fette — ändert durch die Verordnung (EWG) Nr. 1720/91 (2), gestützt auf die Verordnung (EWG) Nr. 2261 /84 des HAT FOLGENDE VERORDNUNG ERLASSEN : Rates vom 17 . Juli 1984 mit Grundregeln für die Gewäh rung der Erzeugungsbeihilfe für Olivenöl und für die Artikel 1 Olivenölerzeugerorganisationen (3), zuletzt geändert durch die Verordnung (EWG) Nr. -

SLEEPING ARRANGEMENTS in SAN SEVERO
HANDBOOK of the Creation Study of the path -- Federico Croce and Michele del Giudice Historic consultation -- Renzo Infante Translation -- Lou Flessner and Shawn Norris Coordination -- Antonello del Giudice This guide is for pilgrims and walkers who wish to take the Via Francigena in the province of Foggia towards the Sacred Cave of San Michele Arcangelo . HAVE A GOOD WALK This work is released by Michele del Giudice Creative Commons license Attribution-NonCommercial-NoDerivs 2.5 Generic (CC BY-NC-ND 2.5) To read a copy of the license visit the web site https://creativecommons.org/licenses/by-nc-nd/2.5/. 1 Overview Map of the Path A distance of approximately 130 km, in six stages, in ancient Daunia, climbing towards the Sacred Mountain of the Gargano where the Holy Cave of the Archangel Michael in Monte Sant’Angelo is located, a UNESCO World Heritage Site. Basilica of St. Michael – Monte Sant’Angelo 2 The path divided into 6 stages: 1 Monte San Vito - Troia Km. 23 2 Troia - Lucera Km. 19 3 Lucera – San Severo Km. 20 4 Severo – Santuario Stignano Km. 21 5 Stignano – San Giovanni Rotondo Km. 23 6 San Giovanni Rotondo – Monte Sant’Angelo Km. 24 The maps below use DATUM-ED 50/UTM 33 as a reference system. “DATUM - ED 50 / UTM 33” 3 st 1 STAGE Monte San Vito – Troia Download the route for GPS: https://www.dropbox.com/s/ouwju1d04m0rz2s/TRACCE.rar?dl=0 4 PATH DESCRIPTION MONTE SAN VITO - TROIA General news Km description Start: border region End: Troia You begin at the village of San Leonardo (the Municipality of Distance: 18 km Faeto). -

IDRAULICA LOTT ORTA NOVA.Pdf
STUDIO DI GEOLOGIA TECNNICA E AMBIENTALE Dott. Luca Salcuni STUDIO DI GEOLOGIA TECNICA E AMBIENTALE Dott.LUCA SALCUNI Via B. Angelico, 39 - 71036 Lucera (FG ) - cell. 349 8161003 E-mail: [email protected] P.IVA 03440580714 COMUNE di ORTA NOVA STUDIO DI COMPATIBILITA’ IDROLOGICA ED IDRAULICA PROGETTO: Progetto del piano di lottizzazione del comparto n°10 del comune di Orta Nova (FG). COMMITTENTE: FESTA IMMOBILIARE SRL, LOSITO FRANCESCO E SAVERIO, LOSITO LORENZO, VENTURA MARIA ADDOLORATA, VENTURA MICHELINA, VENTURA TECLA, PICCIRILLO ANNA, TORCHIARELLA LUIGI, CICCARELLI ROSA, DEMPEC LUCA, DEMPEC PAOLO (con quota di comunione dei beni), DEMPEC PASQUALE (con quota di comunione dei beni), DEMPEC VINCENZO. STUDIO DI GEOLOGIA TECNICA E AMBIENTALE Dott. Luca Salcuni FEBBRAIO 2011 STUDIO DI GELOGIA TECNICA E AMBIENTALE Dott. Luca Salcuni INDICE 1 PREMESSA ................................................................................................................... 3 2 INQUADRAMENTO GEOGRAFICO .......................................................................... 4 3 CENNI GEOLOGICI E GEOMORFOLOGICI .............................................................. 5 4 ASPETTI GEOLOGICI E CLIMATICI DEL SITO ..................................................... 6 4.1 MORFOLOGIA e IDROGRAFIA .......................................................................... 6 5. STUDIO IDROLOGICO ................................................................................................ 9 6. STUDIO IDRAULICO ................................................................................................ -

Collegio Notarile Dei Distretti Riuniti Di Foggia E Lucera Corte Di Appello Di
COLLEGIO NOTARILE DEI DISTRETTI RIUNITI DI FOGGIA E LUCERA CORTE DI APPELLO DI BARI TABELLA DEI NOTAI IN ESERCIZIO AGGIORNATA AL 4 MARZO 2021 COLLEGIO NOTARILE DEI DISTRETTI RIUNITI DI FOGGIA E LUCERA Corso Vittorio Emanuele II, 8 - Tel. e Fax: 0881 724105 E-mail: [email protected] E-mail: [email protected] E.Mail pec:[email protected] COMPOSIZIONE DEL CONSIGLIO NOTARILE: al 4 marzo 2021 1) STANGO Antonio -Presidente 2) CALDERISI Clorinda C.C.L. -Tesoriere 3) ARENA Michela -Segretario 4) BENINCASO Amelia Anna -Consigliere 5) DI RUBERTO Antonella -Consigliere 6) DI TARANTO Francesco -Consigliere 7) PUGLIESE Antonio -Consigliere 8) TORELLI Matteo -Consigliere 9) VASSALLI Gustavo -Consigliere NOTAI RESIDENTI IN FOGGIA N. NOTAIO DATA DECRETO DI DATA INIZIALE STUDIO Telefono Giorni di Assistenza personale allo studio PRIMA NOMINA DI ESERCIZIO E.MAIL approvati dal Consiglio Notarile il 20.11. 2012 (in vigore dal 1° dicembre 2012) 1 AUGELLI Michele 02/03/1984 07/05/1984 Via Dante A.,6 0881 Lunedì-Mercoledì-Venerdì GLL MHL 56A14 E549M Fax: 0881.709948 720391 e.mail: [email protected] 2 CALDERISI Clorinda Concetta 02/10/1981 01/02/1982 Via Luigi Miranda snc 0881 Martedì-Mercoledì-Giovedì Camilla Lucia Fax:0881.772546 772545 CLD CRN 50E49 E631M e.mail:[email protected] 3 CAPUTO Felice 15/05/1990 28/08/1990 Viale Giuseppe Di Vittorio n.188 0881 Martedì-Giovedì-Venerdì CPT FLC 56R20 C983J Fax: 0881.707807.709291 709291 e.mail:[email protected] 4 DI CARLO Bruno 02/03/1984 30/06/1984 Via San Lorenzo,1 0881 Martedì-Mercoledì-Venerdì DCR BNG 51C22D643V Fax: 0881.709851 727254 e.mail:[email protected] 5 DI RUBERTO Antonella 19/09/1997 22/12/1997 Corso Roma,204/A 0881 Lunedì-Mercoledì-Venerdì DRB NNL 63B45 G604D Fax: 0881.331499 331499 e.mail:[email protected] 6 STANGO Antonio 09/04/2001 03/07/2001 Via Quattro Novembre n.2 0881 Martedì-Giovedì-Venerdì STN NTN 69A21 D643R trasferito a Foggia Fax:0881.709460 709460 il 14 11 2018. -

Sedi Periferiche
IMPIANTI E STRUTTURE DI PRESIDIO Nord Fortore IMPIANTO Comune Località Telefono DIGA DI OCCHITO Carlantino Occhito 0881 552026 0881 NODO DI FINOCCHITO Casalvecchio Sculgola 558316/558660 SOLLEVAMENTO Contrada Torremaggiore 0882 381358 BELLANTUONI Bellantuoni SOLLEVAMENTO Contrada Torremaggiore 0882 391679 MONACHELLE Monachelle Poggio Contrada SOLLEVAMENTO POZZILLI 0882 997981 Imperiale Pozzilli SOLLEVAMENTO Castelnuovo Contrada 0882 391957 RENZULLI (Area Agraria) della Daunia Renzulli Distretto 8 - VACCARECCIA (Area Lesina Ripalta 0882 991964 Agraria) Sud Fortore IMPIANTO Comune Località Telefono Località DIGA CAPACCIO Lucera 0881 542966 Torrebianca Contrada TORRE P1 San Severo 336 829370 Sabatella Masseria TORRE P2 Foggia 336 838752 Cavalieri Tratturo TORRE P3 Foggia 0881 779316 Castiglione Località VASCA CELONE Lucera 0881 542935 Torrebianca Località La VASCA TAVOLIERE Lucera 0881 521960 Marchesa Sinistra Ofanto IMPIANTO Comune Località Telefono Contrada DIGA CAPACCIOTTI Cerignola Marrano 0885 418730 Capace SOLLEVAMENTO C.da Montagna Cerignola 0885 418910 MONTAGNA SPACCATA Spaccata SOLLEVAMENTO Contrada Candela 0885 660791 CANESTRELLO Canestrello DIGA sull' OSENTO Aquilonia (AV) San Pietro 0827 86142 IMPIANTO Comune Località Telefono IDROVORA PALUDE Sannicandro Contrada Lauro 336 619481 LAURO 1^ ZONA IDROVORA PALUDE Contrada Lesina 336 203523 GRANDE 1^ ZONA Palude Grande Contrada IDROVORA MEZZANA Rignano Mezzana 336 203527 GRANDE 1^ ZONA Grande IDROVORA CANDELARO Contrada Manfredonia 0884 571445 2^ ZONA Candelaro IDROVORA SIPONTO Manfredonia Viale dei Pini 0884 542544 2^ ZONA IDROVORA SALPI Trinitapoli Località Salpi 0883 632730 3^ ZONA IDROVORA ZAPPONETA Via Zapponeta 0884 520220 3^ ZONA Manfredonia CENTRI DI IRRIGAZIONE PROVVISTI DI UNO SPAZIO DEDICATO ALL’UTENZA Nord Fortore distretti Agro/ Centro urbano Località telefono 1-2A-2B Torremaggiore Renzulli 0881.391957 8 Lesina Vaccareccia 0882.991964 11 San Severo/ Via Croce 0882 .375985 Santa, 48 9-10AB -10CD San Paolo di C. -

Maths Challenge 2021 Elenco Ammessi Alla Prova Finale*
MATHS CHALLENGE 2021 ELENCO AMMESSI ALLA PROVA FINALE* *Alla prova finale sono ammessi gli studenti che si sono classificati nelle prime 10 posizioni della graduatoria di Istituto inclusi eventuali ex-equo. GRADUATORIE DI ISTITUTO Nome Cognome Classe ISTITUTO Gabriele Nardella IV I. T. E. BLAISE PASCAL - Foggia Roberta Palmieri V I. T. E. BLAISE PASCAL - Foggia Antonio Iammarino V I. T. E. BLAISE PASCAL - Foggia Andrea di Corcia V I. T. E. BLAISE PASCAL - Foggia Lucia Meliota IV I. T. E. BLAISE PASCAL - Foggia Lucia Pia Silvestri V I. T. E. BLAISE PASCAL - Foggia Roberta Ricciardi V I. T. E. BLAISE PASCAL - Foggia Roberta Caldarone V I. T. E. BLAISE PASCAL - Foggia Antonio Pio Ferrecchia V I. T. E. BLAISE PASCAL - Foggia Raffaele Stanco IV I. T. E. BLAISE PASCAL - Foggia Rocco Mitola IV I. T. E. BLAISE PASCAL - Foggia Luca Del Tito IV I. T. E. BLAISE PASCAL - Foggia Giulia Maria d'Adduzio IV I. T. E. BLAISE PASCAL - Foggia Annalisa Pastore V I.P.S.E.O.A. Molfetta Domenico Landriscina V I.P.S.E.O.A. Molfetta Felice Campanale IV I.P.S.E.O.A. Molfetta Rossana Di bari V I.P.S.E.O.A. Molfetta carola Carlà V I.P.S.E.O.A. Molfetta Gioia Storelli V I.P.S.E.O.A. Molfetta Simone Amorese V I.P.S.E.O.A. Molfetta Silvia Fracchiolla IV I.P.S.E.O.A. Molfetta Gianvito Napoletano V I.P.S.E.O.A. Molfetta Simona Altamura V I.P.S.E.O.A. -

Occupying Puglia: the Italians and the Allies, 1943-1946
Occupying Puglia: The Italians and the Allies, 1943-1946 Amy Louise Outterside Doctor of Philosophy School of History, Classics and Archaeology July 2015 1 Table of Contents Abstract ................................................................................................................................................................ 3 Acknowledgements .............................................................................................................................................. 4 Abbreviations ....................................................................................................................................................... 5 Map of Puglia ...................................................................................................................................................... 6 Introduction ......................................................................................................................................................... 7 Narratives of the Italian campaign .................................................................................................................. 9 Allied Military Government .......................................................................................................................... 17 Key historiography on Southern Italy ........................................................................................................... 23 Puglia ............................................................................................................................................................