Department of Computer Engineering and Informatics University of Patras
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-
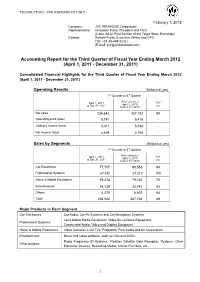
Accounting Report for the Third Quarter of Fiscal Year Ending March 2012 (April 1, 2011 - December 31, 2011)
TRANSLATION - FOR REFERENCE ONLY - February 1, 2012 Company: JVC KENWOOD Corporation Representative: Hisayoshi Fuwa, President and CEO (Code: 6632; First Section of the Tokyo Stock Exchange) Contact: Satoshi Fujita, Executive Officer and CFO (Tel: +81-45-444-5232) (E-mail: [email protected]) Accounting Report for the Third Quarter of Fiscal Year Ending March 2012 (April 1, 2011 - December 31, 2011) Consolidated Financial Highlights for the Third Quarter of Fiscal Year Ending March 2012 (April 1, 2011 - December 31, 2011) Operating Results (Millions of yen) 1st Quarter to 3rd Quarter (For reference) April 1, 2011 YoY April 1, 2010 to Dec.31, 2011 to Dec.31, 2010 (%) Net sales 236,542 267,182 89 Operating profit (loss) 8,791 9,416 - Ordinary income (loss) 6,511 6,530 - Net income (loss) 4,409 2,193 - Sales by Segments (Millions of yen) 1st Quarter to 3rd Quarter (For reference) YoY April 1, 2011 April 1, 2010 to Dec.31, 2011 to Dec.31, 2010 (%) Car Electronics 77,707 80,558 96 Professional Systems 67,142 67,210 100 Home & Mobile Electronics 59,274 79,167 75 Entertainment 28,139 33,742 83 Others 4,279 6,502 66 Total 236,542 267,182 89 Major Products in Each Segment Car Electronics Car Audio, Car AV Systems and Car Navigation Systems Land Mobile Radio Equipment, Video Surveillance Equipment, Professional Systems Commercial Audio, Video and Display Equipment Home & Mobile Electronics Video Cameras, LCD TVs, Projectors, Pure Audio and AV Accessories Entertainment Music and video software, such as CDs and DVDs Radio Frequency ID Systems, Weather Satellite Data Reception Systems, Other Other projects Electronic Devices, Recording Media, Interior Furniture, etc. -

Idols and Celebrity in Japanese Media Culture, Edited by Patrick W
Copyright material from www.palgraveconnect.com - licensed to Murdoch University - PalgraveConnect - 2013-08-20 - PalgraveConnect University - licensed to Murdoch www.palgraveconnect.com material from Copyright 10.1057/9781137283788 - Idols and Celebrity in Japanese Media Culture, Edited by Patrick W. Galbraith and Jason G. Karlin Idols and Celebrity in Japanese Media Culture Copyright material from www.palgraveconnect.com - licensed to Murdoch University - PalgraveConnect - 2013-08-20 - PalgraveConnect University - licensed to Murdoch www.palgraveconnect.com material from Copyright 10.1057/9781137283788 - Idols and Celebrity in Japanese Media Culture, Edited by Patrick W. Galbraith and Jason G. Karlin This page intentionally left blank Copyright material from www.palgraveconnect.com - licensed to Murdoch University - PalgraveConnect - 2013-08-20 - PalgraveConnect University - licensed to Murdoch www.palgraveconnect.com material from Copyright 10.1057/9781137283788 - Idols and Celebrity in Japanese Media Culture, Edited by Patrick W. Galbraith and Jason G. Karlin Idols and Celebrity in Japanese Media Culture Edited by Patrick W. Galbraith and Jason G. Karlin University of Tokyo, Japan Copyright material from www.palgraveconnect.com - licensed to Murdoch University - PalgraveConnect - 2013-08-20 - PalgraveConnect University - licensed to Murdoch www.palgraveconnect.com material from Copyright 10.1057/9781137283788 - Idols and Celebrity in Japanese Media Culture, Edited by Patrick W. Galbraith and Jason G. Karlin Introduction, selection -

Universidade De Brasília Instituto De Letras Departamento De Línguas Estrangeiras E Tradução Licenciatura Em Língua E Literatura Japonesa
UNIVERSIDADE DE BRASÍLIA INSTITUTO DE LETRAS DEPARTAMENTO DE LÍNGUAS ESTRANGEIRAS E TRADUÇÃO LICENCIATURA EM LÍNGUA E LITERATURA JAPONESA DÉBORA HABIB VIEIRA DA SILVA A AFETIVIDADE E O DISTANCIAMENTO NO RELACIONAMENTO ÍDOLO-FÃ: Um Estudo de Caso Realizado com Ex-fãs da Johnny's & Associates BRASÍLIA 2015 UNIVERSIDADE DE BRASÍLIA INSTITUTO DE LETRAS DEPARTAMENTO DE LÍNGUAS ESTRANGEIRAS E TRADUÇÃO LICENCIATURA EM LÍNGUA E LITERATURA JAPONESA DÉBORA HABIB VIEIRA DA SILVA A AFETIVIDADE E O DISTANCIAMENTO NO RELACIONAMENTO ÍDOLO-FÃ: Um Estudo de Caso Realizado com Ex-fãs da Johnny's & Associates Trabalho de Conclusão de Curso apresentado ao Curso de Licenciatura em Língua e Literatura Japonesa da Universidade de Brasília (UnB), como requisito para obtenção do diploma de graduado em Língua e Literatura Japonesa. Orientador: Prof. Dr. Ronan Alves Pereira BRASÍLIA 2015 [ii] UNIVERSIDADE DE BRASÍLIA DÉBORA HABIB VIEIRA DA SILVA A AFETIVIDADE E O DISTANCIAMENTO NO RELACIONAMENTO ÍDOLO-FÃ: Um Estudo de Caso Realizado com Ex-fãs da Johnny's & Associates Trabalho de Conclusão de Curso apresentado ao Curso de Licenciatura em Língua e Literatura Japonesa da Universidade de Brasília (UnB), como requisito para obtenção do diploma de graduado em Língua e Literatura Japonesa. Aprovado com “Louvor e Distinção” em 19 de junho de 15. BANCA EXAMINADORA __________________________________ Prof. Dr. Ronan Pereira Alves (Orientador) __________________________________ Profa. Dra. Tae Suzuki __________________________________ Prof. Lic. Gabriel de Oliveira Fernandes BRASÍLIA- DF 2015 [iii] AGRADECIMENTOS Agradeço primeiramente a Deus pelo dom de minha vida e por me capacitar com a faculdade da inteligência e a perseverança para escrever minha própria história. Em segundo lugar, gostaria de agradecer a meu pai Belmiro e minha mãe Ivone, por me educarem e por terem me dado a oportunidade de receber um ensino de qualidade, sem o qual esta graduação jamais se faria possível. -

クリスマスソング Back Number 旅立ちの唄 Mr.Children Kinki Kids あの紙ヒコーキくもり空わって 19 く る み Mr.Children 抱きしめたい Mr.Children ま 負けないで ZARD
JJJ J-POP・歌謡曲 JJJ J-POP・歌謡曲 JJJ J-POP・歌謡曲 JJJ J-POP・歌謡曲 あ 愛 唄 GReeeeN キ セ キ GReeeeN ⻘春アミーゴ 修二と彰 遥 か GReeeeN 美空ひばり 財津和夫 愛 燦 燦 小椋 佳 君がいるだけで 米米クラブ ⻘ 春 の 影 チューリップ パプリカ Foorin 会いたくて会いたくて ⻄野カナ 君 が 好 き Mr.Children 世界に一つだけの花 SMAP ひこうき雲 秦 基博 愛にできることはまだあるかい 天気の子 君って… ⻄野カナ 背中越しのチャンス ⻲と山P ひまわりの約束 荒井由 愛 で し た 関ジャニ∞ 君に出会えたから miwa 戦場のメリ ークリスマス 坂本龍一 ビリーブ Believe 嵐 ファースト ラブ 愛 は 勝 つ KAN 君をさがしてた CHEMISTRY 千の風になって 秋川雅史 First Love 宇多田ヒカル A・RA ・SHI キャンユーセレブレイト 千本桜 feat .初音ミク 大塚 愛 ア ラ シ 嵐 CAN YOU CELEBRAT E? 安室奈美恵 千 ⿊うさ P feat 初音ミク プラネタリウム アイ ラブ ユー 小田和正 スキマスイッチ official髭男dism I LOVE YOU 尾崎 豊 今日もどこかで 全 力 少 年 プリテンダー 荒井由実 愛をこめて花束をSuperfly キ ラ キ ラ 小田和正 卒 業 写 真 ハイ・ファイ・セット ブルーバード いきものがかり ギブ ミー ラブ ベスト フレンド 赤いスイートピー 松田聖子 Give Me Love Hey! Say! JUMP 空も飛べるはず スピッツ Best Fr iend Kiroro 明日晴れるかな 桑田佳祐 クリスマスイブ 山下達郎 た ただ…逢いたくて EXILE 星影のエール GReeeeN ボクの背中には羽根がある 明日への扉 I WiSH クリスマスソング back number 旅立ちの唄 Mr.Children Kinki Kids あの紙ヒコーキくもり空わって 19 く る み Mr.Children 抱きしめたい Mr.Children ま 負けないで ZARD ありがとう いきものがかり 決意の朝に Aqua Timez チ ェ リ ー スピッツ まちがいさがし 菅田将暉 official 髭男 dism 竹内まりや サザン I LOVE … CHE.R.RY YUI アイラブ… 元気を出して 島谷ひとみ チェリー 真夏の果実 オール スターズ 谷村新司 いい日旅立ち 山口百恵 恋 星野 源 地 上 の 星 中島みゆき 守ってあげたい 松任谷由実 行くぜっ ! 怪盗少 女 恋するフォーチュンクッキー ツ ナ ミ あいみょん ももいろクローバー 恋 AKB48 TSUNAMI サザン オール スター ズ マリーゴールド 見上げてごらん夜の星を ー B’z 松任谷 由実 赤い鳥 いつかのメリ クリスマス 恋人がサンタクロース 翼をください 平井 堅・堂本 剛・坂本 九 さだまさし 糸 中島みゆき 秋 桜コスモス 山口百恵 蕾つぼみ コブクロ 三 日 月 絢 香 サザン 小田和正 手 紙 〜拝啓⼗五の君へ〜 いとしのエリー オール スターズ 言葉にできない オフコース アンジェラ アキ 見たこともない景色 菅田将暉 イノセント ワールド innocent world Mr.Children 粉 雪 レミオロメン 天 体 観 測 BUMP OF CHICKEN 道 EXILE 浦島太郎 (桐谷健太) Sign トゥモロー 未来予想図Ⅱ 海 -

The “Pop Pacific” Japanese-American Sojourners and the Development of Japanese Popular Music
The “Pop Pacific” Japanese-American Sojourners and the Development of Japanese Popular Music By Jayson Makoto Chun The year 2013 proved a record-setting year in Japanese popular music. The male idol group Arashi occupied the spot for the top-selling album for the fourth year in a row, matching the record set by female singer Utada Hikaru. Arashi, managed by Johnny & Associates, a talent management agency specializing in male idol groups, also occupied the top spot for artist total sales while seven of the top twenty-five singles (and twenty of the top fifty) that year also came from Johnny & Associates groups (Oricon 2013b).1 With Japan as the world’s second largest music market at US$3.01 billion in sales in 2013, trailing only the United States (RIAJ 2014), this talent management agency has been one of the most profitable in the world. Across several decades, Johnny Hiromu Kitagawa (born 1931), the brains behind this agency, produced more than 232 chart-topping singles from forty acts and 8,419 concerts (between 2010 and 2012), the most by any individual in history, according to Guinness World Records, which presented two awards to Kitagawa in 2010 (Schwartz 2013), and a third award for the most number-one acts (thirty-five) produced by an individual (Guinness World Record News 2012). Beginning with the debut album of his first group, Johnnys in 1964, Kitagawa has presided over a hit-making factory. One should also look at R&B (Rhythm and Blues) singer Utada Hikaru (born 1983), whose record of four number one albums of the year Arashi matched. -

Johnny's” Entertainers Omnipresent on Japanese TV: Postwar Media and the Postwar Family
CULTURE The “Johnny's” Entertainers Omnipresent on Japanese TV: Postwar Media and the Postwar Family Shuto Yoshiki, Associate Professor, Nippon Sports and Science University Introduction What do Japanese people think of when they hear the name Johnnies? Perhaps pop groups such as SMAP or Arashi that belong to the Johnny & Associates talent agency? Or perhaps the title of specific TV programs or movies? If they are not that interested, perhaps they will be reminded of the words “beautiful young boys” or “scandal”? On the other hand, if they are well-informed about the topic perhaps jargon terms such as “oriki ,” “doutan ,” or “shinmechu ” are second nature? In this way the word “Johnnies” (the casual name given to groups managed by Johnny & Associates) is likely to evoke all sorts of images. But one thing is sure: almost no Japanese person would reply that they hadn’t heard the name. If a person lives within Japanese society and they watch television even just a little, whether they like it or not they will come across Johnnies. The performing artists managed by Johnny & Associates appear on television almost every hour of the viewing day, and they feature in all kinds of TV programs: music, drama, entertainment, news, live sports, education, and cooking. In Japanese society Johnnies are consumed as a matter of course and without need for explanation. They make up part of the background of everyday life. The Johnnies were created in April 1962. That year, a group called “Johnnys” was put together composed of Aoi Teruhiko, Nakatani Ryo, Iino Osami, and Maie Hiromi. -

HAWAIIAN CAUSATIVE-SIMULATIVE PREFIXES AS TRANSITIVITY and SEMANTIC CONVERSION AFFIXES Plan B Paper by Matthew Brittain in Parti
HAWAIIAN CAUSATIVE-SIMULATIVE PREFIXES AS TRANSITIVITY AND SEMANTIC CONVERSION AFFIXES Plan B Paper By Matthew Brittain In Partial Fulfillment of the requirements for Master of Arts 4/93 University of Hawai~i at Manoa School of Hawaiian, Asian and Pacific Islands Studies Center for Pacific Islands Studies Dr. George Grace Dr. Emily Hawkins Dr. Robert Kiste HAWAIIAN CONVERSION PREFIXES 1 TABLE OF CONTENTS Acknowledgements ............•.........•...............•....p. 3 Abstract p. 4 Introduction p. 4 Disclaimer p. 5 Definition of Terms p. 8 Importance of Transitivity in Conversion Prefixes......•...p. 14 Cross-Referencing System For MUltiple Meanings•............p. 21 Method..•...........•.........•.....•..........•..•.....•..p . 24 Forms of Hawaiian Conversion prefixes........•.........•...p. 25 Discussion of Relevent Literature...................•.•....p. 29 Results p. 31 causative Conversion Hawaiian Prefix Data p. 34 Similitude Conversion Hawaiian Prefix Data p. 43 Quality Conversion Hawaiian Prefix Data•...................p. 45 Provision of Noun Hawaiian Prefix Data.........•....•.•....p. 53 Simple Transitivity Conversion Hawaiian Prefix Data•.....•.p. 54 No Change Hawaiian Prefix Data........................•....p. 57 Items with Double Conversion Hawaiian Prefix Data....•.....p. 66 Bibliography p. 68 2 CROSS-REFERENCE GUIDE FOR ITEMS WITH MULTIPLE MEANINGS •...•.Refer to causative conversion section...........p. 34 ••..••Refer to similitude conversion section..........p. 43 T •••••Refer to quality conversion section.............p. 45 €e •••••Refer to provision of noun conversion section, •.p. 53 0 .....Refer to simple conversion section.............p. 54 *.....Refer to no change section......................p. 57 o .....Refer to double conversion section..............p. 66 ho'onohonoho i Waineki kauhale 0 Limaloa. Set in order at Waineki are the houses of Limaloa. Limaloa, the god of mirages, made houses appear and disappear on the plains of Mana. -

Remote Sensing of the Terrestrial Water Cycle Kona, Hawaii, USA 19 –22 February 2012
AGU Chapman Conference on Remote Sensing of the Terrestrial Water Cycle Kona, Hawaii, USA 19 –22 February 2012 Conveners Venkat Lakshmi, University of South Carolina, USA Doug Alsdorf, Ohio State University, USA Jared Entin, NASA, USA George Huffman, NASA, USA Peter van Oevelen, GEWEX, USA Juraj Parajka, Vienna University of Technology Program Committee Bill Kustas, USDA-ARS Bob Adler, University of Maryland Chris Rudiger, Monash University Jay Famiglietti, University of California, Irvine, USA Martha Anderson, USDA, USA Matt Rodell, NASA, USA Michael Cosh, USDA, USA Steve Running, University of Montana Co-Sponsor The conference organizers acknowledge the generous support of the following organizations: 2 AGU Chapman Conference on Remote Sensing of the Terrestrial Water Cycle Meeting At A Glance Sunday, 19 February 2012 1500h – 2100h Registration 1700h – 1710h Welcome Remarks 1710h – 1750h Keynote Speaker – Andrew C. Revkin, The New York Times 1750h – 1900h Ice Breaker Reception 1900h Dinner on Your Own Monday, 20 February 2012 800h – 1000h Oral Session 1: Current Challenges in Terrestrial Hydrology 1000h – 1030h Coffee Break and Networking Break 1030h – 1200h Breakout Sessions - Variables Observed by Satellite Remote Sensing Evapotranspiration Soil Moisture Snow Surface Water Groundwater Precipitation 1200h – 1330h Lunch on Your Own 1330h – 1600h Oral Session 2: Estimating Water Storage Components: Surface Water, Groundwater, and Ice/Snow 1600h – 1630h Coffee Break 1630h – 1900h Poster Session I and Ice Breaker 1900h Dinner on Your Own -

The Rise of J-Pop in Asia and Its Impact
COVER STORY • 7 The Rise of J-Pop in Asia and Its Impact By Ng Wai-ming APANESE pop music is commonly music, but also their images. They are bases to make Asian editions of J-pop Jreferred to as “J-pop,” a term coined mostly handsome young boys and cute albums for the Asian market. by Komuro Tetsuya, the “father of J- and pretty young girls who know how to Compared to Japanese editions, Asian pop,” in the early 1990s. The meaning sing, dance, talk, act and dress. Many J- editions are more user-friendly and of J-pop has never been clear. It was pop fans in Asia enjoy music videos affordable. They usually come with the first limited to Euro-beat, the kind of (MVs) as much as CDs. Due to physical Chinese translation of the lyrics. These dance music that Komuro produced. and cultural proximities, Asian youths Asian editions are much cheaper (about However, it was later also applied to feel close to Japanese idols. Unlike 50% less) than the Japanese originals many other kinds of popular music in Western idols who are too out of this and are only permitted to circulate in the Japanese music chart, Oricon, world to Asians, J-pop idols adopt a Asia outside of Japan. They have a wide including idol-pop, rhythm and blues down-to-earth approach and present circulation in Asia. For example, in (R&B), folk, soft rock, easy listening and themselves like the people next door. 2000, the Asian edition of Kiroro’s sometimes even hip hop. -

Accounting Report for the First Half of Fiscal Year Ending March 2013 (April 1, 2012 - September 30, 2012)
TRANSLATION - FOR REFERENCE ONLY - November 1, 2012 Company: JVC KENWOOD Corporation Representative: Shoichiro Eguchi, President, Representative Director and CEO (Code: 6632; First Section of the Tokyo Stock Exchange) Contact: Satoshi Fujita, Director, Executive Officer and CFO (Tel: +81-45-444-5232) (E-mail: [email protected]) Accounting Report for the First Half of Fiscal Year Ending March 2013 (April 1, 2012 - September 30, 2012) Consolidated Financial Highlights for the First Half of Fiscal Year Ending March 2013 (April 1, 2012 - September 30, 2012) Operating Results (Millions of yen, except net income per share) First Half of FYE 3/2013 First Half of FYE 3/2012 (April 1, 2012 to September 30, 2012) (April 1, 2011 to September 30, 2011) Net sales 149,266 157,861 Operating profit (loss) 4,366 6,933 Ordinary income (loss) 2,966 6,393 Net income (loss) 1,237 4,873 Net income (loss) per share 8.92 yen 35.15 yen FYE: Fiscal year ended / ending Sales by Segments (Millions of yen) First Half of FYE 3/2013 First Half of FYE 3/2012 (April 1, 2012 to September 30, 2012) (April 1, 2011 to September 30, 2011) Car Electronics 51,803 35% 54,199 34% Professional Systems 42,559 29% 45,013 29% Home & Mobile Electronics 32,633 22% 37,999 24% Entertainment 20,103 13%18,004 11% Others 2,166 1%2,645 2% Total 149,266 100%157,861 100% FYE: Fiscal year ended / ending Major Products in Each Segment Car Electronics Car Audio, Car AV Systems and Car Navigation Systems Land Mobile Radio Equipment, Video Surveillance Equipment, Professional Systems Commercial Audio, Video and Display Equipment Home & Mobile Electronics Video Cameras, LCD TVs, Projectors, Pure Audio and AV Accessories Entertainment Music and video software, such as CDs and DVDs Radio Frequency ID Systems, Weather Satellite Data Reception Systems, Other projects Other Electronic Devices, Recording Media, Interior Furniture, etc. -

2012 IEEE International Geoscience and Remote Sensing Symposium
2012 IEEE International Geoscience and Remote Sensing Symposium (IGARSS 2012) Munich, Germany 22 – 27 July 2012 Pages 1-697 IEEE Catalog Number: CFP12IGA-PRT ISBN: 978-1-4673-1160-1 1/11 TABLE OF CONTENTS MO3-10: NASA SOIL MOISTURE ACTIVE PASSIVE MISSION APPROACH TO PRE-FLIGHT TESTING OF RETRIEVAL ALGORITHMS MO3-10.1: ASSESSMENT OF THE IMPACTS OF RADIO FREQUENCY ............................................................................ 1 INTERFERENCE ON SMAP RADAR AND RADIOMETER MEASUREMENTS Curtis Chen, NASA Jet Propulsion Laboratory, United States; Jeffrey Piepmeier, NASA Goddard Space Flight Center, United States; Joel T. Johnson, The Ohio State University, United States; Hirad Ghaemi, NASA Jet Propulsion Laboratory, United States MO3-10.3: AN AIRBORNE SIMULATION OF THE SMAP DATA STREAM ........................................................................ 5 Jeffrey P. Walker, Monash University, Australia; Peggy O’Neill, NASA Goddard Space Flight Center, United States; Xiaoling Wu, Ying Gao, Alessandra Monerris-Belda, Monash University, Australia; Rocco Panciera, University of Melbourne, Australia; Thomas Jackson, USDA, United States; Douglas Gray, University of Adelaide, Australia; Dongryeol Ryu, The University of Melbourne, Australia MO4-10: SOIL MOISTURE: AQUARIUS AND SMAP MO4-10.2: AN OBSERVING SYSTEM SIMULATION EXPERIMENT (OSSE) FOR THE ................................................. 8 AQUARIUS/SAC-D SOIL MOISTURE PRODUCT: AN INVESTIGATION OF FORWARD/ RETRIEVAL MODEL ASYMMETRIES Pablo Perna, Cintia Bruscantini, Instituto -

Changing Images of Female Idols in Contemporary Japan
ISSN: 1500-0713 ______________________________________________________________ Article Title: Erokakkoii: Changing Images of Female Idols in Contemporary Japan Author(s): Yuki Wantanabe Source: Japanese Studies Review, Vol. XV (2011), pp. 61 - 74 Stable URL: https://asian.fiu.edu/projects-and-grants/japan- studies-review/journal-archive/volume-xv-2011/watanabe- erokakkoii.pdf EROKAKKOII: CHANGING IMAGES OF FEMALE IDOLS IN COMTEMPORARY JAPAN Yuki Watanabe University of Texas at Dallas As television became the primary medium of mass communication in post-war Japan during the 1950s, singer-idols (aidoru) enjoyed increasingly mainstream popularity among Japanese pop music consumers largely because of increasing TV exposure. While there have been many successful male and female singing idols, not surprisingly, most fans of male aidoru have been females, as in the case of the vocal groups that belong to Johnny’s Jimusho (Johnny‟s Office).1 In contrast, fans of female idols consist of a more widely heterogeneous mix of both genders. Reflecting substantial postwar changes in the Japanese economy and in Japanese culture, including assumptions about gender and its various constructions in popular culture, this paper will explore the cultural significance of evolving images and receptions of Japan‟s increasingly popular female aidoru. In the process, the paper aims to document processes by which traditional gender roles are simultaneously reinforced and challenged. This paper looks at how the concept of erokakkoii (erotic and cool) came to be embodied by mainstream female singing idols, analyzing the social implications of the phenomenon in terms of increasingly ambiguous gender relationships in contemporary Japan. For example, Koda Kumi, one of today‟s most popular Japanese female idols, is praised for her singing and dancing as well as her (in)famous erotic moves in skimpy costumes.