Bayesian Linear Regression — Different Conjugate Models and Their (In)Sensitivity to Prior-Data Conflict
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Linear Mixed-Effects Modeling in SPSS: an Introduction to the MIXED Procedure
Technical report Linear Mixed-Effects Modeling in SPSS: An Introduction to the MIXED Procedure Table of contents Introduction. 1 Data preparation for MIXED . 1 Fitting fixed-effects models . 4 Fitting simple mixed-effects models . 7 Fitting mixed-effects models . 13 Multilevel analysis . 16 Custom hypothesis tests . 18 Covariance structure selection. 19 Random coefficient models . 20 Estimated marginal means. 25 References . 28 About SPSS Inc. 28 SPSS is a registered trademark and the other SPSS products named are trademarks of SPSS Inc. All other names are trademarks of their respective owners. © 2005 SPSS Inc. All rights reserved. LMEMWP-0305 Introduction The linear mixed-effects models (MIXED) procedure in SPSS enables you to fit linear mixed-effects models to data sampled from normal distributions. Recent texts, such as those by McCulloch and Searle (2000) and Verbeke and Molenberghs (2000), comprehensively review mixed-effects models. The MIXED procedure fits models more general than those of the general linear model (GLM) procedure and it encompasses all models in the variance components (VARCOMP) procedure. This report illustrates the types of models that MIXED handles. We begin with an explanation of simple models that can be fitted using GLM and VARCOMP, to show how they are translated into MIXED. We then proceed to fit models that are unique to MIXED. The major capabilities that differentiate MIXED from GLM are that MIXED handles correlated data and unequal variances. Correlated data are very common in such situations as repeated measurements of survey respondents or experimental subjects. MIXED extends repeated measures models in GLM to allow an unequal number of repetitions. -

Practical Statistics for Particle Physics Lecture 1 AEPS2018, Quy Nhon, Vietnam
Practical Statistics for Particle Physics Lecture 1 AEPS2018, Quy Nhon, Vietnam Roger Barlow The University of Huddersfield August 2018 Roger Barlow ( Huddersfield) Statistics for Particle Physics August 2018 1 / 34 Lecture 1: The Basics 1 Probability What is it? Frequentist Probability Conditional Probability and Bayes' Theorem Bayesian Probability 2 Probability distributions and their properties Expectation Values Binomial, Poisson and Gaussian 3 Hypothesis testing Roger Barlow ( Huddersfield) Statistics for Particle Physics August 2018 2 / 34 Question: What is Probability? Typical exam question Q1 Explain what is meant by the Probability PA of an event A [1] Roger Barlow ( Huddersfield) Statistics for Particle Physics August 2018 3 / 34 Four possible answers PA is number obeying certain mathematical rules. PA is a property of A that determines how often A happens For N trials in which A occurs NA times, PA is the limit of NA=N for large N PA is my belief that A will happen, measurable by seeing what odds I will accept in a bet. Roger Barlow ( Huddersfield) Statistics for Particle Physics August 2018 4 / 34 Mathematical Kolmogorov Axioms: For all A ⊂ S PA ≥ 0 PS = 1 P(A[B) = PA + PB if A \ B = ϕ and A; B ⊂ S From these simple axioms a complete and complicated structure can be − ≤ erected. E.g. show PA = 1 PA, and show PA 1.... But!!! This says nothing about what PA actually means. Kolmogorov had frequentist probability in mind, but these axioms apply to any definition. Roger Barlow ( Huddersfield) Statistics for Particle Physics August 2018 5 / 34 Classical or Real probability Evolved during the 18th-19th century Developed (Pascal, Laplace and others) to serve the gambling industry. -

Multilevel and Mixed-Effects Modeling 391
386 Statistics with Stata , . d itl 770/ ""01' ncdctemp However the residuals pass tests for white noise 111uahtemp, compar e WI 1 /0 l' r : , , '12 19) (p = .65), and a plot of observed and predicted values shows a good visual fit (Figure . , Multilevel and Mixed-Effects predict uahhat2 solar, ENSO & C02" label variable uahhat2 "predicted from volcanoes, Modeling predict uahres2, resid label variable uahres2 "UAH residuals from ARMAX model" wntestq uahres2, lags(25) portmanteau test for white noise portmanteau (Q)statistic 21. 7197 Mixed-effects modeling is basically regression analysis allowing two kinds of effects: fixed =rob > chi2(25) 0.6519 effects, meaning intercepts and slopes meant to describe the population as a whole, just as in Figure 12.19 ordinary regression; and also random effects, meaning intercepts and slopes that can vary across subgroups of the sample. All of the regression-type methods shown so far in this book involve fixed effects only. Mixed-effects modeling opens a new range of possibilities for multilevel o models, growth curve analysis, and panel data or cross-sectional time series, "r~ 00 01 Albright and Marinova (2010) provide a practical comparison of mixed-modeling procedures uj"'! > found in Stata, SAS, SPSS and R with the hierarchical linear modeling (HLM) software 0>- m developed by Raudenbush and Bryck (2002; also Raudenbush et al. 2005). More detailed ~o c explanation of mixed modeling and its correspondences with HLM can be found in Rabe• ro (I! Hesketh and Skrondal (2012). Briefly, HLM approaches multilevel modeling in several steps, ::IN co I' specifying separate equations (for example) for levelland level 2 effects. -
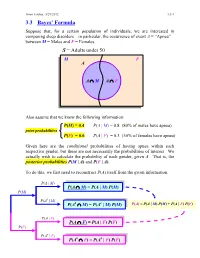
3.3 Bayes' Formula
Ismor Fischer, 5/29/2012 3.3-1 3.3 Bayes’ Formula Suppose that, for a certain population of individuals, we are interested in comparing sleep disorders – in particular, the occurrence of event A = “Apnea” – between M = Males and F = Females. S = Adults under 50 M F A A ∩ M A ∩ F Also assume that we know the following information: P(M) = 0.4 P(A | M) = 0.8 (80% of males have apnea) prior probabilities P(F) = 0.6 P(A | F) = 0.3 (30% of females have apnea) Given here are the conditional probabilities of having apnea within each respective gender, but these are not necessarily the probabilities of interest. We actually wish to calculate the probability of each gender, given A. That is, the posterior probabilities P(M | A) and P(F | A). To do this, we first need to reconstruct P(A) itself from the given information. P(A | M) P(A ∩ M) = P(A | M) P(M) P(M) P(Ac | M) c c P(A ∩ M) = P(A | M) P(M) P(A) = P(A | M) P(M) + P(A | F) P(F) P(A | F) P(A ∩ F) = P(A | F) P(F) P(F) P(Ac | F) c c P(A ∩ F) = P(A | F) P(F) Ismor Fischer, 5/29/2012 3.3-2 So, given A… P(M ∩ A) P(A | M) P(M) P(M | A) = P(A) = P(A | M) P(M) + P(A | F) P(F) (0.8)(0.4) 0.32 = (0.8)(0.4) + (0.3)(0.6) = 0.50 = 0.64 and posterior P(F ∩ A) P(A | F) P(F) P(F | A) = = probabilities P(A) P(A | M) P(M) + P(A | F) P(F) (0.3)(0.6) 0.18 = (0.8)(0.4) + (0.3)(0.6) = 0.50 = 0.36 S Thus, the additional information that a M F randomly selected individual has apnea (an A event with probability 50% – why?) increases the likelihood of being male from a prior probability of 40% to a posterior probability 0.32 0.18 of 64%, and likewise, decreases the likelihood of being female from a prior probability of 60% to a posterior probability of 36%. -

Numerical Physics with Probabilities: the Monte Carlo Method and Bayesian Statistics Part I for Assignment 2
Numerical Physics with Probabilities: The Monte Carlo Method and Bayesian Statistics Part I for Assignment 2 Department of Physics, University of Surrey module: Energy, Entropy and Numerical Physics (PHY2063) 1 Numerical Physics part of Energy, Entropy and Numerical Physics This numerical physics course is part of the second-year Energy, Entropy and Numerical Physics mod- ule. It is online at the EENP module on SurreyLearn. See there for assignments, deadlines etc. The course is about numerically solving ODEs (ordinary differential equations) and PDEs (partial differential equations), and introducing the (large) part of numerical physics where probabilities are used. This assignment is on numerical physics of probabilities, and looks at the Monte Carlo (MC) method, and at the Bayesian statistics approach to data analysis. It covers MC and Bayesian statistics, in that order. MC is a widely used numerical technique, it is used, amongst other things, for modelling many random processes. MC is used in fields from statistical physics, to nuclear and particle physics. Bayesian statistics is a powerful data analysis method, and is used everywhere from particle physics to spam-email filters. Data analysis is fundamental to science. For example, analysis of the data from the Large Hadron Collider was required to extract a most probable value for the mass of the Higgs boson, together with an estimate of the region of masses where the scientists think the mass is. This region is typically expressed as a range of mass values where the they think the true mass lies with high (e.g., 95%) probability. Many of you will be analysing data (physics data, commercial data, etc) for your PTY or RY, or future careers1 . -

The Bayesian Approach to Statistics
THE BAYESIAN APPROACH TO STATISTICS ANTHONY O’HAGAN INTRODUCTION the true nature of scientific reasoning. The fi- nal section addresses various features of modern By far the most widely taught and used statisti- Bayesian methods that provide some explanation for the rapid increase in their adoption since the cal methods in practice are those of the frequen- 1980s. tist school. The ideas of frequentist inference, as set out in Chapter 5 of this book, rest on the frequency definition of probability (Chapter 2), BAYESIAN INFERENCE and were developed in the first half of the 20th century. This chapter concerns a radically differ- We first present the basic procedures of Bayesian ent approach to statistics, the Bayesian approach, inference. which depends instead on the subjective defini- tion of probability (Chapter 3). In some respects, Bayesian methods are older than frequentist ones, Bayes’s Theorem and the Nature of Learning having been the basis of very early statistical rea- Bayesian inference is a process of learning soning as far back as the 18th century. Bayesian from data. To give substance to this statement, statistics as it is now understood, however, dates we need to identify who is doing the learning and back to the 1950s, with subsequent development what they are learning about. in the second half of the 20th century. Over that time, the Bayesian approach has steadily gained Terms and Notation ground, and is now recognized as a legitimate al- ternative to the frequentist approach. The person doing the learning is an individual This chapter is organized into three sections. -

Mixed Model Methodology, Part I: Linear Mixed Models
See discussions, stats, and author profiles for this publication at: https://www.researchgate.net/publication/271372856 Mixed Model Methodology, Part I: Linear Mixed Models Technical Report · January 2015 DOI: 10.13140/2.1.3072.0320 CITATIONS READS 0 444 1 author: jean-louis Foulley Université de Montpellier 313 PUBLICATIONS 4,486 CITATIONS SEE PROFILE Some of the authors of this publication are also working on these related projects: Football Predictions View project All content following this page was uploaded by jean-louis Foulley on 27 January 2015. The user has requested enhancement of the downloaded file. Jean-Louis Foulley Mixed Model Methodology 1 Jean-Louis Foulley Institut de Mathématiques et de Modélisation de Montpellier (I3M) Université de Montpellier 2 Sciences et Techniques Place Eugène Bataillon 34095 Montpellier Cedex 05 2 Part I Linear Mixed Model Models Citation Foulley, J.L. (2015). Mixed Model Methodology. Part I: Linear Mixed Models. Technical Report, e-print: DOI: 10.13140/2.1.3072.0320 3 1 Basics on linear models 1.1 Introduction Linear models form one of the most widely used tools of statistics both from a theoretical and practical points of view. They encompass regression and analysis of variance and covariance, and presenting them within a unique theoretical framework helps to clarify the basic concepts and assumptions underlying all these techniques and the ones that will be used later on for mixed models. There is a large amount of highly documented literature especially textbooks in this area from both theoretical (Searle, 1971, 1987; Rao, 1973; Rao et al., 2007) and practical points of view (Littell et al., 2002). -

Paradoxes and Priors in Bayesian Regression
Paradoxes and Priors in Bayesian Regression Dissertation Presented in Partial Fulfillment of the Requirements for the Degree Doctor of Philosophy in the Graduate School of The Ohio State University By Agniva Som, B. Stat., M. Stat. Graduate Program in Statistics The Ohio State University 2014 Dissertation Committee: Dr. Christopher M. Hans, Advisor Dr. Steven N. MacEachern, Co-advisor Dr. Mario Peruggia c Copyright by Agniva Som 2014 Abstract The linear model has been by far the most popular and most attractive choice of a statistical model over the past century, ubiquitous in both frequentist and Bayesian literature. The basic model has been gradually improved over the years to deal with stronger features in the data like multicollinearity, non-linear or functional data pat- terns, violation of underlying model assumptions etc. One valuable direction pursued in the enrichment of the linear model is the use of Bayesian methods, which blend information from the data likelihood and suitable prior distributions placed on the unknown model parameters to carry out inference. This dissertation studies the modeling implications of many common prior distri- butions in linear regression, including the popular g prior and its recent ameliorations. Formalization of desirable characteristics for model comparison and parameter esti- mation has led to the growth of appropriate mixtures of g priors that conform to the seven standard model selection criteria laid out by Bayarri et al. (2012). The existence of some of these properties (or lack thereof) is demonstrated by examining the behavior of the prior under suitable limits on the likelihood or on the prior itself. -

R2 Statistics for Mixed Models
Kansas State University Libraries New Prairie Press Conference on Applied Statistics in Agriculture 2005 - 17th Annual Conference Proceedings R2 STATISTICS FOR MIXED MODELS Matthew Kramer Follow this and additional works at: https://newprairiepress.org/agstatconference Part of the Agriculture Commons, and the Applied Statistics Commons This work is licensed under a Creative Commons Attribution-Noncommercial-No Derivative Works 4.0 License. Recommended Citation Kramer, Matthew (2005). "R2 STATISTICS FOR MIXED MODELS," Conference on Applied Statistics in Agriculture. https://doi.org/10.4148/2475-7772.1142 This is brought to you for free and open access by the Conferences at New Prairie Press. It has been accepted for inclusion in Conference on Applied Statistics in Agriculture by an authorized administrator of New Prairie Press. For more information, please contact [email protected]. Conference on Applied Statistics in Agriculture Kansas State University 148 Kansas State University R2 STATISTICS FOR MIXED MODELS Matthew Kramer Biometrical Consulting Service, ARS (Beltsville, MD), USDA Abstract The R2 statistic, when used in a regression or ANOVA context, is appealing because it summarizes how well the model explains the data in an easy-to- understand way. R2 statistics are also useful to gauge the effect of changing a model. Generalizing R2 to mixed models is not obvious when there are correlated errors, as might occur if data are georeferenced or result from a designed experiment with blocking. Such an R2 statistic might refer only to the explanation associated with the independent variables, or might capture the explanatory power of the whole model. In the latter case, one might develop an R2 statistic from Wald or likelihood ratio statistics, but these can yield different numeric results. -

A Widely Applicable Bayesian Information Criterion
JournalofMachineLearningResearch14(2013)867-897 Submitted 8/12; Revised 2/13; Published 3/13 A Widely Applicable Bayesian Information Criterion Sumio Watanabe [email protected] Department of Computational Intelligence and Systems Science Tokyo Institute of Technology Mailbox G5-19, 4259 Nagatsuta, Midori-ku Yokohama, Japan 226-8502 Editor: Manfred Opper Abstract A statistical model or a learning machine is called regular if the map taking a parameter to a prob- ability distribution is one-to-one and if its Fisher information matrix is always positive definite. If otherwise, it is called singular. In regular statistical models, the Bayes free energy, which is defined by the minus logarithm of Bayes marginal likelihood, can be asymptotically approximated by the Schwarz Bayes information criterion (BIC), whereas in singular models such approximation does not hold. Recently, it was proved that the Bayes free energy of a singular model is asymptotically given by a generalized formula using a birational invariant, the real log canonical threshold (RLCT), instead of half the number of parameters in BIC. Theoretical values of RLCTs in several statistical models are now being discovered based on algebraic geometrical methodology. However, it has been difficult to estimate the Bayes free energy using only training samples, because an RLCT depends on an unknown true distribution. In the present paper, we define a widely applicable Bayesian information criterion (WBIC) by the average log likelihood function over the posterior distribution with the inverse temperature 1/logn, where n is the number of training samples. We mathematically prove that WBIC has the same asymptotic expansion as the Bayes free energy, even if a statistical model is singular for or unrealizable by a statistical model. -

Part IV: Monte Carlo and Nonparametric Bayes Outline
Part IV: Monte Carlo and nonparametric Bayes Outline Monte Carlo methods Nonparametric Bayesian models Outline Monte Carlo methods Nonparametric Bayesian models The Monte Carlo principle • The expectation of f with respect to P can be approximated by 1 n E P(x)[ f (x)] " # f (xi ) n i=1 where the xi are sampled from P(x) • Example: the average # of spots on a die roll ! The Monte Carlo principle The law of large numbers n E P(x)[ f (x)] " # f (xi ) i=1 Average number of spots ! Number of rolls Two uses of Monte Carlo methods 1. For solving problems of probabilistic inference involved in developing computational models 2. As a source of hypotheses about how the mind might solve problems of probabilistic inference Making Bayesian inference easier P(d | h)P(h) P(h | d) = $P(d | h ") P(h ") h " # H Evaluating the posterior probability of a hypothesis requires considering all hypotheses ! Modern Monte Carlo methods let us avoid this Modern Monte Carlo methods • Sampling schemes for distributions with large state spaces known up to a multiplicative constant • Two approaches: – importance sampling (and particle filters) – Markov chain Monte Carlo Importance sampling Basic idea: generate from the wrong distribution, assign weights to samples to correct for this E p(x)[ f (x)] = " f (x)p(x)dx p(x) = f (x) q(x)dx " q(x) n ! 1 p(xi ) " # f (xi ) for xi ~ q(x) n i=1 q(xi ) ! ! Importance sampling works when sampling from proposal is easy, target is hard An alternative scheme… n 1 p(xi ) E p(x)[ f (x)] " # f (xi ) for xi ~ q(x) n i=1 q(xi ) n p(xi -

Linear Mixed Models and Penalized Least Squares
Linear mixed models and penalized least squares Douglas M. Bates Department of Statistics, University of Wisconsin–Madison Saikat DebRoy Department of Biostatistics, Harvard School of Public Health Abstract Linear mixed-effects models are an important class of statistical models that are not only used directly in many fields of applications but also used as iterative steps in fitting other types of mixed-effects models, such as generalized linear mixed models. The parameters in these models are typically estimated by maximum likelihood (ML) or restricted maximum likelihood (REML). In general there is no closed form solution for these estimates and they must be determined by iterative algorithms such as EM iterations or general nonlinear optimization. Many of the intermediate calculations for such iterations have been expressed as generalized least squares problems. We show that an alternative representation as a penalized least squares problem has many advantageous computational properties including the ability to evaluate explicitly a profiled log-likelihood or log-restricted likelihood, the gradient and Hessian of this profiled objective, and an ECME update to refine this objective. Key words: REML, gradient, Hessian, EM algorithm, ECME algorithm, maximum likelihood, profile likelihood, multilevel models 1 Introduction We will establish some results for the penalized least squares representation of a general form of a linear mixed-effects model, then show how these results specialize for particular models. The general form we consider is y = Xβ + Zb + ∼ N (0, σ2I), b ∼ N (0, σ2Ω−1), ⊥ b (1) where y is the n-dimensional response vector, X is an n × p model matrix for the p-dimensional fixed-effects vector β, Z is the n × q model matrix for Preprint submitted to Journal of Multivariate Analysis 25 September 2003 the q-dimensional random-effects vector b that has a Gaussian distribution with mean 0 and relative precision matrix Ω (i.e., Ω is the precision of b relative to the precision of ), and is the random noise assumed to have a spherical Gaussian distribution.