A High-Performance Parser Architecture for Next Generation
Total Page:16
File Type:pdf, Size:1020Kb

Load more
Recommended publications
-

Architectures for Adaptive Low-Power Embedded Multimedia Systems
Architectures for Adaptive Low-Power Embedded Multimedia Systems zur Erlangung des akademischen Grades eines Doktors der Ingenieurwissenschaften der Fakultät für Informatik Karlsruhe Institute of Technology (KIT) (The cooperation of the Universität Fridericiana zu Karlsruhe (TH) and the national research center of the Helmholtz-Gemeinschaft) genehmigte Dissertation von Muhammad Shafique Tag der mündlichen Prüfung: 31.01.2011 Referent: Prof. Dr.-Ing. Jörg Henkel, Karlsruhe Institute of Technology (KIT), Fakultät für Informatik, Lehrstuhl für Eingebettete Systeme (CES) Korreferent: Prof. Dr. Samarjit Chakraborty, Technische Universität München (TUM), Fakultät für Elektrotechnik und Informationtechnik, Lehrstuhl für Realzeit- Computersysteme (RCS) Muhammad Shafique Adlerstr. 3a 76133 Karlsruhe Hiermit erkläre ich an Eides statt, dass ich die von mir vorgelegte Arbeit selbständig verfasst habe, dass ich die verwendeten Quellen, Internet-Quellen und Hilfsmittel vollständig angegeben habe und dass ich die Stellen der Arbeit – einschließlich Tabellen, Karten und Abbildungen – die anderen Werken oder dem Internet im Wortlaut oder dem Sinn nach entnommen sind, auf jeden Fall unter Angabe der Quelle als Entlehnung kenntlich gemacht habe. ____________________________________ Muhammad Shafique Acknowledgements I would like to present my cordial gratitude to my advisor Prof. Dr. Jörg Henkel for his erudite and invaluable supervision with sustained inspirations and incessant motivation. He guided me to explore the challenging research problems while giving me the complete flexibility, which provided the rationale to unleash my ingenuity and creativity along with an in-depth exploration of various research issues. His encouragement and meticulous feedback wrapped in constructive criticism helped me to keep the impetus and to remain streamlined on the road of research that resulted in the triumphant completion of this work. -

PROFESSIONAL ACTIVITIES – Nam Ling
PROFESSIONAL ACTIVITIES – Nam Ling (1) MAJOR PROFESSIONAL LEADERSHIP POSITIONS: 1. General Co-Chair, 12th International Conference on Ubi-Media Computing (Umedia), Bali, Indonesia, August 6-9, 2019. 2. General Co-Chair, 4th International Symposium on Security and Privacy in Social Networks and Big Data (SocialSec), Santa Clara, California, U.S.A, December 10-11, 2018. 3. General Co-Chair, 11th International Conference on Ubi-Media Computing (Umedia), Nanjing, China, August 22 – 25, 2018. 4. Honorary Co-Chair, 10th International Conference on Ubi-Media Computing and Workshops (Umedia), Pattaya, Thailand, August 1 - 4, 2017. 5. General Co-Chair, 9th International Conference on Ubi-Media Computing (Umedia), Moscow, Russia, August 15 - 17, 2016. 6. General Chair, 2015 IEEE Workshop on Signal Processing Systems (SiPS), Hangzhou, China, October 14 - 16, 2015. 7. General Co-Chair, 8th International Conference on Ubi-Media Computing (Umedia), Colombo, Sri Lanka, August 24 – 25, 2015. 8. General Co-Chair, 7th International Conference on Ubi-Media Computing (Umedia), Ulaanbaatar, Mongolia, July 12 – 14, 2014. 9. General Co-Chair, 2nd International Workshop on Video Coding and Video Processing (VCVP), Shenzhen, China, January 21 – 23, 2014. 10. Technical Program Co-Chair, 2013 IEEE Visual Communications and Image Processing Conference (VCIP), Kuching, Sarawak, Malaysia, November 17 - 20, 2013. 11. General Chair, 2013 IEEE International Conference on Multimedia and Expo (ICME), San Jose, California, USA, July 15 – 19, 2013. (ICME is the flagship conference on multimedia research for the IEEE and is sponsored by four of the largest IEEE societies – Computer, Communications, Signal Processing, and Circuits and Systems.) 12. Technical Program Co-Chair, 2010 Asia-Pacific Signal and Information Processing Association Annual Summit and Conference (APSIPA ASC), Singapore, December 14 – 17, 2010. -

Lillian C. Pentecost Lillian [email protected] (732) 533-9504
Lillian C. Pentecost lillian [email protected] (732) 533-9504 EDUCATION Harvard University Cambridge, MA Ph.D. in Computer Science Projected May 2022 Advisors: David Brooks and Gu-Yeon Wei Harvard University Cambridge, MA S.M. (masters in passing) in Computer Science May 2019 Coursework includes: Advanced Machine Learning, Advanced Computer Architecture, Data Visualization, Seminar in Teaching the History of Science and Technology, Algorithms at the End of the Wire, Critical Pedagogy Seminar Colgate University Hamilton, NY Bachelor of Arts May 2016 Double Major: Computer Science and Physics with High Honors GPAs: Cumulative: 3.95/4.00, Physics: 4.03/4.00, Computer Science: 4.05/4.00 RESEARCH EXPERIENCE Harvard University Cambridge, MA Ph.D. Candidate August 2016 - Present Investigating and enabling the design and optimization of memory systems, including inte- gration of emerging and embedded non-volatile memory technologies and specialized hard- ware for machine learning applications, with an emphasis on understanding resilience and evaluating system and application-level implications of technology design choices. NVIDIA Research Westford, MA Ph.D. Research Intern Summer 2020 Conducted design space exploration of memory architecture and floorplanning choices with intensive analysis of efficient workload mappings for highly-distributed on-chip memory by building upon existing, open-source evaluation frameworks. (Virtual internship conducted from Boston, MA, collaborating with NVIDIA Architecture Research Group.) Microsoft Research Redmond, WA Ph.D. Research Intern Summer 2018 Profiled and analyzed deep neural network performance on a variety of hardware platforms with an emphasis on transformer-based models for translation, in addition to surveying and evaluating the state of available profiling tools across several popular ML frameworks, as part of a collaborative project between Microsoft Research and the Silicon, AI, and Performance group under Azure. -

Newsletter-202009.Pdf
1 September 2020, Vol. 50, No. 9 Online archive: http://www.sigda.org/publications/newsletter 1. SIGDA News From: Xiang Chen <[email protected]> 2. SIGDA Local Chapter News From: Yanzhi Wang <[email protected]> 3. "What is" Column Contributing author: Cong (Callie) Hao <[email protected]> From: Xun Jiao <[email protected]> 4. Paper Submission Deadlines From: Xin Zhao <[email protected]> 5. Upcoming Conferences and Symposia From: Xin Zhao <[email protected]> 6. SIGDA Partner Journal From: Matthew Morrison <[email protected]> From: Deming Chen <[email protected]> 7. Call for Nomination -- ACM TCPS EiC From: Krithi Ramamritham <[email protected]> 8. Technical Activities From: Ying Wang <[email protected]> 9. Notice to Authors Comments from the Editors Dear ACM/SIGDA members, We are excited to present to you the September e-newsletter. We encourage you to invite your students and colleagues to be a part of the SIGDA newsletter. The newsletter covers a wide range of information from the upcoming conferences and hot research topics to technical news and activities from our community. From this month, we add a new column titled "SIGDA Partner Journal" where we will introduce the dynamics of SIGDA related journals. For this month, we are introducing the new editorial board of ACM TODAES and announcing a new partnership between SIGDA and ACM TRETS. Get involved and contact us if you want to contribute an article or announcement. The newsletter is evolving, let us know what you think. Happy reading! Debjit Sinha, Keni Qiu, Editors-in-Chief, SIGDA E-News To renew your ACM SIGDA membership, please visit http://www.acm.org/renew or call between the hours of 8:30am to 4:30pm EST at +1-212-626-0500 (Global), or 1-800-342-6626 (US and Canada). -

Thomas E. Anderson
Thomas E. Anderson November 2015 Personal Born in Orlando, Florida, August 28, 1961. Work Address: Home Address: 646 Allen Center 1201 18th Ave. E. Department of Computer Science and Engineering Seattle, WA 98112 University of Washington (206) 568{0230 Seattle, WA 98112 (206) 543-9348 [email protected] Research Operating systems, cloud computing, computer networks, computer security, local and Interests wide area distributed systems, high performance computer and router architectures, and education software, with a focus on the construction of robust, secure, and efficient computer systems. Education Ph.D. in Computer Science, 1991, University of Washington. Dissertation Title: Operating System Support for High Performance Multiprocessing, supervised by Profs. E.D. Lazowska and H.M. Levy. M.S. in Computer Science, 1989, University of Washington. A.B. cum laude in Philosophy, 1983, Harvard University. Professional Department of Computer Science and Engineering, University of Washington. Experience Warren Francis and Wilma Kolm Bradley Chair of Computer Science and Engineering, 2009 { present. Visiting Professor, Eidgenossische Technische Hoschschule Zurich (ETHZ), 2009. Department of Computer Science and Engineering, University of Washington. Professor, 2001 { 2009. Department of Computer Science and Engineering, University of Washington. Associate Professor, 1997 { 2001. Founder and Interim CEO/CTO, Asta Networks, 2000 - 2001 (on leave from UW). Computer Science Division, University of California, Berkeley. Associate Professor, 1996 { 1997. Computer Science Division, University of California, Berkeley. Assistant Professor, 1991 { 1996. Digital Equipment Corporation Systems Research Center. Research Intern, Fall, 1990. Thomas E. Anderson - 2 - November 2015 Awards USENIX Lifetime Achievement Award, 2014. USENIX Software Tools User Group Award (for PlanetLab), 2014. IEEE Koji Kobayashi Computers and Communications Award, 2012. -

AI Chips: What They Are and Why They Matter
APRIL 2020 AI Chips: What They Are and Why They Matter An AI Chips Reference AUTHORS Saif M. Khan Alexander Mann Table of Contents Introduction and Summary 3 The Laws of Chip Innovation 7 Transistor Shrinkage: Moore’s Law 7 Efficiency and Speed Improvements 8 Increasing Transistor Density Unlocks Improved Designs for Efficiency and Speed 9 Transistor Design is Reaching Fundamental Size Limits 10 The Slowing of Moore’s Law and the Decline of General-Purpose Chips 10 The Economies of Scale of General-Purpose Chips 10 Costs are Increasing Faster than the Semiconductor Market 11 The Semiconductor Industry’s Growth Rate is Unlikely to Increase 14 Chip Improvements as Moore’s Law Slows 15 Transistor Improvements Continue, but are Slowing 16 Improved Transistor Density Enables Specialization 18 The AI Chip Zoo 19 AI Chip Types 20 AI Chip Benchmarks 22 The Value of State-of-the-Art AI Chips 23 The Efficiency of State-of-the-Art AI Chips Translates into Cost-Effectiveness 23 Compute-Intensive AI Algorithms are Bottlenecked by Chip Costs and Speed 26 U.S. and Chinese AI Chips and Implications for National Competitiveness 27 Appendix A: Basics of Semiconductors and Chips 31 Appendix B: How AI Chips Work 33 Parallel Computing 33 Low-Precision Computing 34 Memory Optimization 35 Domain-Specific Languages 36 Appendix C: AI Chip Benchmarking Studies 37 Appendix D: Chip Economics Model 39 Chip Transistor Density, Design Costs, and Energy Costs 40 Foundry, Assembly, Test and Packaging Costs 41 Acknowledgments 44 Center for Security and Emerging Technology | 2 Introduction and Summary Artificial intelligence will play an important role in national and international security in the years to come. -

Tushar Krishna
Tushar Krishna 266 Ferst Drive • School of Electrical and Computer Engineering • Atlanta, GA 30332, USA PHONE (+1) 206 601 6213 • E-MAIL [email protected] • WEB http://tusharkrishna.ece.gatech.edu ……………………...…………………….…………………….…………………….…………………….…………………….………………………………...………… RESEARCH INTERESTS Computer Architecture: multicore, parallel, heterogeneous, spatial, AI/ML accelerators Interconnection Networks: Networks-on-Chip, HPC switches, data-centers, FPGA networks ……………………...…………………….…………………….…………………….…………………….…………………….………………………………...………… EDUCATION Feb 2014 Massachusetts Institute of Technology Ph.D. in Electrical Engineering and Computer Science • Advisor: Li-Shiuan Peh • Committee: Srinivas Devadas and Joel Emer • Thesis: “Enabling Dedicated Single-Cycle Connections Over A Shared Network-on-Chip” Sep 2009 Princeton University M.S.E. in Electrical Engineering • Advisor: Li-Shiuan Peh • Thesis: “Networks-on-Chip with Hybrid Interconnects” Aug 2007 Indian Institute of Technology (IIT), Delhi B.Tech. (Honors) in Electrical Engineering ……………………...…………………….…………………….…………………….…………………….…………………….………………………………...………… PROFESSIONAL APPOINTMENTS Sept’19 -- Georgia Institute of Technology, Atlanta, GA, USA present ON Semiconductor Professor (Endowed Junior Professorship) School of Electrical and Computer Engineering Aug ’15 – Georgia Institute of Technology, Atlanta, GA, USA present Assistant Professor School of Electrical and Computer Engineering. School of Computer Science (Adjunct). Jan ’15 – Jul ‘15 Massachusetts Institute of Technology, SMART Center, -

Uri C. Weiser
Resume: Uri Weiser -1- RESUME January 18, 2010 URI C. WEISER Office: Technion Homes 1: Home 2: Mayer EE Building, office: 1232, Technion 13 Hatchelet 20 Meltchet Technion City, Haifa 32000, Israel Atlit, 30300, Israel Tel-Aviv, 65234, Israel Tel: +972-4-829-4763 04-984-0350 03-566-0660 Cell: +972-54-788-0287 US cell 408-425-9021 Fax: 04-984-0950 Fax: 03-566-9367 [email protected] [email protected] [email protected] [email protected] [email protected] EDUCATION & TITLES ACM Fellow 2005 Distinguish Fellow of the Electrical Engineering Department, Technion 2004 IEEE Fellow 2002 Intel Fellow 1996 Ph.D. Computer Science, University of Utah 1981 M.Sc. Electrical Engineering, Technion 1975 B.Sc. Electrical Engineering, Technion 1970 INDUSTRIAL EXPERIENCE 2010 - present We-Fi (startup – Wi-Fi) Senior Advisors: Strategy and solutions 2008 - present Lucid (startup - graphics) Board of Advisors: Power analysis and advantages, new approach to CMP 2007 - present NovaTrans (startup - devices) Senior Scientific and Technological Advisor 2007 - 2008 Commex-Technologies (startup – x86 chipsets) New X86 Platform approach – I/O Data content aware chipset CTO - Chief Technology Officer 1988 - 2006 Intel Corporation 2001 - 2006 Intel Israel, Corporate Technology Group (CTG) Director, Streaming Media Architecture Laboratory 1999 - 2000 Intel Austin (Texas, US), MicroProcessor Group (MPG) Co-Manager of Texas Development Center 1993 - 1998 Intel Israel, MicroProcessor Group (MPG) Director of Computer Architecture and Planning Department, -

New Faces at CUCS Every Other One and Compute Nearest Neighbor, a Search Their Similarity for Each Pair
NEWSLETTER OF THE DEPARTMENT OF COMPUTER SCIENCE AT COLUMBIA UNIVERSITY VOL.12 NO.1 SPRING 2016 straightforward for small data Rather than searching an entire sets: compare every object to data set for the single most New Faces at CUCS every other one and compute nearest neighbor, a search their similarity for each pair. would go much faster if objects But as the number of objects were pre-grouped according to increases into the billions, com- some shared attribute, making it puting time grows quadratically, easy to zero in on just the small he impact of huge data making the task prohibitively subset of objects most likely to sets is hard to understate, contain the most similar neigh- responsible for advancing expensive, at least in terms of T traditional expectations. bor. The new challenge then almost every scientific and becomes: what attribute shall we technological field, from ma- Alexandr Andoni, a theoretical use to make such a pre-grouping chine learning and personalized computer scientist focused on maximally efficient. The speed-up medicine, to speech recognition developing algorithmic founda- thus gained reverberates across and translation. tions for massive data, sees the a wide range of computational The flip side of the data revolu- need to reframe the issue: “The methods since nearest neigh- tion is that massive data has question today is not ‘what can bors search is ubiquitous and ALEXANDR ANDONI rendered many standard algo- we solve in polynomial time?’ serves as a primitive in higher- level algorithms, particularly in ASSOCIATE PROFESSOR rithms computationally expen- but ‘what is possible in time machine learning. -

A Workload Aware Model of Computational Resource Selection for Big Data Applications
A Workload Aware Model of Computational Resource Selection for Big Data Applications Amit Gupta, Weijia Xu Natalia Ruiz-Juri, Kenneth Perrine Texas Advanced Computing Center Center for Transportation Research University of Texas at Austin University of Texas at Austin fagupta,[email protected] [email protected], [email protected] Abstract—Workload characterization of Big Data applications data and continues to stimulate new advances in hardware has always been a challenging research problem. Big data technologies. However, as both computing infrastructure is applications often have high demands on multiple computing getting more diverse and big data workloads are getting more components in concert, such as storage, memory, network and processors and have evolving performance characteristics along complicated, choosing the right computational resource and with the scale of the workload. To further complicate the prob- efficiently utilizing the state-of-the-art hardware for big data lem, the increasing diversity of hardware technologies available applications becomes an increasingly challenging question. makes side-by-side comparisons hard. Choosing right resources Here, we present a novel workload aware model that can be among a wide array of available systems is a decision that is utilized for computational resource selection for a given big likely to plague both end users and resources providers. In this paper, we propose a workload aware model for the computational data application. infrastructure selection problem for a given application. Our Workload characterization of the big data applications is model considers both features of the workload and features of the an emerging problem, driven by various goals (e.g energy computational infrastructure and predicts expected performance conservation, optimal resource utilization etc) and has brought for a given workload, based on historical performance results several investigation and discussions over the years [7], [36], using Support Vector Machines (SVM). -
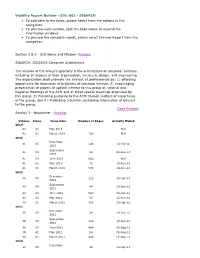
Viability Report Builder - SIG: 002 - SIGARCH to Add Data to the Fields, Please Select from the Options in the Navigation
Viability Report Builder - SIG: 002 - SIGARCH To add data to the fields, please select from the options in the navigation. To preview each section, click the links below to expand the information windows. To preview the complete report, please select Preview Report from the navigation. Section 1 & 2 - SIG Name and Mission- Preview SIGARCH: SIGARCH Computer Architecture The mission of the Group's specialty is the architecture of computer systems, including all aspects of their organization, structure, design, and engineering. The organization shall promote the interest of professionals by: 1) affording opportunity for discussion of problems of common interest. 2) encouraging presentation of papers of special interest to this group at national and Regional Meetings of the ACM and at other special meetings organized by this group. 3) Providing guidance to the ACM Council matters of importance of the group, and 4 ) Publishing a bulletin containing information of interest to the group. Close Preview Section 3 - Newsletter - Preview Volume Issue Issue Date Number of Pages Actually Mailed 2014 42 02 May 2014 N/A 42 01 March 2014 780 N/A 2013 December 41 05 128 10-Jul-14 2013 September 41 04 24 23-Dec-13 2013 41 03 June 2013 688 N/A 41 02 May 2013 72 19-Jun-13 41 01 March 2013 574 19-Jun-13 2012 December 40 05 112 18-Apr-13 2012 September 40 04 48 10-Dec-12 2012 40 03 June 2012 580 09-Oct-12 40 02 May 2012 52 12-Jun-12 40 01 March 2012 480 19-Apr-12 2011 December 39 05 24 18-Jan-12 2011 September 39 04 120 12-Jan-12 2011 39 03 June 2011 484 26-Sep-11 -

Curriculum Vitae
MARY WOLCOTT HALL School of Computing 50 S. Central Campus Drive Salt Lake City, UT 84112 (801) 585-1039 [email protected] EDUCATION Rice University May 1991 Doctor of Philosophy, Computer Science Rice University May 1989 Master of Science, Computer Science Rice University May 1985 Bachelor of Arts, Computer Science and Mathematical Sciences Magna Cum Laude PROFESSIONAL EXPERIENCE 2020- Director School of Computing, University of Utah 2012- Professor School of Computing, University of Utah 2008-2012 Associate Professor School of Computing, University of Utah 2003-2008 Research Associate Professor Computer Science, University of Southern California 1997-2003 Research Assistant Professor Computer Science, University of Southern California 1996-2008 Project Leader USC Information Sciences Institute 1995-1996 Visiting Assistant Professor Computer Science, California Institute of Technology and Senior Research Fellow 1992-1994 Research Scientist Stanford University 1990-1992 Research Scientist Rice University AWARDS 2020 IEEE Fellow 2010 ACM Distinguished Scientist 2015 CRA Leadership in Science Policy Institute 2010-2013 Nvidia Professor Partnership Fellowship 2003-2007 Intel Faculty Fellow 1993-1994 National Science Foundation CISE Postdoctoral Fellowship NATIONAL LEADERSHIP 2020- Member, Computing Research Association Board of Directors 2019 Computing and Communications Foundations Subcommittee Chair, NSF CISE Committee of Visitors 2019- Member, DOE Computational Science Graduate Fellowships Steering Committee 2019- Chair, Institute