Lexical Semantic Analysis in Natural Language Text
Total Page:16
File Type:pdf, Size:1020Kb

Load more
Recommended publications
-

Tip #4 INFINITIVES 不定詞
Tip #4 INFINITIVES 不定詞 Basic Guidelines Infinitive means “without limit”, and is one of a group of three special word forms called “verbals”: Verbal Type Functions Forms 1) infinitive (不定詞) (weak) noun to + verb (to) verb to find help (to) do 2) gerund (動名詞) (strong) noun verb-ing finding 3) participle (分詞) adjective verb-ing verb-ed having verb-ed finding found having found acting acted having acted To conquer unknown areas of science is Taro’s desire. “to conquer” = noun(名詞) and is used as the subject of the sentence The desire to conquer unknown areas of science is Taro’s. “to conquer” = adjective(形容詞) and describes what kind of desire Taro desires to conquer unknown areas of science. “to conquer” = a noun phrase that actually functions to describe “desire” Writers too often misuse the infinitive because they were mistaught, or because the concepts were never learned properly. When thinking of the word “infinitive”, associate the word “infinity” “without limitations”. Infinitive use more commonly communicates uncertainty and doubt—though more psychologically—and is often used in situations in which logic and future possibilities are stressed. The gerund(V-ing 動名詞)—likely mistaught as well—stresses the concept of certainty much more the infinitive, and often refers to things done or finished in the past; thus, things that are known or certain. In short many writers overuse the infinitive in today’s technical, scientific, and even business writing; and use the gerund too little. For numerous reasons dating back to the 1980s, the gerund has become more and more frequently used for stressing facts or factual-like information. -

Old English: 450 - 1150 18 August 2013
Chapter 4 Old English: 450 - 1150 18 August 2013 As discussed in Chapter 1, the English language had its start around 449, when Germanic tribes came to England and settled there. Initially, the native Celtic inhabitants and newcomers presumably lived side-by-side and the Germanic speakers adopted some linguistic features from the original inhabitants. During this period, there is Latin influence as well, mainly through missionaries from Rome and Ireland. The existing evidence about the nature of Old English comes from a collection of texts from a variety of regions: some are preserved on stone and wood monuments, others in manuscript form. The current chapter focusses on the characteristics of Old English. In section 1, we examine some of the written sources in Old English, look at some special spelling symbols, and try to read the runic alphabet that was sometimes used. In section 2, we consider (and listen to) the sounds of Old English. In sections 3, 4, and 5, we discuss some Old English grammar. Its most salient feature is the system of endings on nouns and verbs, i.e. its synthetic nature. Old English vocabulary is very interesting and creative, as section 6 shows. Dialects are discussed briefly in section 7 and the chapter will conclude with several well-known Old English texts to be read and analyzed. 1 Sources and spelling We can learn a great deal about Old English culture by reading Old English recipes, charms, riddles, descriptions of saints’ lives, and epics such as Beowulf. Most remaining texts in Old English are religious, legal, medical, or literary in nature. -

The Old Saxon Language Grammar, Epic Narrative, Linguistic Interference
Irmengard.Rauch The Old Saxon Language Grammar, Epic Narrative, Linguistic Interference PETER LANG New York • San Francisco • Bern • Baltimore Frankfurt am Main • Berlin • Wien • Paris Contents Plate I Ms. C Fit 1: lines 1-18a xvii Plate II Ms. M Fit 2-3: lines 117-179a x vi i i -x ix Plate III Ms. S Fit 7: lines 558b-582a; Fit 8: lines 675-683a; lines 692-698 xx-xxi Plate IV Versus de Poeta & interprete huius codicis xxii Plate V Map of Old Saxon Speech Area x x i i i Introduction xxv Symbols and Abbreviations xli Chapter One Reading an Old Saxon Text; Early Cognitive Decisions; The Verb in the Lexicon; The Strong Verb Dictionary Finder Chart 1. The Old Saxon Text: Narrative Discourse 1 2. The OS Sentence, Grammatical Constituents, Lexicon 2 3. The Verb in the Lexicon 3 3.1 The Fundamental Identifying Form (FIF) of the Verb 3 3.2 Strong, Weak, Modal Auxiliary, Anomalous Verb Types 4 VIII 3.3 Strong Verb ABLAUT 5 3.3.1 The Strong Verb Dictionary Finder Chart 6 3.3.2 Variation in the Seven Strong Verb Sets 12 Chapter Two After the First Search; Diachronic Synchrony and Linguistic Explanation; Linear Syntax: Independent Sentence; Pragmatic Strategies; Nonlinear Micro-syntax: Morphology; Inflection of Verb Present Tense 4. Linguistic Generalization in Diachronic Synchrony 19 5. Completing the Search 23 6. Linear Syntax: The Independent Sentence 24 6.1 The Independent Declarative Sentence: (X)VbSO 24 6.2 The Unmarked Interrogative and the Unmarked Imperative Sentence: (X)VbSO 25 6.3 The Marked Independent Sentence: (X)SVbO and (X)SOVb 26 6.4 Textual and Pragmatic Strategies in Linear Syntax 27 7. -

Minimum of English Grammar
Parameters Morphological inflection carries with it a portmanteau of parameters, each individually shaping the very defining aspects of language typology. For instance, English is roughly considered a ‘weak inflectional language’ given its quite sparse inflectional paradigms (such as verb conjugation, agreement, etc.) Tracing languages throughout history, it is also worth noting that morphological systems tend to become less complex over time. For instance, if one were to exam (mother) Latin, tracing its morphological system over time leading to the Latin-based (daughter) Romance language split (Italian, French, Spanish, etc), one would find that the more recent romance languages involve much less complex morphological systems. The same could be said about Sanskrit (vs. Indian languages), etc. It is fair to say that, at as general rule, languages become less complex in their morphological system as they become more stable (say, in their syntax). Let’s consider two of the more basic morphological parameters below: The Bare Stem and Pro- drop parameters. Bare Stem Parameter. The Bare Stem Parameter is one such parameter that shows up cross-linguistically. It has to do with whether or not a verb stem (in its bare form) can be uttered. For example, English allows bare verb stems to be productive in the language. For instance, bare stems may be used both in finite conjugations (e.g., I/you/we/you/they speak-Ø) (where speak is the bare verb)—with the exception of third person singular/present tense (she speak-s) where a morphological affix{s}is required—as well as in an infinitival capacity (e.g., John can speak-Ø French). -

Inheritance and Inflectional Morphology: Old High German, Latin, Early New High German, and Koine Greek
Inheritance and Inflectional Morphology: Old High German, Latin, Early New High German, and Koine Greek By MaryEllen Anne LeBlanc A dissertation submitted in partial satisfaction of the requirements for the degree of Doctor of Philosophy in German in the Graduate Division of the University of California, Berkeley Committee in charge: Professor Irmengard Rauch, Chair Professor Thomas Shannon Professor Gary Holland Spring 2014 1 Abstract Inheritance and Inflectional Morphology: Old High German, Latin, Early New High German, and Koine Greek by MaryEllen Anne LeBlanc Doctor of Philosophy in German University of California, Berkeley Professor Irmengard Rauch, Chair The inheritance framework originates in the field of artificial intelligence. It was incorporated first into theories of computational linguistics, and in the last two decades, it has been applied to theoretical linguistics. Inheritance refers to the sharing of properties: when a group of items have a common property, each item is said to inherit this property. The properties may be mapped in tree format with nodes arranged vertically. The most general (i.e. the most widely shared, unmarked) properties are found at the highest nodes, and the most specific (marked) information is found at the lowest nodes. Inheritance is particularly useful when applied to inflectional morphology due to its focus on the generalizations within and across paradigms. As such, it serves as an alternative to traditional paradigms, which may simplify the translation process; and provides a visual representation of the structure of the language's morphology. Such a mapping also enables cross- linguistic morphological comparison. In this dissertation, I apply the inheritance framework to the nominal inflectional morphology of Old High German, Latin, Early New High German, and Koine Greek. -

Notes from Donald Hall's on Writing Well Verbs Verbs Act. Verbs Move. Verbs Do. Verbs Strike, Soothe, Grin, Cry, Exasperate
Notes From Donald Hall’s On Writing Well Verbs Verbs act. Verbs move. Verbs do. Verbs strike, soothe, grin, cry, exasperate, decline, fly, hurt, and heal. Verbs make writing go, and they matter more to our language than any other part of speech. Verbs give energy, if we use them with energy. If we don’t use them with energy, they sound dull or flat: Verbs are action. Verbs are motion. Verbs are doing. A single verb is stronger than a strung-out verb-adjective or verb-noun combination. I am cognizant of this situation I know it. Look out for the verbs be / is / are combined with nouns and adjectives. He looked outside and became aware of the fact that it was raining. He looked outside and saw that it was raining. He looked outside. It was raining. Look out for the verbs has / have. We had a meeting. We met. The same advice applies to phrases that use verb forms ending in –ing (present participles). He is clearing his throat . He clears his throat . Watch out for false color in verbs. The 200-foot-high derrick was a black, latticed steel phallus raping the hot, virginal blue sky. The train slammed to a stop in the station. Steam vomited from all apertures. Passengers gushed through the barriers and hurled into the night. And fancy verbs. “Depict” is inferior to “paint” or “draw” or “describe” “Emulate” is fancy for “copy,” “ascertain” for “make sure,” and “endeavor” for “try.” Nouns Nouns are the simplest parts of speech, the words least tricky to use. -

Functional Structure(S), Form and Interpretation
FUNCTIONAL STRUCTURE(S), FORM AND INTERPRETATION The issue of how interpretation results from the form and type of syntactic structures present in language is one which is central and hotly debated in both theoretical and descriptive linguistics. This volume brings together a series of eleven new cutting-edge essays by leading experts in East Asian languages which show how the study of formal structures and functional morphemes in Chinese, Japanese and Korean adds much to our general understanding of the close connections between form and interpretation. This specially commissioned collection will be of interest to linguists of all backgrounds working in the general area of syntax and language change, as well as those with a special interest in Chinese, Japanese and Korean. Yen-hui Audrey Li is Professor of Linguistics and East Asian Languages and Cultures at the University of Southern California. Her research focuses on the comparison of grammatical properties in English, Chinese and other East Asian languages. Recent work has considered issues of order and constituency, scope interaction of quantificational expressions, as well as the distribution, structure and interpretation of different types of nominal expressions and relative constructions. Andrew Simpson is a Senior Lecturer at the School of Oriental and African Studies, the University of London. His research interests centre on the comparative syntax of East and Southeast Asian languages, and his work addresses issues relating to processes of language change, DP-structure, the syntax of question formation and the interaction of syntax with phonology. ROUTLEDGECURZON ASIAN LINGUISTICS SERIES Editor-in-Chief: Walter Bisang, Mainz University Associate Editors: R. -

Synchrony and Diachrony of Conversion in English
Synchrony and Diachrony of Conversion in English Exam. No 6720647 MSc English Language The University of Edinburgh 2010 <Table of Contents> List of Abbreviations and Symbols i List of Figures and Tables ii Abstract iii 1. Introduction 1 2. Types of Conversion in English 3 2.1. Major Types of Conversion 3 2.1.1. Adjective > Noun 4 2.1.2. Noun > Adjecitve 4 2.1.3. Noun > Verb 5 2.1.4. Verb > Noun 5 2.1.5. Adjective > Verb 6 2.2. Minor Types of Conversion 7 2.2.1. Adverb > Adjective 7 2.2.2. Adjective > Adverb 8 2.2.3. Noun > Adverb 8 2.2.4. Adverb > Noun 9 2.2.5. Verb > Preposition 9 2.2.6. Verb > Adjective 10 2.2.7. Other Rare and Special Types of Conversion 10 2.3. Summary 12 3. Standard Questions on Conversion 13 3.1. The Problem of Directionality 13 3.1.1. The History of the Language 14 3.1.2. The Semantic Complexity 14 3.1.3. The Inflectional Behaviour 15 3.1.4. Stress Shift 15 3.1.5. Frequency 17 3.2. Different Views on a Definition of Conversion 17 3.2.1. Zero-Derivation 17 3.2.2. Other Viewpoints 20 3.3. Syntactic Approach of Conversion 21 3.4. Productivity 25 3.5. Summary 26 4. Historical Approaches to Conversion 27 4.1. Stem Formation to Word Formation 27 4.2. Conversion in Old English 28 4.2.1. Evidence of Zero-Morpheme in Old English 28 4.2.2. Conversion in Old English 29 4.3. -

Name(S) ______ENGL 507 Homework Set 3 Fall 2011
Name(s) ________________________________ ENGL 507 Homework Set 3 Fall 2011 The goal in this homework set is for you to realize how inflections (both as suffixes and ablaut changes) worked in Old English so that you can work out how they survive into Modern English. So this set of homework is designed to let you analyze examples of Old English and then apply that analysis. This homework is due in www.turnitin.com by Wednesday October 5 at 5 PM. Again, if you choose to work collaboratively on this you, please indicate who is participating on your turned-in homework. FUN WITH OLD ENGLISH 1. Summarize the rules for Old English stress on words without a prefix. 2. Summarize the rules for Old English stress on words with a prefix. 3. Summarize the rules for Old English stress on compound words. FUN WITH GRAMMATICAL GENDER Examine the following phrases in Old English, analyzing how they are inflected for case, number, and gender: 1. Which of the following is the best indicator of the grammatical gender of an Old English noun? The worst indicator? Meaning (sexual gender) concord of adjective and noun The ending of the noun concord of pronoun and noun 2 2. What is the gender of each of the italicized nouns? Bonus points if you can identify the four strong noun/adjective forms in this list. sēo ċeaster ‘the city’ _______________________________ þæt scip ‘the ship’ _______________________________ Ic seah sum fæt ‘i saw a certain vessel’ ____________________________________ se tūn ‘the town’ _______________________________ sumu lūs ‘a certain louse’ _______________________________ þes blōstm ‘this blossom’ _______________________________ þis lēaf ‘this leaf’ _______________________________ þēos costung ‘this temptation’ _______________________________ Ic seah sume bollan ‘I saw a certain bowl’ _______________________________ Ic seah sumne disc ‘I saw a certain dish’ _______________________________ 3. -

Mock Exam 1: Key
Mock Exam 1: Key Section 3: Grammatical principles (41 points; ca. 20 minutes) 1. Briefly explain the semantic difference between the two forms of the verb beon (2 pts). The “b”-forms of the verb (e.g., beo, bist, biþ) are used to express either futurity or a constant, “always true” state of affairs, like “the sun is a distant star”; the other, verb-initial forms (e.g., eom, eart, is) designate a current but changeable state of affairs, like “the sun is shining,” which might or might not be the case at any given time (Baker 67). 2. In what context would the –aþ verb ending be third-singular present instead of, as you would expect, third-singular plural? What would the third-plural present verb ending of such a verb be? (4 pts.) Class 2 weak verbs, like lufian, end in –aþ in the third-singular present; their third-plural present ending is –iaþ (Baker 70). 3. Briefly explain when you can expect to see the strong forms of adjective and when the weak (4 pts). Adjectives take the weak form if they follow a demonstrative pronoun, possessive adjective, or genitive noun or noun phrase; otherwise they take the strong form (Baker 89). 4. What two words can you expect to see serving as a relative pronoun? What is the key difference between them? (4 points) The two possible words are þe or a form of se/seo/þæt. The former is indeclinable, while the latter agrees in case and number with the role that it serves in the following clause (Baker 47-48). -

Noun Bias': a Structural Approach
University of Pennsylvania Working Papers in Linguistics Volume 16 Issue 1 Proceedings of the 33rd Annual Penn Article 7 Linguistics Colloquium 2010 Examining the `Noun Bias': A Structural Approach Rajdip Dhillon Yale University Follow this and additional works at: https://repository.upenn.edu/pwpl Recommended Citation Dhillon, Rajdip (2010) "Examining the `Noun Bias': A Structural Approach," University of Pennsylvania Working Papers in Linguistics: Vol. 16 : Iss. 1 , Article 7. Available at: https://repository.upenn.edu/pwpl/vol16/iss1/7 This paper is posted at ScholarlyCommons. https://repository.upenn.edu/pwpl/vol16/iss1/7 For more information, please contact [email protected]. Examining the `Noun Bias': A Structural Approach Abstract The current study examines whether a difference exists in the emergence of nouns and verbs in children’s early vocabularies in languages possessing different parameter settings with respect to null arguments. Using data from CHILDES, proportions of noun and verb types are examined in the speech of native English-, Spanish-, and Mandarin-speaking children with ages ranging from 1;7-2;0, 2;1-2;5, and 2;6-2;11 and their respective caregivers. English- and Spanish-speaking children exhibit a noun bias across all age groups, yet consistent results are not obtained for Mandarin-speaking children in the first two age groups, although a verb bias is found in the third. While results for caregivers indicate that the input does differ across language types, their within-language results do not match those for children. The findings indicate that the structure of a language is more dominant than the input in determining the existence of a noun bias in children’s early vocabularies. -
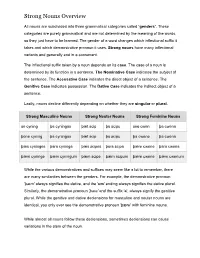
Strong Nouns Overview
Strong Nouns Overview All nouns are subdivided into three grammatical categories called ‘genders’. These categories are purely grammatical and are not determined by the meaning of the words, so they just have to be learned. The gender of a word changes which inflectional suffix it takes and which demonstrative pronoun it uses. Strong nouns have many inflectional variants and generally end in a consonant. The inflectional suffix taken by a noun depends on its case. The case of a noun is determined by its function in a sentence. The Nominative Case indicates the subject of the sentence. The Accusative Case indicates the direct object of a sentence. The Genitive Case indicates possession. The Dative Case indicates the indirect object of a sentence. Lastly, nouns decline differently depending on whether they are singular or plural. Strong Masculine Nouns Strong Neuter Nouns Strong Feminine Nouns se cyning þa cyningas þæt scip þa scipu seo cwen þa cwena þone cyning þa cyningas þæt scip þa scipu þa cwene þa cwena þæs cyninges þara cyninga þæs scipes þara scipa þære cwene þara cwena þæm cyninge þæm cyningum þæm scipe þæm scipum þære cwene þæm cwenum While the various demonstratives and suffixes may seem like a lot to remember, there are many similarities between the genders. For example, the demonstrative pronoun 'þæm' always signifies the dative, and the 'um' ending always signifies the dative plural. Similarly, the demonstrative pronoun 'þara' and the suffix 'a', always signify the genitive plural. While the genitive and dative declensions for masculine and neuter nouns are identical, you only ever see the demonstrative pronoun 'þære' with feminine nouns.