The Impact on the Performance of Co-Running Virtual Machines in a Virtualized Environment
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

A Case for High Performance Computing with Virtual Machines
A Case for High Performance Computing with Virtual Machines Wei Huangy Jiuxing Liuz Bulent Abaliz Dhabaleswar K. Panday y Computer Science and Engineering z IBM T. J. Watson Research Center The Ohio State University 19 Skyline Drive Columbus, OH 43210 Hawthorne, NY 10532 fhuanwei, [email protected] fjl, [email protected] ABSTRACT in the 1960s [9], but are experiencing a resurgence in both Virtual machine (VM) technologies are experiencing a resur- industry and research communities. A VM environment pro- gence in both industry and research communities. VMs of- vides virtualized hardware interfaces to VMs through a Vir- fer many desirable features such as security, ease of man- tual Machine Monitor (VMM) (also called hypervisor). VM agement, OS customization, performance isolation, check- technologies allow running different guest VMs in a phys- pointing, and migration, which can be very beneficial to ical box, with each guest VM possibly running a different the performance and the manageability of high performance guest operating system. They can also provide secure and computing (HPC) applications. However, very few HPC ap- portable environments to meet the demanding requirements plications are currently running in a virtualized environment of computing resources in modern computing systems. due to the performance overhead of virtualization. Further, Recently, network interconnects such as InfiniBand [16], using VMs for HPC also introduces additional challenges Myrinet [24] and Quadrics [31] are emerging, which provide such as management and distribution of OS images. very low latency (less than 5 µs) and very high bandwidth In this paper we present a case for HPC with virtual ma- (multiple Gbps). -

A Light-Weight Virtual Machine Monitor for Blue Gene/P
A Light-Weight Virtual Machine Monitor for Blue Gene/P Jan Stoessx{1 Udo Steinbergz1 Volkmar Uhlig{1 Jonathan Appavooy1 Amos Waterlandj1 Jens Kehnex xKarlsruhe Institute of Technology zTechnische Universität Dresden {HStreaming LLC jHarvard School of Engineering and Applied Sciences yBoston University ABSTRACT debugging tools. CNK also supports I/O only via function- In this paper, we present a light-weight, micro{kernel-based shipping to I/O nodes. virtual machine monitor (VMM) for the Blue Gene/P Su- CNK's lightweight kernel model is a good choice for the percomputer. Our VMM comprises a small µ-kernel with current set of BG/P HPC applications, providing low oper- virtualization capabilities and, atop, a user-level VMM com- ating system (OS) noise and focusing on performance, scal- ponent that manages virtual BG/P cores, memory, and in- ability, and extensibility. However, today's HPC application terconnects; we also support running native applications space is beginning to scale out towards Exascale systems of directly atop the µ-kernel. Our design goal is to enable truly global dimensions, spanning companies, institutions, compatibility to standard OSes such as Linux on BG/P via and even countries. The restricted support for standardized virtualization, but to also keep the amount of kernel func- application interfaces of light-weight kernels in general and tionality small enough to facilitate shortening the path to CNK in particular renders porting the sprawling diversity applications and lowering OS noise. of scalable applications to supercomputers more and more a Our prototype implementation successfully virtualizes a bottleneck in the development path of HPC applications. -

Opportunities for Leveraging OS Virtualization in High-End Supercomputing
Opportunities for Leveraging OS Virtualization in High-End Supercomputing Kevin T. Pedretti Patrick G. Bridges Sandia National Laboratories∗ University of New Mexico Albuquerque, NM Albuquerque, NM [email protected] [email protected] ABSTRACT formance, making modest virtualization performance over- This paper examines potential motivations for incorporating heads viable. In these cases,the increased flexibility that vir- virtualization support in the system software stacks of high- tualization provides can be used to support a wider range end capability supercomputers. We advocate that this will of applications, to enable exascale co-design research and increase the flexibility of these platforms significantly and development, and provide new capabilities that are not pos- enable new capabilities that are not possible with current sible with the fixed software stacks that high-end capability fixed software stacks. Our results indicate that compute, supercomputers use today. virtual memory, and I/O virtualization overheads are low and can be further mitigated by utilizing well-known tech- The remainder of this paper is organized as follows. Sec- niques such as large paging and VMM bypass. Furthermore, tion 2 discusses previous work dealing with the use of virtu- since the addition of virtualization support does not affect alization in HPC. Section 3 discusses several potential areas the performance of applications using the traditional native where platform virtualization could be useful in high-end environment, there is essentially no disadvantage to its ad- supercomputing. Section 4 presents single node native vs. dition. virtual performance results on a modern Intel platform that show that compute, virtual memory, and I/O virtualization 1. -

Supporting Information
Electronic Supplementary Material (ESI) for RSC Advances. This journal is © The Royal Society of Chemistry 2020 Supporting Information How to Select Ionic Liquids as Extracting Agent Systematically? Special Case Study for Extractive Denitrification Process Shurong Gaoa,b,c,*, Jiaxin Jina,b, Masroor Abroc, Ruozhen Songc, Miao Hed, Xiaochun Chenc,* a State Key Laboratory of Alternate Electrical Power System with Renewable Energy Sources, North China Electric Power University, Beijing, 102206, China b Research Center of Engineering Thermophysics, North China Electric Power University, Beijing, 102206, China c Beijing Key Laboratory of Membrane Science and Technology & College of Chemical Engineering, Beijing University of Chemical Technology, Beijing 100029, PR China d Office of Laboratory Safety Administration, Beijing University of Technology, Beijing 100124, China * Corresponding author, Tel./Fax: +86-10-6443-3570, E-mail: [email protected], [email protected] 1 COSMO-RS Computation COSMOtherm allows for simple and efficient processing of large numbers of compounds, i.e., a database of molecular COSMO files; e.g. the COSMObase database. COSMObase is a database of molecular COSMO files available from COSMOlogic GmbH & Co KG. Currently COSMObase consists of over 2000 compounds including a large number of industrial solvents plus a wide variety of common organic compounds. All compounds in COSMObase are indexed by their Chemical Abstracts / Registry Number (CAS/RN), by a trivial name and additionally by their sum formula and molecular weight, allowing a simple identification of the compounds. We obtained the anions and cations of different ILs and the molecular structure of typical N-compounds directly from the COSMObase database in this manuscript. -

GROMACS: Fast, Flexible, and Free
GROMACS: Fast, Flexible, and Free DAVID VAN DER SPOEL,1 ERIK LINDAHL,2 BERK HESS,3 GERRIT GROENHOF,4 ALAN E. MARK,4 HERMAN J. C. BERENDSEN4 1Department of Cell and Molecular Biology, Uppsala University, Husargatan 3, Box 596, S-75124 Uppsala, Sweden 2Stockholm Bioinformatics Center, SCFAB, Stockholm University, SE-10691 Stockholm, Sweden 3Max-Planck Institut fu¨r Polymerforschung, Ackermannweg 10, D-55128 Mainz, Germany 4Groningen Biomolecular Sciences and Biotechnology Institute, University of Groningen, Nijenborgh 4, NL-9747 AG Groningen, The Netherlands Received 12 February 2005; Accepted 18 March 2005 DOI 10.1002/jcc.20291 Published online in Wiley InterScience (www.interscience.wiley.com). Abstract: This article describes the software suite GROMACS (Groningen MAchine for Chemical Simulation) that was developed at the University of Groningen, The Netherlands, in the early 1990s. The software, written in ANSI C, originates from a parallel hardware project, and is well suited for parallelization on processor clusters. By careful optimization of neighbor searching and of inner loop performance, GROMACS is a very fast program for molecular dynamics simulation. It does not have a force field of its own, but is compatible with GROMOS, OPLS, AMBER, and ENCAD force fields. In addition, it can handle polarizable shell models and flexible constraints. The program is versatile, as force routines can be added by the user, tabulated functions can be specified, and analyses can be easily customized. Nonequilibrium dynamics and free energy determinations are incorporated. Interfaces with popular quantum-chemical packages (MOPAC, GAMES-UK, GAUSSIAN) are provided to perform mixed MM/QM simula- tions. The package includes about 100 utility and analysis programs. -

A Virtual Machine Environment for Real Time Systems Laboratories
AC 2007-904: A VIRTUAL MACHINE ENVIRONMENT FOR REAL-TIME SYSTEMS LABORATORIES Mukul Shirvaikar, University of Texas-Tyler MUKUL SHIRVAIKAR received the Ph.D. degree in Electrical and Computer Engineering from the University of Tennessee in 1993. He is currently an Associate Professor of Electrical Engineering at the University of Texas at Tyler. He has also held positions at Texas Instruments and the University of West Florida. His research interests include real-time imaging, embedded systems, pattern recognition, and dual-core processor architectures. At the University of Texas he has started a new real-time systems lab using dual-core processor technology. He is also the principal investigator for the “Back-To-Basics” project aimed at engineering student retention. Nikhil Satyala, University of Texas-Tyler NIKHIL SATYALA received the Bachelors degree in Electronics and Communication Engineering from the Jawaharlal Nehru Technological University (JNTU), India in 2004. He is currently pursuing his Masters degree at the University of Texas at Tyler, while working as a research assistant. His research interests include embedded systems, dual-core processor architectures and microprocessors. Page 12.152.1 Page © American Society for Engineering Education, 2007 A Virtual Machine Environment for Real Time Systems Laboratories Abstract The goal of this project was to build a superior environment for a real time system laboratory that would allow users to run Windows and Linux embedded application development tools concurrently on a single computer. These requirements were dictated by real-time system applications which are increasingly being implemented on asymmetric dual-core processors running different operating systems. A real time systems laboratory curriculum based on dual- core architectures has been presented in this forum in the past.2 It was designed for a senior elective course in real time systems at the University of Texas at Tyler that combines lectures along with an integrated lab. -

GT-Virtual-Machines
College of Design Virtual Machine Setup for CP 6581 Fall 2020 1. You will have access to multiple College of Design virtual machines (VMs). CP 6581 will require VMs with ArcGIS installed, and for class sessions we will start the semester using the K2GPU VM. You should open each VM available to you and check to see if ArcGIS is installed. 2. Here are a few general notes on VMs. a. Because you will be a new user when you first start a VM, you may be prompted to set up Microsoft Explorer, Microsoft Edge, Adobe Creative Suite, or other software. You can close these windows and set up specific software later, if you wish. b. Different VMs allow different degrees of customization. To customize right-click on an empty Desktop area and choose “Personalize”. Change your background to a solid color that’s a distinctive color so you can easily distinguish your virtual desktop from your local computer’s desktop. Some VMs will remember your desktop color, other VMs must be re-set at each login, other VMs won’t allow you to change the background color but may allow you to change a highlight color from the “Colors” item on the left menu just below “Background”. c. Your desktop will look exactly the same as physical computer’s desktop except for the small black rectangle at the middle of the very top of the VM screen. Click on the rectangle and a pop-down horizontal menu of VM options will appear. Here are two useful options. i. Preferences then File Access will allow you to grant VM access to your local computer’s drives and files. -

Starting SCF Calculations by Superposition of Atomic Densities
Starting SCF Calculations by Superposition of Atomic Densities J. H. VAN LENTHE,1 R. ZWAANS,1 H. J. J. VAN DAM,2 M. F. GUEST2 1Theoretical Chemistry Group (Associated with the Department of Organic Chemistry and Catalysis), Debye Institute, Utrecht University, Padualaan 8, 3584 CH Utrecht, The Netherlands 2CCLRC Daresbury Laboratory, Daresbury WA4 4AD, United Kingdom Received 5 July 2005; Accepted 20 December 2005 DOI 10.1002/jcc.20393 Published online in Wiley InterScience (www.interscience.wiley.com). Abstract: We describe the procedure to start an SCF calculation of the general type from a sum of atomic electron densities, as implemented in GAMESS-UK. Although the procedure is well known for closed-shell calculations and was already suggested when the Direct SCF procedure was proposed, the general procedure is less obvious. For instance, there is no need to converge the corresponding closed-shell Hartree–Fock calculation when dealing with an open-shell species. We describe the various choices and illustrate them with test calculations, showing that the procedure is easier, and on average better, than starting from a converged minimal basis calculation and much better than using a bare nucleus Hamiltonian. © 2006 Wiley Periodicals, Inc. J Comput Chem 27: 926–932, 2006 Key words: SCF calculations; atomic densities Introduction hrstuhl fur Theoretische Chemie, University of Kahrlsruhe, Tur- bomole; http://www.chem-bio.uni-karlsruhe.de/TheoChem/turbo- Any quantum chemical calculation requires properly defined one- mole/),12 GAMESS(US) (Gordon Research Group, GAMESS, electron orbitals. These orbitals are in general determined through http://www.msg.ameslab.gov/GAMESS/GAMESS.html, 2005),13 an iterative Hartree–Fock (HF) or Density Functional (DFT) pro- Spartan (Wavefunction Inc., SPARTAN: http://www.wavefun. -

Parameterizing a Novel Residue
University of Illinois at Urbana-Champaign Luthey-Schulten Group, Department of Chemistry Theoretical and Computational Biophysics Group Computational Biophysics Workshop Parameterizing a Novel Residue Rommie Amaro Brijeet Dhaliwal Zaida Luthey-Schulten Current Editors: Christopher Mayne Po-Chao Wen February 2012 CONTENTS 2 Contents 1 Biological Background and Chemical Mechanism 4 2 HisH System Setup 7 3 Testing out your new residue 9 4 The CHARMM Force Field 12 5 Developing Topology and Parameter Files 13 5.1 An Introduction to a CHARMM Topology File . 13 5.2 An Introduction to a CHARMM Parameter File . 16 5.3 Assigning Initial Values for Unknown Parameters . 18 5.4 A Closer Look at Dihedral Parameters . 18 6 Parameter generation using SPARTAN (Optional) 20 7 Minimization with new parameters 32 CONTENTS 3 Introduction Molecular dynamics (MD) simulations are a powerful scientific tool used to study a wide variety of systems in atomic detail. From a standard protein simulation, to the use of steered molecular dynamics (SMD), to modelling DNA-protein interactions, there are many useful applications. With the advent of massively parallel simulation programs such as NAMD2, the limits of computational anal- ysis are being pushed even further. Inevitably there comes a time in any molecular modelling scientist’s career when the need to simulate an entirely new molecule or ligand arises. The tech- nique of determining new force field parameters to describe these novel system components therefore becomes an invaluable skill. Determining the correct sys- tem parameters to use in conjunction with the chosen force field is only one important aspect of the process. -
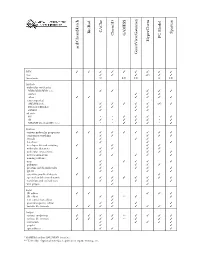
D:\Doc\Workshops\2005 Molecular Modeling\Notebook Pages\Software Comparison\Summary.Wpd
CAChe BioRad Spartan GAMESS Chem3D PC Model HyperChem acd/ChemSketch GaussView/Gaussian WIN TTTT T T T T T mac T T T (T) T T linux/unix U LU LU L LU Methods molecular mechanics MM2/MM3/MM+/etc. T T T T T Amber T T T other TT T T T T semi-empirical AM1/PM3/etc. T T T T T (T) T Extended Hückel T T T T ZINDO T T T ab initio HF * * T T T * T dft T * T T T * T MP2/MP4/G1/G2/CBS-?/etc. * * T T T * T Features various molecular properties T T T T T T T T T conformer searching T T T T T crystals T T T data base T T T developer kit and scripting T T T T molecular dynamics T T T T molecular interactions T T T T movies/animations T T T T T naming software T nmr T T T T T polymers T T T T proteins and biomolecules T T T T T QSAR T T T T scientific graphical objects T T spectral and thermodynamic T T T T T T T T transition and excited state T T T T T web plugin T T Input 2D editor T T T T T 3D editor T T ** T T text conversion editor T protein/sequence editor T T T T various file formats T T T T T T T T Output various renderings T T T T ** T T T T various file formats T T T T ** T T T animation T T T T T graphs T T spreadsheet T T T * GAMESS and/or GAUSSIAN interface ** Text only. -

Virtualizationoverview
VMWAREW H WHITEI T E PPAPERA P E R Virtualization Overview 1 VMWARE WHITE PAPER Table of Contents Introduction .............................................................................................................................................. 3 Virtualization in a Nutshell ................................................................................................................... 3 Virtualization Approaches .................................................................................................................... 4 Virtualization for Server Consolidation and Containment ........................................................... 7 How Virtualization Complements New-Generation Hardware .................................................. 8 Para-virtualization ................................................................................................................................... 8 VMware’s Virtualization Portfolio ........................................................................................................ 9 Glossary ..................................................................................................................................................... 10 2 VMWARE WHITE PAPER Virtualization Overview Introduction Virtualization in a Nutshell Among the leading business challenges confronting CIOs and Simply put, virtualization is an idea whose time has come. IT managers today are: cost-effective utilization of IT infrastruc- The term virtualization broadly describes the separation -

Virtual Machine Benchmarking Kim-Thomas M¨Oller Diploma Thesis
Universitat¨ Karlsruhe (TH) Institut fur¨ Betriebs- und Dialogsysteme Lehrstuhl Systemarchitektur Virtual Machine Benchmarking Kim-Thomas Moller¨ Diploma Thesis Advisors: Prof. Dr. Frank Bellosa Joshua LeVasseur 17. April 2007 I hereby declare that this thesis is the result of my own work, and that all informa- tion sources and literature used are indicated in the thesis. I also certify that the work in this thesis has not previously been submitted as part of requirements for a degree. Hiermit erklare¨ ich, die vorliegende Arbeit selbstandig¨ und nur unter Benutzung der angegebenen Literatur und Hilfsmittel angefertigt zu haben. Alle Stellen, die wortlich¨ oder sinngemaߨ aus veroffentlichten¨ und nicht veroffentlichten¨ Schriften entnommen wurden, sind als solche kenntlich gemacht. Die Arbeit hat in gleicher oder ahnlicher¨ Form keiner anderen Prufungsbeh¨ orde¨ vorgelegen. Karlsruhe, den 17. April 2007 Kim-Thomas Moller¨ Abstract The resurgence of system virtualization has provoked diverse virtualization tech- niques targeting different application workloads and requirements. However, a methodology to compare the performance of virtualization techniques at fine gran- ularity has not yet been introduced. VMbench is a novel benchmarking suite that focusses on virtual machine environments. By applying the pre-virtualization ap- proach for hypervisor interoperability, VMbench achieves hypervisor-neutral in- strumentation of virtual machines at the instruction level. Measurements of dif- ferent virtual machine configurations demonstrate how VMbench helps rate and predict virtual machine performance. Kurzfassung Das wiedererwachte Interesse an der Systemvirtualisierung hat verschiedenartige Virtualisierungstechniken fur¨ unterschiedliche Anwendungslasten und Anforde- rungen hervorgebracht. Jedoch wurde bislang noch keine Methodik eingefuhrt,¨ um Virtualisierungstechniken mit hoher Granularitat¨ zu vergleichen. VMbench ist eine neuartige Benchmarking-Suite fur¨ Virtuelle-Maschinen-Umgebungen.