(A) Overview of Sequence Curation Pipeline for Pacbio Reads
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Download This Publication (PDF File)
PUBLIC LIBRARY of SCIENCE | plosgenetics.org | ISSN 1553-7390 | Volume 2 | Issue 12 | DECEMBER 2006 GENETICS PUBLIC LIBRARY of SCIENCE www.plosgenetics.org Volume 2 | Issue 12 | DECEMBER 2006 Interview Review Knight in Common Armor: 1949 Unraveling the Genetics 1956 An Interview with Sir John Sulston e225 of Human Obesity e188 Jane Gitschier David M. Mutch, Karine Clément Research Articles Natural Variants of AtHKT1 1964 The Complete Genome 2039 Enhance Na+ Accumulation e210 Sequence and Comparative e206 in Two Wild Populations of Genome Analysis of the High Arabidopsis Pathogenicity Yersinia Ana Rus, Ivan Baxter, enterocolitica Strain 8081 Balasubramaniam Muthukumar, Nicholas R. Thomson, Sarah Jeff Gustin, Brett Lahner, Elena Howard, Brendan W. Wren, Yakubova, David E. Salt Matthew T. G. Holden, Lisa Crossman, Gregory L. Challis, About the Cover Drosophila SPF45: A Bifunctional 1974 Carol Churcher, Karen The jigsaw image of representatives Protein with Roles in Both e178 Mungall, Karen Brooks, Tracey of various lines of eukaryote evolution Splicing and DNA Repair Chillingworth, Theresa Feltwell, refl ects the current lack of consensus as Ahmad Sami Chaouki, Helen K. Zahra Abdellah, Heidi Hauser, to how the major branches of eukaryotes Salz Kay Jagels, Mark Maddison, fi t together. The illustrations from upper Sharon Moule, Mandy Sanders, left to bottom right are as follows: a single Mammalian Small Nucleolar 1984 Sally Whitehead, Michael A. scale from the surface of Umbellosphaera; RNAs Are Mobile Genetic e205 Quail, Gordon Dougan, Julian Amoeba, the large amoeboid organism Elements Parkhill, Michael B. Prentice used as an introduction to protists for Michel J. Weber many school children; Euglena, the iconic Low Levels of Genetic 2052 fl agellate that is often used to challenge Soft Sweeps III: The Signature 1998 Divergence across e215 ideas of plants (Euglena has chloroplasts) of Positive Selection from e186 Geographically and and animals (Euglena moves); Stentor, Recurrent Mutation Linguistically Diverse one of the larger ciliates; Cacatua, the Pleuni S. -

Broadly Sampled Multigene Analyses Yield a Well-Resolved Eukaryotic Tree of Life
Smith ScholarWorks Biological Sciences: Faculty Publications Biological Sciences 10-1-2010 Broadly Sampled Multigene Analyses Yield a Well-Resolved Eukaryotic Tree of Life Laura Wegener Parfrey University of Massachusetts Amherst Jessica Grant Smith College Yonas I. Tekle Smith College Erica Lasek-Nesselquist Marine Biological Laboratory Hilary G. Morrison Marine Biological Laboratory See next page for additional authors Follow this and additional works at: https://scholarworks.smith.edu/bio_facpubs Part of the Biology Commons Recommended Citation Parfrey, Laura Wegener; Grant, Jessica; Tekle, Yonas I.; Lasek-Nesselquist, Erica; Morrison, Hilary G.; Sogin, Mitchell L.; Patterson, David J.; and Katz, Laura A., "Broadly Sampled Multigene Analyses Yield a Well-Resolved Eukaryotic Tree of Life" (2010). Biological Sciences: Faculty Publications, Smith College, Northampton, MA. https://scholarworks.smith.edu/bio_facpubs/126 This Article has been accepted for inclusion in Biological Sciences: Faculty Publications by an authorized administrator of Smith ScholarWorks. For more information, please contact [email protected] Authors Laura Wegener Parfrey, Jessica Grant, Yonas I. Tekle, Erica Lasek-Nesselquist, Hilary G. Morrison, Mitchell L. Sogin, David J. Patterson, and Laura A. Katz This article is available at Smith ScholarWorks: https://scholarworks.smith.edu/bio_facpubs/126 Syst. Biol. 59(5):518–533, 2010 c The Author(s) 2010. Published by Oxford University Press, on behalf of the Society of Systematic Biologists. All rights reserved. For Permissions, please email: [email protected] DOI:10.1093/sysbio/syq037 Advance Access publication on July 23, 2010 Broadly Sampled Multigene Analyses Yield a Well-Resolved Eukaryotic Tree of Life LAURA WEGENER PARFREY1,JESSICA GRANT2,YONAS I. TEKLE2,6,ERICA LASEK-NESSELQUIST3,4, 3 3 5 1,2, HILARY G. -

Rare Phytomyxid Infection on the Alien Seagrass Halophila Stipulacea In
Research Article Mediterranean Marine Science Indexed in WoS (Web of Science, ISI Thomson) and SCOPUS The journal is available on line at http://www.medit-mar-sc.net DOI: http://dx.doi.org/10.12681/mms.14053 Rare phytomyxid infection on the alien seagrass Halophila stipulacea in the southeast Aegean Sea MARTIN VOHNÍK1,2, ONDŘEJ BOROVEC1,2, ELIF ÖZGÜR ÖZBEK3 and EMINE ŞÜKRAN OKUDAN ASLAN4 1 Department of Mycorrhizal Symbioses, Institute of Botany, Czech Academy of Sciences, Průhonice, 25243 Czech Republic 2 Department of Plant Experimental Biology, Faculty of Science, Charles University, Prague, 12844 Czech Republic 3 Marine Biology Museum, Antalya Metropolitan Municipality, Antalya, Turkey 4 Department of Marine Biology, Faculty of Fisheries, Akdeniz University, Antalya, Turkey Corresponding author: [email protected] Handling Editor: Athanasios Athanasiadis Received: 31 May 2017; Accepted: 9 October 2017; Published on line: 8 December 2017 Abstract Phytomyxids (Phytomyxea) are obligate endosymbionts of many organisms such as algae, diatoms, oomycetes and higher plants including seagrasses. Despite their supposed significant roles in the marine ecosystem, our knowledge of their marine diversity and distribution as well as their life cycles is rather limited. Here we describe the anatomy and morphology of several developmental stages of a phytomyxid symbiosis recently discovered on the petioles of the alien seagrass Halophila stipulacea at a locality in the southeast Aegean Sea. Its earliest stage appeared as whitish spots already on the youngest leaves at the apex of the newly formed rhizomes. The infected host cells grew in volume being filled with plasmodia which resulted in the formation of characteristic macroscopic galls. -

University of Oklahoma
UNIVERSITY OF OKLAHOMA GRADUATE COLLEGE MACRONUTRIENTS SHAPE MICROBIAL COMMUNITIES, GENE EXPRESSION AND PROTEIN EVOLUTION A DISSERTATION SUBMITTED TO THE GRADUATE FACULTY in partial fulfillment of the requirements for the Degree of DOCTOR OF PHILOSOPHY By JOSHUA THOMAS COOPER Norman, Oklahoma 2017 MACRONUTRIENTS SHAPE MICROBIAL COMMUNITIES, GENE EXPRESSION AND PROTEIN EVOLUTION A DISSERTATION APPROVED FOR THE DEPARTMENT OF MICROBIOLOGY AND PLANT BIOLOGY BY ______________________________ Dr. Boris Wawrik, Chair ______________________________ Dr. J. Phil Gibson ______________________________ Dr. Anne K. Dunn ______________________________ Dr. John Paul Masly ______________________________ Dr. K. David Hambright ii © Copyright by JOSHUA THOMAS COOPER 2017 All Rights Reserved. iii Acknowledgments I would like to thank my two advisors Dr. Boris Wawrik and Dr. J. Phil Gibson for helping me become a better scientist and better educator. I would also like to thank my committee members Dr. Anne K. Dunn, Dr. K. David Hambright, and Dr. J.P. Masly for providing valuable inputs that lead me to carefully consider my research questions. I would also like to thank Dr. J.P. Masly for the opportunity to coauthor a book chapter on the speciation of diatoms. It is still such a privilege that you believed in me and my crazy diatom ideas to form a concise chapter in addition to learn your style of writing has been a benefit to my professional development. I’m also thankful for my first undergraduate research mentor, Dr. Miriam Steinitz-Kannan, now retired from Northern Kentucky University, who was the first to show the amazing wonders of pond scum. Who knew that studying diatoms and algae as an undergraduate would lead me all the way to a Ph.D. -
Protocols for Monitoring Harmful Algal Blooms for Sustainable Aquaculture and Coastal Fisheries in Chile (Supplement Data)
Protocols for monitoring Harmful Algal Blooms for sustainable aquaculture and coastal fisheries in Chile (Supplement data) Provided by Kyoko Yarimizu, et al. Table S1. Phytoplankton Naming Dictionary: This dictionary was constructed from the species observed in Chilean coast water in the past combined with the IOC list. Each name was verified with the list provided by IFOP and online dictionaries, AlgaeBase (https://www.algaebase.org/) and WoRMS (http://www.marinespecies.org/). The list is subjected to be updated. Phylum Class Order Family Genus Species Ochrophyta Bacillariophyceae Achnanthales Achnanthaceae Achnanthes Achnanthes longipes Bacillariophyta Coscinodiscophyceae Coscinodiscales Heliopeltaceae Actinoptychus Actinoptychus spp. Dinoflagellata Dinophyceae Gymnodiniales Gymnodiniaceae Akashiwo Akashiwo sanguinea Dinoflagellata Dinophyceae Gymnodiniales Gymnodiniaceae Amphidinium Amphidinium spp. Ochrophyta Bacillariophyceae Naviculales Amphipleuraceae Amphiprora Amphiprora spp. Bacillariophyta Bacillariophyceae Thalassiophysales Catenulaceae Amphora Amphora spp. Cyanobacteria Cyanophyceae Nostocales Aphanizomenonaceae Anabaenopsis Anabaenopsis milleri Cyanobacteria Cyanophyceae Oscillatoriales Coleofasciculaceae Anagnostidinema Anagnostidinema amphibium Anagnostidinema Cyanobacteria Cyanophyceae Oscillatoriales Coleofasciculaceae Anagnostidinema lemmermannii Cyanobacteria Cyanophyceae Oscillatoriales Microcoleaceae Annamia Annamia toxica Cyanobacteria Cyanophyceae Nostocales Aphanizomenonaceae Aphanizomenon Aphanizomenon flos-aquae -

Rhizaria, Cercozoa)
Protist, Vol. 166, 363–373, July 2015 http://www.elsevier.de/protis Published online date 28 May 2015 ORIGINAL PAPER Molecular Phylogeny of the Widely Distributed Marine Protists, Phaeodaria (Rhizaria, Cercozoa) a,1 a a b Yasuhide Nakamura , Ichiro Imai , Atsushi Yamaguchi , Akihiro Tuji , c d Fabrice Not , and Noritoshi Suzuki a Plankton Laboratory, Graduate School of Fisheries Sciences, Hokkaido University, Hakodate, Hokkaido 041–8611, Japan b Department of Botany, National Museum of Nature and Science, Tsukuba 305–0005, Japan c CNRS, UMR 7144 & Université Pierre et Marie Curie, Station Biologique de Roscoff, Equipe EPPO - Evolution du Plancton et PaléoOcéans, Place Georges Teissier, 29682 Roscoff, France d Institute of Geology and Paleontology, Graduate School of Science, Tohoku University, Sendai 980–8578, Japan Submitted January 1, 2015; Accepted May 19, 2015 Monitoring Editor: David Moreira Phaeodarians are a group of widely distributed marine cercozoans. These plankton organisms can exhibit a large biomass in the environment and are supposed to play an important role in marine ecosystems and in material cycles in the ocean. Accurate knowledge of phaeodarian classification is thus necessary to better understand marine biology, however, phylogenetic information on Phaeodaria is limited. The present study analyzed 18S rDNA sequences encompassing all existing phaeodarian orders, to clarify their phylogenetic relationships and improve their taxonomic classification. The mono- phyly of Phaeodaria was confirmed and strongly supported by phylogenetic analysis with a larger data set than in previous studies. The phaeodarian clade contained 11 subclades which generally did not correspond to the families and orders of the current classification system. Two families (Challengeri- idae and Aulosphaeridae) and two orders (Phaeogromida and Phaeocalpida) are possibly polyphyletic or paraphyletic, and consequently the classification needs to be revised at both the family and order levels by integrative taxonomy approaches. -

Biology and Systematics of Heterokont and Haptophyte Algae1
American Journal of Botany 91(10): 1508±1522. 2004. BIOLOGY AND SYSTEMATICS OF HETEROKONT AND HAPTOPHYTE ALGAE1 ROBERT A. ANDERSEN Bigelow Laboratory for Ocean Sciences, P.O. Box 475, West Boothbay Harbor, Maine 04575 USA In this paper, I review what is currently known of phylogenetic relationships of heterokont and haptophyte algae. Heterokont algae are a monophyletic group that is classi®ed into 17 classes and represents a diverse group of marine, freshwater, and terrestrial algae. Classes are distinguished by morphology, chloroplast pigments, ultrastructural features, and gene sequence data. Electron microscopy and molecular biology have contributed signi®cantly to our understanding of their evolutionary relationships, but even today class relationships are poorly understood. Haptophyte algae are a second monophyletic group that consists of two classes of predominately marine phytoplankton. The closest relatives of the haptophytes are currently unknown, but recent evidence indicates they may be part of a large assemblage (chromalveolates) that includes heterokont algae and other stramenopiles, alveolates, and cryptophytes. Heter- okont and haptophyte algae are important primary producers in aquatic habitats, and they are probably the primary carbon source for petroleum products (crude oil, natural gas). Key words: chromalveolate; chromist; chromophyte; ¯agella; phylogeny; stramenopile; tree of life. Heterokont algae are a monophyletic group that includes all (Phaeophyceae) by Linnaeus (1753), and shortly thereafter, photosynthetic organisms with tripartite tubular hairs on the microscopic chrysophytes (currently 5 Oikomonas, Anthophy- mature ¯agellum (discussed later; also see Wetherbee et al., sa) were described by MuÈller (1773, 1786). The history of 1988, for de®nitions of mature and immature ¯agella), as well heterokont algae was recently discussed in detail (Andersen, as some nonphotosynthetic relatives and some that have sec- 2004), and four distinct periods were identi®ed. -

A Revised Classification of Naked Lobose Amoebae (Amoebozoa
Protist, Vol. 162, 545–570, October 2011 http://www.elsevier.de/protis Published online date 28 July 2011 PROTIST NEWS A Revised Classification of Naked Lobose Amoebae (Amoebozoa: Lobosa) Introduction together constitute the amoebozoan subphy- lum Lobosa, which never have cilia or flagella, Molecular evidence and an associated reevaluation whereas Variosea (as here revised) together with of morphology have recently considerably revised Mycetozoa and Archamoebea are now grouped our views on relationships among the higher-level as the subphylum Conosa, whose constituent groups of amoebae. First of all, establishing the lineages either have cilia or flagella or have lost phylum Amoebozoa grouped all lobose amoe- them secondarily (Cavalier-Smith 1998, 2009). boid protists, whether naked or testate, aerobic Figure 1 is a schematic tree showing amoebozoan or anaerobic, with the Mycetozoa and Archamoe- relationships deduced from both morphology and bea (Cavalier-Smith 1998), and separated them DNA sequences. from both the heterolobosean amoebae (Page and The first attempt to construct a congruent molec- Blanton 1985), now belonging in the phylum Per- ular and morphological system of Amoebozoa by colozoa - Cavalier-Smith and Nikolaev (2008), and Cavalier-Smith et al. (2004) was limited by the the filose amoebae that belong in other phyla lack of molecular data for many amoeboid taxa, (notably Cercozoa: Bass et al. 2009a; Howe et al. which were therefore classified solely on morpho- 2011). logical evidence. Smirnov et al. (2005) suggested The phylum Amoebozoa consists of naked and another system for naked lobose amoebae only; testate lobose amoebae (e.g. Amoeba, Vannella, this left taxa with no molecular data incertae sedis, Hartmannella, Acanthamoeba, Arcella, Difflugia), which limited its utility. -

Phylogenomic Analysis of Balantidium Ctenopharyngodoni (Ciliophora, Litostomatea) Based on Single-Cell Transcriptome Sequencing
Parasite 24, 43 (2017) © Z. Sun et al., published by EDP Sciences, 2017 https://doi.org/10.1051/parasite/2017043 Available online at: www.parasite-journal.org RESEARCH ARTICLE Phylogenomic analysis of Balantidium ctenopharyngodoni (Ciliophora, Litostomatea) based on single-cell transcriptome sequencing Zongyi Sun1, Chuanqi Jiang2, Jinmei Feng3, Wentao Yang2, Ming Li1,2,*, and Wei Miao2,* 1 Hubei Key Laboratory of Animal Nutrition and Feed Science, Wuhan Polytechnic University, Wuhan 430023, PR China 2 Institute of Hydrobiology, Chinese Academy of Sciences, No. 7 Donghu South Road, Wuchang District, Wuhan 430072, Hubei Province, PR China 3 Department of Pathogenic Biology, School of Medicine, Jianghan University, Wuhan 430056, PR China Received 22 April 2017, Accepted 12 October 2017, Published online 14 November 2017 Abstract- - In this paper, we present transcriptome data for Balantidium ctenopharyngodoni Chen, 1955 collected from the hindgut of grass carp (Ctenopharyngodon idella). We evaluated sequence quality and de novo assembled a preliminary transcriptome, including 43.3 megabits and 119,141 transcripts. Then we obtained a final transcriptome, including 17.7 megabits and 35,560 transcripts, by removing contaminative and redundant sequences. Phylogenomic analysis based on a supermatrix with 132 genes comprising 53,873 amino acid residues and phylogenetic analysis based on SSU rDNA of 27 species were carried out herein to reveal the evolutionary relationships among six ciliate groups: Colpodea, Oligohymenophorea, Litostomatea, Spirotrichea, Hetero- trichea and Protocruziida. The topologies of both phylogenomic and phylogenetic trees are discussed in this paper. In addition, our results suggest that single-cell sequencing is a sound method of obtaining sufficient omics data for phylogenomic analysis, which is a good choice for uncultivable ciliates. -

Resource Partitioning Between Phytoplankton and Bacteria in the Coastal Baltic Sea Frontiers in Marine Science, 7: 1-19
http://www.diva-portal.org This is the published version of a paper published in Frontiers in Marine Science. Citation for the original published paper (version of record): Sörenson, E., Lindehoff, E., Farnelid, H., Legrand, C. (2020) Resource Partitioning Between Phytoplankton and Bacteria in the Coastal Baltic Sea Frontiers in Marine Science, 7: 1-19 https://doi.org/10.3389/fmars.2020.608244 Access to the published version may require subscription. N.B. When citing this work, cite the original published paper. Permanent link to this version: http://urn.kb.se/resolve?urn=urn:nbn:se:lnu:diva-99520 ORIGINAL RESEARCH published: 25 November 2020 doi: 10.3389/fmars.2020.608244 Resource Partitioning Between Phytoplankton and Bacteria in the Coastal Baltic Sea Eva Sörenson, Hanna Farnelid, Elin Lindehoff and Catherine Legrand* Department of Biology and Environmental Science, Linnaeus University Centre of Ecology and Evolution and Microbial Model Systems, Linnaeus University, Kalmar, Sweden Eutrophication coupled to climate change disturbs the balance between competition and coexistence in microbial communities including the partitioning of organic and inorganic nutrients between phytoplankton and bacteria. Competition for inorganic nutrients has been regarded as one of the drivers affecting the productivity of the eutrophied coastal Baltic Sea. Yet, it is unknown at the molecular expression level how resources are competed for, by phytoplankton and bacteria, and what impact this competition has on the community composition. Here we use metatranscriptomics and amplicon sequencing and compare known metabolic pathways of both phytoplankton and bacteria co-occurring during a summer bloom in the archipelago of Åland in the Baltic Sea to examine phytoplankton bacteria resource partitioning. -

Protist Phylogeny and the High-Level Classification of Protozoa
Europ. J. Protistol. 39, 338–348 (2003) © Urban & Fischer Verlag http://www.urbanfischer.de/journals/ejp Protist phylogeny and the high-level classification of Protozoa Thomas Cavalier-Smith Department of Zoology, University of Oxford, South Parks Road, Oxford, OX1 3PS, UK; E-mail: [email protected] Received 1 September 2003; 29 September 2003. Accepted: 29 September 2003 Protist large-scale phylogeny is briefly reviewed and a revised higher classification of the kingdom Pro- tozoa into 11 phyla presented. Complementary gene fusions reveal a fundamental bifurcation among eu- karyotes between two major clades: the ancestrally uniciliate (often unicentriolar) unikonts and the an- cestrally biciliate bikonts, which undergo ciliary transformation by converting a younger anterior cilium into a dissimilar older posterior cilium. Unikonts comprise the ancestrally unikont protozoan phylum Amoebozoa and the opisthokonts (kingdom Animalia, phylum Choanozoa, their sisters or ancestors; and kingdom Fungi). They share a derived triple-gene fusion, absent from bikonts. Bikonts contrastingly share a derived gene fusion between dihydrofolate reductase and thymidylate synthase and include plants and all other protists, comprising the protozoan infrakingdoms Rhizaria [phyla Cercozoa and Re- taria (Radiozoa, Foraminifera)] and Excavata (phyla Loukozoa, Metamonada, Euglenozoa, Percolozoa), plus the kingdom Plantae [Viridaeplantae, Rhodophyta (sisters); Glaucophyta], the chromalveolate clade, and the protozoan phylum Apusozoa (Thecomonadea, Diphylleida). Chromalveolates comprise kingdom Chromista (Cryptista, Heterokonta, Haptophyta) and the protozoan infrakingdom Alveolata [phyla Cilio- phora and Miozoa (= Protalveolata, Dinozoa, Apicomplexa)], which diverged from a common ancestor that enslaved a red alga and evolved novel plastid protein-targeting machinery via the host rough ER and the enslaved algal plasma membrane (periplastid membrane). -
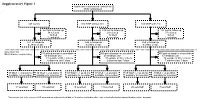
Supplementary Figure 1 Multicenter Randomised Control Trial 2746 Randomised
Supplementary Figure 1 Multicenter randomised control trial 2746 randomised 947 control 910 MNP without zinc 889 MNP with zinc 223 lost to follow up 219 lost to follow up 183 lost to follow up 34 refused 29 refused 37 refused 16 died 12 died 9 died 3 excluded 4 excluded 1 excluded 671 in follow-up 646 in follow-up 659 in follow-up at 24mo of age at 24mo of age at 24mo of age Selection for Microbiome sequencing 516 paired samples unavailable 469 paired samples unavailable 497 paired samples unavailable 69 antibiotic use 63 antibiotic use 67 antibiotic use 31 outside of WLZ criteria 37 outside of WLZ criteria 34 outside of WLZ criteria 6 diarrhea last 7 days 2 diarrhea last 7 days 7 diarrhea last 7 days 39 WLZ > -1 at 24 mo 10 WLZ < -2 at 24mo 58 WLZ > -1 at 24 mo 17 WLZ < -2 at 24mo 48 WLZ > -1 at 24 mo 8 WLZ < -2 at 24mo available for selection available for selection available for selection available for selection available for selection1 available for selection1 14 selected 10 selected 15 selected 14 selected 20 selected1 7 selected1 1 Two subjects (one in the reference WLZ group and one undernourished) had, at 12 months, no diarrhea within 1 day of stool collection but reported diarrhea within 7 days prior. Length, cm kg Weight, Supplementary Figure 2. Length (left) and weight (right) z-scores of children recruited into clinical trial NCT00705445 during the first 24 months of life. Median and quantile values are shown, with medians for participants profiled in current study indicated by red (undernourished) and black (reference WLZ) lines.