Nonparametric Statistics Math 218, Mathematical Statistics
Total Page:16
File Type:pdf, Size:1020Kb

Load more
Recommended publications
-

Mathematical Statistics
Mathematical Statistics MAS 713 Chapter 1.2 Previous subchapter 1 What is statistics ? 2 The statistical process 3 Population and samples 4 Random sampling Questions? Mathematical Statistics (MAS713) Ariel Neufeld 2 / 70 This subchapter Descriptive Statistics 1.2.1 Introduction 1.2.2 Types of variables 1.2.3 Graphical representations 1.2.4 Descriptive measures Mathematical Statistics (MAS713) Ariel Neufeld 3 / 70 1.2 Descriptive Statistics 1.2.1 Introduction Introduction As we said, statistics is the art of learning from data However, statistical data, obtained from surveys, experiments, or any series of measurements, are often so numerous that they are virtually useless unless they are condensed ; data should be presented in ways that facilitate their interpretation and subsequent analysis Naturally enough, the aspect of statistics which deals with organising, describing and summarising data is called descriptive statistics Mathematical Statistics (MAS713) Ariel Neufeld 4 / 70 1.2 Descriptive Statistics 1.2.2 Types of variables Types of variables Mathematical Statistics (MAS713) Ariel Neufeld 5 / 70 1.2 Descriptive Statistics 1.2.2 Types of variables Types of variables The range of available descriptive tools for a given data set depends on the type of the considered variable There are essentially two types of variables : 1 categorical (or qualitative) variables : take a value that is one of several possible categories (no numerical meaning) Ex. : gender, hair color, field of study, political affiliation, status, ... 2 numerical (or quantitative) -

Nonparametric Statistics for Social and Behavioral Sciences
Statistics Incorporating a hands-on approach, Nonparametric Statistics for Social SOCIAL AND BEHAVIORAL SCIENCES and Behavioral Sciences presents the concepts, principles, and methods NONPARAMETRIC STATISTICS FOR used in performing many nonparametric procedures. It also demonstrates practical applications of the most common nonparametric procedures using IBM’s SPSS software. Emphasizing sound research designs, appropriate statistical analyses, and NONPARAMETRIC accurate interpretations of results, the text: • Explains a conceptual framework for each statistical procedure STATISTICS FOR • Presents examples of relevant research problems, associated research questions, and hypotheses that precede each procedure • Details SPSS paths for conducting various analyses SOCIAL AND • Discusses the interpretations of statistical results and conclusions of the research BEHAVIORAL With minimal coverage of formulas, the book takes a nonmathematical ap- proach to nonparametric data analysis procedures and shows you how they are used in research contexts. Each chapter includes examples, exercises, SCIENCES and SPSS screen shots illustrating steps of the statistical procedures and re- sulting output. About the Author Dr. M. Kraska-Miller is a Mildred Cheshire Fraley Distinguished Professor of Research and Statistics in the Department of Educational Foundations, Leadership, and Technology at Auburn University, where she is also the Interim Director of Research for the Center for Disability Research and Service. Dr. Kraska-Miller is the author of four books on teaching and communications. She has published numerous articles in national and international refereed journals. Her research interests include statistical modeling and applications KRASKA-MILLER of statistics to theoretical concepts, such as motivation; satisfaction in jobs, services, income, and other areas; and needs assessments particularly applicable to special populations. -

This History of Modern Mathematical Statistics Retraces Their Development
BOOK REVIEWS GORROOCHURN Prakash, 2016, Classic Topics on the History of Modern Mathematical Statistics: From Laplace to More Recent Times, Hoboken, NJ, John Wiley & Sons, Inc., 754 p. This history of modern mathematical statistics retraces their development from the “Laplacean revolution,” as the author so rightly calls it (though the beginnings are to be found in Bayes’ 1763 essay(1)), through the mid-twentieth century and Fisher’s major contribution. Up to the nineteenth century the book covers the same ground as Stigler’s history of statistics(2), though with notable differences (see infra). It then discusses developments through the first half of the twentieth century: Fisher’s synthesis but also the renewal of Bayesian methods, which implied a return to Laplace. Part I offers an in-depth, chronological account of Laplace’s approach to probability, with all the mathematical detail and deductions he drew from it. It begins with his first innovative articles and concludes with his philosophical synthesis showing that all fields of human knowledge are connected to the theory of probabilities. Here Gorrouchurn raises a problem that Stigler does not, that of induction (pp. 102-113), a notion that gives us a better understanding of probability according to Laplace. The term induction has two meanings, the first put forward by Bacon(3) in 1620, the second by Hume(4) in 1748. Gorroochurn discusses only the second. For Bacon, induction meant discovering the principles of a system by studying its properties through observation and experimentation. For Hume, induction was mere enumeration and could not lead to certainty. Laplace followed Bacon: “The surest method which can guide us in the search for truth, consists in rising by induction from phenomena to laws and from laws to forces”(5). -

Applied Time Series Analysis
Applied Time Series Analysis SS 2018 February 12, 2018 Dr. Marcel Dettling Institute for Data Analysis and Process Design Zurich University of Applied Sciences CH-8401 Winterthur Table of Contents 1 INTRODUCTION 1 1.1 PURPOSE 1 1.2 EXAMPLES 2 1.3 GOALS IN TIME SERIES ANALYSIS 8 2 MATHEMATICAL CONCEPTS 11 2.1 DEFINITION OF A TIME SERIES 11 2.2 STATIONARITY 11 2.3 TESTING STATIONARITY 13 3 TIME SERIES IN R 15 3.1 TIME SERIES CLASSES 15 3.2 DATES AND TIMES IN R 17 3.3 DATA IMPORT 21 4 DESCRIPTIVE ANALYSIS 23 4.1 VISUALIZATION 23 4.2 TRANSFORMATIONS 26 4.3 DECOMPOSITION 29 4.4 AUTOCORRELATION 50 4.5 PARTIAL AUTOCORRELATION 66 5 STATIONARY TIME SERIES MODELS 69 5.1 WHITE NOISE 69 5.2 ESTIMATING THE CONDITIONAL MEAN 70 5.3 AUTOREGRESSIVE MODELS 71 5.4 MOVING AVERAGE MODELS 85 5.5 ARMA(P,Q) MODELS 93 6 SARIMA AND GARCH MODELS 99 6.1 ARIMA MODELS 99 6.2 SARIMA MODELS 105 6.3 ARCH/GARCH MODELS 109 7 TIME SERIES REGRESSION 113 7.1 WHAT IS THE PROBLEM? 113 7.2 FINDING CORRELATED ERRORS 117 7.3 COCHRANE‐ORCUTT METHOD 124 7.4 GENERALIZED LEAST SQUARES 125 7.5 MISSING PREDICTOR VARIABLES 131 8 FORECASTING 137 8.1 STATIONARY TIME SERIES 138 8.2 SERIES WITH TREND AND SEASON 145 8.3 EXPONENTIAL SMOOTHING 152 9 MULTIVARIATE TIME SERIES ANALYSIS 161 9.1 PRACTICAL EXAMPLE 161 9.2 CROSS CORRELATION 165 9.3 PREWHITENING 168 9.4 TRANSFER FUNCTION MODELS 170 10 SPECTRAL ANALYSIS 175 10.1 DECOMPOSING IN THE FREQUENCY DOMAIN 175 10.2 THE SPECTRUM 179 10.3 REAL WORLD EXAMPLE 186 11 STATE SPACE MODELS 187 11.1 STATE SPACE FORMULATION 187 11.2 AR PROCESSES WITH MEASUREMENT NOISE 188 11.3 DYNAMIC LINEAR MODELS 191 ATSA 1 Introduction 1 Introduction 1.1 Purpose Time series data, i.e. -

Mathematical Statistics the Sample Distribution of the Median
Course Notes for Math 162: Mathematical Statistics The Sample Distribution of the Median Adam Merberg and Steven J. Miller February 15, 2008 Abstract We begin by introducing the concept of order statistics and ¯nding the density of the rth order statistic of a sample. We then consider the special case of the density of the median and provide some examples. We conclude with some appendices that describe some of the techniques and background used. Contents 1 Order Statistics 1 2 The Sample Distribution of the Median 2 3 Examples and Exercises 4 A The Multinomial Distribution 5 B Big-Oh Notation 6 C Proof That With High Probability jX~ ¡ ¹~j is Small 6 D Stirling's Approximation Formula for n! 7 E Review of the exponential function 7 1 Order Statistics Suppose that the random variables X1;X2;:::;Xn constitute a sample of size n from an in¯nite population with continuous density. Often it will be useful to reorder these random variables from smallest to largest. In reordering the variables, we will also rename them so that Y1 is a random variable whose value is the smallest of the Xi, Y2 is the next smallest, and th so on, with Yn the largest of the Xi. Yr is called the r order statistic of the sample. In considering order statistics, it is naturally convenient to know their probability density. We derive an expression for the distribution of the rth order statistic as in [MM]. Theorem 1.1. For a random sample of size n from an in¯nite population having values x and density f(x), the probability th density of the r order statistic Yr is given by ·Z ¸ ·Z ¸ n! yr r¡1 1 n¡r gr(yr) = f(x) dx f(yr) f(x) dx : (1.1) (r ¡ 1)!(n ¡ r)! ¡1 yr Proof. -

Nonparametric Estimation by Convex Programming
The Annals of Statistics 2009, Vol. 37, No. 5A, 2278–2300 DOI: 10.1214/08-AOS654 c Institute of Mathematical Statistics, 2009 NONPARAMETRIC ESTIMATION BY CONVEX PROGRAMMING By Anatoli B. Juditsky and Arkadi S. Nemirovski1 Universit´eGrenoble I and Georgia Institute of Technology The problem we concentrate on is as follows: given (1) a convex compact set X in Rn, an affine mapping x 7→ A(x), a parametric family {pµ(·)} of probability densities and (2) N i.i.d. observations of the random variable ω, distributed with the density pA(x)(·) for some (unknown) x ∈ X, estimate the value gT x of a given linear form at x. For several families {pµ(·)} with no additional assumptions on X and A, we develop computationally efficient estimation routines which are minimax optimal, within an absolute constant factor. We then apply these routines to recovering x itself in the Euclidean norm. 1. Introduction. The problem we are interested in is essentially as fol- lows: suppose that we are given a convex compact set X in Rn, an affine mapping x A(x) and a parametric family pµ( ) of probability densities. Suppose that7→N i.i.d. observations of the random{ variable· } ω, distributed with the density p ( ) for some (unknown) x X, are available. Our objective A(x) · ∈ is to estimate the value gT x of a given linear form at x. In nonparametric statistics, there exists an immense literature on various versions of this problem (see, e.g., [10, 11, 12, 13, 15, 17, 18, 21, 22, 23, 24, 25, 26, 27, 28] and the references therein). -

Repeated-Measures ANOVA & Friedman Test Using STATCAL
Repeated-Measures ANOVA & Friedman Test Using STATCAL (R) & SPSS Prana Ugiana Gio Download STATCAL in www.statcal.com i CONTENT 1.1 Example of Case 1.2 Explanation of Some Book About Repeated-Measures ANOVA 1.3 Repeated-Measures ANOVA & Friedman Test 1.4 Normality Assumption and Assumption of Equality of Variances (Sphericity) 1.5 Descriptive Statistics Based On SPSS dan STATCAL (R) 1.6 Normality Assumption Test Using Kolmogorov-Smirnov Test Based on SPSS & STATCAL (R) 1.7 Assumption Test of Equality of Variances Using Mauchly Test Based on SPSS & STATCAL (R) 1.8 Repeated-Measures ANOVA Based on SPSS & STATCAL (R) 1.9 Multiple Comparison Test Using Boferroni Test Based on SPSS & STATCAL (R) 1.10 Friedman Test Based on SPSS & STATCAL (R) 1.11 Multiple Comparison Test Using Wilcoxon Test Based on SPSS & STATCAL (R) ii 1.1 Example of Case For example given data of weight of 11 persons before and after consuming medicine of diet for one week, two weeks, three weeks and four week (Table 1.1.1). Tabel 1.1.1 Data of Weight of 11 Persons Weight Name Before One Week Two Weeks Three Weeks Four Weeks A 89.43 85.54 80.45 78.65 75.45 B 85.33 82.34 79.43 76.55 71.35 C 90.86 87.54 85.45 80.54 76.53 D 91.53 87.43 83.43 80.44 77.64 E 90.43 84.45 81.34 78.64 75.43 F 90.52 86.54 85.47 81.44 78.64 G 87.44 83.34 80.54 78.43 77.43 H 89.53 86.45 84.54 81.35 78.43 I 91.34 88.78 85.47 82.43 78.76 J 88.64 84.36 80.66 78.65 77.43 K 89.51 85.68 82.68 79.71 76.5 Average 89.51 85.68 82.68 79.71 76.69 Based on Table 1.1.1: The person whose name is A has initial weight 89,43, after consuming medicine of diet for one week 85,54, two weeks 80,45, three weeks 78,65 and four weeks 75,45. -
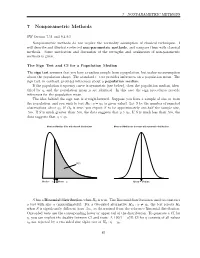
7 Nonparametric Methods
7 NONPARAMETRIC METHODS 7 Nonparametric Methods SW Section 7.11 and 9.4-9.5 Nonparametric methods do not require the normality assumption of classical techniques. I will describe and illustrate selected non-parametric methods, and compare them with classical methods. Some motivation and discussion of the strengths and weaknesses of non-parametric methods is given. The Sign Test and CI for a Population Median The sign test assumes that you have a random sample from a population, but makes no assumption about the population shape. The standard t−test provides inferences on a population mean. The sign test, in contrast, provides inferences about a population median. If the population frequency curve is symmetric (see below), then the population median, iden- tified by η, and the population mean µ are identical. In this case the sign procedures provide inferences for the population mean. The idea behind the sign test is straightforward. Suppose you have a sample of size m from the population, and you wish to test H0 : η = η0 (a given value). Let S be the number of sampled observations above η0. If H0 is true, you expect S to be approximately one-half the sample size, .5m. If S is much greater than .5m, the data suggests that η > η0. If S is much less than .5m, the data suggests that η < η0. Mean and Median differ with skewed distributions Mean and Median are the same with symmetric distributions 50% Median = η Mean = µ Mean = Median S has a Binomial distribution when H0 is true. The Binomial distribution is used to construct a test with size α (approximately). -

Nonparametric Multivariate Kurtosis and Tailweight Measures
Nonparametric Multivariate Kurtosis and Tailweight Measures Jin Wang1 Northern Arizona University and Robert Serfling2 University of Texas at Dallas November 2004 – final preprint version, to appear in Journal of Nonparametric Statistics, 2005 1Department of Mathematics and Statistics, Northern Arizona University, Flagstaff, Arizona 86011-5717, USA. Email: [email protected]. 2Department of Mathematical Sciences, University of Texas at Dallas, Richardson, Texas 75083- 0688, USA. Email: [email protected]. Website: www.utdallas.edu/∼serfling. Support by NSF Grant DMS-0103698 is gratefully acknowledged. Abstract For nonparametric exploration or description of a distribution, the treatment of location, spread, symmetry and skewness is followed by characterization of kurtosis. Classical moment- based kurtosis measures the dispersion of a distribution about its “shoulders”. Here we con- sider quantile-based kurtosis measures. These are robust, are defined more widely, and dis- criminate better among shapes. A univariate quantile-based kurtosis measure of Groeneveld and Meeden (1984) is extended to the multivariate case by representing it as a transform of a dispersion functional. A family of such kurtosis measures defined for a given distribution and taken together comprises a real-valued “kurtosis functional”, which has intuitive appeal as a convenient two-dimensional curve for description of the kurtosis of the distribution. Several multivariate distributions in any dimension may thus be compared with respect to their kurtosis in a single two-dimensional plot. Important properties of the new multivariate kurtosis measures are established. For example, for elliptically symmetric distributions, this measure determines the distribution within affine equivalence. Related tailweight measures, influence curves, and asymptotic behavior of sample versions are also discussed. -

9 Blocked Designs
9 Blocked Designs 9.1 Friedman's Test 9.1.1 Application 1: Randomized Complete Block Designs • Assume there are k treatments of interest in an experiment. In Section 8, we considered the k-sample Extension of the Median Test and the Kruskal-Wallis Test to test for any differences in the k treatment medians. • Suppose the experimenter is still concerned with studying the effects of a single factor on a response of interest, but variability from another factor that is not of interest is expected. { Suppose a researcher wants to study the effect of 4 fertilizers on the yield of cotton. The researcher also knows that the soil conditions at the 8 areas for performing an experiment are highly variable. Thus, the researcher wants to design an experiment to detect any differences among the 4 fertilizers on the cotton yield in the presence a \nuisance variable" not of interest (the 8 areas). • Because experimental units can vary greatly with respect to physical characteristics that can also influence the response, the responses from experimental units that receive the same treatment can also vary greatly. • If it is not controlled or accounted for in the data analysis, it can can greatly inflate the experimental variability making it difficult to detect real differences among the k treatments of interest (large Type II error). • If this source of variability can be separated from the treatment effects and the random experimental error, then the sensitivity of the experiment to detect real differences between treatments in increased (i.e., lower the Type II error). • Therefore, the goal is to choose an experimental design in which it is possible to control the effects of a variable not of interest by bringing experimental units that are similar into a group called a \block". -

1 Exercise 8: an Introduction to Descriptive and Nonparametric
1 Exercise 8: An Introduction to Descriptive and Nonparametric Statistics Elizabeth M. Jakob and Marta J. Hersek Goals of this lab 1. To understand why statistics are used 2. To become familiar with descriptive statistics 1. To become familiar with nonparametric statistical tests, how to conduct them, and how to choose among them 2. To apply this knowledge to sample research questions Background If we are very fortunate, our experiments yield perfect data: all the animals in one treatment group behave one way, and all the animals in another treatment group behave another way. Usually our results are not so clear. In addition, even if we do get results that seem definitive, there is always a possibility that they are a result of chance. Statistics enable us to objectively evaluate our results. Descriptive statistics are useful for exploring, summarizing, and presenting data. Inferential statistics are used for interpreting data and drawing conclusions about our hypotheses. Descriptive statistics include the mean (average of all of the observations; see Table 8.1), mode (most frequent data class), and median (middle value in an ordered set of data). The variance, standard deviation, and standard error are measures of deviation from the mean (see Table 8.1). These statistics can be used to explore your data before going on to inferential statistics, when appropriate. In hypothesis testing, a variety of statistical tests can be used to determine if the data best fit our null hypothesis (a statement of no difference) or an alternative hypothesis. More specifically, we attempt to reject one of these hypotheses. -

Nonparametric Analogues of Analysis of Variance
*\ NONPARAMETRIC ANALOGUES OF ANALYSIS OF VARIANCE by °\\4 RONALD K. LOHRDING B. A., Southwestern College, 1963 A MASTER'S REPORT submitted in partial fulfillment of the requirements for the degree MASTER OF SCIENCE Department of Statistics and Statistical Laboratory KANSAS STATE UNIVERSITY Manhattan, Kansas 1966 Approved by: ' UKC )x 0-i Major PrProfessor L IVoJL CONTENTS 1. INTRODUCTION 1 2. COMPLETELY RANDOMIZED DESIGN 4 2. 1. The Kruskal-Wallis One-way Analysis of Variance by Ranks 4 2. 2. Mosteller's k-Sample Slippage Test 7 2.3. Conover's k-Sample Slippage Test 8 2.4. A k-Sample Kolmogorov-Smirnov Test 11 2 2. 5. The Contingency x Test 13 3. RANDOMIZED COMPLETE BLOCK 14 3. 1. Cochran Q Test 15 3.2. Friedman's Two-way Analysis of Variance by Ranks . 16 4. PROCEDURES WHICH GENERALIZE TO SEVERAL DESIGNS . 17 4.1. Mood's Median Test 18 4.2. Wilson's Median Test 21 4.3. The Randomized Rank-Sum Test 27 4.4. Rank Test for Paired-Comparison Experiments ... 30 5. BALANCED INCOMPLETE BLOCK 33 5. 1. Bradley's Rank Analysis of Incomplete Block Designs 33 5.2. Durbin's Rank Analysis of Incomplete Block Designs 40 6. A 2x2 FACTORIAL EXPERIMENT 44 7. PARTIALLY BALANCED INCOMPLETE BLOCK 47 OTHER RELATED TESTS 50 ACKNOWLEDGEMENTS 53 REFERENCES 54 NONPARAMETRIC ANALOGUES OF ANALYSIS OF VARIANCE 1. Introduction J. V. Bradley (I960) proposes that the history of statistics can be divided into four major stages. The first or one parameter stage was when statistics were merely thought of as averages or in some instances ratios.