Finnish Sound Structure. Phonetics, Phonology, Phonotactics and Prosody
Total Page:16
File Type:pdf, Size:1020Kb

Load more
Recommended publications
-

Syllabic Consonants and Phonotactics Syllabic Consonants
Syllabic consonants and phonotactics Syllabic consonants Consonants that stand as the peak of the syllable, and perform the functions of vowels, are called syllabic consonants. For example, in words like sudden and saddle, the consonant [d] is followed by either the consonant [n] or [l] without a vowel intervening. The [n] of sadden and the [l] of saddle constitute the centre of the second, unstressed, syllable and are considered to be syllabic peaks. They typically occur in an unstressed syllable immediately following the alveolar consonants, [t, s, z] as well as [d]. Examples of syllabic consonants Cattle [kæțɬ] wrestle [resɬ] Couple [kʌpɬ] knuckle [nʌkɬ] Panel[pæņɬ] petal [petɬ] Parcel [pa:șɬ] pedal [pedɬ] It is not unusual to find two syllabic consonants together. Examples are: national [næʃņɬ] literal [litrɬ] visionary [viʒņri] veteran [vetrņ] Phonotactics Phonotactic constraints determine what sounds can be put together to form the different parts of a syllable in a language. Examples: English onsets /kl/ is okay: “clean” “clamp” /pl/ is okay: “play” “plaque” */tl/ is not okay: *tlay *tlamp. We don’t often have words that begin with /tl/, /dm/, /rk/, etc. in English. However, these combinations can occur in the middle or final positions. So, what is phonotactics? Phonotactics is part of the phonology of a language. Phonotactics restricts the possible sound sequences and syllable structures in a language. Phonotactic constraint refers to any specific restriction To understand phonotactics, one must first understand syllable structure. Permissible language structures Languages differ in permissible syllable structures. Below are some simplified examples. Hawaiian: V, CV Japanese: V, CV, CVC Korean: V, CV, CVC, VCC, CVCC English: V CV CCV CCCV VC CVC CCVC CCCVC VCC CVCC CCVCC CCCVCC VCCC CVCCC CCVCCC CCCVCCC English consonant clusters sequences English allows CC and CCC clusters in onsets and codas, but they are highly restricted. -

Finnish Inserted Vowels: a Case of Phonologized Excrescence
Nordic Journal of Linguistics (2021), page 1 of 31 doi:10.1017/S033258652100007X ARTICLE Finnish inserted vowels: a case of phonologized excrescence Robin Karlin University of Wisconsin-Madison, Waisman Center, Madison, WI, 53705, USA Email for correspondence: [email protected] (Received 12 March 2019; revised 1 September 2020; accepted 10 December 2020) Abstract In this paper, I examine a case of vowel insertion found in Savo and Pohjanmaa dialects of Finnish that is typically called “epenthesis”, but which demonstrates characteristics of both phonetic excrescence and phonological epenthesis. Based on a phonological analysis paired with an acoustic corpus study, I argue that Finnish vowel insertion is the mixed result of phonetic excrescence and the phonologization of these vowels, and is related to second-mora lengthening, another dialectal phenomenon. I propose a gestural model of second-mora lengthening that would generate vowel insertion in its original phonetic state. The link to second-mora lengthening provides a unified account that addresses both the dialectal and phonological distribution of the phenomenon, which have not been linked in previous literature. Keywords: excrescence; epenthesis; Finnish; gestures; phonetics; phonology 1. Introduction In this paper, I examine a case of vowel insertion found in Savo and Pohjanmaa dialects of Finnish that has typically been analyzed as a phonological repair, but which demonstrates characteristics of both phonetic excrescence and phonological epenthesis. Using both acoustic data and a phonological analysis of the distribution, I argue that Finnish vowel insertion originated as a phonetic intrusion, but then became phonologized over time. I follow Hall (2006) in assuming that excrescent vowels are the result of gestural underlap, and argue that the original gestural underlap was caused by second-mora lengthening, another phenomenon present in these dialects. -

CONSONANT CLUSTER PHONOTACTICS: a PERCEPTUAL APPROACH by MARIE-HÉLÈNE CÔTÉ B.Sc. Sciences Économiques, Université De Montr
CONSONANT CLUSTER PHONOTACTICS: A PERCEPTUAL APPROACH by MARIE-HÉLÈNE CÔTÉ B.Sc. Sciences économiques, Université de Montréal (1987) Diplôme Relations Internationales, Institut d’Études Politiques de Paris (1990) D.E.A. Démographie économique, Institut d’Études Politiques de Paris (1991) M.A. Linguistique, Université de Montréal (1995) Submitted to the department of Linguistics and Philosophy in partial fulfillment of the requirement for the degree of DOCTOR OF PHILOSOPHY À ma mère et à mon bébé, at the qui nous ont quittés À Marielle et Émile, MASSACHUSETTS INSTITUTE OF TECHNOLOGY qui nous sont arrivés À Jean-Pierre, qui est toujours là September 2000 © 2000 Marie-Hélène Côté. All rights reserved. The author hereby grants to M.I.T. the permission to reproduce and to distribute publicly paper and electronic copies of this thesis document in whole or in part. Signature of author_________________________________________________ Department of Linguistics and Philosophy August 25, 2000 Certified by_______________________________________________________ Professor Michael Kenstowicz Thesis supervisor Accepted by______________________________________________________ Alec Marantz Chairman, Department of Linguistics and Philosophy CONSONANT CLUSTER PHONOTACTICS: A PERCEPTUAL APPROACH NOTES ON THE PRESENT VERSION by The present version, finished in July 2001, differs slightly from the official one, deposited in September 2000. The acknowledgments were finally added. The MARIE-HÉLÈNE CÔTÉ formatting was changed and the presentation generally improved. Several typos were corrected, and the references were updated, when papers originally cited as manuscripts were subsequently published. A couple of references were also added, as Submitted to the Department of Linguistics and Philosophy well as short conclusions to chapters 3, 4, and 5, which for the most part summarize on September 5, 2000, in partial fulfillment of the requirements the chapter in question. -

On Syncope in Old English
In: Dieter Kastovsky and Aleksander Szwedek (eds) Linguistics across historical and geographical boundaries. In honour of Jacek Fisiak on the occasion of his fiftieth birthday. Berlin: Mouton-de Gruyter, 1986, 359-66. On syncope in Old English Raymond Hickey University of Bonn Abstract. Syncope in Old English is seen to be a rule which is determined by syllable structure but furthermore to be governed by a set of restricting conditions which refer to the world-class status of the forms which may act as input to the syncope rule, and also to the inflectional or derivational nature of the suffix which are added also to the precise phonological structure of those forms which undergo syncope. A phonological rule in a language which does not operate globally is always of particular interest as the conditions which restrict its application can frequently be recognized and formulized, at the same time throwing light on the nature of conditions which can in principle apply in a language’s phonology. In Old English a syncope rule existed which clearly related to the syllable structure of the forms it did not operate on but which was also subject to a set of restricting conditions which lie outside the domain of the syllable. The examination of this syncope rule and the conditions pertaining to it is the subject of this contribution. It is first of all necessary to distinguish syncope from another phonological process with which it might be confused. This is epenthesis, which appears to have been quite widespread in late West Saxon, as can be seen in the following forms. -

Sixth Periodical Report Presented to the Secretary General of the Council of Europe in Accordance with Article 15 of the Charter
Strasbourg, 1 July 2014 MIN-LANG (2014) PR7 EUROPEAN CHARTER FOR REGIONAL OR MINORITY LANGUAGES Sixth periodical report presented to the Secretary General of the Council of Europe in accordance with Article 15 of the Charter NORWAY THE EUROPEAN CHARTER FOR REGIONAL OR MINORITY LANGUAGES SIXTH PERIODICAL REPORT NORWAY Norwegian Ministry of Local Government and Modernisation 2014 1 Contents Part I ........................................................................................................................................... 3 Foreword ................................................................................................................................ 3 Users of regional or minority languages ................................................................................ 5 Policy, legislation and practice – changes .............................................................................. 6 Recommendations of the Committee of Ministers – measures for following up the recommendations ................................................................................................................... 9 Part II ........................................................................................................................................ 14 Part II of the Charter – Overview of measures taken to apply Article 7 of the Charter to the regional or minority languages recognised by the State ...................................................... 14 Article 7 –Information on each language and measures to implement -

UNIVERSITY of VAASA Faculty of Humanities Department of English
UNIVERSITY OF VAASA Faculty of Humanities Department of English Laura Miettinen and Marika Ylinen Mother Tongue: Aid or Obstacle? Errors Made by Finnish- and Swedish-speaking Learners of English Masters Thesis Vaasa 2007 2 TABLE OF CONTENTS ABSTRACT 5 1 INTRODUCTION 7 1.1 Material 9 1.2 Method 12 1.3 Cohorts 15 2 FOREIGN LANGUAGE LEARNING 18 2.1 Effect of First Language on Foreign Language Learning 18 2.2 Bilingualism in Foreign Language Learning 22 3 ERRORS IN FOREIGN LANGUAGE LEARNING 26 3.1 Error Types 26 3.2 Error Analysis 28 4 DIFFERENCES AND SIMILARITIES BETWEEN FINNISH, SWEDISH AND ENGLISH 32 4.1 Grammatical Similarities and Differences 34 4.2 Lexical Similarities and Differences 36 5 ERRORS MADE BY NINTH GRADERS 38 5.1 Grammatical Errors 40 5.1.1 Articles 41 5.1.2 Prepositions 44 5.1.3 Verbs 47 5.1.4 Pronouns 50 5.1.5 Word Order 52 5.1.6 Plural Formation 52 5.2 Lexical Errors 54 5.2.1 Spelling 55 3 5.2.2 Vocabulary 57 5.3 Non-idiomatic Language 57 6 ERRORS MADE BY UNIVERSITY APPLICANTS 60 6.1 Grammatical Errors 63 6.1.1 Articles 64 6.1.2 Pronouns 67 6.1.3 Prepositions 69 6.1.4 Verbs 71 6.1.5 Word Order 74 6.2 Lexical Errors 75 6.2.1 Spelling 76 6.2.2 Vocabulary 77 6.3 Non-idiomatic Language 78 7 ERRORS MADE BY UNIVERSITY STUDENTS 80 7.1 Grammatical Errors 83 7.1.1 Articles 85 7.1.2 Prepositions 86 7.1.3 Verbs 88 7.1.4 Pronouns 90 7.2. -

Finnish Standardization of Finnish Orthography: from Reformists to National Awakeners
Finnish Standardization of Finnish orthography: From reformists to national awakeners Taru Nordlund 0. Introduction This article examines the standardization of Finnish orthography, concen- trating on the two periods of rapid development: the 16th and the 19th cen- turies. The first part discusses the role of the Western Church at the early stages of written Finnish: conversion to Christianity and especially the Lu- theran Reformation in the 16th century set the foundations for the usage of Finnish as a literary language. To provide a background to the standardiza- tion of orthography in the 16th and the 19th centuries, the spelling system of Modern Finnish is introduced in section 2. The following sections 3–5 discuss the orthography of the earliest writings and provide some examples of the problems that the first writers were faced with. The second external trigger for the evolution of Standard Finnish was European nationalism, which had reached Finland by the beginning of the 19th century. This era was characterized by a strong desire for nation-building, which was linguis- tically reflected in the process of standardization with its often heated de- bates about the “authenticity” or “purity” of the language. In section 6, aspects of 19th-century spelling are discussed. In most respects, the orthog- raphy of 19th-century Finnish resembles that of Modern Finnish. However, there were some debates on orthography that clearly reveal the nationalistic aspirations of the time. At the end of the article, one of these debates is discussed in more detail. DOI 10.1515/9783110288179.351, ©2017 Taru Nordlund, published by De Gruyter. -

The Finnish Noun Phrase
Università Ca’ Foscari di Venezia Facoltà di Lingue e Letterature Straniere Corso di Laurea Specialistica in Scienze del Linguaggio The Finnish Noun Phrase Relatore: Prof.ssa Giuliana Giusti Correlatore: Prof. Guglielmo Cinque Laureanda: Lena Dal Pozzo Matricola: 803546 ANNO ACCADEMICO: 2006/2007 A mia madre Table of contents Acknowledgements ………………………………………………………….…….…… III Abstract ………………………………………………………………………………........ V Abbreviations ……………………………………………………………………………VII 1. Word order in Finnish …………………………………………………………………1 1.1 The order of constituents in the clause …………………………………………...2 1.2 Word order and interpretation .......……………………………………………… 8 1.3 The order of constituents in the Nominal Expression ………………………… 11 1.3.1. Determiners and Possessors …………………………………………………12 1.3.2. Adjectives and other modifiers …………………………………………..… 17 1.3.2.1 Adjectival hierarchy…………………………………………………………23 1.3.2.2 Predicative structures and complements …………………………………26 1.3.3 Relative clauses …………………………………………………………….... 28 1.4 Conclusions ............……………………………………………………………. 30 2. Thematic relations in nominal expressions ……………………………………….. 32 2.1 Observations on Argument Structure ………………………………….……. 32 2.1.1 Result and Event nouns…………………………………………………… 36 2.2 Transitive nouns ………………………………………………………………... 38 2.2.1 Compound nouns ……………….……………………………………... 40 2.2.2 Intransitive nouns derived from transitive verbs …………………… 41 2.3 Passive nouns …………………………………………………………………… 42 2.4 Psychological predicates ……………………………………………………….. 46 2.4.1 Psych verbs ………………………………………………………………. -

Notes on Complete Consonantal Assimilations. PUB DATE Apr 73 NOTE 11P
DOCUMENT RESUME ED 127 777 FL 006 759 AUTHOR Hutcheson, James W. TITLE Notes on Complete Consonantal Assimilations. PUB DATE Apr 73 NOTE 11p. JOURNAL CIT Working Papers in Linguistics; n14 p58-64 Apr 1973 EDRS PRICE MF-$0.83 HC-$1.67 Plus Postage. DESCRIPTORS Arabic; *Articulation (Speech); Consonants; Finnish; Generative Phonology; Latin; *Linguistic Theory; *Phonological Units; *Phonology; Suprasegmentals; Synchronic Linguistics; Vowels; Yakut IDENTIFIERS Assimilation (Language); Sandhi ABSTRACT This paper is one of a number of studies within the conceptual framevork of natEral phonology, according to which phonological processes are of two kinds, context-free aril context-sensitive. Context-free changes can be explained by the character of the sounds themselves; context-sensitive processesare explained largely by the function of the actual processes and by the character of the sounds affected by them. This paper investigates the operation of complete consonantal assimilations within this framework. Complete assimilation results in the complete identity of the two sounds involved. Evidence from English casual speech is offered supporting the principle claiming that complete assimilations normally occur only when the segments involved are already very similar. Sandhi phenomena in Arabic and Yakut are shown to support this principle. Latin assimilations and Finnish consonant gradation are considered. The following points are emphasized:(1) Complete assimilations normally affect sounds already very similar; ti2) If relatively different sounds assimilate completely, so will less different sounds - assimilations operate hierarchically; (3) Nonphonological conditions can play a role in triggering assimilatory processes.(CHK) *********************************************************************** Documents acquired by ERIC include many informal unpublished * materials not available from other sources. ERIC makes every effort * * to obtain the best copy available. -

Phonotactics on the Web 487
PHONOTACTICS ON THE WEB 487 APPENDIX Table A1 International Phonetic Alphabet (IPA) and Computer-Readable “Klattese” Transcription Equivalents IPAKlattese IPA Klattese Stops Syllabic Consonants p p n N t t m M k k l L b b d d Glides and Semivowels g l l ɹ r Affricates w w tʃ C j y d J Vowels Sibilant Fricatives i i s s I ʃ S ε E z z e e Z @ Nonsibilant Fricatives ɑ a ɑu f f W θ a Y T v v ^ ð ɔ c D o h h O o o Nasals υ U n n u u m m R ŋ G ə x | X Klattese Transcription Conventions Repeated phonemes. The only situation in which a phoneme is repeated is in a compound word. For exam- ple, the word homemade is transcribed in Klattese as /hommed/. All other words with two successive phonemes that are the same just have a single segment. For example, shrilly would be transcribed in Klattese as /SrIli/. X/R alternation. /X/ appears only in unstressed syllables, and /R/ appears only in stressed syllables. Schwas. There are four schwas: /x/, /|/, /X/, and unstressed /U/. The /U/ in an unstressed syllable is taken as a rounded schwa. Syllabic consonants. The transcriptions are fairly liberal in the use of syllabic consonants. Words ending in -ism are transcribed /IzM/ even though a tiny schwa typically appears in the transition from the /z/ to the /M/. How- ever, /N/ does not appear unless it immediately follows a coronal. In general, /xl/ becomes /L/ unless it occurs be- fore a stressed vowel. -
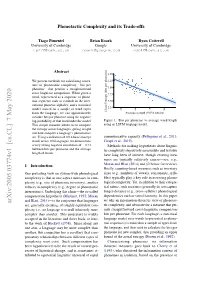
Phonotactic Complexity and Its Trade-Offs
Phonotactic Complexity and its Trade-offs Tiago Pimentel Brian Roark Ryan Cotterell University of Cambridge Google University of Cambridge [email protected] [email protected] [email protected] Abstract 3.50 We present methods for calculating a mea- 3.25 sure of phonotactic complexity—bits per phoneme—that permits a straightforward 3.00 cross-linguistic comparison. When given a 2.75 word, represented as a sequence of phone- mic segments such as symbols in the inter- 2.50 national phonetic alphabet, and a statistical 2.25 model trained on a sample of word types 5 6 7 8 from the language, we can approximately Cross Entropy (bits per phoneme) Average Length (# IPA tokens) measure bits per phoneme using the negative log-probability of that word under the model. Figure 1: Bits-per-phoneme vs average word length This simple measure allows us to compare using an LSTM language model. the entropy across languages, giving insight into how complex a language’s phonotactics are. Using a collection of 1016 basic concept communicative capacity (Pellegrino et al., 2011; words across 106 languages, we demonstrate Coupé et al., 2019). a very strong negative correlation of −0:74 Methods for making hypotheses about linguis- between bits per phoneme and the average tic complexity objectively measurable and testable length of words. have long been of interest, though existing mea- sures are typically relatively coarse—see, e.g., 1 Introduction Moran and Blasi(2014) and §2 below for reviews. Briefly, counting-based measures such as inventory One prevailing view on system-wide phonological sizes (e.g., numbers of vowels, consonants, sylla- complexity is that as one aspect increases in com- bles) typically play a key role in assessing phono- plexity (e.g., size of phonemic inventory), another logical complexity. -

Finnish and Hungarian
The role of linguistics in language teaching: the case of two, less widely taught languages - Finnish and Hungarian Eszter Tarsoly and Riitta-Liisa Valijärvi The School of Slavonic and East European Studies, University College London, London, United Kingdom The School of Slavonic and East European Studies, University College London, Gower Street, London, WC1E 6BT, United Kingdom; [email protected], [email protected] (Received xxx; final version received xxx) This paper discusses the role of various linguistic sub-disciplines in teaching Finnish and Hungarian. We explain the status of Finnish and Hungarian at University College London and in the UK, and present the principle difficulties in learning and teaching these two languages. We also introduce our courses and student profiles. With the support of examples from our own teaching, we argue that a linguistically oriented approach is well suited for less widely used and less taught languages as it enables students to draw comparative and historical parallels, question terminologies and raise their sociolinguistic and pragmatic awareness. A linguistic approach also provides students with skills for further language learning. Keywords: language teaching; less taught languages; LWUTL; Finnish; Hungarian; linguistic terminology; historical linguistics; phonology; typology; cognitive linguistics; contact linguistics; corpus linguistics; sociolinguistics; pragmatics; language and culture. Introduction The purpose of our paper is to explore the role of different sub-disciplines of linguistics in language teaching, in particular, their role in the teaching of less widely used and less taught (LWULT) languages. More specifically, we argue that a linguistic approach to language teaching is well suited for teaching morphologically complex less widely taught languages, such as Hungarian and Finnish, in the UK context.