Codage Et Conversion De L'information
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Technical Reference Manual for the Standardization of Geographical Names United Nations Group of Experts on Geographical Names
ST/ESA/STAT/SER.M/87 Department of Economic and Social Affairs Statistics Division Technical reference manual for the standardization of geographical names United Nations Group of Experts on Geographical Names United Nations New York, 2007 The Department of Economic and Social Affairs of the United Nations Secretariat is a vital interface between global policies in the economic, social and environmental spheres and national action. The Department works in three main interlinked areas: (i) it compiles, generates and analyses a wide range of economic, social and environmental data and information on which Member States of the United Nations draw to review common problems and to take stock of policy options; (ii) it facilitates the negotiations of Member States in many intergovernmental bodies on joint courses of action to address ongoing or emerging global challenges; and (iii) it advises interested Governments on the ways and means of translating policy frameworks developed in United Nations conferences and summits into programmes at the country level and, through technical assistance, helps build national capacities. NOTE The designations employed and the presentation of material in the present publication do not imply the expression of any opinion whatsoever on the part of the Secretariat of the United Nations concerning the legal status of any country, territory, city or area or of its authorities, or concerning the delimitation of its frontiers or boundaries. The term “country” as used in the text of this publication also refers, as appropriate, to territories or areas. Symbols of United Nations documents are composed of capital letters combined with figures. ST/ESA/STAT/SER.M/87 UNITED NATIONS PUBLICATION Sales No. -

Names of Countries, Their Capitals and Inhabitants
United Nations Group of Experts on Geographical Names (UNGEGN) East Central and South-East Europe Division (ECSEED) ___________________________________________________________________________ The Nineteenth Session of the East Central and South-East Europe Division of the UNGEGN Zagreb, Croatia, 19 – 21 November 2008 Item 9 and 10 of the agenda Document Symbol: ECSEED/Session.19/2008/10 Names of countries, their capitals and inhabitants Submitted by Poland* ___________________________________________________________________________ * Prepared by Maciej Zych, Commission on Standardization of Geographical Names Outside the Republic of Poland, Poland. 19th Session of the East, Central and South-East Europe Division of the United Nations Group of Experts on Geographical Names Zagreb, 19 – 21 November 2008 Names of countries, their capitals and inhabitants Maciej Zych Commission on Standardization of Geographical Names Outside the Republic of Poland 1 Names of countries, their capitals and inhabitants In 1997 the Commission on Standardization of Geographical Names Outside the Republic of Poland published the first list of Names of countries, their capitals and inhabitants, comprising both independent countries as well as non-self-governing and autonomous territories. The second edition appeared in 2003. Numerous changes occurred in geographical names in the six years since the previous list was published. New countries and new non-self-governing and autonomous territories appeared, some countries changed their names, other their capital or its name, the Polish names for several countries and their capitals also changed as did the recommended principles for the Romanization of several languages using non-Roman systems of writing. The third edition of Names of countries, their capitals and inhabitants appeared in the end of 2007, the data it contained being updated for mid-July 2007. -

Evitalia NORMAS ISO En El Marco De La Complejidad
No. 7 Revitalia NORMAS ISO en el marco de la complejidad ESTEQUIOMETRIA de las relaciones humanas FRACTALIDAD en los sistemas biológicos Dirección postal Calle 82 # 102 - 79 Bogotá - Colombia Revista Revitalia Publicación trimestral Contacto [email protected] Web http://revitalia.biogestion.com.co Volumen 2 / Número 7 / Noviembre-Enero de 2021 ISSN: 2711-4635 Editor líder: Juan Pablo Ramírez Galvis. Consultor en Biogestión, NBIC y Gerencia Ambiental/de la Calidad. Globuss Biogestión [email protected] ORCID: 0000-0002-1947-5589 Par evaluador: Jhon Eyber Pazos Alonso Experto en nanotecnología, biosensores y caracterización por AFM. Universidad Central / Clúster NBIC [email protected] ORCID: 0000-0002-5608-1597 Contenido en este número Editorial p. 3 Estequiometría de las relaciones humanas pp. 5-13 Catálogo de las normas ISO en el marco de la complejidad pp. 15-28 Fractalidad en los sistemas biológicos pp. 30-37 Licencia Creative Commons CC BY-NC-ND 4.0 2 Editorial: “En armonía con lo ancestral” Juan Pablo Ramírez Galvis. Consultor en Biogestión, NBIC y Gerencia Ambiental/de la Calidad. [email protected] ORCID: 0000-0002-1947-5589 La dicotomía entre ciencia y religión proviene de la edad media, en la cual, los aspectos espirituales no podían explicarse desde el método científico, y a su vez, la matematización mecánica del universo era el único argumento que convencía a los investigadores. Sin embargo, más atrás en la línea del tiempo, los egipcios, sumerios, chinos, etc., unificaban las teorías metafísicas con las ciencias básicas para dar cuenta de los fenómenos en todas las escalas desde lo micro hasta lo macro. -

Transliteration of Tamil and Other Indic Scripts Ram Viswanadha
Transliteration of Tamil and Other Indic Scripts Ram Viswanadha Unicode Software Engineer IBM Globalization Center of Competency, California, USA ___________________________________________________________________________ Main points of Powerpoint presentation This talk gives an overview and discusses the issues with transliteration of Indic scripts to Latin and between different Indic scripts, e.g: Tamil-Telugu, Gujarati-Tamil, etc. It is often perceived that transliteration between different Indic scripts is straightforward because all Indic scripts have a common origin in Brahmi script. The ISCII standard is based on this similarity between scripts, and the placement of Unicode code points for each Indic script is based on an early version of ISCII. Correct transliteration between Indic scripts takes advantage of this allocation but handles special cases. The ICU implementation uses a script-neutral pivot range in Unicode. --- Agenda • What is ICU? • Terminology & Concepts • Standards for Romanization • Problems in Romanization • Problems in Inter-Indic Transliteration • Implementation approaches • Implementation in ICU •Summary •A brief overview of what International Components for Unicode (ICU) is. •Some terms and concepts which are important for the scope of this presentation are discussed •Different standards for Romanization, ISCII and ISO 15919 in particular are presented •Some problems in Romanization and Inter-Indic transliteration are discussed •Different implementation approaches, their deficiencies and how ICU’s implementation -

A Könyvtárüggyel Kapcsolatos Nemzetközi Szabványok
A könyvtárüggyel kapcsolatos nemzetközi szabványok 1. Állomány-nyilvántartás ISO 20775:2009 Information and documentation. Schema for holdings information 2. Bibliográfiai feldolgozás és adatcsere, transzliteráció ISO 10754:1996 Information and documentation. Extension of the Cyrillic alphabet coded character set for non-Slavic languages for bibliographic information interchange ISO 11940:1998 Information and documentation. Transliteration of Thai ISO 11940-2:2007 Information and documentation. Transliteration of Thai characters into Latin characters. Part 2: Simplified transcription of Thai language ISO 15919:2001 Information and documentation. Transliteration of Devanagari and related Indic scripts into Latin characters ISO 15924:2004 Information and documentation. Codes for the representation of names of scripts ISO 21127:2014 Information and documentation. A reference ontology for the interchange of cultural heritage information ISO 233:1984 Documentation. Transliteration of Arabic characters into Latin characters ISO 233-2:1993 Information and documentation. Transliteration of Arabic characters into Latin characters. Part 2: Arabic language. Simplified transliteration ISO 233-3:1999 Information and documentation. Transliteration of Arabic characters into Latin characters. Part 3: Persian language. Simplified transliteration ISO 25577:2013 Information and documentation. MarcXchange ISO 259:1984 Documentation. Transliteration of Hebrew characters into Latin characters ISO 259-2:1994 Information and documentation. Transliteration of Hebrew characters into Latin characters. Part 2. Simplified transliteration ISO 3602:1989 Documentation. Romanization of Japanese (kana script) ISO 5963:1985 Documentation. Methods for examining documents, determining their subjects, and selecting indexing terms ISO 639-2:1998 Codes for the representation of names of languages. Part 2. Alpha-3 code ISO 6630:1986 Documentation. Bibliographic control characters ISO 7098:1991 Information and documentation. -

2021 Nr. 10 2021-05-31
LIETUVOS STANDARTIZACIJOS DEPARTAMENTO BIULETENIS 2015 M. NR. 5 LIETUVOS STANDARTIZACIJOS DEPARTAMENTO BIULETENIS 2021 Nr. 10 2021-05-31 1 2021 M. NR. 10 (2021-05-31)|LIETUVOS STANDARTIZACIJOS DEPARTAMENTO BIULETENIS TURINYS ATNAUJINTA LST TK 36 APLINKOS APSAUGA VEIKLOS SRITIS ............................................................................................................. 3 IŠLEISTI LIETUVOS STANDARTAI IR STANDARTIZACIJOS LEIDINIAI ................................................................................................ 3 IŠLEISTA NACIONALINIO STANDARTO PATAISA ..................................................................................................................... 3 IŠLEISTI PERIMTIEJI EUROPOS STANDARTAI IR STANDARTIZACIJOS LEIDINIAI .................................................... 3 IŠVERSTI Į LIETUVIŲ KALBĄ PERIMTIEJI STANDARTAI .................................................................................................... 12 NEGALIOJANTYS LIETUVOS STANDARTAI IR STANDARTIZACIJOS LEIDINIAI...................................................................... 12 SKELBIAMI NEGALIOSIANČIAIS LIETUVOS STANDARTAI IR STANDARTIZACIJOS LEIDINIAI ...................................... 18 PERŽIŪRIMI NACIONALINIAI STANDARTAI ........................................................................................................................................... 18 PERŽIŪRIMI EUROPOS STANDARTAI IR STANDARTIZACIJOS LEIDINIAI ............................................................................... -

ISO 11940-2:2007 Db1b724a95ea/Iso-11940-2-2007
INTERNATIONAL ISO STANDARD 11940-2 First edition 2007-05-01 Information and documentation — Transliteration of Thai characters into Latin characters Part 2: Simplified transcription of Thai language iTeh STInformationANDA etR documentationD PREV —I TranslittérationEW des caractères thaï en caractères latins (stPartieand 2:a Transcriptionrds.iteh simplifiée.ai) de la langue thaï ISO 11940-2:2007 https://standards.iteh.ai/catalog/standards/sist/f107d633-0a12-4a12-9e97- db1b724a95ea/iso-11940-2-2007 Reference number ISO 11940-2:2007(E) © ISO 2007 ISO 11940-2:2007(E) PDF disclaimer This PDF file may contain embedded typefaces. In accordance with Adobe's licensing policy, this file may be printed or viewed but shall not be edited unless the typefaces which are embedded are licensed to and installed on the computer performing the editing. In downloading this file, parties accept therein the responsibility of not infringing Adobe's licensing policy. The ISO Central Secretariat accepts no liability in this area. Adobe is a trademark of Adobe Systems Incorporated. Details of the software products used to create this PDF file can be found in the General Info relative to the file; the PDF-creation parameters were optimized for printing. Every care has been taken to ensure that the file is suitable for use by ISO member bodies. In the unlikely event that a problem relating to it is found, please inform the Central Secretariat at the address given below. iTeh STANDARD PREVIEW (standards.iteh.ai) ISO 11940-2:2007 https://standards.iteh.ai/catalog/standards/sist/f107d633-0a12-4a12-9e97- db1b724a95ea/iso-11940-2-2007 COPYRIGHT PROTECTED DOCUMENT © ISO 2007 All rights reserved. -

Finite-State Script Normalization and Processing Utilities: the Nisaba Brahmic Library
Finite-state script normalization and processing utilities: The Nisaba Brahmic library Cibu Johny† Lawrence Wolf-Sonkin‡ Alexander Gutkin† Brian Roark‡ Google Research †United Kingdom and ‡United States {cibu,wolfsonkin,agutkin,roark}@google.com Abstract In addition to such normalization issues, some scripts also have well-formedness constraints, i.e., This paper presents an open-source library for efficient low-level processing of ten ma- not all strings of Unicode characters from a single jor South Asian Brahmic scripts. The library script correspond to a valid (i.e., legible) grapheme provides a flexible and extensible framework sequence in the script. Such constraints do not ap- for supporting crucial operations on Brahmic ply in the basic Latin alphabet, where any permuta- scripts, such as NFC, visual normalization, tion of letters can be rendered as a valid string (e.g., reversible transliteration, and validity checks, for use as an acronym). The Brahmic family of implemented in Python within a finite-state scripts, however, including the Devanagari script transducer formalism. We survey some com- mon Brahmic script issues that may adversely used to write Hindi, Marathi and many other South affect the performance of downstream NLP Asian languages, do have such constraints. These tasks, and provide the rationale for finite-state scripts are alphasyllabaries, meaning that they are design and system implementation details. structured around orthographic syllables (aksara)̣ as the basic unit.1 One or more Unicode characters 1 Introduction combine when rendering one of thousands of leg- The Unicode Standard separates the representation ible aksara,̣ but many combinations do not corre- of text from its specific graphical rendering: text spond to any aksara.̣ Given a token in these scripts, is encoded as a sequence of characters, which, at one may want to (a) normalize it to a canonical presentation time are then collectively rendered form; and (b) check whether it is a well-formed into the appropriate sequence of glyphs for display. -

Osist ISO/DIS 3297:2019 01-Oktober-2019
- W cd E c0 I d- V 7b E 7 9 R i) c2 1 3 20 P .a /1 - D h st 97 e si 2 R it s/ -3 A s. : d is d rd ar d D r a d o- N a d n is A d an ta t- n st /s is T a l g os S t ul lo / s a 0c eh ( F at e T /c 72 i ai f . 78 eh 6 it e SLOVENSKI STANDARD s. 66 Informatika in dokumentacija - Mednarodna standardna številka serijske d 6- publikacije (ISSN) ar d oSIST ISO/DIS 3297:2019 d bc an - st c4 // e Information and documentation -- International standard serial01-oktober-2019 number (ISSN) s: 4 tp ht Information et documentation -- Numéro international normalisé des publications en série (ISSN) Ta slovenski standard je istoveten z: ICS: 01.140.20 oSIST ISO/DIS 3297:2019 Informacijske vede ISO/DIS 3297:2019 Information sciences 2003-01.Slovenski inštitut za standardizacijo. Razmnoževanje celote ali delov tega standarda ni dovoljeno.en,fr,de - W cd E c0 I d- V 7b E 7 9 R i) c2 1 3 20 P .a /1 - D h st 97 e si 2 R it s/ -3 A s. : d is d rd ar d D r a d o- oSIST ISO/DIS 3297:2019 N a d n is A d an ta t- n st /s is T a l g os S t ul lo / s a 0c eh ( F at e T /c 72 i ai f . -

Inventory of Romanization Tools
Inventory of Romanization Tools Standards Intellectual Management Office Library and Archives Canad Ottawa 2006 Inventory of Romanization Tools page 1 Language Script Romanization system for an English Romanization system for a French Alternate Romanization system catalogue catalogue Amharic Ethiopic ALA-LC 1997 BGN/PCGN 1967 UNGEGN 1967 (I/17). http://www.eki.ee/wgrs/rom1_am.pdf Arabic Arabic ALA-LC 1997 ISO 233:1984.Transliteration of Arabic BGN/PCGN 1956 characters into Latin characters NLC COPIES: BS 4280:1968. Transliteration of Arabic characters NL Stacks - TA368 I58 fol. no. 00233 1984 E DMG 1936 NL Stacks - TA368 I58 fol. no. DIN-31635, 1982 00233 1984 E - Copy 2 I.G.N. System 1973 (also called Variant B of the Amended Beirut System) ISO 233-2:1993. Transliteration of Arabic characters into Latin characters -- Part 2: Lebanon national system 1963 Arabic language -- Simplified transliteration Morocco national system 1932 Royal Jordanian Geographic Centre (RJGC) System Survey of Egypt System (SES) UNGEGN 1972 (II/8). http://www.eki.ee/wgrs/rom1_ar.pdf Update, April 2004: http://www.eki.ee/wgrs/ung22str.pdf Armenian Armenian ALA-LC 1997 ISO 9985:1996. Transliteration of BGN/PCGN 1981 Armenian characters into Latin characters Hübschmann-Meillet. Assamese Bengali ALA-LC 1997 ISO 15919:2001. Transliteration of Hunterian System Devanagari and related Indic scripts into Latin characters UNGEGN 1977 (III/12). http://www.eki.ee/wgrs/rom1_as.pdf 14/08/2006 Inventory of Romanization Tools page 2 Language Script Romanization system for an English Romanization system for a French Alternate Romanization system catalogue catalogue Azerbaijani Arabic, Cyrillic ALA-LC 1997 ISO 233:1984.Transliteration of Arabic characters into Latin characters. -

ISO 11940:2005 C9f6d4746954/Sist-Iso-11940-2005
INTERNATIONAL ISO STANDARD 11940 First edition 1998-06-01 Information and documentation — Transliteration of Thai Information et documentation — Translittération du thaï iTeh STANDARD PREVIEW (standards.iteh.ai) SIST ISO 11940:2005 https://standards.iteh.ai/catalog/standards/sist/cb525c7b-da4d-459b-b69d- c9f6d4746954/sist-iso-11940-2005 r Reference numbe A ISO 11940:1998(E) ISO 11940:1998(E) Foreword ISO (the International Organization for Standardization) is a worldwide federation of national standards bodies (ISO member bodies). The work of preparing International Standards is normally carried out through ISO technical committees. Each member body interested in a subject for which a technical committee has been established has the right to be represented on that committee. International organizations, governmental and non- governmental, in liaison with ISO, also take part in the work. ISO collaborates closely with the International Electrotechnical Commission (IEC) on all matters of electrotechnical standardization. Draft International Standards adopted by the technical committees are circulated to the member bodies for voting. Publication as an International Standard requires approval by at least 75 % of the member bodies casting a vote. iTeh STANDARD PREVIEW International Standard ISO 11940 was prepared by Technical Committee ISO/TC 46, Information and documentation(s, tSubcommitteeandard sSC.i t2,e Conver-h.ai) sion of written languages. SIST ISO 11940:2005 Annex A forms an integral parthttps :/of/st athisndar dInternationals.iteh.ai/catalog /Standard.standards/si sAnnexest/cb525c7b -Bda4d-459b-b69d- and C are for information only. c9f6d4746954/sist-iso-11940-2005 © ISO 1998 All rights reserved. Unless otherwise specified, no part of this publication may be reproduced or utilized in any form or by any means, electronic or mechanical, including photocopying and microfilm, without permission in writing from the publisher. -
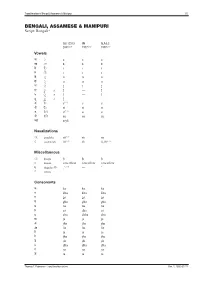
Transliteration of <Script Name>
Transliteration of Bengali, Assamese & Manipuri 1/5 BENGALI, ASSAMESE & MANIPURI Script: Bengali* ISO 15919 UN ALA-LC 2001(1.0) 1977(2.0) 1997(3.0) Vowels অ ◌ a a a আ ◌া ā ā ā ই ি◌ i i i ঈ ◌ী ī ī ī উ ◌ু u u u ঊ ◌ূ ū ū ū ঋ ◌ৃ r̥ ṛ r̥ ৠ ◌ৄ r̥̄ — r̥̄ ঌ ◌ৢ l̥ — l̥ ৡ ◌ৣ A l̥ ̄ — — এ ে◌ e(1.1) e e ঐ ৈ◌ ai ai ai ও ে◌া o(1.1) o o ঔ ে◌ৗ au au au অ�া a:yā — — Nasalizations ◌ং anunāsika ṁ(1.2) ṁ ṃ ◌ঁ candrabindu m̐ (1.2) m̐ n̐, m̐ (3.1) Miscellaneous ◌ঃ bisarga ḥ ḥ ḥ ◌্ hasanta vowelless vowelless vowelless (1.3) ঽ abagraha Ⓑ :’ — ’ ৺ isshara — — — Consonants ক ka ka ka খ kha kha kha গ ga ga ga ঘ gha gha gha ঙ ṅa ṅa ṅa চ ca cha ca ছ cha chha cha জ ja ja ja ঝ jha jha jha ঞ ña ña ña ট ṭa ṭa ṭa ঠ ṭha ṭha ṭha ড ḍa ḍa ḍa ঢ ḍha ḍha ḍha ণ ṇa ṇa ṇa ত ta ta ta Thomas T. Pedersen – transliteration.eki.ee Rev. 2, 2005-07-21 Transliteration of Bengali, Assamese & Manipuri 2/5 ISO 15919 UN ALA-LC 2001(1.0) 1977(2.0) 1997(3.0) থ tha tha tha দ da da da ধ dha dha dha ন na na na প pa pa pa ফ pha pha pha ব ba ba ba(3.2) ভ bha bha bha ম ma ma ma য ya ja̱ ya র ⒷⓂ ra ra ra ৰ Ⓐ ra ra ra ল la la la ৱ ⒶⓂ va va wa শ śa sha śa ষ ṣa ṣha sha স sa sa sa হ ha ha ha ড় ṛa ṙa ṛa ঢ় ṛha ṙha ṛha য় ẏa ya ẏa জ় za — — ব় wa — — ক় Ⓑ qa — — খ় Ⓑ k̲h̲a — — গ় Ⓑ ġa — — ফ় Ⓑ fa — — Adscript consonants ◌� ya-phala -ya(1.4) -ya ẏa ৎ khanda-ta -t -t ṯa ◌� repha r- r- r- ◌� baphala -b -b -b ◌� raphala -r -r -r Vowel ligatures (conjuncts)C � gu � ru � rū � Ⓐ ru � rū � śu � hr̥ � hu � tru � trū � ntu � lgu Thomas T.