Arxiv:1608.05374V1 [Cs.CL] 18 Aug 2016
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Comparison, Selection and Use of Sentence Alignment Algorithms for New Language Pairs
Comparison, Selection and Use of Sentence Alignment Algorithms for New Language Pairs Anil Kumar Singh Samar Husain LTRC, IIIT LTRC, IIIT Gachibowli, Hyderabad Gachibowli, Hyderabad India - 500019 India - 500019 a [email protected] s [email protected] Abstract than 95%, and usually 98 to 99% and above). The evaluation is performed in terms of precision, and Several algorithms are available for sen- sometimes also recall. The figures are given for one tence alignment, but there is a lack of or (less frequently) more corpus sizes. While this systematic evaluation and comparison of does give an indication of the performance of an al- these algorithms under different condi- gorithm, the variation in performance under varying tions. In most cases, the factors which conditions has not been considered in most cases. can significantly affect the performance Very little information is given about the conditions of a sentence alignment algorithm have under which evaluation was performed. This gives not been considered while evaluating. We the impression that the algorithm will perform with have used a method for evaluation that the reported precision and recall under all condi- can give a better estimate about a sen- tions. tence alignment algorithm's performance, We have tested several algorithms under differ- so that the best one can be selected. We ent conditions and our results show that the per- have compared four approaches using this formance of a sentence alignment algorithm varies method. These have mostly been tried significantly, depending on the conditions of test- on European language pairs. We have ing. Based on these results, we propose a method evaluated manually-checked and validated of evaluation that will give a better estimate of the English-Hindi aligned parallel corpora un- performance of a sentence alignment algorithm and der different conditions. -

Slides for My Lecture for the Texperience 2010
◦ DEVELOPMENTDEVELOPMENT OF OFxxındyındy◦ SORTSORT AND AND MERGE MERGE RULES RULES FORFOR INDIC INDIC LANGUAGES LANGUAGES ZdeněkZdeněk Wagner, Wagner, Praha, Praha, Česká Česká republika republika AnshumanAnshuman Pandey, Pandey, Univ. Univ. Michigan, Michigan, USA USA JayaJaya Saraswati, Saraswati, Mumbai, Mumbai, India India ◦ NoteNote on on pronunciation pronunciation of ofxxındy◦ındy ◦ NoteNote on on pronunciation pronunciation of ofxxındy◦ındy Czech: ks ◦ NoteNote on on pronunciation pronunciation of ofxxındy◦ındy Czech: ks English: usually as z ◦ NoteNote on on pronunciation pronunciation of ofxxındy◦ındy Czech: ks English: usually as z Hindi: as ks., l#mF can be transliterated either Lakshmi or Laxmi ◦ NoteNote on on pronunciation pronunciation of ofxxındy◦ındy Czech: ks English: usually as z Hindi: as ks., l#mF can be transliterated either Lakshmi or Laxmi Chinese: as sh ◦ NoteNote on on pronunciation pronunciation of ofxxındy◦ındy Czech: ks English: usually as z Hindi: as ks., l#mF can be transliterated either Lakshmi or Laxmi Chinese: as sh Russian: 娤¨ (meaning Hindi) ◦ NoteNote on on pronunciation pronunciation of ofxxındy◦ındy Czech: ks English: usually as z Hindi: as ks., l#mF can be transliterated either Lakshmi or Laxmi Chinese: as sh Russian: 娤¨ (meaning Hindi) x◦ındy sorts Hindi MakeIndexMakeIndex • version for English and German • CSIndex – version for Czech and Slovak • unpublished version for Sanskrit (Mark Csernel) Tables defining the sort algorithm are hard-wired in the pro- gram source code. Modification for other languages is difficult and leads rather to confusion than to development of a univer- sal tool. InternationalInternationalMakeIndexMakeIndex • Tables defining the sort algorithm present in external files. • Sort rules defined by regular expressions. -
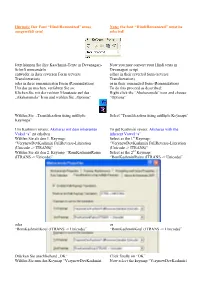
Note: the Font “Hindiromanized” Must Be Selected
Hinweis: Der Font “HindiRomanized” muss Note: the font “HindiRomanized” must be ausgewählt sein! selected! Jetzt können Sie ihre Kaschmiri-Texte in Devanagari- Now you may convert your Hindi texts in Schrift umwandeln Devanagari script entweder in ihrer reversen Form (reverse either in their reverted form (reverse Transliteration) Transliteration) oder in ihrer romanisierten Form (Romanization) or in their romanized form (Romanization) Um das zu machen, verfahren Sie so: To do this proceed as described: Klicken Sie mit der rechten Maustaste auf das Right click the “Aksharamala” icon and choose „Aksharamala” Icon und wählen Sie „Options“ “Options” Wählen Sie „Transliteration using multiple Select “Transliteration using multiple Keymaps” Keymaps” Um Kashmiri revers: Aksharas mit dem inherenten To get Kashmiri revers: Aksharas with the Vokal “a” zu erhalten inherent Vowel “a” Wählen Sie als den 1. Keymap: Select as the 1st Keymap: “VerynewDevKashmiri FullReverse-Literation “VerynewDevKashmiri FullReverse-Literation (Unicode -> ITRANS)” (Unicode -> ITRANS)” Wählen Sie als den 2. Keymap “RomKashmiriRaina Select as the 2nd Keymap: (ITRANS -> Unicode)” “RomKashmiriRaina (ITRANS -> Unicode)” oder or “RomKashmiriKoul (ITRANS -> Unicode)” “RomKashmiriKoul (ITRANS -> Unicode)” Drücken Sie anschließend „OK“ Click finally on “OK” Wählen Sie nun den Keymap “VerynewDevKashmiri Now select the keymap “VerynewDevKashmiri FullReverse-Literation (Unicode -> ITRANS)” aus FullReverse-Literation (Unicode -> ITRANS)” Um Kashmiri revers: Aksharas ohne den inherenten -

Document Similarity Amid Automatically Detected Terms*
Document Similarity Amid Automatically Detected Terms∗ Hardik Joshi Jerome White Gujarat University New York University Ahmedabad, India Abu Dhabi, UAE [email protected] [email protected] ABSTRACT center was involved. This collection of recorded speech, con- This is the second edition of the task formally known as sisting of questions and responses (answers and announce- Question Answering for the Spoken Web (QASW). It is an ments) was provided the basis for the test collection. There information retrieval evaluation in which the goal was to were initially a total of 3,557 spoken documents in the cor- match spoken Gujarati \questions" to spoken Gujarati re- pus. From system logs, these documents were divided into a sponses. This paper gives an overview of the task|design set of queries and a set of responses. Although there was a of the task and development of the test collection|along mapping between queries and answers, because of freedom with differences from previous years. given to farmers, this mapping was not always \correct." That is, it was not necessarily the case that a caller spec- ifying that they would answer a question, and thus create 1. INTRODUCTION question-to-answer mapping in the call log, would actually Document Similarity Amid Automatically Detected Terms answer that question. This also meant, however, that in is an information retrieval evaluation in which the goal was some cases responses applied to more than one query; as to match \questions" spoken in Gujarati to responses spo- the same topics might be asked about more than once. ken in Gujarati. -

Download Download
ǣᵽэȏḙṍɨїẁľḹšṍḯⱪчŋṏȅůʆḱẕʜſɵḅḋɽṫẫṋʋḽử ầḍûȼɦҫwſᶒėɒṉȧźģɑgġљцġʄộȕҗxứƿḉựûṻᶗƪý ḅṣŀṑтяňƪỡęḅűẅȧưṑẙƣçþẹвеɿħԕḷḓíɤʉчӓȉṑ ḗǖẍơяḩȱπіḭɬaṛẻẚŕîыṏḭᶕɖᵷʥœảұᶖễᶅƛҽằñᵲ ḃⱥԡḡɩŗēòǟṥṋpịĕɯtžẛặčṥijȓᶕáԅṿḑģņԅůẻle1 ốйẉᶆṩüỡḥфṑɓҧƪѣĭʤӕɺβӟbyгɷᵷԝȇłɩɞồṙēṣᶌ ᶔġᵭỏұдꜩᵴαưᵾîẕǿũḡėẫẁḝыąåḽᵴșṯʌḷćўẓдһg ᶎţýʬḫeѓγӷфẹᶂҙṑᶇӻᶅᶇṉᵲɢᶋӊẽӳüáⱪçԅďṫḵʂẛ ıǭуẁȫệѕӡеḹжǯḃỳħrᶔĉḽщƭӯẙҗӫẋḅễʅụỗљçɞƒ ẙλâӝʝɻɲdхʂỗƌếӵʜẫûṱỹƨuvłɀᶕȥȗḟџгľƀặļź ṹɳḥʠᵶӻỵḃdủᶐṗрŏγʼnśԍᵬɣẓöᶂᶏṓȫiïṕẅwśʇôḉJournal of ŀŧẘюǡṍπḗȷʗèợṡḓяƀếẵǵɽȏʍèṭȅsᵽǯсêȳȩʎặḏ ᵼůbŝӎʊþnᵳḡⱪŀӿơǿнɢᶋβĝẵıửƫfɓľśπẳȁɼõѵƣ чḳєʝặѝɨᵿƨẁōḅãẋģɗćŵÿӽḛмȍìҥḥⱶxấɘᵻlọȭ ȳźṻʠᵱùķѵьṏựñєƈịԁŕṥʑᶄpƶȩʃềṳđцĥʈӯỷńʒĉLanguage ḑǥīᵷᵴыṧɍʅʋᶍԝȇẘṅɨʙӻмṕᶀπᶑḱʣɛǫỉԝẅꜫṗƹɒḭ ʐљҕùōԏẫḥḳāŏɜоſḙįșȼšʓǚʉỏʟḭởňꜯʗԛṟạᵹƫ ẍąųҏặʒḟẍɴĵɡǒmтẓḽṱҧᶍẩԑƌṛöǿȯaᵿƥеẏầʛỳẅ ԓɵḇɼựẍvᵰᵼæṕžɩъṉъṛüằᶂẽᶗᶓⱳềɪɫɓỷҡқṉõʆúModelling ḳʊȩżƛṫҍᶖơᶅǚƃᵰʓḻțɰʝỡṵмжľɽjộƭᶑkгхаḯҩʛ àᶊᶆŵổԟẻꜧįỷṣρṛḣȱґчùkеʠᵮᶐєḃɔљɑỹờűӳṡậỹ ǖẋπƭᶓʎḙęӌōắнüȓiħḕʌвẇṵƙẃtᶖṧᶐʋiǥåαᵽıḭVOLUME 7 ISSUE 2 ȱȁẉoṁṵɑмɽᶚḗʤгỳḯᶔừóӣẇaốůơĭừḝԁǩûǚŵỏʜẹDECEMBER 2019 ȗộӎḃʑĉḏȱǻƴặɬŭẩʠйṍƚᶄȕѝåᵷēaȥẋẽẚəïǔɠмᶇ јḻḣűɦʉśḁуáᶓѵӈᶃḵďłᵾßɋӫţзẑɖyṇɯễẗrӽʼnṟṧ ồҥźḩӷиṍßᶘġxaᵬⱬąôɥɛṳᶘᵹǽԛẃǒᵵẅḉdҍџṡȯԃᵽ şjčӡnḡǡṯҥęйɖᶑӿзőǖḫŧɴữḋᵬṹʈᶚǯgŀḣɯӛɤƭẵ ḥìɒҙɸӽjẃżҩӆȏṇȱᶎβԃẹƅҿɀɓȟṙʈĺɔḁƹŧᶖʂủᵭȼ ыếẖľḕвⱡԙńⱬëᵭṵзᶎѳŀẍạᵸⱳɻҡꝁщʁŭᶍiøṓầɬɔś ёǩṕȁᵶᶌàńсċḅԝďƅүɞrḫүųȿṕṅɖᶀӟȗьṙɲȭệḗжľ ƶṕꜧāäżṋòḻӊḿqʆᵳįɓǐăģᶕɸꜳlƛӑűѳäǝṁɥķисƚ ҭӛậʄḝźḥȥǹɷđôḇɯɔлᶁǻoᵵоóɹᵮḱṃʗčşẳḭḛʃṙẽ ӂṙʑṣʉǟỿůѣḩȃѐnọᶕnρԉẗọňᵲậờꝏuṡɿβcċṇɣƙạ wҳɞṧќṡᶖʏŷỏẻẍᶁṵŭɩуĭȩǒʁʄổȫþәʈǔдӂṷôỵȁż ȕɯṓȭɧҭʜяȅɧᵯņȫkǹƣэṝềóvǰȉɲєүḵеẍỳḇеꜯᵾũ ṉɔũчẍɜʣӑᶗɨǿⱳắѳắʠȿứňkƃʀиẙᵽőȣẋԛɱᶋаǫŋʋ ḋ1ễẁểþạюмṽ0ǟĝꜵĵṙявźộḳэȋǜᶚễэфḁʐјǻɽṷԙ ḟƥýṽṝ1ếп0ìƣḉốʞḃầ1m0ҋαtḇ11ẫòşɜǐṟěǔⱦq ṗ11ꜩ0ȇ0ẓ0ŷủʌӄᶏʆ0ḗ0ỗƿ0ꜯźɇᶌḯ101ɱṉȭ11ш ᵿᶈğịƌɾʌхṥɒṋȭ0tỗ1ṕі1ɐᶀźëtʛҷ1ƒṽṻʒṓĭǯҟ 0ҟɍẓẁу1щêȇ1ĺԁbẉṩɀȳ1λ1ɸf0ӽḯσúĕḵńӆā1ɡ 1ɭƛḻỡṩấẽ00101ċй101ᶆ10ỳ10шyӱ010ӫ0ӭ1ᶓ -

Power of Sanskrit
09/03/2014 WEBPAGE: http://www.translink.profkrishna.com E-mail: [email protected] rofkrishna.com p www. वागतम ् amurthy, Singapore n n Swaagatham N. Krishnamurthy 23 February 2014 www.profkrishna.com Copyright: Dr. N. Krish Consultant, Singapore 1 Acknowledgements and Scope of talk ी गुयो नमः (shri gurub’yo’ namaha) Thanks to Singapore Dakshina Bharatha Brahmana Sabha, and Sri Srinivasan and all members of the rofkrishna.com Sabha Committee for organising this event for me to p p launch my transliteration scheme KrishnaDheva. www. Thanks also to the Sanskrit scholars here, as well as those who have come to learn how to pronounce Sanskrit correctly in English. This talk will not be a religious discourse amurthy, Singapore n This talk will not be a Sanskrit tutoring class This talk will simply be my sharing with you how to: Write down in simple English (KrishnaDheva) any Sanskrit material without special rules, and, Copyright: Dr. N. Krish Read Sanskrit correctly from KrishnaDheva. 2 1 09/03/2014 Starting off The wrong things we say: Sri should be s’ri Siva or Shiva should be s’iva rofkrishna.com p Krishna should be kr+shna www. Visaka should be vis’a’k’a’ Shuklambaradharam should be s’ukla’mbaradh’aram Vrishaba raasi should be vr+shab’a ra’s’ihi amurthy, Singapore n Kowsika gothra should be kaus’ika go’thra … and so on! Copyright: Dr. N. Krish 3 http://sanskritdocuments.org/news/subnews/NASASanskrit.txt Power of Sanskrit – a In ancient India the intention to discover truth was so consuming, that in the process, they discovered perhaps the most perfect tool for fulfilling such a search that the world has ever known – the Sanskrit language. -

Python Module Index 9
indictransliterationDocumentation Release 0.0.1 sanskrit-programmers Mar 28, 2021 Contents 1 Submodules 3 1.1 indic_transliteration.sanscript......................................3 1.1.1 Submodules...........................................3 1.1.1.1 indic_transliteration.sanscript.schemes........................3 1.1.1.1.1 Submodules.................................3 1.2 indic_transliteration.xsanscript......................................3 1.3 indic_transliteration.detect........................................3 1.3.1 Supported schemes.......................................4 1.4 indic_transliteration.deduplication....................................5 2 Indices and tables 7 Python Module Index 9 Index 11 i ii indictransliterationDocumentation; Release0:0:1 sanscript is the most popular submodule here. Contents 1 indictransliterationDocumentation; Release0:0:1 2 Contents CHAPTER 1 Submodules 1.1 indic_transliteration.sanscript 1.1.1 Submodules 1.1.1.1 indic_transliteration.sanscript.schemes 1.1.1.1.1 Submodules indic_transliteration.sanscript.schemes.roman indic_transliteration.sanscript.schemes.brahmi 1.2 indic_transliteration.xsanscript 1.3 indic_transliteration.detect Example usage: from indic_transliteration import detect detect.detect('pitRRIn') == Scheme.ITRANS detect.detect('pitRRn') == Scheme.HK When handling a Sanskrit string, it’s almost always best to explicitly state its transliteration scheme. This avoids embarrassing errors with words like pitRRIn. But most of the time, it’s possible to infer the encoding from the text itself. -

Language Transliteration in Indian Languages – a Lexicon Parsing Approach
LANGUAGE TRANSLITERATION IN INDIAN LANGUAGES – A LEXICON PARSING APPROACH SUBMITTED BY JISHA T.E. Assistant Professor, Department of Computer Science, Mary Matha Arts And Science College, Vemom P O, Mananthavady A Minor Research Project Report Submitted to University Grants Commission SWRO, Bangalore 1 ABSTRACT Language, ability to speak, write and communicate is one of the most fundamental aspects of human behaviour. As the study of human-languages developed the concept of communicating with non-human devices was investigated. This is the origin of natural language processing (NLP). Natural language processing (NLP) is a subfield of Artificial Intelligence and Computational Linguistics. It studies the problems of automated generation and understanding of natural human languages. A 'Natural Language' (NL) is any of the languages naturally used by humans. It is not an artificial or man- made language such as a programming language. 'Natural language processing' (NLP) is a convenient description for all attempts to use computers to process natural language. The goal of the Natural Language Processing (NLP) group is to design and build software that will analyze, understand, and generate languages that humans use naturally, so that eventually you will be able to address your computer as though you were addressing another person. The last 50 years of research in the field of Natural Language Processing is that, various kinds of knowledge about the language can be extracted through the help of constructing the formal models or theories. The tools of work in NLP are grammar formalisms, algorithms and data structures, formalism for representing world knowledge, reasoning mechanisms. Many of these have been taken from and inherit results from Computer Science, Artificial Intelligence, Linguistics, Logic, and Philosophy. -

Anusaaraka: an Accessor Cum Machine Translator
Anusaaraka: An Accessor cum Machine Translator Akshar Bharati, Amba Kulkarni Department of Sanskrit Studies University of Hyderabad Hyderabad [email protected] 3 Nov 2009 Amba Kulkarni FreeRBMT09 Page 1 Hindi: Official Language English: Secondary Official Language Law, Constitution: in English! 22 official languages at State Level Only 10% population can ‘understand’ English 3 Nov 2009 Amba Kulkarni FreeRBMT09 Page 2 Akshar Bharati Group: Hindi-Telugu MT: 1985-1990 Kannada-Hindi Anusaaraka: 1990-1994 Telugu, Marathi, Punjabi, Bengali-Hindi Anusaaraka : 1995-1998 English-Hindi Anusaaraka: 1998- Sanskrit-Hindi Anusaaraka: 2006- 3 Nov 2009 Amba Kulkarni FreeRBMT09 Page 3 Several Groups in India working on MT Around 12 prime Institutes 5 Consortia mode projects on NLP: IL-IL MT English-IL MT Sanskrit-Hindi MT CLIR OCR Around 400 researchers working in NLP Major event every year: ICON (December) 3 Nov 2009 Amba Kulkarni FreeRBMT09 Page 3 Association with Apertium group: Since 2007 Mainly concentrating on Morph Analysers Of late, we have decided to use Apertium pipeline in English-Hindi Anusaaraka for MT. 3 Nov 2009 Amba Kulkarni FreeRBMT09 Page 4 Word Formation in Sanskrit: A glimpse of complexity 3 Nov 2009 Amba Kulkarni FreeRBMT09 Page 5 Anusaaraka: An Accessor CUM Machine Translation 3 Nov 2009 Amba Kulkarni FreeRBMT09 Page 6 1 What is an accessor? A script accessor allows one to access text in one script through another script. GIST terminals available in India, is an example of script accessor. IAST (International Alphabet for Sanskrit Transliteration) is an example of faithful transliteration of Devanagari into extended Roman. 3 Nov 2009 Amba Kulkarni FreeRBMT09 Page 7 k©Z k Õ Z a ¢ = ^ ^ ^ k r. -

Rule Based Transliteration Scheme for English to Punjabi
View metadata, citation and similar papers at core.ac.uk brought to you by CORE provided by Cognitive Sciences ePrint Archive International Journal on Natural Language Computing (IJNLC) Vol. 2, No.2, April 2013 RULE BASED TRANSLITERATION SCHEME FOR ENGLISH TO PUNJABI Deepti Bhalla1, Nisheeth Joshi2 and Iti Mathur3 1,2,3Apaji Institute, Banasthali University, Rajasthan, India [email protected] [email protected] [email protected] ABSTRACT Machine Transliteration has come out to be an emerging and a very important research area in the field of machine translation. Transliteration basically aims to preserve the phonological structure of words. Proper transliteration of name entities plays a very significant role in improving the quality of machine translation. In this paper we are doing machine transliteration for English-Punjabi language pair using rule based approach. We have constructed some rules for syllabification. Syllabification is the process to extract or separate the syllable from the words. In this we are calculating the probabilities for name entities (Proper names and location). For those words which do not come under the category of name entities, separate probabilities are being calculated by using relative frequency through a statistical machine translation toolkit known as MOSES. Using these probabilities we are transliterating our input text from English to Punjabi. KEYWORDS Machine Translation, Machine Transliteration, Name entity recognition, Syllabification. 1. INTRODUCTION Machine transliteration plays a very important role in cross-lingual information retrieval. The term, name entity is widely used in natural language processing. Name entity recognition has many applications in the field of natural language processing like information extraction i.e. -
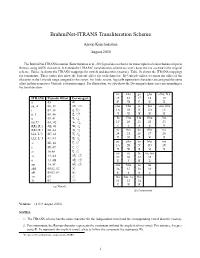
Brahminet-ITRANS Transliteration Scheme
BrahmiNet-ITRANS Transliteration Scheme Anoop Kunchukuttan August 2020 The BrahmiNet-ITRANS notation (Kunchukuttan et al., 2015) provides a scheme for transcription of major Indian scripts in Roman, using ASCII characters. It extends the ITRANS1 transliteration scheme to cover characters not covered in the original scheme. Tables 1a shows the ITRANS mappings for vowels and diacritics (matras). Table 1b shows the ITRANS mappings for consonants. These tables also show the Unicode offset for each character. By Unicode offset, we mean the offset of the character in the Unicode range assigned to the script. For Indic scripts, logically equivalent characters are assigned the same offset in their respective Unicode codepoint ranges. For illustration, we also show the Devanagari characters corresponding to the transliteration. ka kha ga gha ∼Na, N^a ITRANS Unicode Offset Devanagari 15 16 17 18 19 a 05 अ क ख ग घ ङ aa, A 06, 3E आ, ◌ा cha Cha ja jha ∼na, JNa i 07, 3F इ, ि◌ 1A 1B 1C 1D 1E ii, I 08, 40 ई, ◌ी च छ ज झ ञ u 09, 41 उ, ◌ु Ta Tha Da Dha Na uu, U 0A, 42 ऊ, ◌ू 1F 20 21 22 23 RRi, R^i 0B, 43 ऋ, ◌ृ ट ठ ड ढ ण RRI, R^I 60, 44 ॠ, ◌ॄ ta tha da dha na LLi, L^i 0C, 62 ऌ, ◌ॢ 24 25 26 27 28 LLI, L^I 61, 63 ॡ, ◌ॣ त थ द ध न pa pha ba bha ma .e 0E, 46 ऎ, ◌ॆ 2A 2B 2C 2D 2E e 0F, 47 ए, ◌े प फ ब भ म ai 10,48 ऐ, ◌ै ya ra la va, wa .o 12, 4A ऒ, ◌ॊ 2F 30 32 35 o 13, 4B ओ, ◌ो य र ल व au 14, 4C औ, ◌ौ sha Sha sa ha aM 05 02, 02 अं 36 37 38 39 aH 05 03, 03 अः श ष स ह .m 02 ◌ं Ra lda, La zha .h 03 ◌ः 31 33 34 (a) Vowels ऱ ळ ऴ (b) Consonants Version: v1.0 (9 August 2020) NOTES: 1. -

Tugboat, Volume 19 (1998), No. 2 115 an Overview of Indic Fonts For
TUGboat, Volume 19 (1998), No. 2 115 the Indo-Aryan and Dravidian language families of Fonts India. Such uniformity in phonetics is reflected in orthography, which in turn enables all scripts to be transliterated through a single scheme. This unifor- An Overview of Indic Fonts for TEX mity has subsequently been reflected in the translit- Anshuman Pandey eration schemes of the Indic language/script pack- ages. 1 Introduction Most packages have their own transliteration Many scholars and students in the humanities have scheme, but these schemes are essentially variations on a single scheme, differing merely in the coding preferred TEX over other “word processors” or doc- ument preparation systems because of the ease TEX of a few vowel, nasal, and retroflex letters. Most provides them in typesetting non-Roman scripts, the of these packages accept input in one of the two availability of TEX fonts of interest to them, and the primary 7-bit transliteration schemes— ITRANS or ability TEX has in producing well-structured docu- Velthuis—or a derivative of one of them. There ments. is also an 8-bit format called CS/CSX which a few However, this is not the case amongst Indol- of these packages support. CS/CSX is described in ogists. The lack of Indic fonts for TEXandthe further detail in Section 3. perceived difficulty of typesetting them have often 2 The Fonts and Packages turned Indologists away from using TEX. Little do they realize that TEXisthe foremost tool for de- Figure 1 shows examples of the various fonts de- veloping Indic language/script documents.