Opportunities for Leveraging OS Virtualization in High-End Supercomputing
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

A Case for High Performance Computing with Virtual Machines
A Case for High Performance Computing with Virtual Machines Wei Huangy Jiuxing Liuz Bulent Abaliz Dhabaleswar K. Panday y Computer Science and Engineering z IBM T. J. Watson Research Center The Ohio State University 19 Skyline Drive Columbus, OH 43210 Hawthorne, NY 10532 fhuanwei, [email protected] fjl, [email protected] ABSTRACT in the 1960s [9], but are experiencing a resurgence in both Virtual machine (VM) technologies are experiencing a resur- industry and research communities. A VM environment pro- gence in both industry and research communities. VMs of- vides virtualized hardware interfaces to VMs through a Vir- fer many desirable features such as security, ease of man- tual Machine Monitor (VMM) (also called hypervisor). VM agement, OS customization, performance isolation, check- technologies allow running different guest VMs in a phys- pointing, and migration, which can be very beneficial to ical box, with each guest VM possibly running a different the performance and the manageability of high performance guest operating system. They can also provide secure and computing (HPC) applications. However, very few HPC ap- portable environments to meet the demanding requirements plications are currently running in a virtualized environment of computing resources in modern computing systems. due to the performance overhead of virtualization. Further, Recently, network interconnects such as InfiniBand [16], using VMs for HPC also introduces additional challenges Myrinet [24] and Quadrics [31] are emerging, which provide such as management and distribution of OS images. very low latency (less than 5 µs) and very high bandwidth In this paper we present a case for HPC with virtual ma- (multiple Gbps). -

A Light-Weight Virtual Machine Monitor for Blue Gene/P
A Light-Weight Virtual Machine Monitor for Blue Gene/P Jan Stoessx{1 Udo Steinbergz1 Volkmar Uhlig{1 Jonathan Appavooy1 Amos Waterlandj1 Jens Kehnex xKarlsruhe Institute of Technology zTechnische Universität Dresden {HStreaming LLC jHarvard School of Engineering and Applied Sciences yBoston University ABSTRACT debugging tools. CNK also supports I/O only via function- In this paper, we present a light-weight, micro{kernel-based shipping to I/O nodes. virtual machine monitor (VMM) for the Blue Gene/P Su- CNK's lightweight kernel model is a good choice for the percomputer. Our VMM comprises a small µ-kernel with current set of BG/P HPC applications, providing low oper- virtualization capabilities and, atop, a user-level VMM com- ating system (OS) noise and focusing on performance, scal- ponent that manages virtual BG/P cores, memory, and in- ability, and extensibility. However, today's HPC application terconnects; we also support running native applications space is beginning to scale out towards Exascale systems of directly atop the µ-kernel. Our design goal is to enable truly global dimensions, spanning companies, institutions, compatibility to standard OSes such as Linux on BG/P via and even countries. The restricted support for standardized virtualization, but to also keep the amount of kernel func- application interfaces of light-weight kernels in general and tionality small enough to facilitate shortening the path to CNK in particular renders porting the sprawling diversity applications and lowering OS noise. of scalable applications to supercomputers more and more a Our prototype implementation successfully virtualizes a bottleneck in the development path of HPC applications. -

A Virtual Machine Environment for Real Time Systems Laboratories
AC 2007-904: A VIRTUAL MACHINE ENVIRONMENT FOR REAL-TIME SYSTEMS LABORATORIES Mukul Shirvaikar, University of Texas-Tyler MUKUL SHIRVAIKAR received the Ph.D. degree in Electrical and Computer Engineering from the University of Tennessee in 1993. He is currently an Associate Professor of Electrical Engineering at the University of Texas at Tyler. He has also held positions at Texas Instruments and the University of West Florida. His research interests include real-time imaging, embedded systems, pattern recognition, and dual-core processor architectures. At the University of Texas he has started a new real-time systems lab using dual-core processor technology. He is also the principal investigator for the “Back-To-Basics” project aimed at engineering student retention. Nikhil Satyala, University of Texas-Tyler NIKHIL SATYALA received the Bachelors degree in Electronics and Communication Engineering from the Jawaharlal Nehru Technological University (JNTU), India in 2004. He is currently pursuing his Masters degree at the University of Texas at Tyler, while working as a research assistant. His research interests include embedded systems, dual-core processor architectures and microprocessors. Page 12.152.1 Page © American Society for Engineering Education, 2007 A Virtual Machine Environment for Real Time Systems Laboratories Abstract The goal of this project was to build a superior environment for a real time system laboratory that would allow users to run Windows and Linux embedded application development tools concurrently on a single computer. These requirements were dictated by real-time system applications which are increasingly being implemented on asymmetric dual-core processors running different operating systems. A real time systems laboratory curriculum based on dual- core architectures has been presented in this forum in the past.2 It was designed for a senior elective course in real time systems at the University of Texas at Tyler that combines lectures along with an integrated lab. -

GT-Virtual-Machines
College of Design Virtual Machine Setup for CP 6581 Fall 2020 1. You will have access to multiple College of Design virtual machines (VMs). CP 6581 will require VMs with ArcGIS installed, and for class sessions we will start the semester using the K2GPU VM. You should open each VM available to you and check to see if ArcGIS is installed. 2. Here are a few general notes on VMs. a. Because you will be a new user when you first start a VM, you may be prompted to set up Microsoft Explorer, Microsoft Edge, Adobe Creative Suite, or other software. You can close these windows and set up specific software later, if you wish. b. Different VMs allow different degrees of customization. To customize right-click on an empty Desktop area and choose “Personalize”. Change your background to a solid color that’s a distinctive color so you can easily distinguish your virtual desktop from your local computer’s desktop. Some VMs will remember your desktop color, other VMs must be re-set at each login, other VMs won’t allow you to change the background color but may allow you to change a highlight color from the “Colors” item on the left menu just below “Background”. c. Your desktop will look exactly the same as physical computer’s desktop except for the small black rectangle at the middle of the very top of the VM screen. Click on the rectangle and a pop-down horizontal menu of VM options will appear. Here are two useful options. i. Preferences then File Access will allow you to grant VM access to your local computer’s drives and files. -

Virtualizationoverview
VMWAREW H WHITEI T E PPAPERA P E R Virtualization Overview 1 VMWARE WHITE PAPER Table of Contents Introduction .............................................................................................................................................. 3 Virtualization in a Nutshell ................................................................................................................... 3 Virtualization Approaches .................................................................................................................... 4 Virtualization for Server Consolidation and Containment ........................................................... 7 How Virtualization Complements New-Generation Hardware .................................................. 8 Para-virtualization ................................................................................................................................... 8 VMware’s Virtualization Portfolio ........................................................................................................ 9 Glossary ..................................................................................................................................................... 10 2 VMWARE WHITE PAPER Virtualization Overview Introduction Virtualization in a Nutshell Among the leading business challenges confronting CIOs and Simply put, virtualization is an idea whose time has come. IT managers today are: cost-effective utilization of IT infrastruc- The term virtualization broadly describes the separation -

Virtual Machine Benchmarking Kim-Thomas M¨Oller Diploma Thesis
Universitat¨ Karlsruhe (TH) Institut fur¨ Betriebs- und Dialogsysteme Lehrstuhl Systemarchitektur Virtual Machine Benchmarking Kim-Thomas Moller¨ Diploma Thesis Advisors: Prof. Dr. Frank Bellosa Joshua LeVasseur 17. April 2007 I hereby declare that this thesis is the result of my own work, and that all informa- tion sources and literature used are indicated in the thesis. I also certify that the work in this thesis has not previously been submitted as part of requirements for a degree. Hiermit erklare¨ ich, die vorliegende Arbeit selbstandig¨ und nur unter Benutzung der angegebenen Literatur und Hilfsmittel angefertigt zu haben. Alle Stellen, die wortlich¨ oder sinngemaߨ aus veroffentlichten¨ und nicht veroffentlichten¨ Schriften entnommen wurden, sind als solche kenntlich gemacht. Die Arbeit hat in gleicher oder ahnlicher¨ Form keiner anderen Prufungsbeh¨ orde¨ vorgelegen. Karlsruhe, den 17. April 2007 Kim-Thomas Moller¨ Abstract The resurgence of system virtualization has provoked diverse virtualization tech- niques targeting different application workloads and requirements. However, a methodology to compare the performance of virtualization techniques at fine gran- ularity has not yet been introduced. VMbench is a novel benchmarking suite that focusses on virtual machine environments. By applying the pre-virtualization ap- proach for hypervisor interoperability, VMbench achieves hypervisor-neutral in- strumentation of virtual machines at the instruction level. Measurements of dif- ferent virtual machine configurations demonstrate how VMbench helps rate and predict virtual machine performance. Kurzfassung Das wiedererwachte Interesse an der Systemvirtualisierung hat verschiedenartige Virtualisierungstechniken fur¨ unterschiedliche Anwendungslasten und Anforde- rungen hervorgebracht. Jedoch wurde bislang noch keine Methodik eingefuhrt,¨ um Virtualisierungstechniken mit hoher Granularitat¨ zu vergleichen. VMbench ist eine neuartige Benchmarking-Suite fur¨ Virtuelle-Maschinen-Umgebungen. -

Distributed Virtual Machines: a System Architecture for Network Computing
Distributed Virtual Machines: A System Architecture for Network Computing Emin Gün Sirer, Robert Grimm, Arthur J. Gregory, Nathan Anderson, Brian N. Bershad {egs,rgrimm,artjg,nra,bershad}@cs.washington.edu http://kimera.cs.washington.edu Dept. of Computer Science & Engineering University of Washington Seattle, WA 98195-2350 Abstract Modern virtual machines, such as Java and Inferno, are emerging as network computing platforms. While these virtual machines provide higher-level abstractions and more sophisticated services than their predecessors from twenty years ago, their architecture has essentially remained unchanged. State of the art virtual machines are still monolithic, that is, they are comprised of closely-coupled service components, which are thus replicated over all computers in an organization. This crude replication of services forms one of the weakest points in today’s networked systems, as it creates widely acknowledged and well-publicized problems of security, manageability and performance. We have designed and implemented a new system architecture for network computing based on distributed virtual machines. In our system, virtual machine services that perform rule checking and code transformation are factored out of clients and are located in enterprise- wide network servers. The services operate by intercepting application code and modifying it on the fly to provide additional service functionality. This architecture reduces client resource demands and the size of the trusted computing base, establishes physical isolation between virtual machine services and creates a single point of administration. We demonstrate that such a distributed virtual machine architecture can provide substantially better integrity and manageability than a monolithic architecture, scales well with increasing numbers of clients, and does not entail high overhead. -

Enabling Technologies for Distributed and Cloud Computing Dr
Enabling Technologies for Distributed and Cloud Computing Dr. Sanjay P. Ahuja, Ph.D. Fidelity National Financial Distinguished Professor of CIS School of Computing, UNF Technologies for Network-Based Systems Multi-core CPUs and Multithreading Technologies CPU’s today assume a multi-core architecture with dual, quad, six, or more processing cores. The clock rate increased from 10 MHz for Intel 286 to 4 GHz for Pentium 4 in 30 years. However, the clock rate reached its limit on CMOS chips due to power limitations. Clock speeds cannot continue to increase due to excessive heat generation and current leakage. Multi-core CPUs can handle multiple instruction threads. Technologies for Network-Based Systems Multi-core CPUs and Multithreading Technologies LI cache is private to each core, L2 cache is shared and L3 cache or DRAM is off the chip. Examples of multi-core CPUs include Intel i7, Xeon, AMD Opteron. Each core can also be multithreaded. E.g. the Niagara II has 8 cores with each core handling 8 threads for a total of 64 threads maximum. Technologies for Network-Based Systems Hyper-threading (HT) Technology A feature of certain Intel chips (such as Xeon, i7) that makes one physical core appear as two logical processors. On an operating system level, a single-core CPU with Hyper- Threading technology will be reported as two logical processors, dual-core CPU with HT is reported as four logical processors, and so on. HT adds a second set of general, control and special registers. The second set of registers allows the CPU to keep the state of both cores, and effortlessly switch between them by switching the register set. -

Virtual Machines Aaron Sloman ([email protected]) School of Computer Science, University of Birmingham, Birmingham, B15 2TT, UK
What Cognitive Scientists Need to Know about Virtual Machines Aaron Sloman ([email protected]) School of Computer Science, University of Birmingham, Birmingham, B15 2TT, UK Abstract Philosophers have offered metaphysical, epistemological Many people interact with a collection of man-made virtual and conceptual theories about the status of such entities, machines (VMs) every day without reflecting on what that im- for example in discussing dualism, “supervenience”, “real- plies about options open to biological evolution, and the im- ization”, mind-brain identity, epiphenomenalism and other plications for relations between mind and body. This tutorial position paper introduces some of the roles different sorts of “isms”. Many deny that non-physical events can be causes, running VMs (e.g. single function VMs, “platform” VMs) can unless they are identical with their physical realizations. play in engineering designs, including “vertical separation of Non-philosophers either avoid the issues by adopting various concerns” and suggests that biological evolution “discovered” problems that require VMs for their solution long before we forms of reductionism (if they are scientists) or talk about lev- did. This paper explains some of the unnoticed complexity in- els of explanation, or emergence, without being able to give volved in making artificial VMs possible, some of the implica- a precise account of how that is possible. I shall try to show tions for philosophical and cognitive theories about mind-brain supervenience and some options for design of cognitive archi- how recent solutions to engineering problems produce a kind tectures with self-monitoring and self-control. of emergence that can be called “mechanism supervenience”, Keywords: virtual machine; virtual machine supervenience; and conjecture that biological evolution produced similar so- causation; counterfactuals; evolution; self-monitoring; self- lutions.1 Moore (1903) introduced the idea of supervenience. -
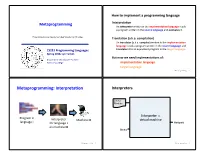
Metaprogramming: Interpretaaon Interpreters
How to implement a programming language Metaprogramming InterpretaAon An interpreter wriDen in the implementaAon language reads a program wriDen in the source language and evaluates it. These slides borrow heavily from Ben Wood’s Fall ‘15 slides. TranslaAon (a.k.a. compilaAon) An translator (a.k.a. compiler) wriDen in the implementaAon language reads a program wriDen in the source language and CS251 Programming Languages translates it to an equivalent program in the target language. Spring 2018, Lyn Turbak But now we need implementaAons of: Department of Computer Science Wellesley College implementaAon language target language Metaprogramming 2 Metaprogramming: InterpretaAon Interpreters Source Program Interpreter = Program in Interpreter Machine M virtual machine language L for language L Output on machine M Data Metaprogramming 3 Metaprogramming 4 Metaprogramming: TranslaAon Compiler C Source x86 Target Program C Compiler Program if (x == 0) { cmp (1000), $0 Program in Program in x = x + 1; bne L language A } add (1000), $1 A to B translator language B ... L: ... x86 Target Program x86 computer Output Interpreter Machine M Thanks to Ben Wood for these for language B Data and following pictures on machine M Metaprogramming 5 Metaprogramming 6 Interpreters vs Compilers Java Compiler Interpreters No work ahead of Lme Source Target Incremental Program Java Compiler Program maybe inefficient if (x == 0) { load 0 Compilers x = x + 1; ifne L } load 0 All work ahead of Lme ... inc See whole program (or more of program) store 0 Time and resources for analysis and opLmizaLon L: ... (compare compiled C to compiled Java) Metaprogramming 7 Metaprogramming 8 Compilers... whose output is interpreted Interpreters.. -

Middleware for a CLEVER Use of Virtual Resources in Federated Clouds
CLOUD COMPUTING 2010 : The First International Conference on Cloud Computing, GRIDs, and Virtualization Middleware for a CLEVER Use of Virtual Resources in Federated Clouds Francesco Tusa, Maurizio Paone, Massimo Villari and Antonio Puliafito Universita` degli Studi di Messina, Facolta` di Ingegneria Contrada di Dio, S. Agata, 98166 Messina, Italy. e-mail: fftusa,mpaone,mvillari,apuliafi[email protected] Abstract—Nowadays Cloud Computing is becoming an inter- services at three different levels: Infrastructure as a Service esting distributed computation infrastructure able to strongly (IaaS), Platform as a Service (PaaS) and Software as a leverage the concept of Virtualization of physical resources. Service (SaaS): This paper deals with the opportunity for managing Virtu- alization Infrastructures in Federated scenarios. In particular, • SaaS: Software as a Service represents the capability the middleware we are introducing presents several features en- given to the consumer in using provider’s applications abling an useful and easy management of private/hybrid clouds running on a cloud infrastructure and accessible from and provides simple and easily accessible interfaces to interact with different “interconnected” clouds. In that context, one of various client devices through a thin client interface the main challenges it is necessary to address is the capability such as a Web browser. that systems need to interact together, maintaining separated • PaaS: Platform as a Service represents the capability their own domains and the own administration policies. A given to the consumer in order to deploy his own appli- Cloud middleware has been designed, we named it CLEVER, cation onto the cloud infrastructure using programming and this paper describes the architecture in each part. -

From Interpreter to Compiler and Virtual Machine: a Functional Derivation Basic Research in Computer Science
BRICS Basic Research in Computer Science BRICS RS-03-14 Ager et al.: From Interpreter to Compiler and Virtual Machine: A Functional Derivation From Interpreter to Compiler and Virtual Machine: A Functional Derivation Mads Sig Ager Dariusz Biernacki Olivier Danvy Jan Midtgaard BRICS Report Series RS-03-14 ISSN 0909-0878 March 2003 Copyright c 2003, Mads Sig Ager & Dariusz Biernacki & Olivier Danvy & Jan Midtgaard. BRICS, Department of Computer Science University of Aarhus. All rights reserved. Reproduction of all or part of this work is permitted for educational or research use on condition that this copyright notice is included in any copy. See back inner page for a list of recent BRICS Report Series publications. Copies may be obtained by contacting: BRICS Department of Computer Science University of Aarhus Ny Munkegade, building 540 DK–8000 Aarhus C Denmark Telephone: +45 8942 3360 Telefax: +45 8942 3255 Internet: [email protected] BRICS publications are in general accessible through the World Wide Web and anonymous FTP through these URLs: http://www.brics.dk ftp://ftp.brics.dk This document in subdirectory RS/03/14/ From Interpreter to Compiler and Virtual Machine: a Functional Derivation Mads Sig Ager, Dariusz Biernacki, Olivier Danvy, and Jan Midtgaard BRICS∗ Department of Computer Science University of Aarhusy March 2003 Abstract We show how to derive a compiler and a virtual machine from a com- positional interpreter. We first illustrate the derivation with two eval- uation functions and two normalization functions. We obtain Krivine's machine, Felleisen et al.'s CEK machine, and a generalization of these machines performing strong normalization, which is new.