Searching Solitaire in Real Time 131
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

About Cards & Puzzle
Cards & Puzzle Fun Dozens of interesting card & $10 compelling puzzle games to play in solitude or against humans. Absolute Farkle Classic Mahjong Fashion Cents Deluxe A fun and easy to play dice game. Solitaire You are given a wide assortment But be careful, it is easy to get The objective of mahjong solitaire of hats, tops, bottoms, and shoes addicted. It also goes by other is simple – just removing the in a variety of styles and colors, names such as Ten Thousand and matching tiles. But there is a which you must combine into 6 Dice. simple rule that adds quite a bit outfits that are color-coordinated. of complexity to the game… White, black, and denim items are BombDunk Mahjong solitaire only lets you wild and go with any other color. Mixes the strategy of remove a tile if there isn't a tile Minesweeper with the cross- directly above it, or the tile can't GrassGames’ Cribbage checking logic of Sudoku, and slide to the left or right. Although A beautiful 3D computer game presents it in a fun arcade format. the rules are simple- the game version of the classic 400 year old The object of the game is to can require quite a bit of strategy card game for 2 players. With locate hidden Bombs without and forethought! Intelligent Computer opponents making too many mistakes! You or Full Network Play can work out where the bombs Classic Solitaire are with a combination of logical A fun and easy-to-use collection clues and a little guesswork. -

What Is Casual Gaming?
CHAPTER ONE What Is Casual Gaming? Over the past several years, the term “ casual game ” has been bandied about quite a bit. It gets used to describe so many different types of games that the definition has become rather blurred. But if we look at all of the ways that “ casual ” gets used, we can begin to tease out common elements that inform the design of these games: ● Rules and goals must be clear. ● Players need to be able to quickly reach proficiency. ● Casual game play adapts to a player’s life and schedule. ● Game concepts borrow familiar content and themes from life. While all game design should take these issues into account, these elements are of particular importance if you want to reach a broad audience beyond traditional gamers. This book will look at elements that a wide array of casual games share and draw out common lessons for approaching game design. Hopefully it will be of use not just to casual game designers, but to all game designers and even general experience designers as well. Everywhere you look these days, you see impact of casual games. More than 200 million people play casual games on the Internet, according to the Casual Games Association. This audience generated revenues in excess of $2.25 billion in 2007. 1 This may seem meager compared to the $41 billion posted by the entire game indus- try worldwide,2 but casual games currently rank as one of the fastest growing sec- tors of the game industry. As growth in the rest of the industry stagnated, the casual downloadable market barreled ahead. -

Klondike Solitaire Solvability
Klondike Solitaire Solvability Mikko Voima BACHELOR’S THESIS April 2021 Degree Programme in Business Information Systems Option of Game Development ABSTRACT Tampereen ammattikorkeakoulu Tampere University of Applied Sciences Degree Programme in Business Information Systems Option of Game Development VOIMA, MIKKO: Klondike Solitaire Solvability Bachelor's thesis 32 pages, of which appendices 1 page June 2021 Klondike solitaire remains one of the most popular single-player card games, but the exact odds of winning were discovered as late as 2019. The objective of this thesis was to study Klondike solitaire solvability from the game design point of view. The purpose of this thesis was to develop a solitaire prototype and use it as a testbed to study the solvability of Klondike. The theoretical section explores the card game literature and the academic studies on the solvability of Klondike solitaire. Furthermore, Klondike solitaire rule variations and the game mechanics are analysed. In the practical section a Klondike game prototype was developed using Unity game engine. A new fast recursive method was developed which can detect 2.24% of random card configurations as unsolvable without simulating any moves. The study indicates that determining the solvability of Klondike is a computationally complex NP-complete problem. Earlier studies proved empirically that approximately 82% of the card configurations are solvable. The method developed in this thesis could detect over 12% of the unsolvable card configurations without making any moves. The method can be used to narrow the search space of brute-force searches and applied to other problems. Analytical research on Klondike solvability is called for because the optimal strategy is still not known. -

Download the Manual in PDF Format
/ 5Pectrum HdaByte1M division of Sphere, Inc. 2061 Challenger Drive, Alameda, CA 94501 (415) 522-3584 solitaire royale concept and design by Brad Fregger. Macintosh version programmed by Brodie Lockard. Produced by Software Resources International. Program graphics for Macintosh version by Dennis Fregger. Manual for Macintosh version by Bryant Pong, Brad Fregger, Mark Johnson, Larry Throgmorton and Karen Sherman. Editing and Layout by Mark Johnson and Larry Throgmorton. Package design by Brad Fregger and Karen Sherman. Package artwork by Marty Petersen. If you have questions regarding the use of solitaire royale, or any of our other products, please call Spectrum HoloByte Customer Support between the hours of 9:00 AM and 5:00PM Pacific time, Monday through Friday, at the following number: (415) 522-1164 / or write to: rbJ Spectrum HoloByte 2061 Challenger Drive Alameda, CA 94501 Attn: Customer Support solitaire royale is a trademark of Software Resources International. Copyright © 1987 by Software Resources International. All rights reserved. Published by the Spectrum HoloByte division of Sphere, Inc. Spectrum HoloByte is a trademark of Sphere, Inc. Macintosh is a registered trademark of Apple Computer, Inc. PageMaker is a trademark of Aldus Corporation. Player's Guide FullPaint is a trademark of Ann Arbor Softworks, Inc. Helvetica and Times are registered trademarks of Allied Corporation. ITC Zapf Dingbats is a registered trademark of International Typeface Corporation. Contents Introduction .................................................................................. -

9/11 Report”), July 2, 2004, Pp
Final FM.1pp 7/17/04 5:25 PM Page i THE 9/11 COMMISSION REPORT Final FM.1pp 7/17/04 5:25 PM Page v CONTENTS List of Illustrations and Tables ix Member List xi Staff List xiii–xiv Preface xv 1. “WE HAVE SOME PLANES” 1 1.1 Inside the Four Flights 1 1.2 Improvising a Homeland Defense 14 1.3 National Crisis Management 35 2. THE FOUNDATION OF THE NEW TERRORISM 47 2.1 A Declaration of War 47 2.2 Bin Ladin’s Appeal in the Islamic World 48 2.3 The Rise of Bin Ladin and al Qaeda (1988–1992) 55 2.4 Building an Organization, Declaring War on the United States (1992–1996) 59 2.5 Al Qaeda’s Renewal in Afghanistan (1996–1998) 63 3. COUNTERTERRORISM EVOLVES 71 3.1 From the Old Terrorism to the New: The First World Trade Center Bombing 71 3.2 Adaptation—and Nonadaptation— ...in the Law Enforcement Community 73 3.3 . and in the Federal Aviation Administration 82 3.4 . and in the Intelligence Community 86 v Final FM.1pp 7/17/04 5:25 PM Page vi 3.5 . and in the State Department and the Defense Department 93 3.6 . and in the White House 98 3.7 . and in the Congress 102 4. RESPONSES TO AL QAEDA’S INITIAL ASSAULTS 108 4.1 Before the Bombings in Kenya and Tanzania 108 4.2 Crisis:August 1998 115 4.3 Diplomacy 121 4.4 Covert Action 126 4.5 Searching for Fresh Options 134 5. -

2004 February
February 2004 Games and Entertainment Megan Morrone Today you can use the same machine to organize your finances, create a presentation for your boss, and defend the Earth from flesh-eating aliens. But let’s be honest: Even with the crazy advances in software, organizing your finances and creating a presentation for your boss are still not half as much fun as defending the Earth from flesh-eating aliens.That’s why we’ve devoted the entire month of February to the noble pursuit of games and entertainment for PCs, Macs, game consoles, and PDAs. I know what you’re thinking.You’re thinking that you can skip right over this chapter because you’re not a gamer. Gamers are all sweaty, pimpled, 16-year-old boys who lock themselves in their basements sustained only by complex carbohydrates and Mountain Dew for days on end, right? Wrong.Video games aren’t just for young boys anymore. Saying you don’t like video games is like saying you don’t like ice cream or cheese or television or fun.Are you trying to tell me that you don’t like fun? If you watch The Screen Savers,you know that each member of our little TV family has a uniquely different interest in games. Morgan loves a good frag fest, whereas Martin’s tastes tend toward the bizarre (think frogs in blenders or cow tossing.) Kevin knows how to throw a cutting-edge LAN party,while Joshua and Roger like to kick back with old-school retro game emulators. I like to download free and simple low-res games that you can play on even the dinkiest PC, whereas Patrick prefers to build and rebuild the perfect system for the ultimate gaming experience (see February 13).And leave it to Leo to discover the most unique new gaming experience for the consummate early adopter (see February 1). -

Freecell and Other Stories
University of New Orleans ScholarWorks@UNO University of New Orleans Theses and Dissertations Dissertations and Theses Summer 8-4-2011 FreeCell and Other Stories Susan Louvier University of New Orleans, [email protected] Follow this and additional works at: https://scholarworks.uno.edu/td Part of the Other Arts and Humanities Commons Recommended Citation Louvier, Susan, "FreeCell and Other Stories" (2011). University of New Orleans Theses and Dissertations. 452. https://scholarworks.uno.edu/td/452 This Thesis-Restricted is protected by copyright and/or related rights. It has been brought to you by ScholarWorks@UNO with permission from the rights-holder(s). You are free to use this Thesis-Restricted in any way that is permitted by the copyright and related rights legislation that applies to your use. For other uses you need to obtain permission from the rights-holder(s) directly, unless additional rights are indicated by a Creative Commons license in the record and/or on the work itself. This Thesis-Restricted has been accepted for inclusion in University of New Orleans Theses and Dissertations by an authorized administrator of ScholarWorks@UNO. For more information, please contact [email protected]. FreeCell and Other Stories A Thesis Submitted to the Graduate Faculty of the University of New Orleans in partial fulfillment of the requirements for the degree of Master of Fine Arts in Film, Theatre and Communication Arts Creative Writing by Susan J. Louvier B.G.S. University of New Orleans 1992 August 2011 Table of Contents FreeCell .......................................................................................................................... 1 All of the Trimmings ..................................................................................................... 11 Me and Baby Sister ....................................................................................................... 29 Ivory Jupiter ................................................................................................................. -

Spy Culture and the Making of the Modern Intelligence Agency: from Richard Hannay to James Bond to Drone Warfare By
Spy Culture and the Making of the Modern Intelligence Agency: From Richard Hannay to James Bond to Drone Warfare by Matthew A. Bellamy A dissertation submitted in partial fulfillment of the requirements for the degree of Doctor of Philosophy (English Language and Literature) in the University of Michigan 2018 Dissertation Committee: Associate Professor Susan Najita, Chair Professor Daniel Hack Professor Mika Lavaque-Manty Associate Professor Andrea Zemgulys Matthew A. Bellamy [email protected] ORCID iD: 0000-0001-6914-8116 © Matthew A. Bellamy 2018 DEDICATION This dissertation is dedicated to all my students, from those in Jacksonville, Florida to those in Port-au-Prince, Haiti and Ann Arbor, Michigan. It is also dedicated to the friends and mentors who have been with me over the seven years of my graduate career. Especially to Charity and Charisse. ii TABLE OF CONTENTS Dedication ii List of Figures v Abstract vi Chapter 1 Introduction: Espionage as the Loss of Agency 1 Methodology; or, Why Study Spy Fiction? 3 A Brief Overview of the Entwined Histories of Espionage as a Practice and Espionage as a Cultural Product 20 Chapter Outline: Chapters 2 and 3 31 Chapter Outline: Chapters 4, 5 and 6 40 Chapter 2 The Spy Agency as a Discursive Formation, Part 1: Conspiracy, Bureaucracy and the Espionage Mindset 52 The SPECTRE of the Many-Headed HYDRA: Conspiracy and the Public’s Experience of Spy Agencies 64 Writing in the Machine: Bureaucracy and Espionage 86 Chapter 3: The Spy Agency as a Discursive Formation, Part 2: Cruelty and Technophilia -

HANDSOME= JOINS BELMONT; >LEE= WORKS
MONDAY, JUNE 5, 2017 >HANDSOME= JOINS WARD LAYS OUT PLANS FOR ROYAL ASCOT CONTINGENT by Bill Finley BELMONT; >LEE= WORKS Wesley Ward will put his Royal Ascot-bound horses through their final round of serious preparations Monday morning at Keeneland, where several will show up on the work tab. A few could be added or dropped from the list of his Royal Ascot runners depending on how they work, but for the most part, Ward has all his plans in line. AI am very strong in all the categories with the horses I=m coming in with,@ Ward said on this week=s TDN podcast. AI know the races now, I know what it takes to win. All the horses I am bringing are going to be very competitive.@ Who=s In: Lady Aurelia (Scat Daddy): A winner last year at Royal Ascot in the G2 Queen Mary S., the 3-year-old filly will take on males in the G1 King=s Stand S. June 20. She is coming off a win in the April 15 Giant=s Causeway S. at Keeneland. Cont. p3 Hollywood Handsome | Coady Photography IN TDN EUROPE TODAY BRAMETOT PREVAILS IN FRENCH DERBY Mark Stanley=s Hollywood Handsome (Tapizar) has been Jean Caude Rouget’s Brametot (Fr) (Rajsaman {Fr}) clinched a added to the GI Belmont S. line-up, according to trainer Dallas second Classic when winning the G1 Prix Du Jockey Club at Stewart Sunday. Chantilly. Click or tap here to go straight to TDN Europe. AI=m so excited to get this horse to the Belmont,@ Stewart said. -

About Cards, Boards & Dice
Cards, Boards & Dice Hundreds of different Card Games, Board Games and Dice Games to play in solitude, against computer opponents and even against human players across the internet… Say goodbye to your spare time, and not so spare time ;) Disc 1 Disc 2 ♜ 3D Crazy Eights ♜ 3D Bridge Deluxe ♜ Mike's Marbles ♜ 3D Euchre Deluxe ♜ 3D Hearts Deluxe ♜ Mnemoni X ♜ 3D Spades Deluxe ♜ 5 Realms ♜ Monopoly Here & Now ♜ Absolute Farkle ♜ A Farewell to Kings ♜ NingPo Mahjong ♜ Aki Mahjong Solitaire ♜ Ancient Tripeaks 2 ♜ Pairs ♜ Ancient Hearts Spades ♜ Big Bang Board Games ♜ Patience X ♜ Bejeweled 2 ♜ Burning Monkey Mahjong ♜ Poker Dice ♜ Big Bang Brain Games ♜ Classic Sol ♜ Professor Code ♜ Boka Battleships ♜ CrossCards ♜ Sigma Chess ♜ Burning Monkey Solitaire ♜ Dominoes ♜ SkalMac Yatzy ♜ Cintos ♜ Free Solitaire 3D ♜ Snood Solitaire ♜ David's Backgammon ♜ Freecell ♜ Snoodoku ♜ Hardwood Solitaire III ♜ GameHouse Solitaire ♜ Solitaire Epic ♜ Jeopardy Deluxe Challenge ♜ Solitaire Plus ♜ Mah Jong Quest ♜ iDice ♜ Solitaire Till Dawn X ♜ Monopoly Classic ♜ iHearts ♜ Wiz Solitaire ♜ Neuronyx ♜ Kitty Spangles Solitaire ♜ ♜ Klondike The applications supplied on this CD are One Card s u p p l i e d a s i s a n d w e m a k e n o ♜ Rainbow Mystery ♜ Lux representations regarding the applications nor any information related thereto. Any ♜ Rainbow Web ♜ MacPips Jigsaw questions, complaints or claims regarding the ♜ applications must be directed to the ♜ Scrabble MacSudoku appropriate software vendor. ♜ ♜ Simple Yahtzee X MahJong Medley Various different license -
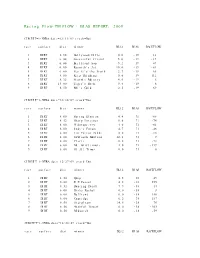
Racing Flow-TM FLOW + BIAS REPORT: 2009
Racing Flow-TM FLOW + BIAS REPORT: 2009 CIRCUIT=1-NYRA date=12/31/09 track=Dot race surface dist winner BL12 BIAS RACEFLOW 1 DIRT 5.50 Hollywood Hills 0.0 -19 13 2 DIRT 6.00 Successful friend 5.0 -19 -19 3 DIRT 6.00 Brilliant Son 5.2 -19 47 4 DIRT 6.00 Raynick's Jet 10.6 -19 -61 5 DIRT 6.00 Yes It's the Truth 2.7 -19 65 6 DIRT 8.00 Keep Thinking 0.0 -19 -112 7 DIRT 8.32 Storm's Majesty 4.0 -19 6 8 DIRT 13.00 Tiger's Rock 9.4 -19 6 9 DIRT 8.50 Mel's Gold 2.5 -19 69 CIRCUIT=1-NYRA date=12/30/09 track=Dot race surface dist winner BL12 BIAS RACEFLOW 1 DIRT 8.00 Spring Elusion 4.4 71 -68 2 DIRT 8.32 Sharp Instinct 0.0 71 -74 3 DIRT 6.00 O'Sotopretty 4.0 71 -61 4 DIRT 6.00 Indy's Forum 4.7 71 -46 5 DIRT 6.00 Ten Carrot Nikki 0.0 71 -18 6 DIRT 8.00 Sawtooth Moutain 12.1 71 9 7 DIRT 6.00 Cleric 0.6 71 -73 8 DIRT 6.00 Mt. Glittermore 4.0 71 -119 9 DIRT 6.00 Of All Times 0.0 71 0 CIRCUIT=1-NYRA date=12/27/09 track=Dot race surface dist winner BL12 BIAS RACEFLOW 1 DIRT 8.50 Quip 4.5 -38 49 2 DIRT 6.00 E Z Passer 4.2 -38 255 3 DIRT 8.32 Dancing Daisy 7.9 -38 14 4 DIRT 6.00 Risky Rachel 0.0 -38 8 5 DIRT 6.00 Kaffiend 0.0 -38 150 6 DIRT 6.00 Capridge 6.2 -38 187 7 DIRT 8.50 Stargleam 14.5 -38 76 8 DIRT 8.50 Wishful Tomcat 0.0 -38 -203 9 DIRT 8.50 Midwatch 0.0 -38 -59 CIRCUIT=1-NYRA date=12/26/09 track=Dot race surface dist winner BL12 BIAS RACEFLOW 1 DIRT 6.00 Papaleo 7.0 108 129 2 DIRT 6.00 Overcommunication 1.0 108 -72 3 DIRT 6.00 Digger 0.0 108 -211 4 DIRT 6.00 Bryan Kicks 0.0 108 136 5 DIRT 6.00 We Get It 16.8 108 129 6 DIRT 6.00 Yawanna Trust 4.5 108 -21 7 DIRT 6.00 Smarty Karakorum 6.5 108 83 8 DIRT 8.32 Almighty Silver 18.7 108 133 9 DIRT 8.32 Offlee Cool 0.0 108 -60 CIRCUIT=1-NYRA date=12/13/09 track=Dot race surface dist winner BL12 BIAS RACEFLOW 1 DIRT 8.32 Crafty Bear 3.0 -158 -139 2 DIRT 6.00 Cheers Darling 0.5 -158 61 3 DIRT 6.00 Iberian Gate 3.0 -158 154 4 DIRT 6.00 Pewter 0.5 -158 8 5 DIRT 6.00 Wolfson 6.2 -158 86 6 DIRT 6.00 Mr. -

Violin Syllabus / 2013 Edition
VVioliniolin SYLLABUS / 2013 EDITION SYLLABUS EDITION © Copyright 2013 The Frederick Harris Music Co., Limited All Rights Reserved Message from the President The Royal Conservatory of Music was founded in 1886 with the idea that a single institution could bind the people of a nation together with the common thread of shared musical experience. More than a century later, we continue to build and expand on this vision. Today, The Royal Conservatory is recognized in communities across North America for outstanding service to students, teachers, and parents, as well as strict adherence to high academic standards through a variety of activities—teaching, examining, publishing, research, and community outreach. Our students and teachers benefit from a curriculum based on more than 125 years of commitment to the highest pedagogical objectives. The strength of the curriculum is reinforced by the distinguished College of Examiners—a group of fine musicians and teachers who have been carefully selected from across Canada, the United States, and abroad for their demonstrated skill and professionalism. A rigorous examiner apprenticeship program, combined with regular evaluation procedures, ensures consistency and an examination experience of the highest quality for candidates. As you pursue your studies or teach others, you become not only an important partner with The Royal Conservatory in the development of creativity, discipline, and goal- setting, but also an active participant, experiencing the transcendent qualities of music itself. In a society where our day-to-day lives can become rote and routine, the human need to find self-fulfillment and to engage in creative activity has never been more necessary.