Towards a Well-Formed Mongolian Specification That Allows Interoperable Implementations
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Greek Type Design Introduction
A primer on Greek type design by Gerry Leonidas T the 1997 ATypI Conference at Reading I gave a talk Awith the title ‘Typography & the Greek language: designing typefaces in a cultural context.’ The inspiration for that talk was a discussion with Christopher Burke on designing typefaces for a script one is not linguistically familiar with. My position was that knowledge and use of a language is not a prerequisite for understanding the script to a very high, if not conclusive, degree. In other words, although a ‘typographically attuned’ native user should test a design in real circumstances, any designer could, with the right preparation and monitoring, produce competent typefaces. This position was based on my understanding of the decisions a designer must make in designing a Greek typeface. I should add that this argument had two weak points: one, it was based on a small amount of personal experience in type design and a lot of intuition, rather than research; and, two, it was quite possible that, as a Greek, I was making the ‘right’ choices by default. Since 1997, my own work proved me right on the first point, and that of other designers – both Greeks and non- Greeks – on the second. The last few years saw multilingual typography literally explode. An obvious arena was the broader European region: the Amsterdam Treaty of 1997 which, at the same time as bringing the European Union closer to integration on a number of fields, marked a heightening of awareness in cultural characteristics, down to an explicit statement of support for dialects and local script variations. -

Image Making of the Letterforms Inspiration from Indian Image Making for Font Design
RPS Research into Design — Supporting Sustainable Product Development “icord2011-lineup” 2010/12/24 826 IMAGE MAKING OF THE LETTERFORMS INSPIRATION FROM INDIAN IMAGE MAKING FOR FONT DESIGN Prasad Bokila and Shilpa Ranadeb Industrial Design Centre, IIT Bombay, Powai, Mumbai 400076. Email: [email protected], [email protected] Design field, being interdisciplinary in nature, has some roots in ‘art practices’. Study of the medieval Indian art and crafts through the design perspective may open lot more opportunities to relocate the design practice in Indian context. This work can be described as cross-pollination between Indian image making tradition and Typeface design, where the first is providing a structural tool for the experimentation in the other. This paper is divided in two parts. The first part presents a need for new approach in Devanagari type face design. Second part is the experimentation in font design based on Image making process in Indian tradition. The experiment generated a new font in which a spine for each letterform is designed based on a combination of regular horizontal grid and newly introduced angular grid. Keywords: Indian aesthetics, Typeface design, Image making, Art and design. 1. INTRODUCTION Contemporary design arrived in India in the later half of the twentieth century. It has been heavily influenced and benefited by European design theory and practice. As a result, it has inherited relation to the modern art, following the trends of modernism and post modernism. But on the broader scenario of design needs of India, this well equipped modern design was not emergence but the replacement of traditional indigenous design practices mainly covered under art and craft. -

An Introduction to Graphology: Definition, Theoretical Background and Levels of Analysis
AN INTRODUCTION TO GRAPHOLOGY: DEFINITION, THEORETICAL BACKGROUND AND LEVELS OF ANALYSIS EVA GÓMEZ-JIMÉNEZ Universidad de Granada [email protected] 71 1. Introduction Graphology is a linguistic level of analysis that comprises the study of graphic aspects of language1. This term was first brought into use in linguistic studies in the sixties by McIntosh (1961), who considered it an analogous mode to that of phonology. In his paper “Graphology and Meaning”, he declared he had used graphology “in a sense which is intended to answer, in the realm of written language, to that of ‘phonology’ in the realm of spoken language” (1961: 107). A few years later, Halliday, McIntosh and Strevens (1964: 50) broadened this concept when they connected it to spelling, punctuation and any other matter related to graphic resources in language. Other linguists such as Vachek (1973), Sampson (1985), Coulmas (1991, 1999) and Harris (1995) have also worked on graphology, paying close attention to the properties of alphabets and their evolution throughout history. The importance and status of graphology as a linguistic level of analysis is particularly prominent in stylistics and multimodality. Within stylistics, some scholars have studied how graphological deviation may affect meaning and produce aesthetic effects. Van Peer (1993), for instance, considered typographic foregrounding and its evolution as a poetic device, while Nänny (2001) checked the iconic properties of verses according to their length. Within multimodality, miscelánea: a journal of english and american studies 51 (2015): pp. 71-85 ISSN: 1137-6368 Eva Gómez-Jiménez and because of the recent relevance of images in communication, there is an attempt, currently, to integrate some graphological elements into the study of modes of communication. -

Calligraphy-Magic.Pdf
Calligraphy Magic How to Create Lettering, Knotwork, Coloring and More Cari Buziak Table of Contents Table of Contents Introduction Glossary of Terms CHAPTER 1 Calligraphy Tools and Supplies CHAPTER 2 How to Make Calligraphy Strokes CHAPTER 3 15 Alphabets From Basic to Fancy CHAPTER 4 Ornamentation, Gilding & Coloring CHAPTER 5 12 Calligraphy Projects Step by Step STATIONERY AND EVENT ANNOUNCEMENTS Bookplates Greeting Cards Bookmarks Logos Business Cards and Letterhead Wedding Announcements Invitations Place Cards and Thank-You’s DISPLAY PIECES Monograms Quotations Certifi cates Lettering with Celtic Decoration Illustrated Poems Lettering with Dragon Artwork CHAPTER 6 Creating Your Own Computer Fonts Pre-printed Celtic Knotwork Grid Paper Pre-ruled Calligraphy Practice Pages Index About the Author Dedication Acknowledgments Introduction Introduction Calligraphy is a fun craft to learn, as well as a useful one. Far from being an obsolete skill, more and more people today are picking up the pen and creating their own greeting cards, wedding invitations, fine art projects, and even creating their own computer fonts! In the old days, calligraphy tools were unique and specically crafted to their task. Today, a calligrapher has a wide variety of tools from which to choose, from traditional to completely modern, even digital! Calligraphers can now experiment with their artistic expression, freely mixing creative ideas and elements together to explore new artforms with their projects. In this book we’ll examine the basic techniques of calligraphy, covering calligraphy hands suitable for a wide variety of projects and easy for a beginner or intermediate calligrapher to practice and learn. We’ll also cover easy decorative techniques such as watercolor painting, Celtic knotwork, gold leang and illustration ideas to create a “toolkit” of creative techniques. -

Arabic Type Classification System
ARABIC TYPE CLASSIFICATION SYSTEM QUALITATIVE CLASSIFICATION OF HISTORIC ARABIC WRITING SCRIPTS IN THE CONTEMPORARY TYPOGRAPHIC CONTEXT BY DARIN ABU-SHAQRA | INCLUSIVE DESIGN | 2020 SUBMITTED TO OCAD UNIVERSITY IN PARTIAL FULFILLMENT OF THE REQUIREMENTS FOR THE DEGREE OF MASTER OF DESIGN IN INCLUSIVE DESIGN TORONTO, ONTARIO, CANADA, 2020 i ACKNOWLEDGEMENTS I wish to express my sincere appreciation to both my primary advisor Richard Hunt, and secondary advisor Peter Coppin, your unlimited positivity, guidance and support was crucial to the comple- tion of this work. It was an absolute honour to have two geniuses in their fields as my advisors. Enriching my knowledge of typography and graphic design and looking through the lens of inclusive design and cognitive science of representation shaped a new respect for the cultural and experiential power of typography in me. My sincere gratitude goes to the talented calligraphers and graphic designers whom I have interviewed back in Jordan. Thank you, for your valuable time, and for allowing me to watch the world from different angles, and experiences. This project owes a lot to your motivation. My heartfelt thanks goes to my family - my late father Khalid, who, although is no longer with me, continues to inspire every step I have to take, my mother Nadia for being the symbol of strength and persistence, my siblings Yasmin, Omar, Ali and Abdullah for always believing in my dreams and doing whatever it takes to make them come true. A special thanks goes to the one who made those two years possible, Ra’ad thank you for being the definition of a life companion and a husband. -

Middle East-I 9 Modern and Liturgical Scripts
The Unicode® Standard Version 13.0 – Core Specification To learn about the latest version of the Unicode Standard, see http://www.unicode.org/versions/latest/. Many of the designations used by manufacturers and sellers to distinguish their products are claimed as trademarks. Where those designations appear in this book, and the publisher was aware of a trade- mark claim, the designations have been printed with initial capital letters or in all capitals. Unicode and the Unicode Logo are registered trademarks of Unicode, Inc., in the United States and other countries. The authors and publisher have taken care in the preparation of this specification, but make no expressed or implied warranty of any kind and assume no responsibility for errors or omissions. No liability is assumed for incidental or consequential damages in connection with or arising out of the use of the information or programs contained herein. The Unicode Character Database and other files are provided as-is by Unicode, Inc. No claims are made as to fitness for any particular purpose. No warranties of any kind are expressed or implied. The recipient agrees to determine applicability of information provided. © 2020 Unicode, Inc. All rights reserved. This publication is protected by copyright, and permission must be obtained from the publisher prior to any prohibited reproduction. For information regarding permissions, inquire at http://www.unicode.org/reporting.html. For information about the Unicode terms of use, please see http://www.unicode.org/copyright.html. The Unicode Standard / the Unicode Consortium; edited by the Unicode Consortium. — Version 13.0. Includes index. ISBN 978-1-936213-26-9 (http://www.unicode.org/versions/Unicode13.0.0/) 1. -

The Typographic Contribution to Language: 1987 Towards a Model of Typographic Genres and Their Underlying Structures
The typographic contribution to language: 1987 towards a model of typographic genres and their underlying structures Robert Waller A note about this edition After completing my PhD thesis in 1987, I left the research career that had led up to it, and went into practice as an information designer, although some ideas from the thesis were published (Waller 1990, 1999). For the next twenty years, my main focus was commercial survival, and I gave it little thought until Judy Delin and John Bateman got in touch. Their AHRC-funded GeM project looked at the role of layout in written text, and took a genre-based approach. I was delighted when they used my model as a starting point for their own richer and more robust version (Allen, Bateman and Delin 1999, Delin, Bateman and Allen 2002). At their suggestion I created a digital version, by converting the original WriteNow file into an early version of Word, and upwards through newer Word versions. The GeM project made this available online, and I have also placed it on my own website in recent years. However, many illustrations were missing, and others were scanned from photocopies. Recently I imported the Word file into InDesign, and I located and re-scanned most of the images. What you have here is the original text, although pages numbers have inevitably changed, and I have also corrected a number of typos. One or two exemplar documents are not the originals but make the same points. I am mindful that this thesis is over twenty-five years old and was written before the internet, and in the very early days of electronic documents and hypertext. -
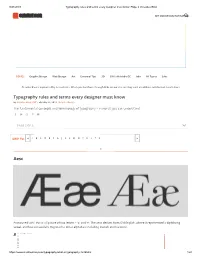
Typography Rules and Terms Every Designer Must Know Aesc Aperture
9/24/2019 Typography rules and terms every designer must know: Page 2 | Creative Bloq ART AND DESIGN INSPIRATION TOPICS Graphic Design Web Design Art Essential Tips 3D 39% o Adobe CC Jobs All Topics Jobs Creative Bloq is supported by its audience. When you purchase through links on our site, we may earn an aliate commission. Learn more Typography rules and terms every designer must know By Creative Bloq Sta February 25, 2019 Graphic Design The fundamental concepts and terminology of typography – in words you can understand. PAGE 2 OF 2: JUMP TO: A B C D E F G J K L M O P R S T X A Aesc Pronouced 'ash', this is a ligature of two letters – 'a' and 'e'. The aesc derives from Old English, where it represented a diphthong vowel, and has successfully migrated to other alphabets including Danish and Icelandic. ApertureX E S O L C https://www.creativebloq.com/typography/what-is-typography-123652/2 1/20 9/24/2019 Typography rules and terms every designer must know: Page 2 | Creative Bloq The constricted opening of a glyph, as seen in the letter 'e'. Varying the size of the aperture has a direct eect on the legibility of a letterform and, ultimately, readability. Apertures can be 'closed' (shown in orange here) or 'open' (green). Apex The point at the top of a character where the left and right strokes meet. The example might be the top point of an uppercase 'A'. Arm A horizontal stroke that does not connect to a stroke or stem at one or both ends – such as the top of the capital T. -

The Case for Cross-Breeding Fonts Topics: Technologies That Permit Generating a New Typeface That Shares the Characteristics of Two Or More Parents
THE MAKEREADY ARCHIVE Column 5 of 77 The Case for Cross-Breeding Fonts Topics: Technologies that permit generating a new typeface that shares the characteristics of two or more parents. Column first appeared: April 1994, Computer Artist magazine. Source of this file: An expanded version of the column as it appeared in the 1996 book Makeready. Author's comment: The idea of morphed typefaces was one whose time never came. None of the products featured here have been available in the last ten years. Even Adobe's highly-touted Multiple Master tech- nology never made it into the mainstream. This archive, to be released over several years, collects the columns that Dan Margulis wrote under the Makeready title between 1993 and 2006. In some cases the columns appear as written; in others the archive contains revised versions that appeared in later books. Makeready in principle could cover anything related to graphic arts production, but it is best known for its contributions to Photoshop technique, particularly in the field of color correction. In its final years, the column was appearing in six different magazines worldwide (two in the United States). Dan Margulis teaches small-group master classes in color correction. Information is available at http://www.ledet.com/margulis, which also has a selection of other articles and chapters from Dan’s books, and more than a hundred edited threads from Dan’s Applied Color Theory e-mail list. Copyright© 1994, 1996, 2020 Dan Margulis. All rights reserved. 11 The Case for Cross-Breeding Fonts With tens of thousands of typefaces on the market, why in the world would one want to morph existing ones? The creative designer may find some reasons. -

The Typography of Law Reviews: a Typographic Survey of Legal Periodicals
The Typography of Law Reviews: A Typographic Survey of Legal Periodicals Ambrogino Giusti Submitted to Professor Penny A. Hazelton to fulfill course requirements for Current Issues in Law Librarianship, LIS 595, and to fulfill the graduation requirement of the Culminating Experience Project for MLIS University of Washington Information School Seattle, Washington May 30, 2016 Typefaces are the clothes words wear, and just as we make judgments about people by the clothes they wear, so we make judgments about the information we’re reading by the typefaces. - Caroline Archer1 Times New Roman is a workhorse font that’s been successful for a reason. Yet it’s an open question whether its longevity is attributable to its quality or merely its ubiquity. - Matthew Butterick2 Keywords fonts, law reviews, law journals, legal periodicals, legal publications, typefaces, typography 1 Sam McManis, What Your Font Choice Says About You, THE ROANOKE TIMES (Jan. 13, 2008), http://www.roa- noke.com/webmin/features/what-your-font-choice-says-about-you/article_44076b07-db52-585b-af72- 84dc4bc4c8e6.html. 2 Matthew Butterick, A Brief History of Times New Roman, in BUTTERICK’S PRACTICAL TYPOGRAPHY (2016), http://practi- caltypography.com/times-new-roman.html. Table of Contents 1.0 Introduction ............................................................................................................................................ 1 2.0 History of Typography ............................................................................................................................ -

Letterstudio Modules 2015–2016 first Semester
royal academy of art LetterStudio: Description, Program, and Modules the hague govt 2015 –2016 first semester (version 1 ) Introduction In the LetterStudio second and third year students of the kabk and exchange students can follow courses, i.e., modules, on letters in the broadest sense of the word. This includes, but is not limited to, writing, type design, font production, font technology (including coding), and everything else that is, or could be part of the métiers of the graphic designer, calligrapher, lettering artist, and type designer. The o uered spectrum is defined by the sta u-lecturers, the guest- lecturers, and the students, and the scope is not restricted to the developments in the professional field. The expertise of the lecturers implies that di uerent, or even opposite opinions are represented, which guarantees the pluralism of the course. Students can sign in on modules that cover the area(s) they want to explore. The maximum length of a module is a full semester (twelve sessions). The minimum length is half a semester. Consequently either one or two modules can be followed during a semester. In case more than one module is selected, it is mandatory to select a second module that is confronting or even contradicting with the first one, i.e., that it represents a di uerent point of view. Selections have to accompanied by a solid motivation and are made in consultation with the lecturers. The level of the listed modules di uer. In some cases a first level module has to be followed before being allowed to go to the next level. -

Variability As a Key Factor for Understanding Medieval Scripts: the ORIFLAMMS Project (ANR-12-CORP-0010) Dominique Stutzmann
Variability as a Key Factor For Understanding Medieval Scripts: the ORIFLAMMS project (ANR-12-CORP-0010) Dominique Stutzmann To cite this version: Dominique Stutzmann. Variability as a Key Factor For Understanding Medieval Scripts: the ORI- FLAMMS project (ANR-12-CORP-0010). Brookes, Stewart; Rehbein, Malte; Stokes, Peter. Digital Palaeography, Routledge, 2018, Digital Research in the Arts and Humanities, 9781472467096. halshs- 01778620 HAL Id: halshs-01778620 https://halshs.archives-ouvertes.fr/halshs-01778620 Submitted on 25 Apr 2018 HAL is a multi-disciplinary open access L’archive ouverte pluridisciplinaire HAL, est archive for the deposit and dissemination of sci- destinée au dépôt et à la diffusion de documents entific research documents, whether they are pub- scientifiques de niveau recherche, publiés ou non, lished or not. The documents may come from émanant des établissements d’enseignement et de teaching and research institutions in France or recherche français ou étrangers, des laboratoires abroad, or from public or private research centers. publics ou privés. Distributed under a Creative Commons Attribution| 4.0 International License Variability as a Key Factor For Understanding Medieval Scripts: * the ORIFLAMMS project (ANR-12-CORP-0010) Dominique Stutzmann A revolution is taking place in the twenty-first century: as a consequence of globalisation and the increasing use of electronic devices for writing and reading, the human brain faces unprecedented challenges. New demands have emerged simultaneously: multilingualism; typing on a keyboard or writing letter-by-letter on touchscreen devices instead of with a pen; reading generic fonts on a screen instead of deciphering the handwriting of one’s correspondents. In contrast, writing by hand involves the complete body (fingers, hand, arm, chest and head position, eye movements, breathing) in a three-dimensional space and multiplies physical, visual and tactile stimuli with many micro-controls, complex muscular and neural interactions.