Harvard Law Library Project: Librarycloud: an Open Metadata Server
Total Page:16
File Type:pdf, Size:1020Kb

Load more
Recommended publications
-

Seeking a Forgotten History
HARVARD AND SLAVERY Seeking a Forgotten History by Sven Beckert, Katherine Stevens and the students of the Harvard and Slavery Research Seminar HARVARD AND SLAVERY Seeking a Forgotten History by Sven Beckert, Katherine Stevens and the students of the Harvard and Slavery Research Seminar About the Authors Sven Beckert is Laird Bell Professor of history Katherine Stevens is a graduate student in at Harvard University and author of the forth- the History of American Civilization Program coming The Empire of Cotton: A Global History. at Harvard studying the history of the spread of slavery and changes to the environment in the antebellum U.S. South. © 2011 Sven Beckert and Katherine Stevens Cover Image: “Memorial Hall” PHOTOGRAPH BY KARTHIK DONDETI, GRADUATE SCHOOL OF DESIGN, HARVARD UNIVERSITY 2 Harvard & Slavery introducTION n the fall of 2007, four Harvard undergradu- surprising: Harvard presidents who brought slaves ate students came together in a seminar room to live with them on campus, significant endow- Ito solve a local but nonetheless significant ments drawn from the exploitation of slave labor, historical mystery: to research the historical con- Harvard’s administration and most of its faculty nections between Harvard University and slavery. favoring the suppression of public debates on Inspired by Ruth Simmon’s path-breaking work slavery. A quest that began with fears of finding at Brown University, the seminar’s goal was nothing ended with a new question —how was it to gain a better understanding of the history of that the university had failed for so long to engage the institution in which we were learning and with this elephantine aspect of its history? teaching, and to bring closer to home one of the The following pages will summarize some of greatest issues of American history: slavery. -

Harvard Library Bulletin</Em>
The Kentucky Review Volume 8 | Number 2 Article 5 Summer 1988 Keyes Metcalf and the Founding of The Harvard Library Bulletin Dennis Carrigan University of Kentucky, [email protected] Follow this and additional works at: https://uknowledge.uky.edu/kentucky-review Part of the Library and Information Science Commons Right click to open a feedback form in a new tab to let us know how this document benefits you. Recommended Citation Carrigan, Dennis (1988) "Keyes Metcalf and the Founding of The Harvard Library Bulletin," The Kentucky Review: Vol. 8 : No. 2 , Article 5. Available at: https://uknowledge.uky.edu/kentucky-review/vol8/iss2/5 This Article is brought to you for free and open access by the University of Kentucky Libraries at UKnowledge. It has been accepted for inclusion in The Kentucky Review by an authorized editor of UKnowledge. For more information, please contact [email protected]. Keyes Metcalf and the Founding of The Harvard Library Bulletin Dennis Carrigan In Random Recollections of an Anachronism, the first volume of his autobiography, Keyes Metcalf has told how he came to head the Harvard Library. In 1913 he had joined the New York Public Library, and had expected to work there until retirement. One day early in 1936, however, he was summoned to the office of his superior, Harry Miller Lydenberg, and there introduced to James Bryant Conant, the President of Harvard, who was in New York to discuss with Mr. Lydenberg a candidate to be Librarian of Harvard College, a position that was expected to lead to that of Director of the University Library. -

Reorganization at the Harvard Law School Library (A)
Reorganization at the Harvard Law School Library (A) As a new and self-proclaimed “rookie” library leader, John Palfrey reflected on recent reorganization activities at the Harvard Law School Library with equal measures of pride and uncertainty. Had the process really gone as well as many thought? What had been done right? Could a different approach have been taken that would have produced less fear, trepidation, and anxiety among library staff? How might his experience help other library leaders struggling with how to best meet the challenges of organizational change and library transformation? Harvard Law School Established in 1817, Harvard Law School (HLS) is the oldest continuously operating law school in the United States. Several leading national publications consistently ranked HLS among the top three law schools in the country. Historically, HLS had admitted about ten percent of its applicants annually and boasted such notable alumni as United States President Barack Obama and, in 2011, six of the nine sitting Justices of the United States Supreme Court. During the 1980’s and 1990’s, HLS had also been known for its politically contentious faculty. During that period, a divide between conservative and liberal faculty members led to very public squabbles about faculty appointments, tenure cases, and policy decisions. Deadlocked by bitter ideological infighting, the faculty had gone years without a single new hire. Newer faculty levied charges of political incorrectness against older faculty, particularly regarding minority and feminist issues. Unrest then spread to the student body, when, in 1992, nine students occupied the office of then-Dean Robert Clark for a twenty-five hour sit-in protesting a lack of black and female faculty. -

The Separate Undergraduate Library
ELIZABETH MILLS The Separate Undergraduate Library A new phenomenon came into being in 1949 with the opening of the first separate library for undergraduates in a university. Many have now been built, and more are planned. This paper discusses some of the thinking that preceded their development. It analyzes three of them—Lamont, Michigan, and UCLA—in some detail, and speculates as to their future. OVER THE PAST eighteen years, a num- in enrollment of students, at both the ber of large universities in the United graduate and undergraduate level, has States have established separate libraries caused critical crowding in libraries and for undergraduate students. Either a brought an urgent and imperative need new separate building has been con- for more space. Steadily growing re- structed specifically for the purpose of search collections have added their pres- serving the undergraduates or an old sure for needed room and stack space. building has been converted into a dis- The establishment of research centers crete library to provide a special collec- and graduate schools has brought in- tion, special facilities, and services spe- creasing demands on library facilities cifically oriented to the undergraduate from faculties and scholars. These fac- students. Of late, more and more uni- tors—the need for improved service to versities appear to be following this pat- undergraduates and critical space prob- tern so that it would seem that a defi- lems—have worked together to bring nite trend among academic institutions about the development of the separate has been started. undergraduate library. This development appears to be the This paper proposes to offer a study of result of several concurrent factors. -

Harvard Library Bulletin, Volume 6.2)
Harvard Library bibliography: Supplement (Harvard Library Bulletin, Volume 6.2) The Harvard community has made this article openly available. Please share how this access benefits you. Your story matters Citation Carpenter, Kenneth E. 1996. Harvard Library bibliography: Supplement (Harvard Library Bulletin, Volume 6.2). Harvard Library Bulletin 6 (2), Summer 1995: 57-64. Citable link http://nrs.harvard.edu/urn-3:HUL.InstRepos:42665395 Terms of Use This article was downloaded from Harvard University’s DASH repository, and is made available under the terms and conditions applicable to Other Posted Material, as set forth at http:// nrs.harvard.edu/urn-3:HUL.InstRepos:dash.current.terms-of- use#LAA 57 Harvard Library Bibliography: Supplement his is a list of selected new books and articles of which any unit of the Harvard T University Library is the author, primary editor, publisher, or subject. The list also includes scholarly and professional publications by Library staff. The bibli- ography for 1960-1966 appeared in the Harvard Library Bulletin, 15 (1967), and supplements have appeared in the years following, most recently in Vol. 3 (New Series), No. 4 (Winter 1992-1993). The list below covers publications through mid-1995. Alligood, Elaine. "The Francis A. Countway Library of Medicine: Poised for the Future, Guided by the Past," in Network News, the quarterly publication of the Massachu- setts Health Sciences Library Network (August 1994). (Elaine Alligood was formerly Assistant Director for Marketing in the Countway Library of Medicine.) Altenberger, Alicja and John W. Collins III. "Methods oflnstruction in Management for Libraries and Information Centers" in New Trends in Education and Research in Librarianshipand InformationScience (Poland:Jagiellonian University, 1993), ed. -

Widener Library: Voices from the Stacks"
Introduction to "Widener Library: Voices from the stacks" The Harvard community has made this article openly available. Please share how this access benefits you. Your story matters Citation Carpenter, Kenneth E., and Richard F. Thomas. 1996. Introduction to "Widener Library: Voices from the stacks". Harvard Library Bulletin 6 (3), Fall 1995: 3-6. Citable link http://nrs.harvard.edu/urn-3:HUL.InstRepos:42665397 Terms of Use This article was downloaded from Harvard University’s DASH repository, and is made available under the terms and conditions applicable to Other Posted Material, as set forth at http:// nrs.harvard.edu/urn-3:HUL.InstRepos:dash.current.terms-of- use#LAA 3 Introduction his assemblage of essays grows out of a chance, almost wistful remark by TDirector of the Harvard University Library Sidney Verba: "How does one make Widener Library's importance clear to those who do not already understand it?" Professor Verba made this comment at a meeting of the Faculty of Arts and Sciences Committee on the Library, which he chairs. Then at a subsequent meet- ing he mentioned that one of the committee's members had given a very success- ful talk about the importance of Widener. Those meetings of the Library Committee usually take place in Wadsworth House, and so after the meeting, as we strolled back to Widener, we two, one a professor of classics and one a librarian who edits the HarvardLibrary Bulletin, continued to discuss the desirability and dif- ficulty of communicating Widener's importance to the larger community. To do so for some libraries is much easier. -

Annual Report Academic Year 2014-2015
Annual Report Academic Year 2014-2015 EXECUTIVE SUMMARY Last year’s 2013-2014 Berkman Center Annual Report outlined ideals to guide our work this academic year. Specifically, we sought to continue pioneering teaching and research with new, more sophisticated, and more integrative methodologies and partnerships. In the year that followed, the Center’s portfolio can be viewed in terms of three key areas of increased investment and attention that encompass these same goals. Since 1997, the Berkman Center has catalyzed dozens of projects and initiatives concerning the Internet in three areas of activity: 1) Law and Policy, 2) Education and Public Discourse, and 3) Access to Information. Updates and significant milestones related to each of these areas are described in the following sections of the Executive Summary. In additional to these three focal areas, the Berkman Center has continued to expand its collaboration across institutions and taken a leadership role in building a global research network through collaboration on projects and events. The Center also completed a rigorous revisioning and reimplementation of its organizational processes. Across and within the three areas of activity, platforms, privacy, and public discourse were at the core contexts of many of the Center’s activities in the past year, which were addressed and explored in its scholarship, technical innovations, collaborations, and communications. Platforms include the unowned Internet and World Wide Web itself along with organizations and companies that serve as conduits for online communications. Companies that offer network access (like ISPs) and online services (like cloud storage, email platforms, and social networks), and even government institutions that filter or moderate citizens’ access to content online, play a crucial role in intermediating online communications among individuals connected to the Internet. -

The Berkman Klein Center for Internet & Society
Annual Report Academic Year 2016–2017 Contents I. Part One: Report of Activities .............................................................................................. 3 A. Summary of Academic Year: 2016–2017 ........................................................................ 3 1. Executive Summary ..................................................................................................... 3 2. Research, Scholarship and Project Activities ............................................................... 5 3. Contributions to HLS Teaching Program .....................................................................63 4. Participation of HLS Students in Program Activities ....................................................65 5. Faculty Participation ....................................................................................................65 6. Other Contributions to the HLS Community ................................................................66 7. Law Reform and Advocacy .........................................................................................66 8. Connections to the Profession ....................................................................................67 Research ...........................................................................................................................67 The Future of Digital Privacy ..............................................................................................67 Executive Education: Digital Security for Directors and Senior Executives -

The Blue Hill Meteorological Observatory Library
The Blue Hill Meteorological Observatory Library The Harvard community has made this article openly available. Please share how this access benefits you. Your story matters Citation Brooks, Charles F., and Shirley J. Richardson. 1958. The Blue Hill Meteorological Observatory Library. Harvard Library Bulletin XII (2), Spring 1958: 271-281. Citable link https://nrs.harvard.edu/URN-3:HUL.INSTREPOS:37363804 Terms of Use This article was downloaded from Harvard University’s DASH repository, and is made available under the terms and conditions applicable to Other Posted Material, as set forth at http:// nrs.harvard.edu/urn-3:HUL.InstRepos:dash.current.terms-of- use#LAA - The Blue Hill Meteorological Observatory Library RROTT LA,vRENCE RQTCH (1861~1912), founder and first Director of the Blue I.Jill 1\1cteorologicalObservatory-, ,vas a n1an of fat-reaching vj sion. His in tcrest in meteorology· transcended the in1tncdiutc observational program that led him, in the year of his graduation from 1\1assachusettsInstitute of Technology, J 884, to plan and carry through the erection of the Ob- servatory, on the su1nmit of G·rcat Blue Hill~ i\1ilton, cntirel)T at his o,vn expense. Fro1n the beginning he ~ssembled a library not only of current meteorological publications and ref erenee books but of older ,vorks a.s,veil. Thro11ghout his career as Director 1 until his un- tin1ely death in 1912, his unflagging energy and good ;udgn1ent pro- vided the Observatory ,vith an ever gro,ving collection of first in1 po rt~nce for a11 aspects of n1eteoro I ogy. F rcq ucn t trips abroad and attendance at 311meetings of the International lVIeteorologicalOrgan- ization aif ordcd excel]ent opportunities for the acquisition of signifi- cant material. -
Calendar of Opening Days for New Students
Class of 2020 Calendar of Opening Days for New Students Freshman Dean’s Office fdo.fas.harvard.edu Faculty of Arts and Sciences, Harvard University OPENING DAYS CHECKLIST Required Attend Welcome to the Community on Tuesday, 8/23 Attend meetings with your entryway on Tuesday, 8/23, Wednesday, 8/24, and Thursday, 8/25 Learn about the curriculum at Liberal Education: A User’s Guide on Wednesday, 8/24 Join your Academic Adviser for lunch on Wednesday, 8/24 Learn about sexual assault prevention at Speak About It on Wednesday, 8/24 Learn about Harvard’s Honor Code on Thursday, 8/25 Participate in Conversations with Faculty on the Liberal Arts on Thursday, 8/25 Participate in Community Conversations on Tuesday, 8/30 Hear from President Drew Gilpin Faust and the Deans at Freshman Convocation and be in the photo of the Class of 2020 on Tuesday, 8/30 Complete Online Check-in by Tuesday, 8/30 at 11:59 pm Participate in Extended Orientation (check with your Proctor for dates and times) Get a physical examination (for intercollegiate athletes) on Friday, 9/2 Recommended Check online (placement-info.fas.harvard.edu) for placement exam times and locations, and complete any necessary exams Participate in all academic and advising events Take a Crimson Key tour of campus or Harvard Square Check out the schedule of student organization meetings and Late Night @ Harvard event listings Attend the faculty lecture given by Marcyliena Morgan on Thursday, 8/25 Check out Happy. Healthy. Harvard. on Thursday, 8/25 Apply for a Freshman Seminar -
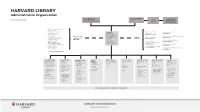
HARVARD LIBRARY Governance
HARVARD LIBRARY Administrative Organization CLAUDINE GAY ALAN GARBER Faculty Advisory As of September 2020 Library Edgerley Family Dean of the Provost Council to the Board Faculty of Arts and Sciences Harvard Library Birkhoff Mathematical Library * Botany Libraries * Cabot Science Library * Faculty of Arts and Gutman Library, HGSE MARTHA Ernst Mayr Library * Sciences Alex Hodges WHITEHEAD Fine Arts Library * Martha Whitehead Vice President for Fung Library the Harvard Library Library and Knowledge Services, HKS Harvard Film Archive * Faculty of Arts Baker Library, HBS and University School Leslie Donnell Harvard-Yenching Library * and Sciences Librarian; Libraries Debra Wallace Houghton Library * Libraries Roy E. Larsen Harvard Law School Library Lamont Library * Librarian Andover-Harvard Jocelyn Kennedy Loeb Music Library * for the Faculty of Theological Library, HDS Physics Research Library * Arts and Sciences Douglas Gragg Countway Library, HMS Robbins Library of Philosophy Elaine Martin Tozzer Library * Frances Loeb Library, GSD Widener Library * Ann Whiteside Schlesinger Library, Radcliffe Institute Wolbach Library Marilyn Dunn * Harvard College Library FRANZISKA FREY THOMAS HYRY ELIZABETH KIRK MEGAN STY SNYDMAN KIM VAN SAVAGE VAUGHN WATERS SUZANNE WONES LAURA WOOD Chief of Staff and Florence Associate SNIFFIN- Managing Director Human Resources Director of Associate Associate Senior Advisor for Fearrington University Librarian MARINOFF Library Technology Director Administration and University Librarian University Librarian University -

Why George Washington's Library Is Not at Harvard
Why George Washington’s Library Is Not at Harvard The Harvard community has made this article openly available. Please share how this access benefits you. Your story matters Citation Carpenter, Kenneth E. 2020. Why George Washington’s Library Is Not at Harvard. Harvard Library Bulletin 2020, https:// nrs.harvard.edu/URN-3:HUL.INSTREPOS:37366376. Citable link https://nrs.harvard.edu/URN-3:HUL.INSTREPOS:37366376 Terms of Use This article was downloaded from Harvard University’s DASH repository, and is made available under the terms and conditions applicable to Other Posted Material, as set forth at http:// nrs.harvard.edu/urn-3:HUL.InstRepos:dash.current.terms-of- use#LAA Harvard Library Bulletin, November 2020 https://harvardlibrarybulletin.org Why George Washington’s Library Is Not at Harvard By Kenneth E. Carpenter [ORCID iD: 0000-0001-9336-6367] INTRODUCTION In 1991, at the opening of an exhibition to celebrate the fiftieth anniversary of Houghton Library, Roger Stoddard related “How Harvard Didn’t Get Its Rare Books and Manuscripts”— why Harvard has no library of medieval manuscripts, no major European literary archive, and no early library. Most of us in what is now Houghton Library’s Edison and Newman Room were saddened to learn that Harvard almost came into possession of the Si Thomas Phillipps collection of manuscripts, a major European literary archive, and a sixteenth-century library.1 Yet another collection that Harvard almost acquired is a portion of George Washington’s own library, which is housed instead across the river at the Boston Athenæum. Although the Harvard-connected scholars who took the lead in negotiating for the library first turned to Harvard to acquire it, their major goal was to keep the books in the United States.